数通知识宝典
Version 1.6.1
朱仕耿 00261992

华为技术有限公司¶
版权所有 侵权必究
修订记录¶
| 日期 | 版本 | 描述 | 作者/修订人 |
|---|---|---|---|
| 2014-07-01 | 1.0 | 初稿完成 | 朱仕耿 00261992 |
| 2014-07-20 | 1.1 | 增加VRP配置基础;修订NAT的部分内容; 增加GREOver IPSec;增加IPv6内容 | 朱仕耿 00261992 |
| 2014-08-01 | 1.2 | 增加Smart Link;增加组播内容;修订部分章节 | 朱仕耿 00261992 |
| 2015-10-20 | 1.3 | 修订部分章节及已知文档错误;增加堆叠技术内容 | 朱仕耿 00261992 |
| 2017-04-28 | 1.5 | 修订部分章节,优化文档结构,修改已知文档错误;增加网 络故障处理等章节;刷新防火墙配置(基于NGFW) | 朱仕耿 00261992 |
| 2017-08-09 | 1.6 | 增加MPLS与MPLS VPN章节,删除部分老旧内容 | 朱仕耿 00261992 |
目 录¶
数据通信与网络 知识地图 10#_bookmark0
- 网络基础 11
- 利用TCP/IP模型理解数据通信过程 11
- IP地址的概念及IP子网划分 19
- VRP基础 27
- 使用Console接口管理设备 32
- eNSP华为官方数通模拟器 37
- 交换基础 43
- 二层交换基础 43
- VLAN及Trunk 47
- VLAN的基本概念 47
- Access类型的接口 49
- Trunk类型的接口 50
- 接口类型小结 51
- VLAN及Trunk的基础配置 54
- Hybrid接口的配置 57
- QinQ 62
- 二层接口、三层接口、以及PVID、VLAN-ID等概念杂谈 65
- 二层防环技术 66
- STP 66
- STP的特性及优化 79
- MSTP 89
- Smart Link及Monitor Link 98
- 实现VLAN间的互访 115
- 通过子接口实现VLAN间的互访 115
- 通过vlan-interface实现VLAN间的互访 118
- 链路聚合 122
- 链路聚合技术背景 122
- 工作方式:手工负载分担(Manual load-balance) 123
- 工作方式:LACP 124
- 基础实验 126
- 交换安全 130
- 端口镜像 130
- 捕获业务报文 135
- 端口隔离 138
- 路由基础 141
- IP路由基础 141
- 什么是IP路由 141
- IP路由表 142
- 路由优先级 143
- 静态路由 144
- 静态路由简单实验 146
- 默认路由(缺省路由) 149
- 浮动静态路由 150
- 路由汇总(路由聚合) 151
- 最长匹配原则 155
- 动态路由协议基础 159
- OSPF 161
- OSPF概述 161
- OSPF基本概念 164
- OSPF的基础配置 172
- OSPF LSA及特殊区域 182
- OSPF高级 192
- IP路由基础 141
-
交换提高 196
4.1 S5300交换机堆叠 196
-
理论部分 196
-
配置指导 198
4.2 S6300交换机堆叠 200
-
理论部分 200
- 配置指导 202
- Traffic-policy流量统计 205
- VLAN映射 206
- 路由提高 207
- 路由重发布 207
- 技术背景 207
- 实施要点 210
- 路由重发布的配置 211
- 路由策略 215
- Route-policy 215
-
IP-Prefix 218
5.3 BGP 222
-
BGP基本概念 222
- BGP入门实验 230
- BGP路径属性 238
- BGP路由策略 253
- BGP路由反射器 275
- BGP联邦 285
- BGP选路规则详解 289
- 虚拟路由转发实例 313
- VPN-Instance部署案例 313
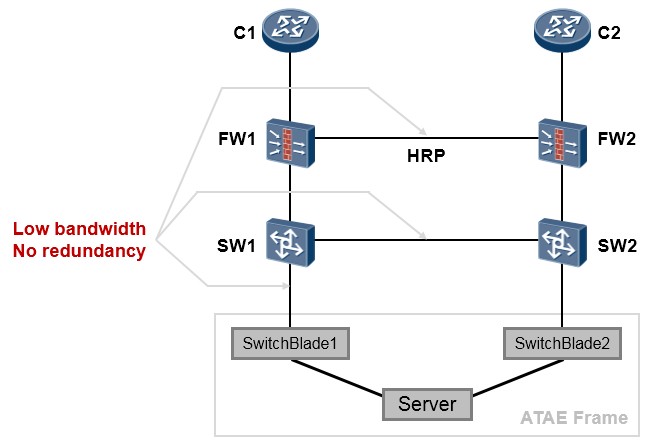
- 冗余可靠 317
- VRRP 317
- VRRP概述 317
- VRRP术语 319
- VRRP的基础配置 320
- VRRP常见问题 330
- VRRP与NQA的联动 331
- 网络安全 333
-
7.1 ACL 333
- ACL概述 333
- ACL的分类 334
- ACL的配置 335
- ACL配置实例(路由器) 336
- ACL配置示例(交换机) 337
-
防火墙基础 338
- 防火墙概述 338
- 防火墙的基础知识 339
-
防火墙的基础配置 346
7.3 NAT 360
-
NAT概述 360
- NAT类型详解 361
- NAT在防火墙(NGFW)上的部署 364
- NAT在路由器上的部署 372
- 防火墙双机热备 375
- 防火墙双机热备概述 375
- 防火墙双机热备基础 377
- 防火墙双机配置步骤 383
- 配置案例1:防火墙双机主备配置(上下行连接交换机并在物理接口部署VRRP) 383
- 与防火墙双机热备相关的其他命令 390
- 配置案例2:防火墙双机主备配置(上下行连接交换机并在下行子接口部署VRRP) 391
- 配置案例3:防火墙双机主备配置(上下行连接交换机并在下行Eth-trunk子接口部署VRRP) 395
- 配置案例4:防火墙双机主备配置(下行连接内部交换机并在Eth-trunk子接口部署VRRP、上行连接外部交换机并运行OSPF) 401
- 防火墙双机配置注意事项 410
- 防火墙常见问题 411
7.6 VPN 415
7.6.1 VPN基础知识 415
7.6.2 GRE 420
7.6.3 IPSecVPN 423
-
-
网络管理 483
- SNMP 483
- SNMPv3的基础配置 487
- NTP的基础配置 489
-
组播技术 490
- 组播基础 490
- 组播概述 490
- 组播模型 492
- 组播分发树 493
- 组播地址 493
-
IGMP 496
-
IGMP概述 496
9.2.2 IGMPv1(RFC1112) 497
9.2.3 IGMPv2(RFC2236) 499
9.2.4 IGMP配置及实现 503
-
-
组播路由协议概述 507
- 关于组播路由协议 507
- 组播路由表项 508
-
组播分发树 509
9.3.4 RPF 510
-
PIM概述 511
- PIM-DM 512
- 协议概述 512
- 协议报文 512
- 邻居关系 513
- 扩散(Flood)、剪枝(Prune)及嫁接(Graft) 514
- Assert断言机制 518
- 配置示例 519
- PIM-SM 526
- 基础知识 526
- 工作机制1:共享树加入 527
- 工作机制2:共享树剪枝 529
- 工作机制3:源注册 531
- 工作机制4:RPT到SPT的切换 534
- PIM-SM DR指定路由器 537
- 配置示例 538
- IPv6基础 548
10.1 IPv6 基础 548
10.1.1 概述 548
10.1.2 报文格式 549
- IPv6编址 551
- IPv6地址 551
- 地址类型 552
- 单播地址 553
- 接口ID 555
- 组播地址 556
- 基础配置 558
- 基础配置命令 558
- 实验1:IPv6入门实验 559
- 实验2:无状态地址自动配置 562
-
ICMPv6 564
-
ICMPv6概述 564
10.4.2 NDP 565
-
-
IPv6过渡技术 575
10.5.1 概述 575
- IPv6 Over IPv4手工隧道 577
- GRE隧道 580
-
6to4自动隧道 584
10.5.5 NAT64概述 589
-
NAT64(IPv6节点主动访问IPv4服务器) 591
- NAT64(IPv4节点主动访问IPv6服务器) 593
- MPLS与MPLS VPN 595
- MPLS基础 595
- MPLS概述 595
- MPLS术语 597
- MPLS标签 599
- MPLS标签操作 600
-
MPLS转发过程详解 601
11.2 LDP 604
-
LDP概述 604
- LDP ID 606
- 标签空间 606
- 传输地址 607
-
LDP的基本工作过程 607
11.2.6 PHP 611
-
MPLS的基础配置 613
- 基础命令 613
- 基础实验 614
- MPLS VPN 619
- MPLS VPN的架构 620
- MPLS VPN初体验 621
-
VPN实例 625
11.4.4 RD 627
11.4.5 RT 628
11.4.6 基础实验 629
- 组播基础 490
-
服务质量 640
12.1 流量分类与标记 640
12.1.1 修改流量的DSCP 640
-
故障处理 641
- 网络故障处理概述 641
-
网络故障处理案例 645
13.2.1 案例1:某局点单板无法访问客户网络设备 645
13.2.2 案例2 647
13.2.3 案例3 648
13.2.4 案例4 649
13.2.5 案例5 650
13.2.6 案例6 652
13.2.7 案例7 652
13.2.8 案例8 653
13.2.9 案例9 654
数据通信与网络 知识地图¶
一个理想的知识体系沉淀(知识库),应该是体系化、系统化的,对知识的呈现应该是有条理的、连续的、模块化的,而且能够将理论与实践相结合,落地到实际业务中,能够直接为业务输出价值。知识的开发过程中,必须站在使用者的角度思考,无法被使用的沉淀是没有价值的。而且理想的知识库应该是低获取门槛, 甚至零获取门槛的,应该是开放的。知识库中的知识应该善用互联网渠道、善用多媒体技术,知识开发更要专注知识的有效和高效传递。
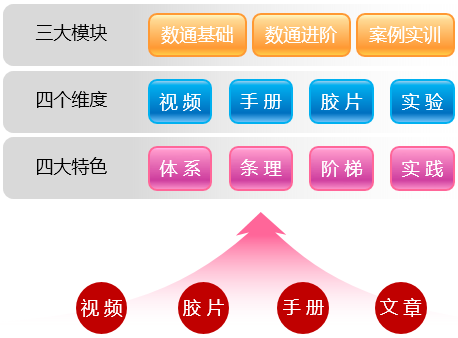
《数据通信与网络 知识地图》是笔者在数据通信领域的知识沉淀,该知识地图从零基础开始,循序渐进、体系化地讲述关于数通的各个知识模块。四个内容阵列——培训视频、配套PPT、技术文档(手册)以及实验案例构成了知识地图的整体框架,搭配华为实验模拟平台(华为官方数通模拟器eNSP),将理论与实践紧密结合。除此之外,为了方便大家集中查阅,笔者还将知识地图中所有的原创技术文章整合成一本数通知识宝典——《数通知识宝典》,也就是您正在阅读的这份文档。
学习过程中,可以先看视频,再阅读配套PPT和知识宝典、产品文档,然后使用模拟环境进行实验——通过本知识地图,任何一个零基础的人都能够迅速地掌握各种数通技术及协议,并且应用到实际业务中。即使是以项目为触发的按需学习,也能在地图中快速定位到所需的技术或协议并获取相关的知识内容。
关于本知识地图的最新版本,请在华为3MS Hi社区搜索:“数据通信与网络 知识地图”,或者访问本人3MS
HI社区的个人主页。
朱 仕 耿 261992 (2015-10-08)
网络基础¶
- 利用 TCP/IP 模型理解数据通信过程
回顾TCP/IP模型¶
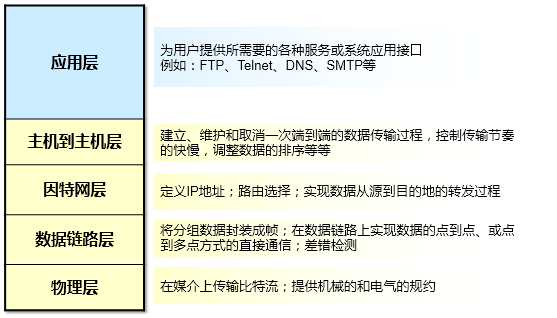
什么是数据网络(Data Network)?简单地说,数据网络就是一个由各种设备搭建起来的一张网,常见的设备有:路由器、交换机、防火墙、负载均衡器、IDS/IPS、VPN服务器等等。数据网络最基本的功能就是实现不同节点之间的数据互通,也就是数据通信。
TCP/IP模型是当今IP网络的基础(也被称为DoD模型,上图我贴出的并不是标准的TCP/IP模型,为了方便下文的阐述,这里给出的是一个TCP/IP模型与OSI模型的对等模型),它将整个数据通信的任务划分成不同的功能层次(Layer),每一个层次有其所定义的功能,以及对应的协议。打个比方,对于一家公司而言,一笔业务需要各个部门相互协同工作才能完成,部门与部门之间既相互独立,但是又需要相互配合,可以借用这种思路来理解TCP/IP参考模型。分层参考模型的设计是非常经典的理念:
- 层次化的模型设计将网络的通信过程划分为更小、更简单的部件,因此有助于各个部件的独立开发、设计和故障排除;
- 层与层之间相互独立,又互相依赖,每一层都有该层的功能、以及定义的协议标准。层与层之间相
互配合,共同完成数据通信的过程;
- 通过组件的标准化,允许多个供应商进行开发;
- 通过定义在模型的每一层实现什么功能,鼓励产业的标准化;
-
 允许各种类型的网络硬件和软件相互通信。
允许各种类型的网络硬件和软件相互通信。上面这张图显示的就是每个层次对应的代表性协议。
理解数据通信过程¶
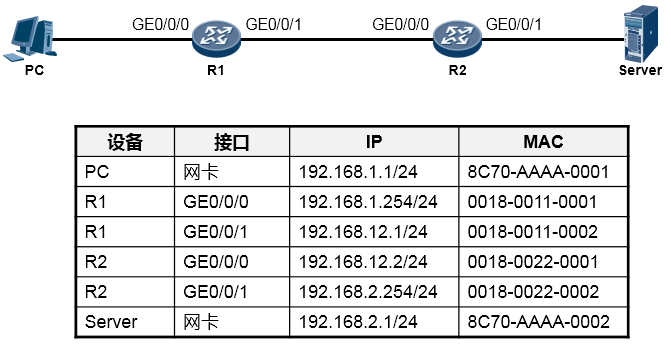
根据上图所示的网络拓扑(Topology),我们来分析一下PC访问Server的WEB服务的详细通信过程。在阐述过程中,我们聚焦的重点是利用TCP/IP参考模型理解数据通信过程,因此可能会忽略部分技术细节,例如DNS、TCP三次握手等,这些技术细节这里暂不做讨论。现在你要换一种视野来看待这个
“世界”了,想象一下上图所示的终端以及路由器都是一个个的“TCP/IP通信模型”,事实上,整个过程在宏观层面体现如下:
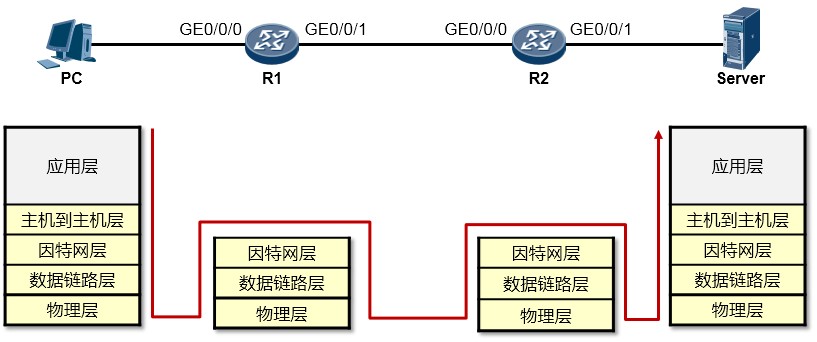
我们一步一步的来分析:
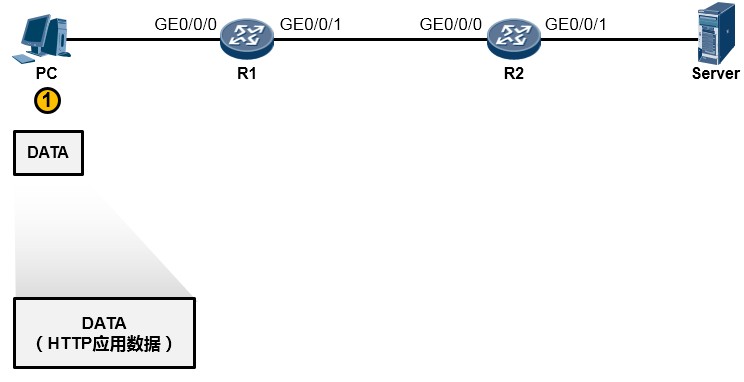
- PC的用户在WEB浏览器中访问Server的WEB服务(这里我们暂且不去关注HTTP交互、DNS交互等细节,重点看通信过程),PC的这次操作将触发HTTP应用为用户构造一个应用数据(如下图所示)。当然这个数据最终要传递到Server并“递交”到Server的HTTP应用来处理,但是HTTP不关心数据怎么传、怎么寻址、怎么做差错校验等等,这些事情交由专门的层次来完成,所以HTTP应用数据还需经过一番“折腾”才能从PC传到Server,OK GO。
-
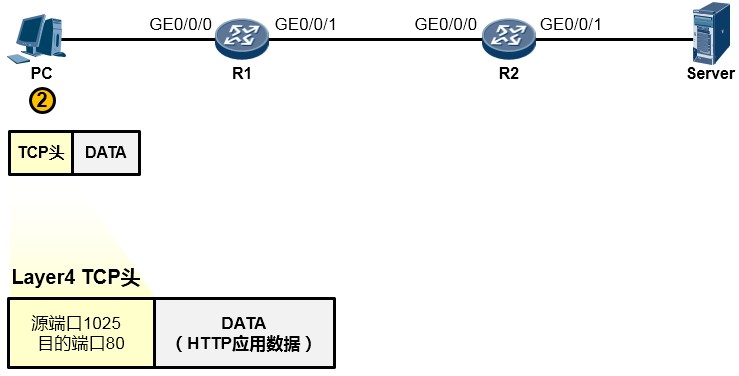
由于HTTP基于TCP,因此这个应用数据交由参考模型中的主机到主机层(第4层)进一步处理。在该层,上层HTTP应用的数据被封装一个TCP的头部(可以简单的理解为套了一个TCP的信封), 在TCP头部中我们重点关注两个字段(信封上写的东西),一个是源端口号,另一个是目的端口号, 源端口号为随机产生的端口号(是PC本地设置的、专门用于本次会话的端口),目的端口号为80
(HTTP服务对应的默认端口号是80),如下图所示。然后这个数据段(Segment)被交给下一个层处理。
-
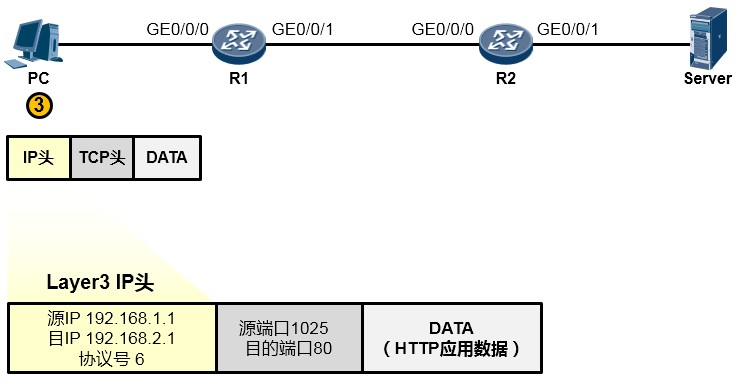
下一层是网络层,也叫因特网层(第3层),处于这个层的IP协议为这个上层下来的数据封装一个
IP头部(在之前的基础上又套了一个信封,如下图所示),以便该数据能够在IP网络中被网络设备 从源转发(路由)到目的地。在IP头当中我们重点关注源IP地址、目的IP地址、协议号这三个字段。 其中源地址填写的是PC自己的IP地址192.168.1.1,目的地址存放的是Server的IP地址192.168.2.1, 而协议号字段则存放的是值6,这个值是一个众所周知(Well-Known),也就是行业约定的值,该 值对应上层协议类型TCP,表示这个IP头后面封装的上层协议为TCP(形象点的描述是,协议字段 用于表示这个IP信封里装的是一个TCP的内容)。搞定之后,这个数据被交给下一层处理。
-
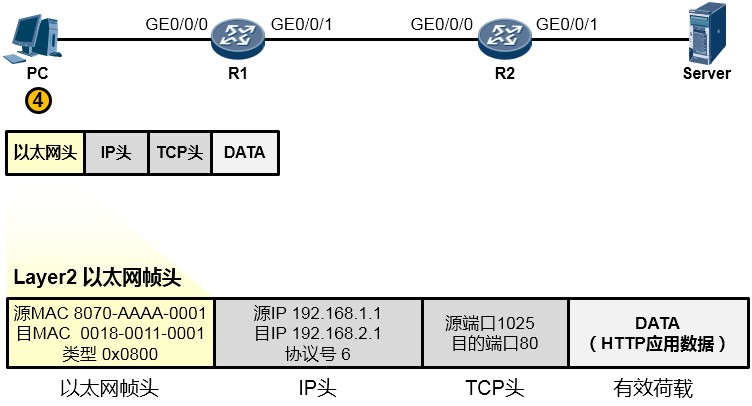
为了让这个IP数据包能够在链路上传输(从链路的一个节点传到另一节点),还要给数据包封装上一个数据链路层(第2层)的头部,以便该数据能够在链路上被顺利传输到对端。由于PC与R1之间为以太网链路,因此上层来的IP数据包被封装一个以太网的数据帧头(再增加一个信封)。这个帧头中写入的源MAC地址为PC 的网卡MAC, 那么目的MAC呢? PC 知道, 数据的目的地是
192.168.2.1这个IP,而本机IP是192.168.1.1/24,显然,目的地与自己并不在同一个IP网段,因此需要求助于自己的默认网关,让网关来帮助自己将数据包转发出去。那首先得把数据转发到网关吧?因此目的MAC地址填写的就是网关192.168.1.254对应的MAC地址。但是初始情况下,PC可
能并不知晓192.168.1.254对应的MAC地址,所以,它会发送一个ARP广播去请求192.168.1.254的
MAC,R1的GE0/0/0口会收到这个ARP请求并且回送ARP响应报文。如此一来PC就知道了网关的
MAC,它将网关MAC 0018-0011-0001填写在以太网数据帧头部的目的MAC地址字段中。另外, 以太网数据帧头的类型字段写上0x0800这个值,表示这个数据帧头后面封装的是一个IP包。费了好大劲儿,这个数据帧(Frame)终于搞定了,如下图所示:
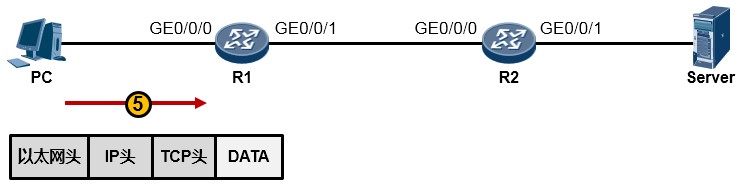
- 值得一提的是,事实上在物理链路中传输的是比特(bit)流,或者电气化的脉冲型号,只不过为了方便理解和更加直观地分析,我们往往会以IP包或者数据帧的形式来阐述通信过程。所以从物理上说,最终这个以太网数据帧变成了一堆的101110101从网线传到了路由器R1上,如下图所示:
-
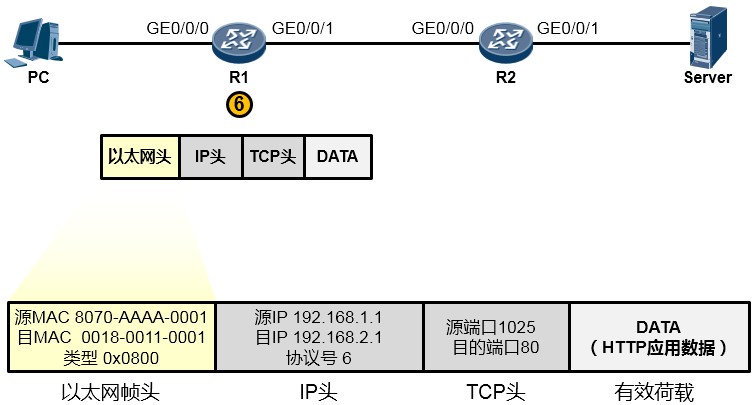
路由器R1在收到这一串的1010…后,先将他们还原成数据帧(如下图所示)。然后会采用相应的机制检查一下数据帧在传输过程中是否有损坏,如果没有损坏,那么就瞅瞅数据帧头部中的目的
MAC地址,看看目的MAC地址是不是我收到这个数据帧的GE0/0/0接口的MAC,结果发现正好是自己的MAC,那么它会很高兴,觉得这个数据帧是给它的,它查看数据帧头部的类型字段,发现是0x0800,于是它知道里头装的是一个IP包,接着它将以太网帧头剥去,或者说解封装,然后将里面的数据移交给上层的IP协议继续处理。
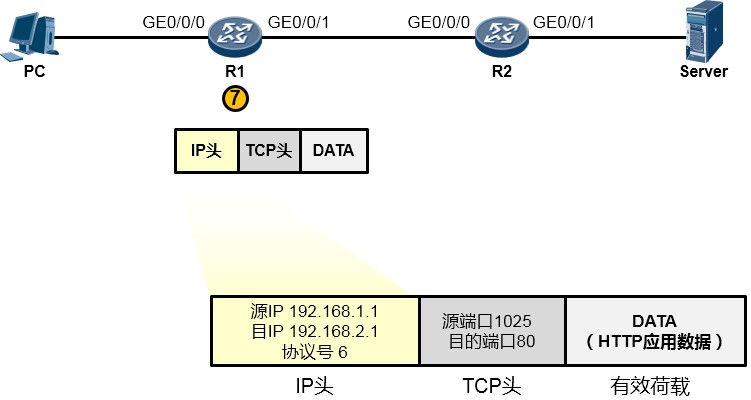
- 现在R1的IP协议栈接着处理这个报文。它会先校验一下数据在传输过程中IP报文有没有受损,如果没有,它就查看IP头中的目的IP地址(如下图所示),结果发现目的IP地址为192.168.2.1,并不是自己的IP地址——原来这个数据包是发给别人的,于是它开始拿着目的地址192.168.2.1到自己的地图(路由表)里去查询,看看有没有到192.168.2.1这个目的地的路径,结果发现有,并且这个路由条目指示它把数据包从从GE0/0/1口送出去,并交给192.168.12.2这个下一跳IP地址。于是它不再继续拆开IP头看里头的东东了,而是乖乖的将IP数据包往下交还给数据链路层去处理。
-
现在数据链路层继续处理上层下来的IP包,它为这个IP包封装上一个新的以太网帧头,帧头中源
MAC地址为R1的GE0/0/1口的MAC:0018-0011-0002,目的MAC是这个数据包即将交给的下一跳路由器192.168.12.2对应的MAC,当然初始情况下R1是不知道这个MAC的,因此又是一轮ARP请求广播及回应过程并最终拿到这个MAC:0018-0022-0001,于是它将这个值填写在目的MAC字段中。完成了新的数据帧封装后(如下图所示),R1把这个数据帧变成1010101…通过电气信号传递给R2。
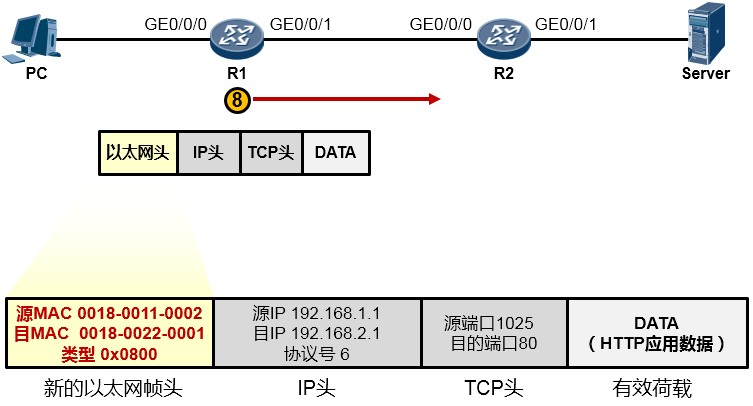
- R2收到这些10101…后,同样的,还是先将其还原成帧,然后查看帧头,发现目的MAC填写的就是自己接口的MAC,并且帧头中类型字段写的是0x0800(指示上层协议是IP,也就是数据帧头内封装的是一个IP包),于是将数据帧头剥去,将里头的IP数据包交给IP协议去处理。
-
而IP协议在处理过程中发现,目的IP地址并非本路由器的IP(如下图所示),于是它知道这个数据包不是发送给自己的,它拿着目的IP地址192.168.2.1在自己路由表中查询,结果发现,R2的
GE0/0/1口就连接着192.168.2.0/24网络,原来家门口就是了,于是它将这个IP包交还给下层协议去处理。
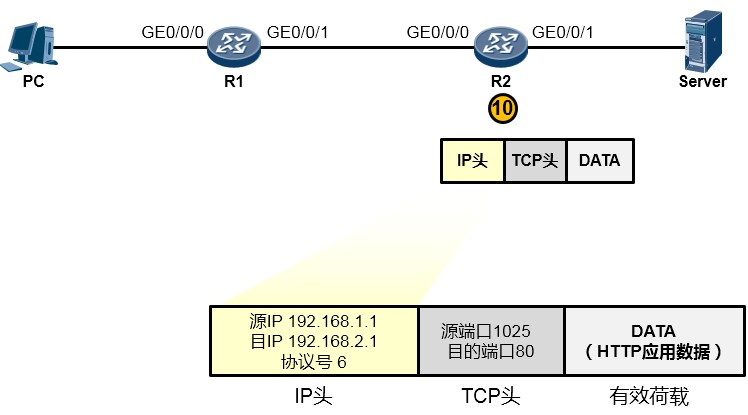
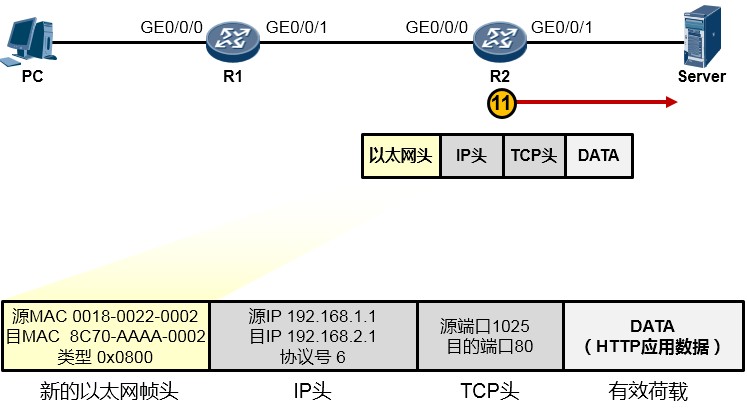
-
接下来又是重新封装成帧,R2为这个IP包封装一个新的数据帧头部,帧头中,源MAC为R2的
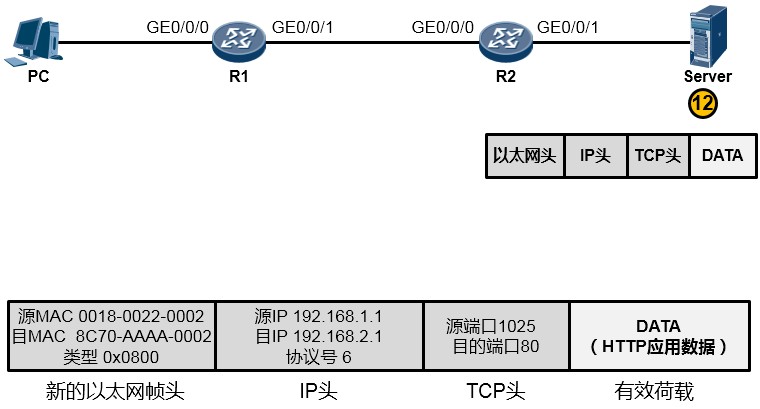
GE0/0/1口的MAC,目的MAC为192.168.2.1这个IP地址对应的MAC,如果ARP表里有192.168.2.1 对应的MAC,则直接将MAC地址写入目的MAC中,如果没有,则发ARP请求报文去请求该地址。另外类型字段依然填写0x0800。最终,R2将这个数据帧传给了Server,如下图所示:
- 好不容易,终于数据帧到达了Server(如下图所示)。Server首先将这些比特流还原成帧,然后做校验看看帧是否损坏,如果没有,则查看数据帧的目的MAC,结果发现就是自己的网卡MAC,于是查看类型字段,发现是0x0800,知道这里头装的是一个IP包,于是将帧头剥去,将内层的IP数据包交给IP协议去处理。IP协议层收到这个数据包之后,首先查看IP包是否损坏,如果没有,则查看目的IP地址,发现目的IP地址是192.168.2.1——正是自己的网卡IP,于是它知道,这个IP包是发给自己的,因此继续查看IP包头中的协议字段,发现协议字段填写的是6这个值,原来这个IP包头后面封装的是一个TCP的数据,于是将IP包头剥去,将里头的TCP数据交给上层的TCP协议处理。而TCP在处理这个数据的时候,查看TCP头部的目的端口号,发现目的端口号是80,而Server本地的TCP 80端口是开放的,开放给HTTP应用了,因此它将TCP头部剥去,将里头的载荷交给HTTP 应用。终于,从PC发送出来的HTTP应用数据到达了目的地——Server的HTTP应用的手中。
- IP 地址的概念及 IP 子网划分
什么是IP地址¶
-
IP地址在网络中用于标识一个节点(例如一台主机,或者一个网络设备的接口)。
- 在IP网络中,数据包的寻址是基于IP地址来进行的,因此IP地址就像是现实生活中的地址一样。
-
IP协议定义了IP数据报文的格式,也定义了数据报文寻址的方式。目前我们在业务环境中常见的IP
主要是两个版本:IPv4及IPv6,而现阶段网络主体仍然是IPv4,但是在可预见的未来,会逐渐向
IPv6过渡。本章只介绍IPv4。
-
一个IPv4地址有32bit。当然,我们不可能用二进制来书写IPv4地址,那是低效的,我们通常采用十进制格式来书写IP地址,但是计算机在进行IP地址的相关计算工作时,无疑是通过二进制的形式来进行。因此掌握十进制到二进制的数制转换是必备的技能。
- IPv4地址通常采用“点分十进制”表示,以适应人类的读写习惯,例如192.168.1.1。
十进制与二进制的转换¶
“点分十进制”IP地址表现形式能够帮助我们更好的使用网络,但网络设备在对IP进行计算时使用的是二进制的操作方式,例如:

以下是192这个数字,对应的二进制算法,这里就不再赘述了,这是基本技能。
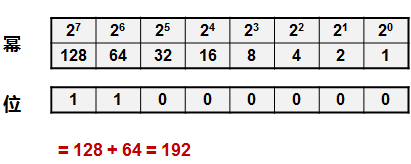
IP地址的分类¶
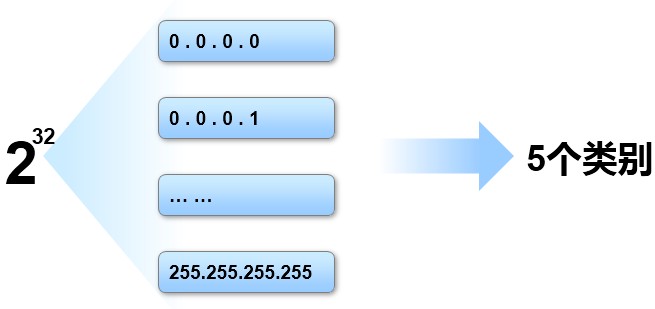
IPv4地址的长度为32bit,如上图所示,IPv4地址的空间从0.0.0.0 一直到 255.255.255.255,这么庞大的空间,如果不加以区分和规划,势必不便于统筹管理。因此我们对整个IPv4地址空间进行类别上的划分,一共分为5类:
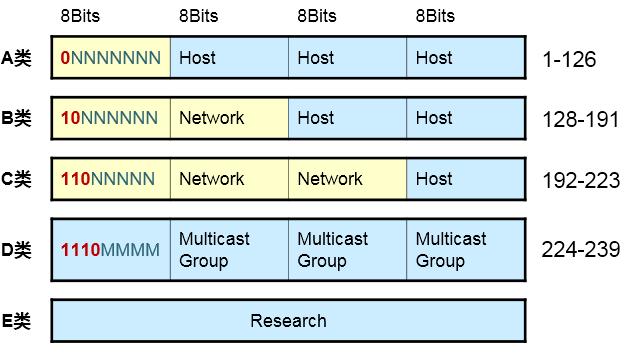
地址的类别上的区分主要体现在第一个八位组(一个IP地址拥有4个八位组)上:
-
第一个八位组首位恒定为0,那么我们就得到一个区间:0.0.0.0一直到127.255.255.255。这是A类地址,其中127.0.0.0/8作为本地回环使用,例如你ping 127.0.0.1实际上ping的是本机。所以如果看到一个IP地址,它的首个八位组掉落在1-126区间内,那么这是一个A类地址。
2) 第一个八位组的最高两位恒定为二进制的10,就得到一个区间:128.0.0.0-191.255.255.255,这是
B类地址。
3) 第一个八位组的最高三位恒定为110,就得到一个区间:192.0.0.0 – 223.255.255.255,这是C类地址。
4) 第一个八位组的最高四位恒定为1110,就得到一个区间:224.0.0.0 – 239.255.255.255,这是D类地址,这个类别的地址专门用于组播。笔者安排了专门的章节介绍组播的概念和应用。
5) 剩下的是E类地址,这类地址保留作为研究使用。
网络掩码(Network Mask)¶
一个IP地址包含两部分:网络部分以及主机部分。网络部分用于表示这个IP地址所处的“空间”,对于一台路由器而言,当它在为数据包寻址时,通常只关心IP地址的网络部分。那么如何区分一个IP地址中的网络与主机部分呢——网络掩码(Network Mask,简称netmask)用于和IP地址进行对应,从而标识出IP地址中的网络与主机部分。
- 网络掩码为32bit,与IPv4地址的位数是一样的。
- 网络掩码在二进制的表示上是一堆连续的1,后面接连续的0。
-
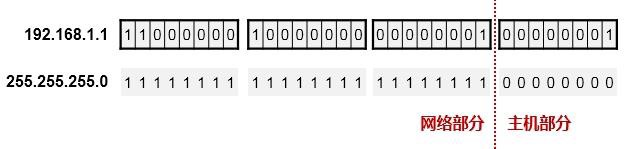 网络掩码值为1的bit对应IP地址中的网络位;为0的bit对应IP地址中的主机位,以此来识别一个IP 地址中的网络与主机位,如下图:
网络掩码值为1的bit对应IP地址中的网络位;为0的bit对应IP地址中的主机位,以此来识别一个IP 地址中的网络与主机位,如下图:为了方便书写,我们往往使用掩码长度的方式来表示一个IP地址+ 掩码组合,例如192.168.1.1
255.255.255.0 等同于192.168.1.1/24。因为255.255.255.0写成二进制的话,从左往右数就是24个1, 所以我们也说,它的掩码长度为24。
默认情况下,A类IP地址的首个八位组为网络位,其他位为主机位,因此A类地址的默认掩码就是
255.0.0.0,或者说掩码长度为/8。B类IP地址前两个八位组为网络位,后两个八位组为主机位,因此B 类地址的默认掩码就是255.255.0.0或者掩码长度/16。C类地址的前三个八位组为网络位,最后一个八位组是主机位,因此C类地址的默认掩码就是255.255.255.0,或者掩码长度为/24。从这里可以看出, 如果申请到一个A类地址段123.0.0.0/8,那么这是一个相当庞大的地址空间,因为这个空间有2的24次方个IP地址。相对的,一个B类的IP网络地址空间默认有2的16次方个IP地址,而每个C类地址段所拥有的主机数量则更少。
IP地址类型¶
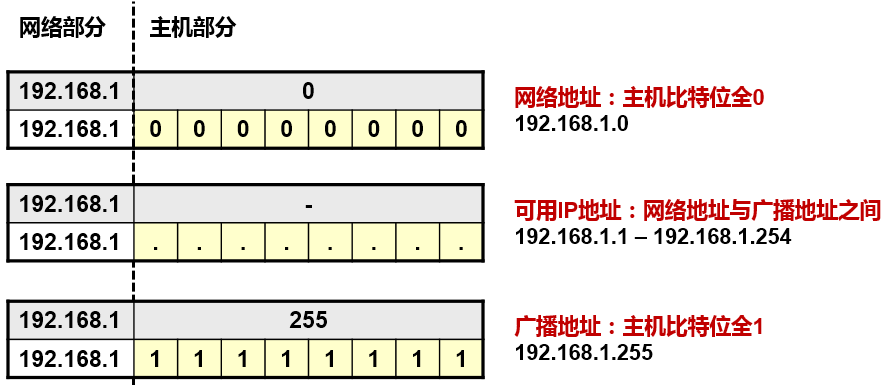
-
网络地址:用于标识一个网络,相当于一个“面”的概念。网络地址是一个IP地址中主机位为全0 的地址。例如192.168.10.0/24,该地址标识了一个网络,在这个网络中,存在多个IP地址,可用于分配给各种设备,例如192.168.10.1、192.168.10.2、…、192.168.10.254,这些地址都属于
192.168.10.0/24网络。网络地址不能够被分配给主机。
-
**广播地址:**用于向网络中的所有节点发送数据的特殊地址。广播地址即主机部分的各比特位全部为
1的地址。例如192.168.10.255/24,该地址是192.168.10.0/24这个网络的广播地址。
3) **节点地址:**可分配给网络中的设备的地址。例如192.168.10.1/24至192.168.1.254/24。网络地址及广播地址是不能够直接被分配给某个设备(的网卡)或者网络设备(的接口)的,因为它们有特殊用途。
例:192.168.1.0 这个C类地址对应的网络地址、广播地址及可分配IP地址分别是?
-
为什么要划分子网¶
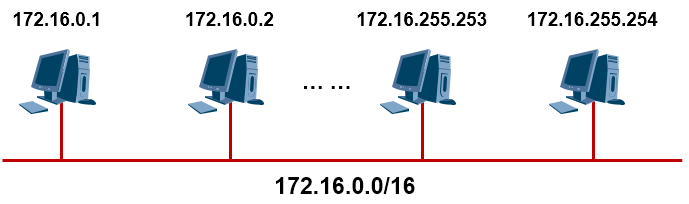
假设你有一个B类地址段172.16.0.0/16,由于B类地址的默认掩码是255.255.0.0,这就意味着这个网络内有2的16次方个IP地址,而可分配给设备使用的IP地址就有2的16次方-2这么多个,为什么要减去2? 因为广播地址及网络地址是不能分配给设备使用的。
设想一下,如果一个网络中真有这么多台PC,这么多个IP地址处于同一个网段中、同一个广播域中, 如上图所示,那么一旦网络中发生广播,影响可就大了。再者,在实际的业务环境中,我们往往会给一个业务单元(例如一个公司内的各个部门),划分一个独立的IP网段,不同的业务单元不同的IP网段, 那么如果有10个业务单元,每个业务单元才几十近百台设备,一个业务单元就耗费一个B类地址段,这就会造成IP地址的浪费。
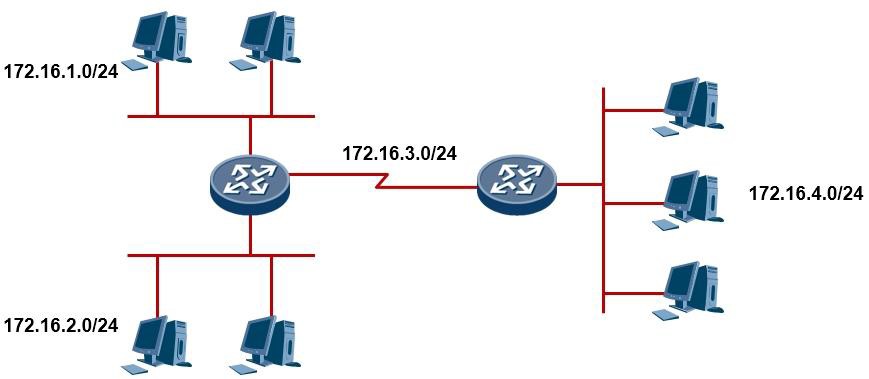
因此,我们提出子网划分的概念,子网划分所使用的思维是VLSM(Variable Length Subnet Mask,可变长子网掩码),事实上是拿网络掩码变戏法。在下图中有五个网段,需要五个IP地址段,如果只有一个B类地址(172.16.0.0/16)可用,那么通过子网划分,可以将这个B类地址划分成一个个小一点的子网。这样一来,一个庞大的网络就可以被分割成小的单元,另外IP地址的使用也更为科学更为合理。
如何划分子网¶
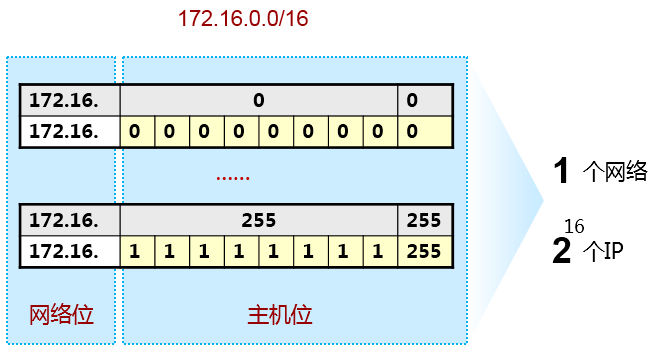
现在假设我们有一个B类地址段172.16.0.0/16,默认情况下,这个B类地址的掩码为255.255.0.0,前两个八位组是网络位,后两个八位组是主机位。那么这个单一的网络中,有2的16次方个IP地址,如上图所示,非常庞大。
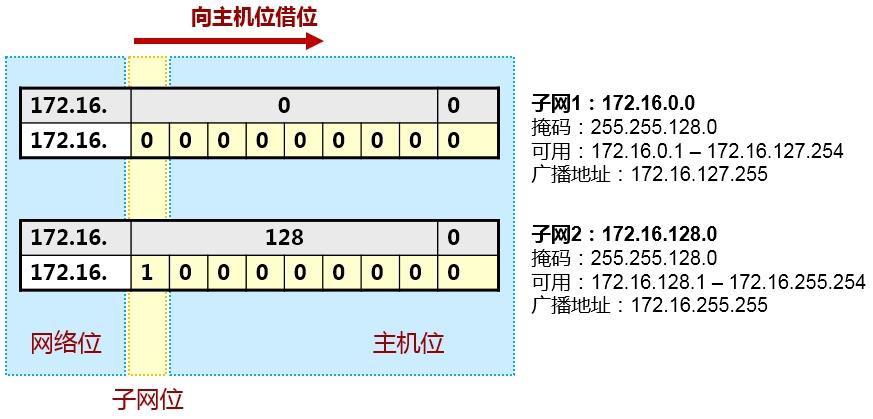
现在,在原有网络位的基础上,再向主机位借一个bit作为网络位的补充,网络位就扩充到了17bit,相对的主机位就变成了15bit。那么借过来的这一位,就是子网位了,如上图所示。由于我们借了这一位, 因此网络掩码就从默认的255.255.0.0变成了255.255.128.0或者说从/16变成了/17。
于是从原来的只有172.16.0.0/16的一个大网段,变成现在拥有172.16.0.0/17及172.16..128.0/17这两个小一点的网段,这就是子网划分。务必要关注网络掩码在这个过程中发挥的作用。
子网划分例子一¶
现在有一个IP地址:192.168.1.0,这是一个C类地址,默认的掩码是/24,我要对它做子网划分,向主机位借一位作为子网位,也就是掩码长度变成/25,那么我能得到几个子网?每个子网的网络地址是多少?每个子网的广播地址是多少?每个子网的可用IP地址范围是多少?
步骤如下:
判断类别,找默认掩码:¶

首先这是一个C类地址,因此默认的掩码长度为/24,你可以划一条竖线帮助计算。线的左边为网络位,右边为主机位,如上图所示。
变更掩码,找子网:¶
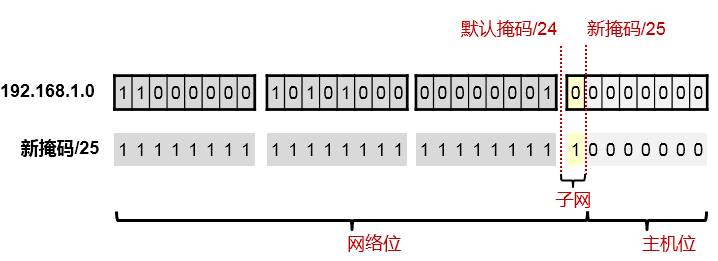
在原有的/24掩码基础上,向主机位借一位,掩码变成/25。借出来的这一位就是子网位,如上图所示,我们只要将虚线往右移动一格就行。这个子网位的值要么为0,要么为1,也就是存在两种可能性,这就创造了两个子网(2的1次方),子网位为0时,得到的子网地址是192.168.1.0/25,子网位为1时,得到另一个子网的网络地址192.168.1.128/25,如下图所示:
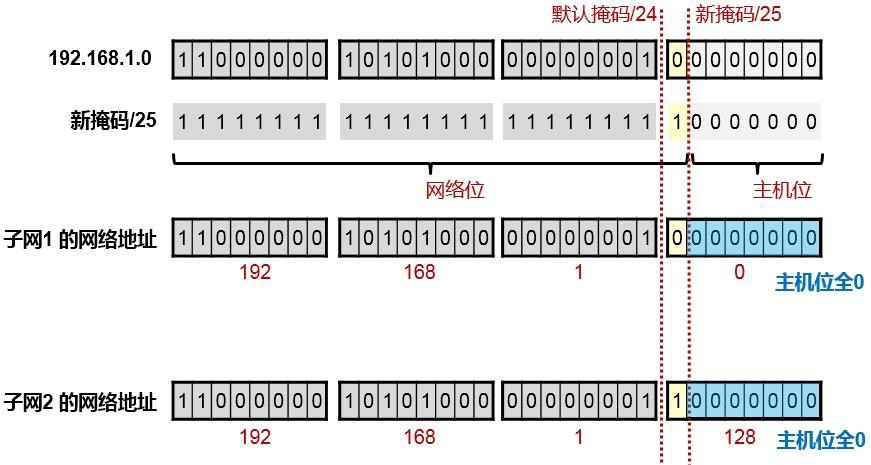
得出广播地址:¶
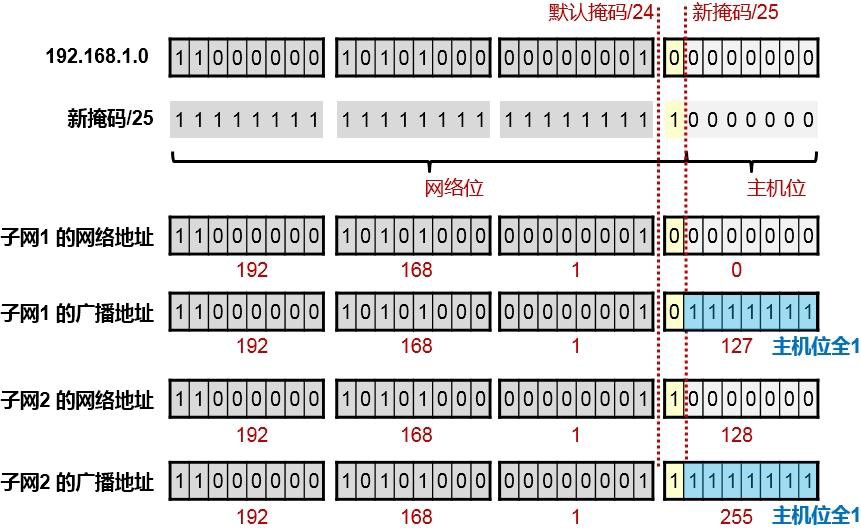
上面分别列出了子网1及子网2的广播地址,其实很简单,就是把各个子网的主机位全部置1即可。因此子网192.168.1.0/25 的广播地址为192.168.1.127 ;子网192.168.1.128/25 的广播地址为192.168.1.255;
得出每个子网的可用IP地址数量:¶
经过上面的计算,得出了子网1及子网2的网络地址和广播地址,那么每个子网可用的IP地址也就出来了,因为可用IP地址实际上就是该子网的网络地址与广播地址之间夹着的那些个IP地址。所以实际上我们对192.168.1.0/24这个C类地址段,用了一个变长后的子网掩码长度:/25,也就是向主机位借1位后产生出了2个子网,每个子网有126个可用IP地址。这里有个公式:

子网划分例子二¶
假设现在有一个IP地址:192.168.1.64/27,想把这个地址配置在一台PC上,是否可行?
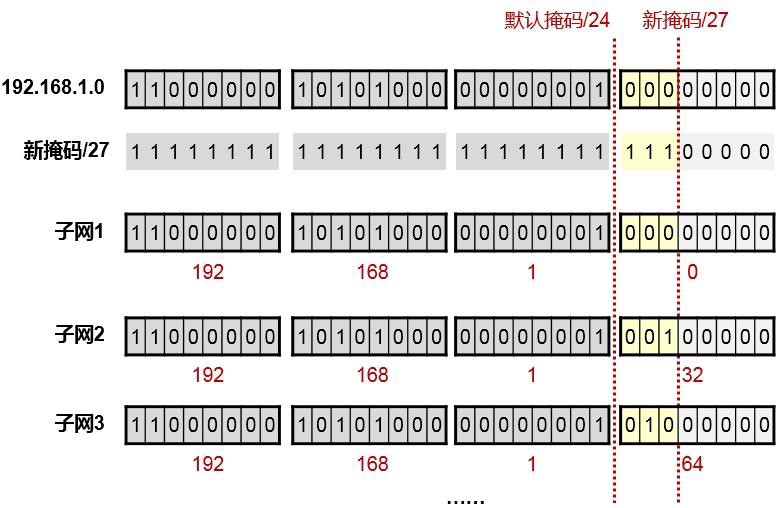
由于该地址的默认掩码长度为/24,而新掩码长度为/27,因此网络位向主机位借了3位,产生了8个子网,每个子网内包含的所有IP地址数量为32,也就是2的5次方(5是剩余的主机位数)。
现在开始把每个子网罗列一下,结果发现192.168.1.64/27这个IP地址,其实是其中一个子网的网络地址,既然是网络地址,当然是不能分配给PC用的了。
- VRP 基础
Versatile Routing Platform 通用路由平台,简称VRP,是华为数据通信产品的通用操作系统平台,它以IP 业务为核心,采用组件化的体系结构,在实现丰富功能及特性的同时,提供基于应用的可裁剪能力和可扩展能力。VRP其实就是运行在华为数通产品上的操作系统,就像Windows系统对于PC,iOS系统对于苹果终端。我们调试VRP系统的数通设备最常用的方法就是通过命令行界面(CLI):
下面我们初步了解一下VRP的命令行界面:
命令视图(View)的概念¶
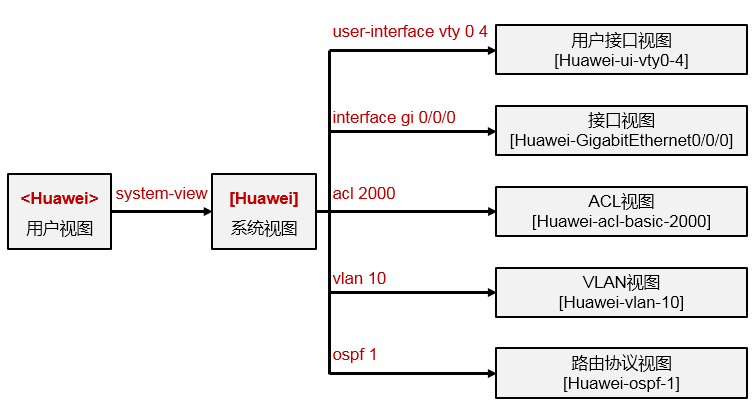
VRP的命令行界面定义了各种命令视图(View),要对特定协议或者功能进行配置就需要进入到相应
的视图。视图的定义使得命令行的配置更模块化,也更严谨、更层次化。例如一台路由器有多个接口, 如果要修改某个接口的IP地址,那么就需要进入该接口的配置视图,然后进行配置,而在这个接口的配置视图中执行的相关命令,只会影响该接口。因此VRP规定,在适当的视图下执行适当的命令。
刚登陆设备时在命令行界面你可能会看到“\<Quidway>”或者“\<Huawei>”这样的提示符,“\<>”尖括号提示你当前所处的视图是“用户视图”,而“Quidway”或“Huawei”是该设备的名称,当然设备名称是可以修改的。在不同的视图下我们会看到不同的提示符。例如上图所列举的几种视图以及进入该视图使用的命令。从当前视图进入到下一级视图需要使用相应的命令,从当前视图退回到上一级视图可使用“quit”命令:
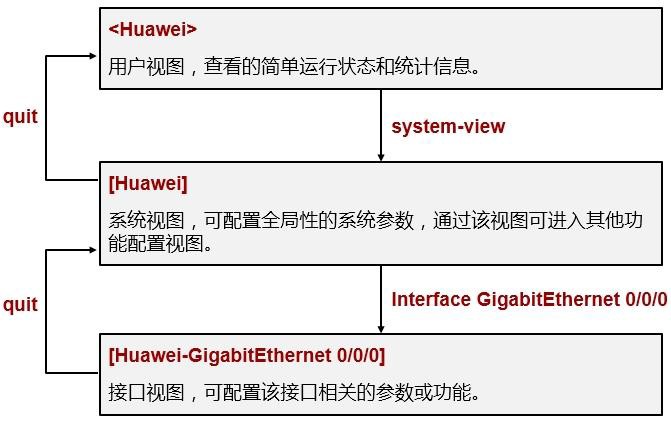
基本命令结构¶
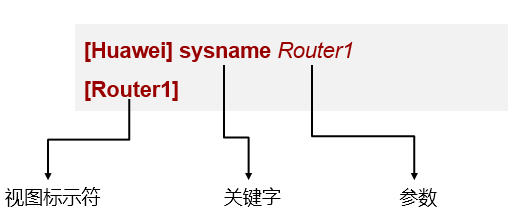
在命令行界面中,通过输入特定的命令及参数来完成对设备的调试,例如上面的例子, sysname
Router1,这条命令中“sysname”是关键字,而“Router1”是参数,这条命令的意思就是将该设备的名称修改为Router1,命令输入完毕后按回车,就会发现系统的提示符发生了改变,变成了“[Router1]”。这条命令需要在系统视图下完成,如果在用户视图下尝试输入这条命令,则会报错。
使用命令行的帮助功能¶
命令提示:¶
在设备的配置过程中,由于命令较多,出现记忆模糊的情况非常正常,VRP的命令后界面为我们贴心地提供了命令提示功能,当一条命令中某个关键字只记得开头的几个字母时,可在键入开头字母后紧接着键入“?”问号,例如“ip rou?”,注意在问号前面没有空格,系统即会自动弹出提示信息,提示当前“rou”这三个字母开头的关键字有哪些:
还有一些情况,可能是当前关键字输入完毕后,忘记了下一个关键字或者参数该输入什么,那么就
可以在当前关键字输入完毕后键入空格,然后再输入一个“?”,系统会自动弹出可选择的关键字或参数的提示信息:
命令补齐:¶
输入命令时,关键字无需完整输入,例如要输入“system-view”,可先输入“sys”,然后按tab 键,系统会自动补齐sys开头的关键字,如果sys开头有多个关键字,可以多次按tab键切换到自己想输入的那一个:
在命令弄熟悉之后,其实可以采用简化的命令书写方式,例如“interface gigabitEthernet 0/0/0”
等同于“int g 0/0/0”,采用后者来配置设备,工作效率大大提升,当然逼格也跟着瞬间提升了好几个档次。
语法检查¶
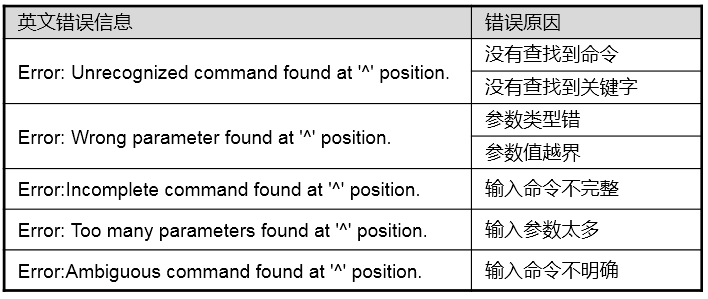
CLI的语法检查功能帮助我们发现命令中的错误:
[Huawei]a
其他的提示如下:
基础配置命令¶
修改设备名称:¶
配置设备的接口:¶
这里GigabitEthernet0/0/0指的是千兆接口GE0/0/0,其中GigabitEthernet表示千兆以太网接口,另
外,后面的三个数字分别是“槽位号/子卡号/接口序号”,具体的含义如下: 槽位号:表示该接口所属单板所在的槽位号。
子卡号:表示该接口所属的子卡号。
接口序号:表示接口在板卡上的编排顺序号。
管理及维护设备配置:¶
\<SW1> save 在设备上的每一个配置操作,都会记录在设备的当前配置“current-configuration”之中,也就是当 前运行中的配置,这个配置文件是保存在动态内存中的。可以使用**display current-configuration** 命令查看当前运行中的配置。
设备重启之后current-configuration将会丢失。因此为了保证设备重启后不丢失当前已经完成的配置,则要在配置变更后,将current-configuration保存到saved-configuration,也就是保存到启动配置文件,这样的话,设备重启后将会读取已保存到硬盘中的启动配置文件,然后将其加载到当前配置中运行。使用**save**命令来将current-configuration保存到启动配置文件,**save**关键字如果不指定可选参数configuration-file(文件名),则配置文件将保存为“vrpcfg.zip”。“vrpcfg.zip”是系统缺省命名的配置文件,初始状态是空配置。
另外,如果要清除已保存的启动配置文件,使得下次设备重启后能恢复出厂配置,可使用如下命令:
\<SW1> reset saved-configuration
如果要备份已保存的启动配置文件,可使用如下命令:
\<SW1> copy flash:/vrpcfg.zip flash:/cfgbackup.zip
- 使用 Console 接口管理设备
一般来说,网络设备(例如路由器、交换机、防火墙等)在设备面板上都会有一个用于配置和管理的专用接口 – Console口(或CON口),通过这个接口,并使用专用的线缆将该设备与PC(网络管理员所使用的电脑)进行连接,即可实现对设备的配置及管理。
对设备上线前的初次配置及管理,往往采用此种方式。我们通过以下四个步骤来了解一下如何使用Console 口对设备进行管理及配置:
- 认识设备的Console口。
- 准备好相关线缆。
- 搭建配置环境。
- 通过终端管理软件登陆设备。
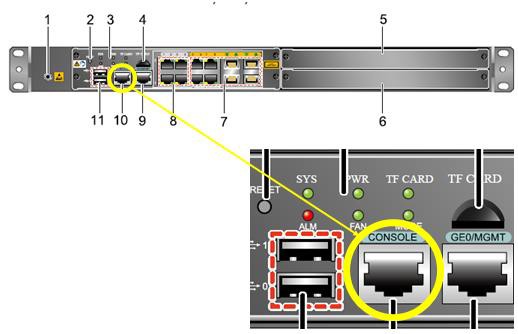
认识设备的Console口¶
华为网络设备面板上的Console口都有做相关标记,比较容易识别,如下图(以防火墙E1000E为例)。
准备好相关线缆¶

Console线缆(上图右侧的线缆)一端为RJ45水晶头,一端为串口接头。RJ45接头用于连接网络设备的Console口,线缆另一端的串口用于连接PC,现在大部分台式PC在主机箱后都有串口可以直接连接
Console线缆。只要将被配置设备与PC按照上述方式进行连接,就完成了配置环境的搭建。环境完成后,在PC上使用终端管理软件即可通过网络设备的Console接口、使用命令行的方式对设备进行管理。
但是大部分笔记本电脑上并没有串口,因此如果使用没有串口的笔记本电脑调试网络设备,则需要另一根线缆来转接,这就是上图左侧所示的USB-RS232的线缆,这根线缆可以说是网络工程师必备的工具, 各大电子产品商铺均有销售(USB-RS232需要安装驱动才可使用,驱动程序安装包随线缆附送)。
搭建配置环境¶
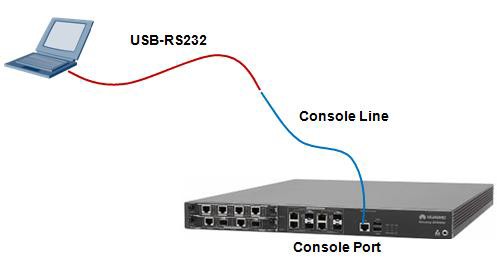
如果使用笔记本电脑来配置路由器、交换机或者防火墙,则可参考如上图所示的线缆连接方法。将USB-
RS232线缆的USB接口接到笔记本电脑上,同时线缆的另一头连接Console线的串口,Console线的另一端,也就是RJ45水晶头这一端则接到设备的Console口上。
通过终端管理软件登陆设备¶
在PC上,我们需要准备好终端管理软件,用于管理和配置网络设备。常用的终端管理软件有:Windows 自带的终端管理工具(WIN7系统没有自带该工具)、SecureCRT以及Putty等。本文档以SecureCRT 为例做讲解。请自行下载SecureCRT并安装。安装完成之后,打开软件。
在自动弹出的Connect对话框中选择下图所示的按钮来创建一个连接:
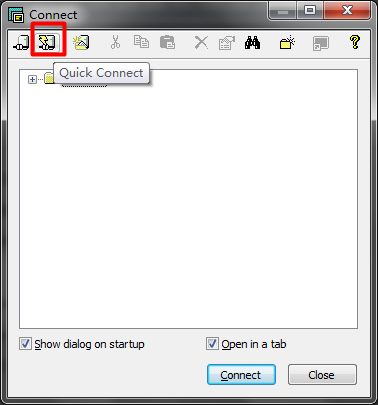
在弹出的Quick Connect对话框中选择“serial”,即使用串行接口管理设备:

进一步配置如下:

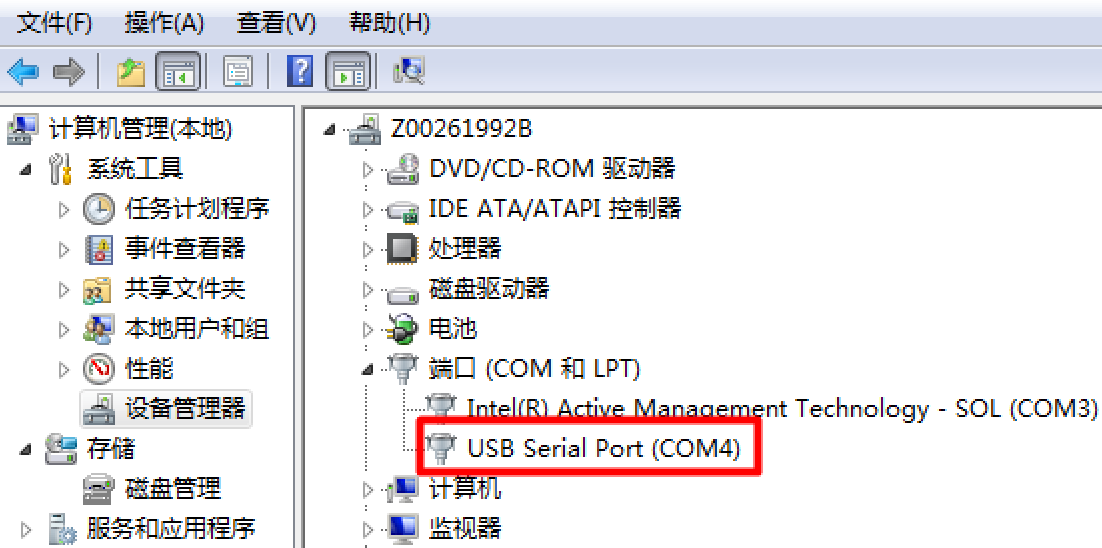
注意在此处,Port的选择视个人情况而定,当用笔记本通过USB-RS232线缆接Console线管理设备时, USB-RS232线缆是需要在PC的windows系统上安装驱动程序的,安装完成的结果是在系统中会出现一个通过USB接口模拟的COM口,而该COM口的编号可在右键“我的电脑”-“计算机管理”-“设备管理”-“端口(COM和LPT)”中看到,此处显示的编号要与SecureCRT中选择的Port对应:
另外,Band Rate也就是波特率,这一项要看设备Console口的默认参数而定,我司的大部分路由、交换及防火墙设备此处设置的值都是9600。
完成后点击“Connect”即可登陆设备。当然,第一次使用Console登陆设备才需要依照上述步骤来操作,往后再次登陆,则可使用上面已创建好的连接方式快速登陆。
- eNSP 华为官方数通模拟器
eNSP(Enterprise Network Simulation Platform)是一款华为自研的、免费的、可扩展的、图形化操作的网络仿真平台,主要对企业网路由器、交换机及防火墙等设备进行软件仿真,完美呈现真实设备实景,支持大型网络模拟,让广大用户有机会在没有真实设备的情况下能够模拟演练,学习网络技术。
eNSP下载链接:点击此处。或者在http://enterprise.huawei.com/搜索eNSP即可找到eNSP软件下载页面。
eNSP的安装非常简单,安装完成后打开软件即可看到主界面。软件的操作也比较简单,需要什么设备就直接从设备栏拖动图标然后在拓扑画布上松开即可。完成拓扑的搭建和连线后,点击工具栏中的绿色播放按钮即可经设备开启。等待设备完成开启后,双击设备即可进入CLI控制台进行配置了。
eNSP不仅支持AR路由器、S57/S37交换机、USG5500防火墙等主流数通设备的模拟,还支持无线设备, 以及DNS、FTP、HTTP服务器和客户端模拟等,更加支持模拟器与物理网卡的桥接,使得实验的扩展性
得到极大的提升。目前,华为数通认证HCIE RS的TroubleShooting考试也是使用NSP软件进行。接下来我们看一个例子,使用eNSP完成第一个实验。
实验拓扑¶
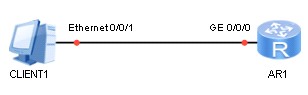
目标网络拓扑如上图所示:一台PC与一台路由器通过网线直连。
现在我们要在eNSP中搭建这个实验环境,并且完成PC和路由器的配置,使得PC能够访问路由器(能够ping通路由器)。为PC配置的地址是192.168.1.1/24,网关地址是192.168.1.254;为路由器的GE0/0/0接口配置的地址是192.168.1.254/24。
环境搭建¶
使用eNSP搭建上述环境是非常简单的。新建一个实验后,从左侧的设备列表中选择“路由器”,如下图所示:
此处有多种型号的路由器可以选择,在本实验中,我们挑选的是AR2220,因此用鼠标左键点住AR2220
的图标不放,然后拖动到画布中再松开即可:
接下来继续添加PC,点击设备列表里的“终端”类型,选择PC,然后拖放到画布上:
接下来完成设备的连线,在左侧设备列表中选择“设备连线”图标,在线缆列表中选择铜缆“Copper”:
点选成功后,鼠标指针会发生变化,随后在交换机和PC上分别点击并选择相应的互联接口,即可实现
设备相应端口之间的连线:
如此一来拓扑就搭建完成了,现在点击工具栏上的启动按钮:

上面的按钮点击后会将所有设备启动。如果实验拓扑比较大,建议不要使用上面的启动按钮集体启动设备,可以对设备进行逐台启动,也就是分别对设备点击右键,然后选择启动。待所有设备都启动完毕后即可开始实验。
配置实现¶
首先完成路由器的配置,双击路由器的图标即可打开命令行界面:

此时打开的便是AR1的命令行界面,在该命令行界面中完成对路由器的基本配置,如下:
接下来开始配置PC,双击Client1,在出现的配置界面中如下填写:

填写完成之后,点击应用即可。接下来就可以进行连通性的测试了,双击PC的图标,选择“命令行” 选项卡,然后就能看到CMD界面,在CMD界面中我们可以进行基本的ping、tracert等操作,例如测试
PC到路由器的联通性,可以ping 192.168.1.254:
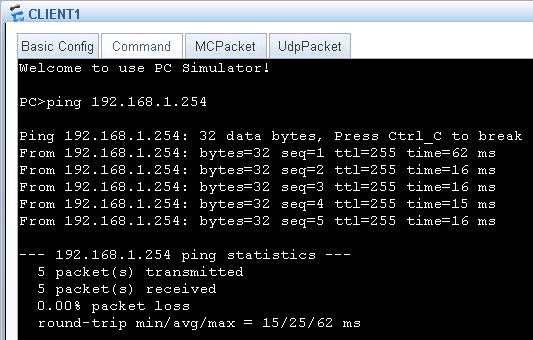
从ping的回显能看到,PC现在能够ping通路由器了,到此实验就成功了。
eNSP能够保存实验拓扑及配置以便下次继续进行操作,非常的方便。如果需要保存实验环境以及拓扑中各设备的配置,则在完成实验操作后,先为实验拓扑中每台设备(PC、Client无需做这个操作)使用
**save**命令保存配置(注意,务必要先在设备的CLI界面中使用save命令保存配置):
\<huawei> save
然后再点击eNSP工具栏的“保存”按钮将拓扑及配置文件保存在指定目录即可。
交换基础¶
- 二层交换基础
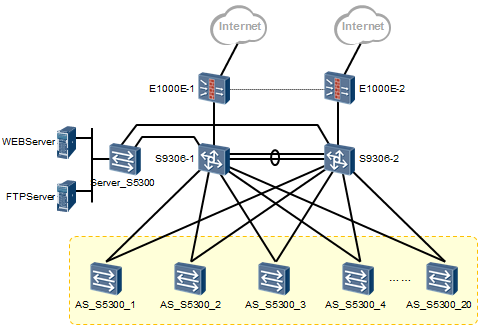
一个典型的数据网络是由路由器、交换机、防火墙、负载均衡器等网络设备构成的。其中交换机一般来说是距离终端设备(PC、服务器等)最近的网络设备,例如上图中黄色背景所标注的设备。
网络接入层(可以理解为在一个网络中,用于终端设备接入的逻辑层次)的交换机一般为二层交换机,所谓的二层交换机指的是针对数据的二层头部(以太网帧头)中的MAC地址进行寻址并转发数据的交换设备。二层交换机不具备路由功能,它工作在OSI七层模型的第二层,因此被称为二层交换机。
二层交换是以太网技术的一个非常基础的概念。那么什么是以太网二层交换(Layer 2 Switching)呢?
为了将内网中的多台PC互联起来,使得PC之间能够以最简单的方式进行通信,我们往往会用一台二层交换机来连接PC,如下图:

在上图中,PC1、PC2、PC3与PC4连接在同一台以太网二层交换机(后续简称为二层交换机)上,我们可以笼统地说,连接在这台交换机上的PC都属于同一个LAN。这些PC都拥有同一个网段的IP地址,同时也处于同一个广播域(Broadcast Domain)中,所谓的一个广播域,指的是一个广播数据所能泛洪的范围,举个简单的例子:PC1发送一个广播数据帧,交换机收到这个广播数据帧后,会为除了接收该数据帧的接口之外的其他所有接口都拷贝一份然后发送出去,接在同一交换机上的所有的PC都会收到这个广播数据帧并且都要去分析它(即使它们可能并不需要这个数据并且最终将收到的数据帧丢弃,但check数据的过程仍然会消耗设备资源),因为它们属于同一个广播域。
现在来分析一下,PC1发送一个数据给PC4时,都发生了什么,以此来理解二层交换的工作机制。
-
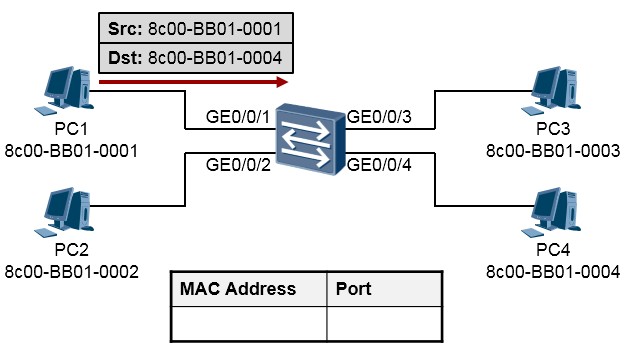
PC1构造IP数据包,IP报文头部里的源IP地址为自己的网卡IP地址,目的IP地址为PC4的IP地址。上述
IP数据包为了能够在以太网环境中传输,还需要封装一个以太网的头部(帧头)。在以太网头部中源
(Source,Src)MAC地址为8c00-BB01-0001,目的(Destination,Dst)MAC地址为8c00-BB01-0004, 如下图所示。
下图只描述了数据帧的帧头(源、目的MAC地址字段),对于IP包头以及数据载荷部分不在图中描述。
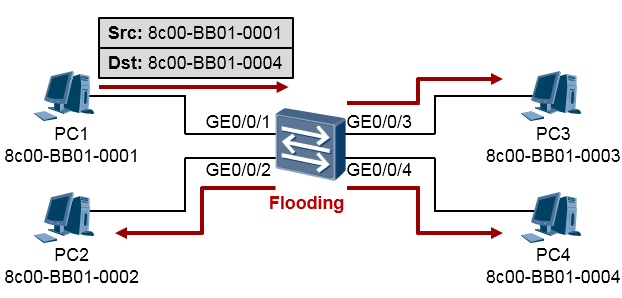
- 这个数据帧被发送到了PC1所连接的交换机上。我们知道路由器都维护了一张路由表,用于指导数据转发,而交换机在做二层交换的时候依据的是**MAC地址表(MAC Address Table)。MAC地址表中包含的表项指示出MAC地址与交换机某个接口的对应关系。在初始情况下,交换机的MAC地址表是空的。当交换机收到PC1发送出来的这个数据帧时,它首先在自己的MAC地址表中查询该帧的目的MAC地址, 由于此时在MAC地址表中,并没有8c00-BB01-0004这个地址的条目,因此交换机将对这个数据帧进行**泛洪Flooding,所谓泛洪就是将这个数据帧从除了收到它的接口之外的其他所有接口都发一份拷贝。这样做的目的事实上是:“哥不知道你在哪,哥索性就全都发一份,碰碰运气”。如下图所示:
-
接下来,交换机将该数据帧的源MAC地址(也就是PC1的MAC地址)学习到MAC地址表中,与接口
GE0/0/1进行关联。这样,交换机就学习到了一个MAC地址条目。通过该条目,交换机知道8c00-BB01-
0001这个MAC地址,连接在GE0/0/1接口,如下图所示:
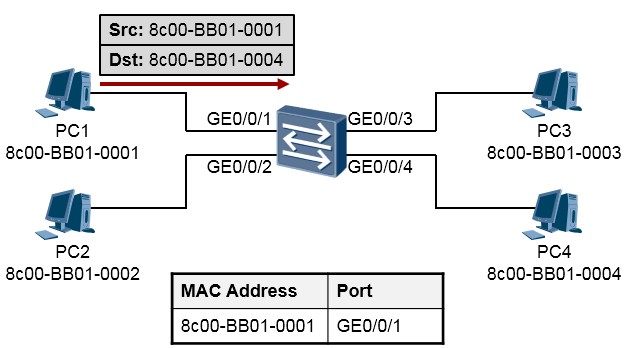
-
由于交换机的泛洪行为,导致连接在该台交换机上的其他PC都会收到这个数据帧,除了PC4之外的其他PC在收到这个数据帧之后,将bit流还原成帧并查看帧头部的目的MAC,发现该MAC与本机的MAC 并不一致,因此判断这个数据帧并非发送给自己,于是丢弃之。而PC4在收到这个数据帧并查看目的
MAC发现,这个数据帧的目的MAC与自己的MAC是相同的,因此判断这个数据帧是发送给自己的,于是进行CRC校验(校验数据帧的完整性),校验成功后将以太网头部解封装,将内层的IP数据将给IP协议栈处理。然后,进一步查看IP头部,发现IP头部中的目的IP地址就是本机的IP,于是将IP头部解封装, 将内层的载荷交给上层协议处理。如此一来PC1发送给PC4的数据就完成了传输。
-
现在,PC4要回送数据给PC1,数据的构造如下图所示:
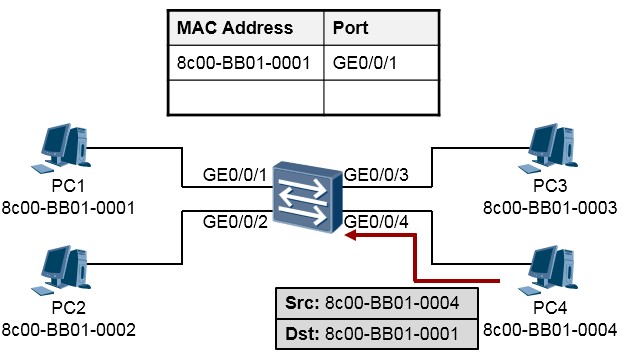
-
交换机在收到这个数据帧后,首先在自己的MAC地址表中查询目的MAC地址8c00-BB01-0001,发现有一个匹配的表项,而且该表项指示这个MAC地址连接在GE0/0/1接口上,于是交换机将这个数据帧从
GE0/0/1接口发送出去。同时交换机还会将数据帧的源MAC地址8c00-BB01-0004学习到自己的MAC地址表中,并与接口GE0/0/4进行关联,如下图所示:
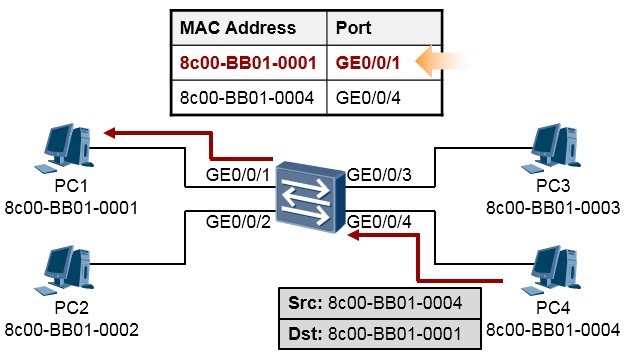
-
这个数据帧最终被PC1接收到,这就完成了一个在以太网环境中的数据交互过程。
小结一下:所谓的以太网环境中的二层交换,就是指的当一台交换机收到一个数据帧时,分析数据帧头部的目的MAC地址,在MAC地址表中查询这个MAC地址,如果有匹配项,则将数据帧从该匹配项所关联的接口转发出去;如果没有匹配项,则将数据帧进行泛洪。所以:以太网二层交换是基于数据帧的帧头中的目的
MAC地址进行查询的,并且是在MAC地址表中进行查询。所以掌握MAC地址表的查询及阅读是非常有必要的,在华为交换机上,可使用**display mac-address**命令可看到MAC地址表。MAC地址表是交换机能够正常工作的非常基础的数据表。
-
VLAN 及 Trunk
- VLAN 的基本概念
对于一台二层交换机来说,缺省时整机的所有接口属于一个广播域。这意味着,只要连接到这个交换机的
PC都配置在同一个IP子网内,即可直接进行互相访问,而且更重要的一点是,处于同一个广播域内的某个节点只要发送一个广播数据帧,在这个广播域内的所有其他节点都会收到这个数据帧,并且耗费资源来处
理(即使它可能并不需要这个数据帧)。当这个广播域变得特别大(交换机上连接的用户数量特别多)时网络就非常有可能被大量的广播消耗掉大量资源。
另一方面,实际的网络中经常存在这样的需求:连接在同一个交换机上的用户有可能是不同的业务单元或者部门的,用户希望对它们进行隔离,或者以独立的网络单元进行管理。
基于上述需求,引入了VLAN的概念,所谓VLAN,也即Virtual LAN,是一个虚拟的、逻辑的LAN,通过VLAN
技术,可以在交换机上,根据接口等信息进行VLAN的划分,从而实现设备的隔离。
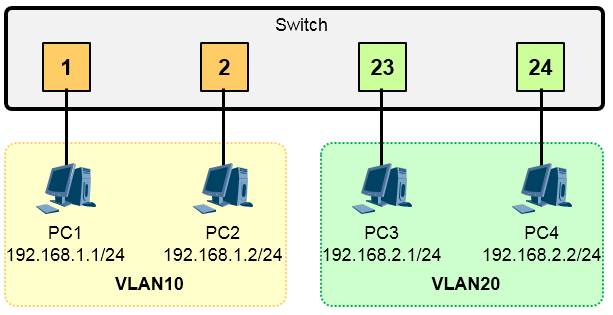
在上图中,用户在交换机上创建了2个VLAN,然后将相应的接口添加到指定的VLAN中——将接口1、2添加到了VLAN10,将接口23、24添加到了VLAN20。这样一来,接口1、2所连接的PC就加入了VLAN10,它俩处于同一个LAN、同一个广播域内,这些PC只要配置同一个网段的IP地址,就能够直接进行互访了(我们将这种通信称为二层互通)。而接口23、24处于VLAN20,即处于另一个LAN、另一个广播域。属于VLAN20 的PC之间能够直接进行互访。不同的VLAN之间,用户是被隔离的(除非借助路由设备,此时,这种这种通信行为就是三层通信了),当然,一个VLAN内的广播数据帧并不会被泛洪到另一个VLAN,因为它们属于不同的广播域。
有了VLAN技术,网络设计将更加灵活。VLAN是一个虚拟的LAN,不受地理环境的限制。我们可以根据实际的业务需要,灵活地进行VLAN的规划,例如将不同的业务部门规划到不同的VLAN中。另外,VLAN还可以跨交换机实现,因此VLAN的成员,例如业务PC,所处的位置就非常灵活了。
下面做一个小结:¶
- 一个VLAN中所有设备都在同一广播域内,不同的VLAN为不同的广播域;
- 相同的VLAN内的用户可以直接进行通信,这种通信被称为二层通信,而不同的VLAN之间互相隔离, 广播数据不能跨越VLAN传播,因此不同VLAN之间的设备一般无法直接互访,需通过具备三层路由功能的设备(例如路由器、三层交换机或防火墙等)实现相互通信;
- 一个VLAN一般使用一个逻辑子网(或者说一个IP子网);
- VLAN中成员多基于交换机的接口分配,此时划分VLAN就是将交换机的接口分配到特定的VLAN中;另外,华为交换机也支持基于IP地址划分VLAN等其他VLAN划分方式。
- VLAN工作于OSI参考模型的第二层;
- VLAN是交换机的一个非常基本的工作机制。
- Access 类型的接口
交换机的物理接口缺省都是二层接口,所谓的二层接口,简单的说就是不能直接配置IP地址、不能隔绝广播、无法直接处理IP数据包三层头部的接口,这种接口只能根据数据帧的头部信息进行帧处理。在华为的交换机上,二层接口的链路类型(Link type)有:Access、Trunk和hybrid三种,以S9300交换机为例,其接口缺省为hybrid类型。
VLAN是二层交换机的一个底层技术,二层交换机工作的方方面面都可能与VLAN有关系,包括接口的工作。我们需要根据实际需要,将交换机的接口设置为适当的类型。
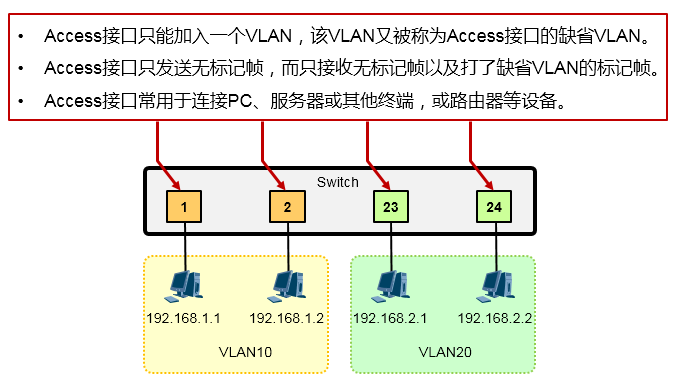
Access类型的接口只能加入一个VLAN,这种类型的接口一般用于连接PC、服务器等终端设备,或者连接路由器、防火墙等设备,如下图所示。Access接口只能发送不带标记的数据帧(也就是untagged帧),通常也只接收untagged帧。
- Trunk 类型的接口
在一台交换机上,可以创建多个VLAN以便对应不同的业务,然后基于交换机的接口,将不同的接口划分给不同的VLAN。
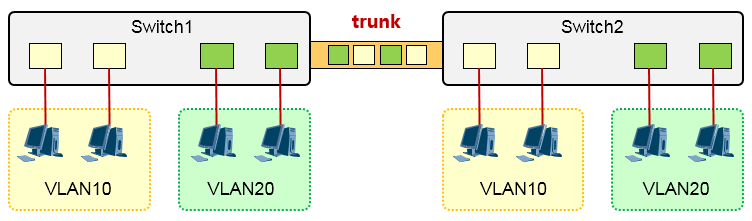
如果分别在两台交换机上部署了VLAN,并且做了统一性的VLAN规划,这时两台交换机对接的时候就需要谨慎,因为这两台交换机之间互联的链路需要承载多个VLAN的数据,如果某个特定VLAN的数据从一台交换机发送出来,经过交换机之间的链路到达另一台交换机,后者如何判定这个数据到底应该放入哪一个
VLAN呢?这里就需要一种“标记”手段。在将数据送出这个互联接口前,给数据做上相应的标记(Tag) 来标记这个数据是从哪一个VLAN跑出来的(如上图所示),这样,对端交换机在收到这个数据之后,就能够根据前者对数据所做的标记来识别数据究竟是属于哪一个VLAN的。此时,我们称两台交换机之间的互联链路为一段干道链路。这里提到的“标记”手段,常被称为干道协议,一个众所周知的公有标准是802.1q, 或者叫Dot1q,由于是公有标准,因此所有的交换机厂商都遵循该标准。
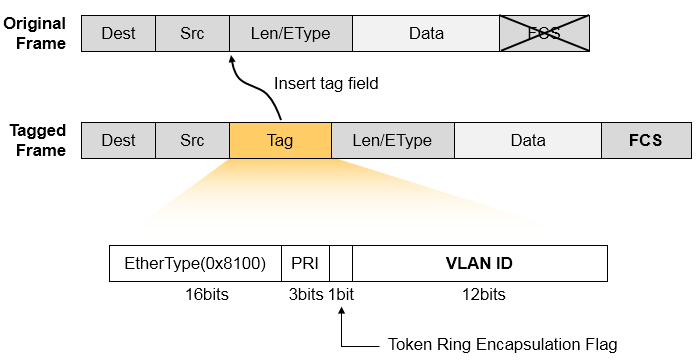
Dot1q针对数据帧的处理方式很简单,就是在原始的以太网数据帧头中插入一个Dot1q的字段,同时重新做
CRC校验。在插入的Dot1q字段中,就有VLAN-ID字段用来指示这个数据帧所属的VLAN,我们将没有携带Dot1q Tag的数据帧称为原始以太网数据帧或无标记帧(Untagged Frame),将携带了Dot1q Tag字段的数据帧称为标记帧(Tagged Frame),如下图所示:
- 接口类型小结
以太网交换机的二层接口类型¶
华为交换机的二层接口支持三种链路类型(Link type),当接口工作在二层模式时,必须使用这三种类型中的一种:
Access:¶
Access接口常用于连接PC、服务器或其他终端,或路由器等设备。Access接口只能加入一个VLAN, 一旦加入特定VLAN后,该接口所连接的设备也就加入了该VLAN。
Trunk:¶
Trunk接口一般用于交换机之间连接的端口,trunk口可以加入多个VLAN,可以接收和发送多个
VLAN的Tagged帧。当交换机的接口连接的对端设备(例如路由器或防火墙)的接口部署了以太网子接口,那么在这种场景下,交换机的接口也需配置为trunk类型(或者Hybrid类型)。
Hybrid:¶
可以用于交换机之间连接,也可以用于接用户的计算机,hybrid口可以属于多个VLAN,可以接收和发送多个VLAN的Tagged帧。可根据需求灵活设置特定VLAN的数据帧在发送时是否打标记
(Trunk接口只能设置一个VLAN在发送数据帧时不打标记,而hybrid接口则可设置多个VLAN在发送数据帧时不打标记)。
接下来,我们看看各种类型的接口在收、发数据帧时的特点。
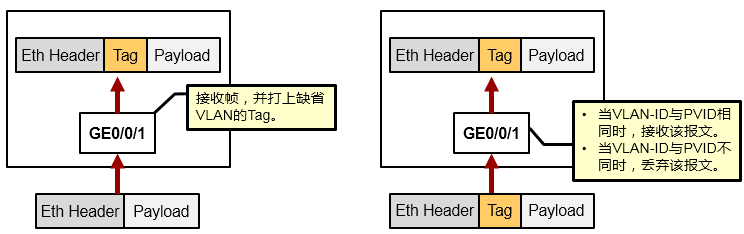
Access口接收帧¶
- 如果该帧是Untagged帧,则接收帧并打上接口的PVID(也就是该Access接口的default vlan或缺省VLAN);
- 如果该帧是Tagged帧,则当其VLAN-ID与接口PVID相同时,接收该帧,否则丢弃。
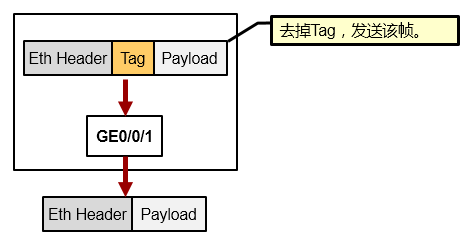
Access口发送帧¶
在发送数据帧时,剥离其Tag,发出的帧为原始以太网帧,也就是Untagged帧。
由于Access接口通常用于连接终端设备,而终端设备通常是只能够识别Untagged帧的,因此Access接口在发送数据帧时,始终是不会携带标记的。
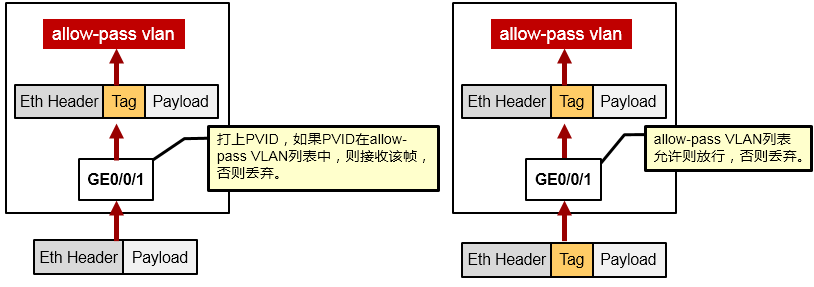
Trunk口接收帧¶
若收到的数据帧是Untagged帧,则为数据帧打上接口PVID的标记,然后,如果PVID在接口允许通行
(Allow-pass)的VLAN列表里,则接收该帧,若PVID不在允许通行的VLAN列表里,则丢弃。缺省时,Trunk接口的PVID为1,而且VLAN1缺省已经在允许通行的VLAN列表中。
若收到的数据帧是Tagged帧,且其VLAN-ID在接口允许通行的VLAN列表里,则接收该帧。否则丢弃。
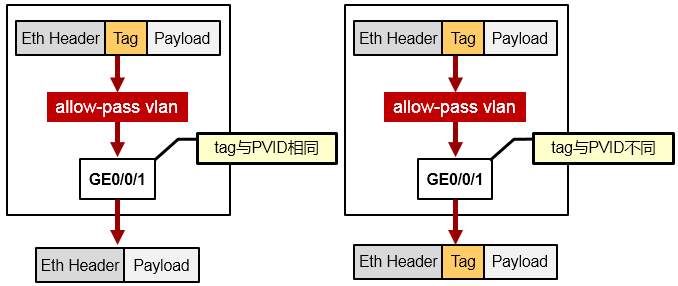
Trunk口发送帧¶
若该帧的VLAN-ID与接口PVID相同,且该VLAN在允许通行的VLAN列表中,则去掉Tag,发送数据帧。若该帧的VLAN-ID与接口PVID不同,且该VLAN在允许通行的VLAN列表中,则保持原有Tag,发送该
Tagged帧,而如果数据帧的VLAN-ID不在允许通行的VLAN列表中,则禁止从该接口发出。
Hybrid口接收帧¶
若数据帧是Untagged帧,则将其打上PVID的Tag,然后,若PVID在接口允许通行的VLAN列表里则接收,否则丢弃。
若数据帧是Tagged帧,且其VLAN-ID在接口允许通行的VLAN列表里则接收该帧,否则丢弃。
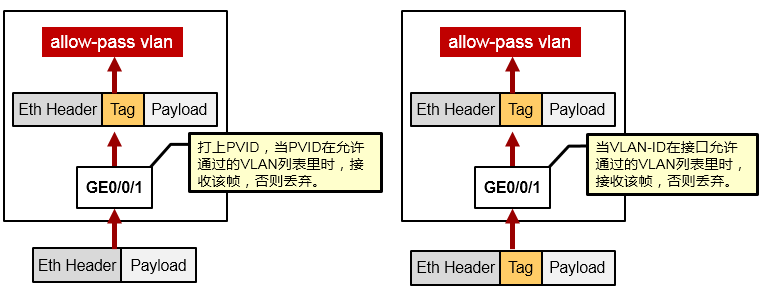
Hybrid口发送帧¶
当该帧的VLAN-ID是接口允许通行的VLAN时,发送该帧,此时可以通过命令设置发送时是否携带Tag。
- VLAN 及 Trunk 的基础配置
VLAN相关的基础配置命令¶
在交换机上创建VLAN10并进入VLAN10的配置视图:
(可选)在特定的VLAN视图下添加VLAN描述:
[Quidway-vlan10] description TechVLAN
将特定的接口配置为access类型,并加入特定VLAN。下面以将GE0/0/1配置为access类型并加入
VLAN10为例:
将特定接口配置为trunk类型,然后配置trunk接口允许通行的VLAN:
(可选)配置Trunk接口的PVID。PVID所对应VLAN的流量从trunk接口发送出去时不会打Tag(也就是以Untagged帧发送),另外,如果Trunk接口收到Untagged帧,也认为是属于PVID所对应的VLAN。缺省时PVID是1。以下将GE0/0/24接口(该接口已经被配置为Trunk类型)的PVID修改为99:
[Quidway-gigabitEthernet0/0/24] port trunk pvid vlan 99
VLAN基础配置示例¶
在交换机上创建VLAN10及VLAN20,将PC1(所在接口)划入VLAN10,将PC2划入VLAN20。
SW1的配置如下:
完成配置后,在SW1上可进行相应的查看:
另外,使用**display port vlan**命令也能查看每个接口的link type以及所加入的VLAN等信息。
VLAN及Trunk基础实验¶
在SW1、SW2上创建VLAN10及VLAN20,将交换机连接PC的接口配置为Access类型并添加到如图所示的VLAN。然后,将两台交换机互联的接口配置为Trunk类型,并放通相应的VLAN,使得相同VLAN 内的PC能够直接通信。
SW1的配置如下:
SW2的配置如下:
完成上述配置后,同一个VLAN内的用户就能够互相通信了,例如PC1可以ping通PC3,而PC2也能够
ping通PC4。但是不同的VLAN之间是无法互访的。
- Hybrid 接口的配置
Hybrid是一种特殊的二层接口类型。与trunk类型的接口类似,hybrid类型的接口也能够承载多个VLAN的数据帧,而且它能够灵活的设置接口在发送数据帧时,是否携带tag。另一方面,hybrid类型的接口还能用于部署基于IP地址的VLAN划分。下面我们将针对几种使用场景,讲讲hrbrid接口的配置。
Hybrid接口用于连接终端PC¶

在上图中,PC1连接在SW1的GE0/0/1接口上,现在将SW1的GE0/0/1接口做如下配置:
以上命令将GE0/0/1接口配置为hybrid类型,以S5300交换机为例,接口缺省即为该类型,而且缺省将
VLAN1设置为PVID(缺省VLAN),并且接口已经放通VLAN1(缺省就配置了**port hybrid untagged vlan 1**)。因此在这个场景中,如果为SW1的Vlanif1配置一个192.168.10.0/24网段的IP地址,则PC1 与SW1即可实现互通。此时PC1被认为属于VLAN1。
如果我们期望将PC1规划在VLAN10中,那么配置修改如下:
上面配置中**port hybrid pvid vlan 10**命令用于将接口的PVID修改为10,这样当该接口收到PC1发送出
来的untagged帧时,就会认为这些帧来自于VLAN10;而**port hybrid untagged vlan 10**命令则用于将该接口加入VLAN10,使得PC1所发送的数据帧能够进入GE0/0/1接口(被该接口接收)从而进入交换机,另外,这条命令还使得交换机在从GE0/0/1接口向外发送VLAN10的数据帧时,以untagged的方式发送。因此完成上述配置后,PC1被认为属于VLAN10,并且能够ping通SW1的vlanif10接口IP地址:
192.168.10.3。
值得注意的是,在PC1发送的数据帧进入交换机SW1之后,如果SW1将数据帧透传处理,那么该帧从
GE0/0/15发出时,是否携带tag,则要根据GE0/0/15接口的配置而定。
Hybric接口用于连接交换机¶
在上图中,SW1及SW2分别连接着PC1及PC2,我们将两台交换机的GE0/0/1配置为access类型,并且都加入VLAN10。现在SW1的GE0/0/15被配置为trunk类型,并且放通了VLAN10:
现在,来看看如果SW2的GE0/0/15接口采用hybrid类型该如何配置(纯粹为了讲解hybrid的配置而举例,
通常我们会为链路两端的接口配置相同的类型)。
由于对端接口(SW1的GE0/0/15)以tagged的方式发送VLAN10的数据帧,因此SW2的GE0/0/15接口也必须将VLAN10以tagged的方式处理:
**port hybrid tagged vlan 10**命令用于将GE0/0/15接口加入VLAN10,并且该VLAN的帧以Tagged方式
通过接口。
现在考虑另一种情况,如下图所示:
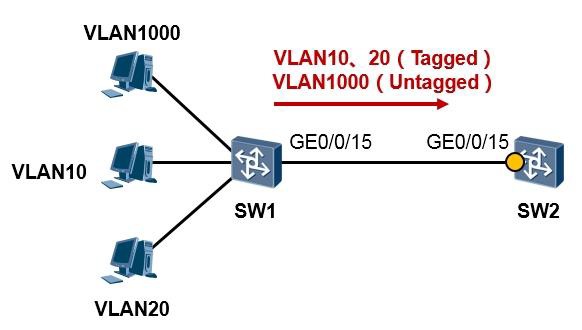
SW1左侧连接着VLAN10、20以及1000,现在SW1的GE0/0/15做了如下配置:
也即SW1在通过GE0/0/15往外发送数据帧时,对于VLAN10及VLAN20采用tagged帧的方式发送,而对
于VLAN1000则采用untagged帧的方式发送,那么如果SW2采用hybrid接口与其对接,此时该接口的配置应该如下:
基于IP地址识别VLAN的功能¶
通常我们在划分VLAN时,是采用基于接口划分VLAN的方式,也就是通过命令,将交换机的接口加入某个特定的VLAN。某局点遇到个较为“特殊”的需求:在下图所示的网络中,SW2下挂着三台服务器, 其中SW2连接Server1、Server2的接口是Access类型接口,而且接口加入了VLAN1;连接Server3的接口也是Access类型,但是加入了VLAN30。而SW2上联SW1的上行口则是Trunk类型接口,该接口放通了VLAN1及VLAN30,并且PVID为1。
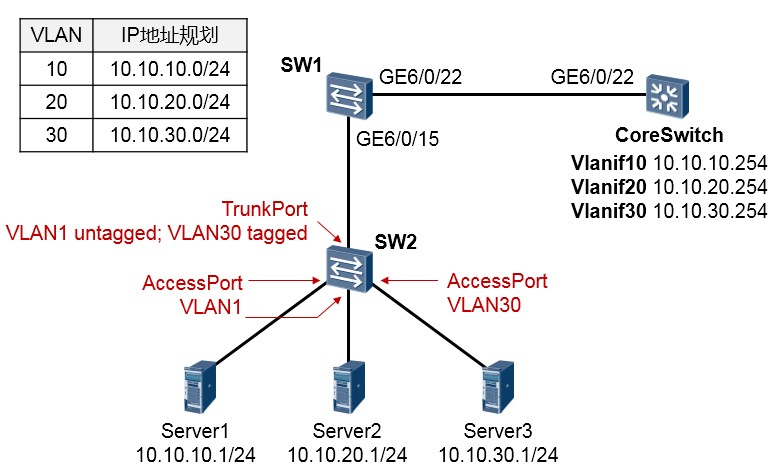
如此一来,SW1将会在GE6/0/15接口上收到三种类型的流量,分别是源地址为10.10.10.0/24网段的无标记帧、源地址为10.10.20.0/24网段的无标记帧,以及VLAN30的标记帧。现在需求是,根据规划,将上述各个网段在核心交换机CoreSwitch上对应到不同的VLAN,并且实现服务器之间的相互通信。由于某种原因,SW2是无法被直接管理的,因此只能在SW1及CoreSwitch上完成配置。
实际的需求是,在SW1上完成相应的配置,使得其在GE6/0/15接口上收到源地址为10.10.10.0/24网段的数据时,将其识别为VLAN10的数据,收到源地址为10.10.20.0/24的数据时,将其识别为VLAN20的数据,而VLAN30的数据需为标记帧。因此需在SW1上部署基于IP地址的VLAN划分。当然,这个接口在发送VLAN10及VLAN20的数据帧时,不能打标记,而在发送VLAN30的数据帧时,则需要打标记。
SW1的配置如下:
CoreSwitch的配置如下:
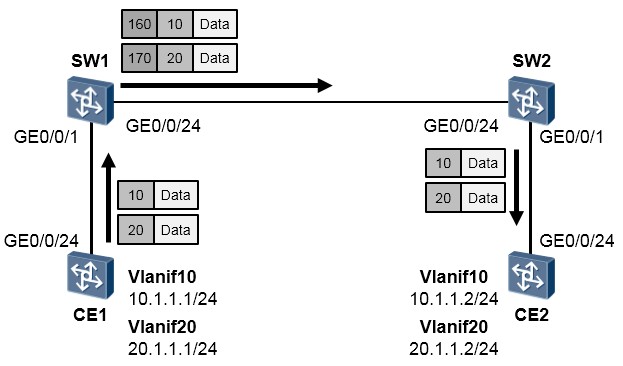
- QinQ
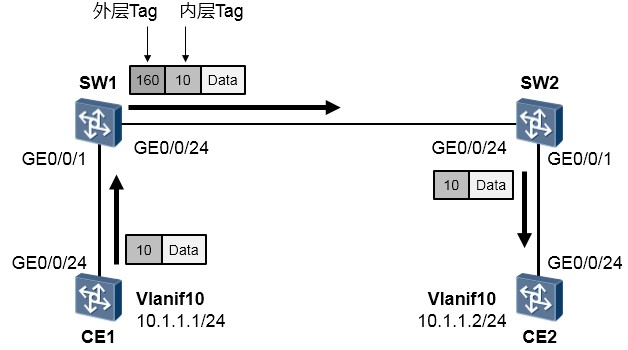
在上图中,CE1及CE2两台交换机都部署了VLAN10。两台交换机分别接入了SW1及SW2。SW1及SW2是两台公网交换机,且连接着其他设备,为了保证CE1及CE2能够在VLAN10中实现二层通信,而且不与其他设备产生冲突,公网为该业务分配了外层VLAN160。
在SW1及SW2上部署QinQ使得CE1能够访问CE2。图中的交换机以S5700 V2R1C00版本为例。
SW1的配置如下:
SW2的配置如下:
CE1的配置如下:
CE2的配置如下:
完成上述配置后,从CE1即可ping通10.1.1.2。在SW1及SW2之间可捕获如下ICMP Request报文:
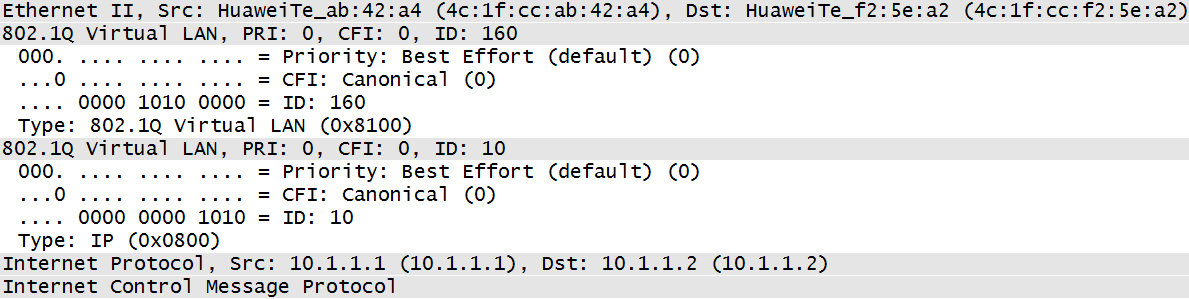
留意到该报文携带两层VLAN-Tag,其中外层VLAN-ID为160,而内层为10。
在不同的网络规划或不同厂商设备的QinQ报文中,VLAN-Tag的TPID字段可能被设置为不同的值。为了和现有网络规划兼容,设备提供了QinQ报文外层VLAN-Tag的TPID值可修改的功能。用户通过配置TPID的值, 使得发送到公网中的QinQ报文携带的TPID值与当前网络配置相同,从而实现与现有网络的兼容。
再看另一个例子,拓扑如下图所示。网络中的需求是,CE1发往SW1的数据帧中,携带VLAN-Tag 10的流量增加一层VLAN-Tag,外层VLAN-Tag为160;携带VLAN-Tag 20的流量增加一层VLAN-Tag,外层VLAN-
Tag为170。
SW1的配置如下:
SW2的配置如下:
CE1的配置如下:
CE2的配置如下:
- 二层接口、三层接口、以及 PVID、VLAN-ID 等概念杂谈
- 二层接口,可以简单理解为只具备二层交换能力的接口,例如二层交换机的物理接口,或者三层交换机的物理接口(一般而言,这些接口缺省时为二层模式,某些款型具备切换为三层模式的能力)。
- 二层接口不能直接配置IP地址,并且不直接终结广播帧(目的MAC地址为广播MAC地址FFFF- FFFF-FFFF的数据帧)。二层接口收到广播帧后,会将其从同属一个广播域(VLAN)的所有其他接口泛洪出去。
- 三层接口维护IP地址与MAC地址。
- 三层接口会终结广播帧,三层接口在收到广播帧后,不会进行泛洪处理。
- 二层接口在收到单播帧后,会在MAC地址表中查询该数据帧的目的MAC地址,然后依据表项指引进行转发,如果没有任何表项匹配,则进行泛洪。三层接口在收到单播帧后,首先判断其目的MAC 地址是否为本地MAC地址,如果是,则将数据帧解封装,并解析出报文目的IP地址,然后进行路由查询及转发。因此二层接口与三层接口在数据处理行为上也存在明显差异。
- 二层接口有几种类型(这里说的是以太网二层接口):access、trunk、hybrid。三层接口则没有上述类型。
-
三层接口有物理形态的,也有逻辑形态的,典型的物理接口如路由器的三层物理端口;逻辑接口如
VLANIF,以及以太网子接口,例如GE0/0/1.1。等等。VLANIF与其关联的VLAN的VLAN-ID对应,
- 三层接口维护IP地址与MAC地址。
- 二层接口不能直接配置IP地址,并且不直接终结广播帧(目的MAC地址为广播MAC地址FFFF- FFFF-FFFF的数据帧)。二层接口收到广播帧后,会将其从同属一个广播域(VLAN)的所有其他接口泛洪出去。
此外:
而以太网子接口,通常也会绑定相应的VLAN-ID,从而与相应的VLAN对接。这两种典型的三层接口均可以直接配置IP地址。
-
在以太网二层交换网络里,VLAN是一个非常基础的东西。每个VLAN都是一个逻辑的广播域,每个VLAN都使用对应的ID进行标识,这是VLAN-ID。
-
接口缺省VLAN标识,即PVID(Port Default VLAN ID),指的是二层接口上的缺省VLAN-ID(每个二层接口上有且只有一个VLAN-ID作为PVID),也就是说,PVID必定是某一个具体VLAN的VLAN-ID。PVID的作用是,当这个二层接口收到了流量,并且该流量不携带任何802.1Q Tag
(VLAN-ID信息),该接口便认为这些流量属于PVID对应的VLAN。当然,PVID还会影响接口发送数据帧,这里不再赘述。缺省情况下,所有接口的PVID均为VLAN1。
- 对于Access接口,缺省VLAN就是它允许通过的VLAN,修改接口允许通过的VLAN即可更改接口的缺省VLAN。
- 对于Trunk接口和Hybrid接口,一个接口可以允许多个VLAN通过,但是只能有一个缺省VLAN, 修改接口允许通过的VLAN不会更改接口的缺省VLAN。
- 三层接口未必一定对应VLAN-ID。例如路由器的三层物理接口,这种类型的接口无需配置VLAN-ID。
-
在三层交换机上(路由器或防火墙等设备,也有支持VLANIF的款型),每个VLAN都有对应的
VLANIF,VLANIF指的是VLAN对应的逻辑三层接口,这个三层接口在VLAN被创建后,可以直接赋予IP地址,且具备路由转发能力。一个VLAN对应一个VLANIF,VLAN与VLANIF的标识相同。
VLAN内的终端设备,可以与该VLAN对应的VLANIF直接进行二层通信。
- 对于Access接口,缺省VLAN就是它允许通过的VLAN,修改接口允许通过的VLAN即可更改接口的缺省VLAN。
-
-
二层防环技术
- STP
STP技术背景¶
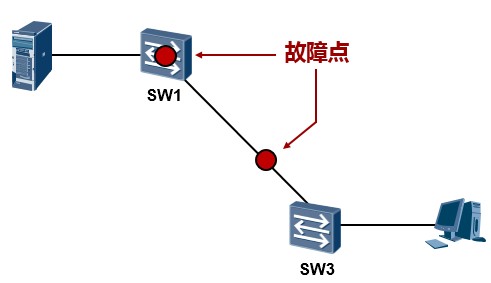
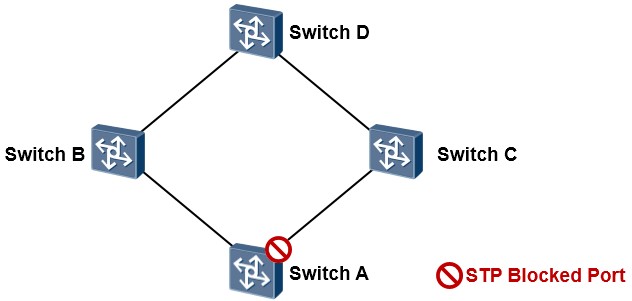
在上图所示的网络中,接入层交换机SW3单链路上联到汇聚交换机SW1,这是存在单链路故障的,这个网络的可靠性也是比较差的。如果SW3的上联链路发生故障,SW3(以及下联用户)就断网了。网络中存在的另一个单点故障问题,就是SW1如果宕机,SW3也就断网了。为了使得网络更加健壮、更具有冗余性, 我们可以考虑将拓扑修改为如下图所示:接入层交换机SW3采用双链路上联到两台汇聚设备,构成一个物理链路冗余的二层环境,解决了单链路及单设备故障问题。
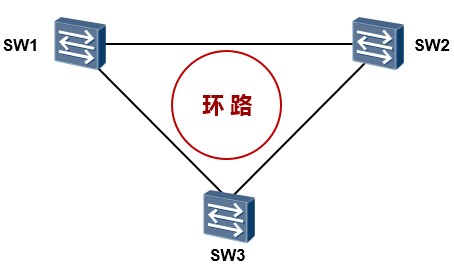
但是这却带来了另一个大问题:网络中存在二层环路(所谓的二层环路指的是由二层链路构成的环路)。这个三角形的二层环路会为网络带来重大问题。我们已经知道交换机的工作机制:当其收到组播、广播数据帧时,会直接在VLAN内进行泛洪,另外,如果收到目的MAC地址未知的单播数据帧时,同样会进行泛洪,这么一来,当网络中出现二层环路时,就可能会导致广播风暴、多帧复制、MAC地址漂移等等多种问题,从而给网络带来巨大影响。即使不是人为搭建冗余的物理环境而导致的环路,网络也有可能因为种种原因出现二层环路引发的故障,例如由于人为的误接线缆等。那么有没有什么办法解决环路的问题呢?解决方案有许多,实际上以太网中的二层环路问题是一个不小的课题,业界有许多非常经典的解决方案应对这个问题,数据设备厂商为了应对二层环路问题也都纷纷提出了自己的技术或方法论,但是这里不得不提到的是**生成树(Spanning-tree,简称STP)协议**,这是一个经典的、公有的协议,专门用于应对以太网二层环路问题。
通过STP,在逻辑上将特定接口进行阻塞(Block),从而实现保持物理上的冗余环境同时、二层环境中又可打破环路。例如在下图中,网络是存在环路的,在三台交换机上运行生成树协议后,STP经过一定的计算, 最终决定阻塞掉一个接口,从而打破环路。
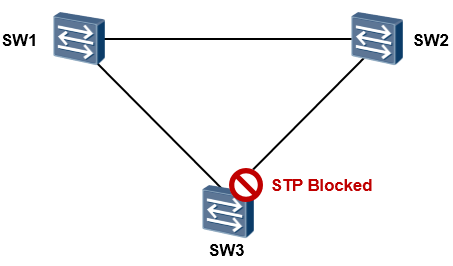
当拓扑发生变更的时候,如下图所示,STP能够探测到这些变化,并且及时自动的调整接口状态,从而适应网络拓扑的变化,实现链路冗余。
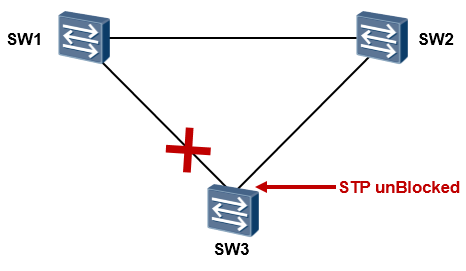
STP需要运行在网络中的所有交换机上以防止网络出现环路。一旦开启STP,交换机之间就会进行STP报文的交互,而STP的工作及计算正是依赖于这些报文的交互,STP操作的结果是将网络中的特定接口阻塞,从而达到消灭环路的目的,但是具体是什么接口被阻塞,可不是随便定的,STP一套自己的计算方法。本章我们主要介绍的是STP的802.1D标准。这个标准实际上已经非常古老而且基本不再使用了,但是却依然是入门生成树技术的必经之路,后续的更新实际上都是基于这个协议,因此掌握它是非常有必要的。接下来我们先了解一下802.1D标准的STP。
STP基本概念¶
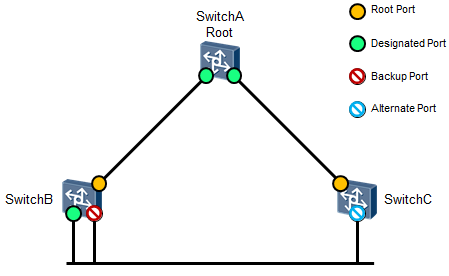
简单地说STP采用四个步骤来解决二层环路问题:¶
- 在交换网络中选举一个根桥(Root Bridge,简称RB);
- 在每个非根桥上选举一个根端口(Root Port,简称RP);
- 在每个段中选举一个指定端口(Designated Port,简称DP);
- 阻塞非指定端口(Non-Designated Port,简称NDP)。
说明:这里的桥(Bridge),其实就是指交换机,由于交换机是由早期的网桥发展而来,因此在一些场合下,我们依然
沿用“ 网桥“或者“ 桥“来称呼交换机。
关键字段及比较原则¶
运行STP的交换机之间会交互一些非常重要的协议报文,该报文称为网桥协议数据单元(Bridge Protocol Data Unit,简称BPDU)。STP之所以能够正常工作并构建一个无环的网络,是依赖于BPDU 报文的泛洪。要理解STP的工作过程,非常重要的一点就是要理解BPDU中各字段的含义,因为这些都是STP赖以工作的根本。BPDU报文包含的所有字段在后文中有所涉及,这里我们先关注几个重点字段
(此处介绍的是BPDU中的一种关键类型:配置BPDU):

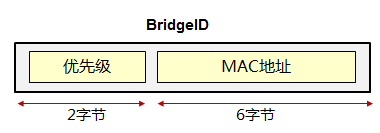
桥ID(Bridge Identifier)¶
在STP中,每一台交换机都有一个唯一的标识符,这个标识符就是桥ID,桥ID长度为8个字节,由两部分组成:2个字节的桥优先级和6个字节的桥MAC地址,其中优先级默认为32768,可以手工更改。而桥MAC地址为网桥的背板MAC(可以简单地理解为系统MAC)。交换机发送的BPDU报文中,桥ID字段存放的就是自己的桥ID,而根桥ID字段存放的就是网络中根桥的桥ID。
根路径开销(Root Path Cost)¶
根路径开销是一个用于度量接口到根桥的开销的值,交换机的接口到根桥的路径开销越小则被阻塞的可能性也就越小。
根桥发送出来的BPDU中,根路径开销字段值都为0。当非根桥在某个接口上收到这个BPDU再进
行STP计算的时候,会把该BPDU中所包含的根路径开销累加上收到该BPDU的接口的STP Cost, 从而得到从该接口到达根的总路径开销。
STP接口Cost与接口的带宽有关,接口带宽越高,则接口的STP Cost越小。
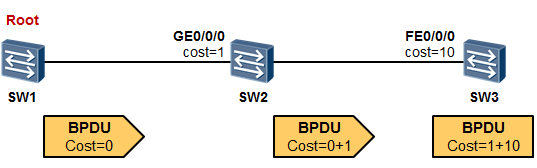
在上面的例子中,SW1是网络中的根桥,因此它发送BPDU报文中Root Path Cost字段为0,SW2 在GE0/0/0收到这个BPDU后就可以进行相应的计算,它从GE0/0/0到达根桥的Root Path Cost等于自己接口的Cost加上所收到的BPDU报文中的Root Path Cost,结果就是1,随后SW2将这个
BPDU转发给SW3,注意此时BPDU中的Root Path Cost被修改为1。SW3在收到这个BPDU并进行Root Path Cost计算的时候,Root Path Cost就等于自己FE0/0/0接口的Cost加上BPDU报文中的Root Path Cost,也就是11。
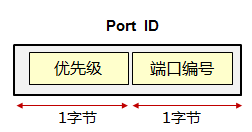
端口ID(Port ID)¶
端口ID(2字节)包含两部分:端口优先级(1字节)以及端口编号(1字节)。缺省时优先级值为
128,该值可以通过命令修改,取值范围是0-255,值越小越优。
说明:在本文中,交换机的端口指的就是交换机的接口,在描述交换机时,笔者可能同时使用端口或接口一词。
生成树构造一个无环路拓扑时,总是使用相同的4步来判定(下面的信息都是BPDU中的字段):¶
Step1:最小的根桥ID
Step2:最小的根路径开销
Step3:最小的桥ID
Step4:最小的端口ID
STP操作¶
在交换网络中选举一个根桥¶
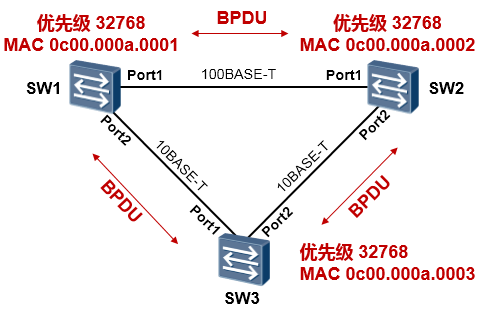
以上图所示的网络为例,我们在交换机上都开启了STP,初始情况下,所有的交换机都认为自己就是网络中的根桥,于是都向网络中泛洪配置BPDU,在各自发送的配置BPDU中,都声称自己是根桥。经过
PK之后,拥有最小桥ID的交换机胜出,成为这个交换网络真正的根桥。
根桥的选举过程:首先比较桥优先级,优先级值最小的交换机胜出,如果优先级相等,则再比较桥MAC 地址,也是优选最小的值。所以在上图所示的例子中,SW1胜出成为根桥。
根桥是STP计算得出的无环的拓扑(可以形象地理解为一棵树)的树根,STP后续的计算都是以这个树根作为参考点的。当然,在实际的项目中,我们通常是不会通过MAC地址的比较让交换机自己去选根桥的,为了网络的稳定和可控,一般会将核心交换设备配置为网络的根桥——将其桥优先级调节为最小值,从而确保其成为根桥。
在每个非根桥上选举一个根端口¶
在选举出根桥后,根桥仍然持续向网络中发送配置BPDU,而非根桥将持续不断地收到根桥发送的配置
BPDU。STP计算过程的第二步是在每个非根桥上选择一个根端口,根端口是每台交换机上收到最优
BPDU的端口。
一台非根桥可能会有多个端口连接到交换网络,每个非根桥上必须选举一个根端口,而且只会选举一个根端口。当存在多个端口时,交换机在这些端口上都会收到配置BPDU,交换机会比较这些配置BPDU,然后选择比较结果最优的接口作为根端口,按照如下顺序比较:1)比较配置BPDU中的根桥ID字段, 选择值小的;2)如果前者相等,则将配置BPDU中的根路径开销值读取出来,与收到该BPDU的接口的
Cost相加,比较相加后的值,选择值最小的;3)如果前者还相等,则比较配置BPDU中的桥ID字段;
4)如果前者还相等,则比较端口ID字段。
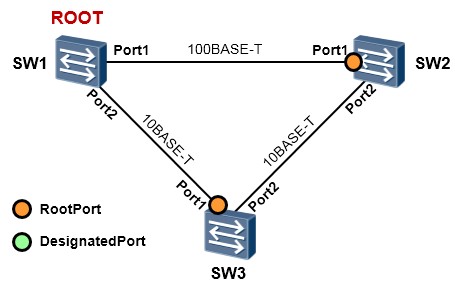
例如在上图中,SW3有两个接口接入到这个交换网络中:Port1及Port2,现在SW3要在两者之间选举一个根端口。SW3会从Port1和Port2都收到配置BPDU报文(从Port1收到的是SW1直接发送过来的,从
Port2收到的是根桥SW1发往SW2,然后由SW2转发过来的),在报文中都有携带“桥ID、根路径开销、桥ID、端口ID”等关键字段,那么SW2就会进行Port1及Port2的PK,PK什么呢?先PK这两个端口到达根桥的根路径开销,优选值更小的,如果相等,则PK这两个接口收到的BPDU中的桥ID,也是优选值更小的,如果连这个也相等呢,那就进一步PK这两个接口收到的BPDU中的端口ID。很明显,这里Port1 到根的根路径开销更小,而从Port2到根呢,除了自己接口的开销还要累加上SW2的Port1的开销。所以
SW3上,Port1成为了根端口。
为每个段选举一个指定端口(Designated Port)¶
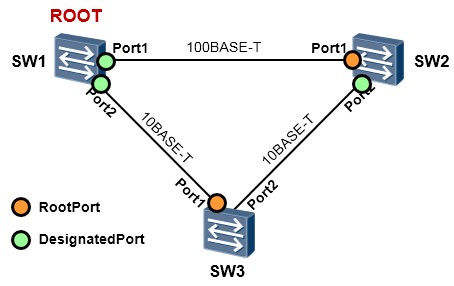
非根桥选举出根端口后,会将根端口上收到的配置BPDU进行计算:为本交换机上的其他端口各计算一份配置BPDU,而这些接口也会从网络中收到配置BPDU,此时交换机会比较这两份配置BPDU,如果前者更优,则该端口成为指定端口,如果后者更优,则该端口成为非指定端口并且将被阻塞。
交换机根据根端口上收到的最优配置BPDU后为其他端口计算配置BPDU的过程如下:
- 配置BPDU中的根桥ID替换为根端口的配置BPDU的根桥ID;
- 根路径开销替换为根端口配置BPDU的根路径开销加上根端口的开销;
- 桥ID替换为自身设备的桥ID;
- 端口ID替换为自身端口ID。
阻塞非指定端口(Non-Designated Port)¶
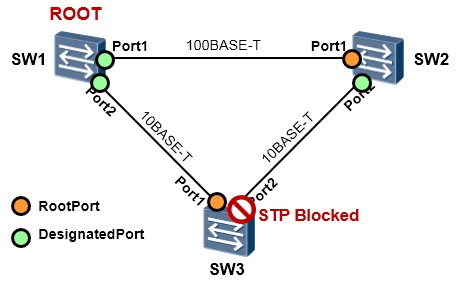
最后,非指定端口被阻塞,环路就打破了。
STP报文¶
STP的BPDU有两种类型:配置BPDU(Configuration BPDU)及TCN BPDU(Topology Change BPDU)。两种BPDU各有各的用途。
配置BPDU¶
在网络刚开始运行的阶段,所有交换机都会从所有端口发送配置BPDU,大家都认为自己是根桥,随着配置BPDU泛洪和收集、计算,根据配置BPDU中所含信息,大家PK出来个结果,根桥被选举出来了。在此之后根桥以默认2S为周期发送配置BPDU,所有的非根交换机从自己的根端口收到配置BPDU,再 从自己的指定端口计算BPDU发出去。这就有点像我们从根桥倒一盆水下来,水在重力的牵引下顺着这颗无环的树从上往下不断的往下流。另外,被阻塞的非指定端口会源源不断的收到链路上的配置BPDU 并一直侦听之,当其在一定时间内没有再收到配置BPDU,则认为链路出现了故障,开始进入新的收敛阶段。
下表是配置BPDU的报文格式:¶
| 字节 | 字段 | 描述 |
|---|---|---|
| 2 | 协议 | 代表上层协议(BPDU),该值总为0 |
| 1 | 版本 | (对于802.1D,该字段总为0) |
| 1 | TYPE | “配置BPDU”为0x00、“TCN BPDU”为0x80 |
| 1 | 标志 | LSB最低有效位表示TC标志;MSB最高有效位表示TCA标志 |
| 8 | 根ID | 根网桥的桥ID |
|---|---|---|
| 4 | 路径开销 | 到达根桥的STP cost |
| 8 | 桥ID | BPDU发送桥的ID |
| 2 | 端口ID | BPDU发送网桥的端口ID(优先级+端口号) |
| 2 | 消息寿命 Message age | 从根网桥发出BPDU之后的秒数(这个BPDU存活了多长时间了),每经 过一个网桥都减1,所以它本质上是到达根桥的跳数。 |
| 2 | 最大寿命 Max age | 当一段时间未收到任何BPDU,生存期到达MAX age时,网桥认为该端口 连接的链路发生故障。也可以理解为这个BPDU的最大寿命, |
| 2 | HELLO时间 | 根网桥连续发送的BPDU之间的时间间隔。 |
| 2 | 转发延迟 | 在监听和学习状态所停留的时间间隔。 |
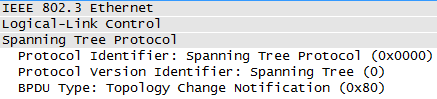 TCN BPDU¶
TCN BPDU¶
当网络拓扑发生变化的时候,最先意识到变化的交换机(假设该交换机不是根桥)会从根端口发送TCN BPDU(Topology Change Notofication BPDU,拓扑变更通知BPDU,该BPDU报文中TYPE字段=0x80), 也就是朝着根桥的方向发送TCN BPDU,这个报文会一跳一跳地传递到根交换机。上联的交换机在收到了该交换机发送上来的TCN BPDU后,除了向它自己的上一级交换机继续发送TCN BPDU外,还需回送一个TCA BPDU(FLAG字段中TCA位为1的配置BPDU)的确认信息给该交换机。当根桥接收到
TCN后意识到了拓扑变化,遂向所有网桥发送TC BPDU(FLAG字段中TC位为1的配置BPDU)。 交换机们收到根桥发出来的TC BPDU后,会立即删除自己的MAC地址表,以便适应新的网络拓扑。
STP的计时器¶
STP有三个非常重要的计时器:
- Hello Timer:根桥周期性发送配置BPDU的时间间隔,缺省为2s。
- 转发延迟计时器(Forward Delay Timer):接口从Listening转换到Learning状态,或者从Learning转换到Forwarding状态过程中所需等待的时间,缺省为15s。
- 最大生存时间(Max Age Timer):在丢弃配置BPDU之前,交换机用来存储配置BPDU的时间,缺省
为20s。如果一个被阻塞的接口(非指定端口)在收到一个配置BPDU后,20s内没有再次收到配置BPDU,则切换到Listening状态。
网络中的生成树拓扑依附于根桥的计时器,根桥将配置BPDU中的计时器时间间隔传递给所有交换机。对于
802.1D标准的STP而言,端口从Blocking到Forwarding通常要30-50s(30s是15+15,也就是两个转发延迟时间,50s即20+15+15)。
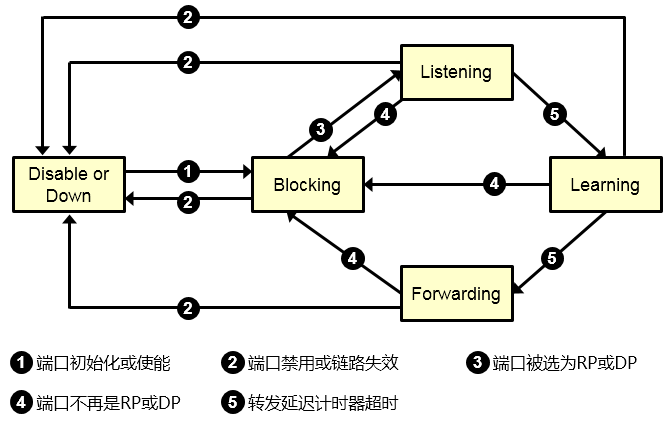
STP端口状态¶

关于为什么要定义这么多的端口状态,其实很好理解,拿Learning来说,为什么不让端口一旦被选举为指定端口后立即进入转发状态呢?设想一下,端口激活后,交换机在该端口是没有学习到任何的MAC地址表项的,如果没有设计Learning状态的话,端口将直接进入转发状态,那么就有可能引发短暂的数据泛洪(交换机收到目的MAC地址未知的数据帧时会进行泛洪)。
下图是每个状态的切换关系图:
STP的基础配置¶
基础配置¶
指定生成树协议类型(STP/RSTP/MSTP):
配置交换机优先级:
配置该交换机成为主根桥:
配置该交换机成为次根桥:
启用生成树:
配置端口STP优先级:
配置端口路径开销:
基础实验¶
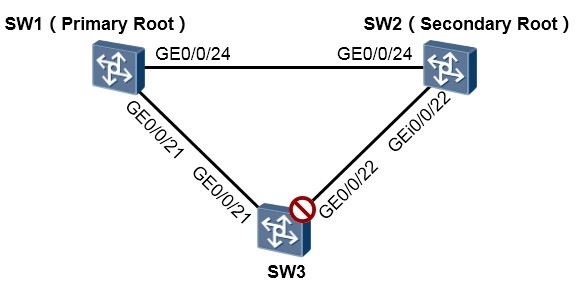
在上图所示的网络中,在SW1、SW2及SW3上运行STP,并将SW1指定为主根桥,SW2指定为次根桥, 最终需使得SW3的GE0/0/22接口被阻塞。
从拓扑我们能非常直观的看出,在物理上这是一个冗余的环境,并且存在二层环路。一旦在这个网络中出现流量,那么流量就很有可能在环路中被不断泛洪从而导致广播风暴。当出现广播风暴时,我们能从设备的指示灯上观察到非常直观的现象:设备的指示灯会出现非常规律的“齐闪”。另外,交换机的接口带宽利用率可能会攀升到一个比较高的值,而且如果广播风暴比较严重,交换机的CPU利用率也可能会飙高,从而影响到其工作。
SW1的配置如下:
SW2的配置如下:
SW3的配置如下:
在完成上述配置后,STP开始工作,并开始选举根桥,三台交换机中,STP桥ID(桥优先级和桥MAC)
最小的交换机将成为本交换网络的根桥。当然,所有的交换机默认的桥优先级为32768,这样一来拥有最小背板MAC的交换机将成为网络的根桥,这显然带有一定的随机性,在实际的网络部署中,我们往往会手工指定一台设备成为根桥,从而保证生成树计算的稳定性。例如在这个例子中,手工指定SW1 成为网络的主根桥,SW2成为网络的次根桥:
SW1上增加的配置如下:
[SW1] stp root primary
SW2上增加的配置如下:
[SW2] stp root secondary
现在,我们再看看实验效果,在SW1上查看STP的全局信息:
从输出的信息我们得知,本交换机的桥ID为 0:4c1f-cc06-71d8,其中0为交换机的桥优先级,这显然
是我们的命令**stp root primary**的作用,交换机的优先级被配置为0——最小值也是最优的值。4c1f- cc06-71d8是本机的MAC地址。而上述输出的信息中,根桥的MAC也是4c1f-cc06-71d8,这就表明,本交换机就是网络的根桥。再来查看下SW1的生成树接口状态:
使用上述命令,可以查看STP的相关简化信息,从上面的输出可以看出,SW1的两个接口都是指定接口(DESI),并且都是Forwarding转发状态。
再去SW2上看看:
| [SW2] display stp -------[CIST Global Info][Mode STP]------- | ||
|---|---|---|
| CIST Bridge | :4096 .4c1f-cc34-71cd | #本机的桥ID |
| Config Times | :Hello 2s MaxAge 20s FwDly 15s MaxHop 20 | |
| Active Times CIST Root/ERPC | :Hello 2s MaxAge 20s FwDly 15s MaxHop 20 :0 .4c1f-cc06-71d8 / 1 | #根桥的桥ID,也就是SW1 |
| CIST RegRoot/IRPC | :4096 .4c1f-cc34-71cd / 0 | |
| CIST RootPortId | :128.24 | |
| BPDU-Protection | :Disabled | |
| CIST Root Type | :Secondary root |
SW2为次根桥,它将在检测到SW1出现故障后,替代它成为网络的根桥。
我想,你已经能想到SW3上哪一个端口将被Blocked了:
SW3的GE0/0/22口现在是Discarding状态,被阻塞了。这是因为这个接口到达根桥SW1的开销最大。
如果此时希望SW3被阻塞的不是GE0/0/22口,而是GE0/0/21口呢?一种可选的办法是,将GE0/0/21 的接口开销调大,使得从这个接口上收到配置BPDU后,累加的根路径开销比GE0/0/22口的累加值要大, 也就是使得这个接口距离根桥SW1的“开销”更大、“更远”。
SW3增加配置如下:
完成上述配置后,检查一下SW3的接口角色和状态:
| [SW3] display stp brief | ||||
|---|---|---|---|---|
| MSTID | Port | Role | STP State | Protection |
| 0 | GigabitEthernet0/0/21 | ALTE | DISCARDING | NONE |
| 0 | GigabitEthernet0/0/22 | ROOT | DISCARDING | NONE |
- STP 的特性及优化
STP及BPDU取消使能¶
[Switch-GigabitEthernet0/0/1] stp disable 上述命令用于在接口上关闭STP。如果交换机在全局使能了STP,则所有接口也将激活STP。使用上述命令,将会关闭某个特定接口的STP,这样一来这个接口将不再参与STP计算,此后,使用**display stp interface** 命令会看到该接口的STP被禁用,使用**display stp brief**命令则不会看到这个接口出现在STP接口列表中。
当交换机的一个接口连接着一台路由器(的路由接口)或者其他不可能产生二层环路的设备时,在交换机的这个接口上运行STP实际上是没有意义的,因此可以考虑将该接口的STP关闭。
[Switch-GigabitEthernet0/0/2] bpdu disable
接口级命令**bpdu enable**用来配置接口上送BPDU报文,接口对目的MAC地址属于BPDU MAC的报文上送
CPU处理,BPDU MAC可以通过**display bpdu mac-address**命令查看,而**bpdu disable**命令将使接口把收到的BPDU报文丢弃。
值得注意的是,如果错误的配置**bpdu disable**将会导致STP计算的错误从而导致环路,因此该命令要格外留意。S5300 V100R005C01SPC100版本的交换机默认在STP全局激活的情况下接口的bpdu是disable的
(S5300的其他软件版本则要看版本的描述),需要注意这一点。
边缘端口(Edged-port)¶
基本概念¶
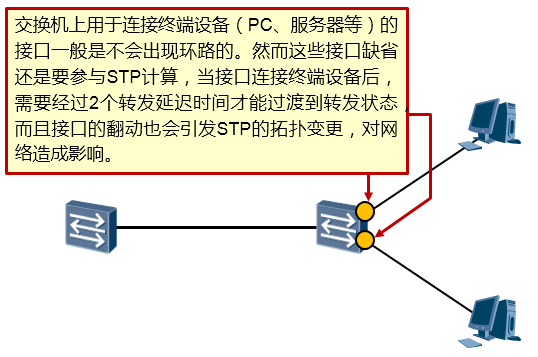
我们知道在运行了STP的交换机上,一个端口在UP之后,需要经过Listening、Learning两个状态才能够最终进入Forwarding状态开始转发数据帧(当然前提是该端口不能是非指定端口),这里就耗费了两个15s的延迟时间。这实际上是非常低效的。
交换机连接终端设备(例如PC、服务器等)的端口一般是不会产生二层环路的,其实并不需要上述状态的切换过程,可直接进入转发状态,提高工作效率。将交换机连接终端设备的端口配置为边缘端口
(Edge-port)即可解决上述问题。边缘端口不参与生成树的计算,它可以在UP后立即进入转发状态。另外,边缘端口的UP/DOWN不会触发STP拓扑变更而发生TC报文。
在没有配置BPDU保护(将在后续的内容中介绍)的情况下,边缘端口一旦收到BPDU,就丧失了边缘
端口属性,成为了普通的STP端口。
配置实现¶
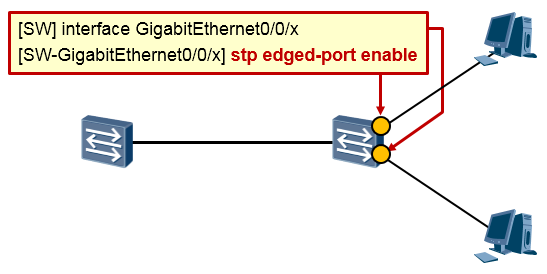
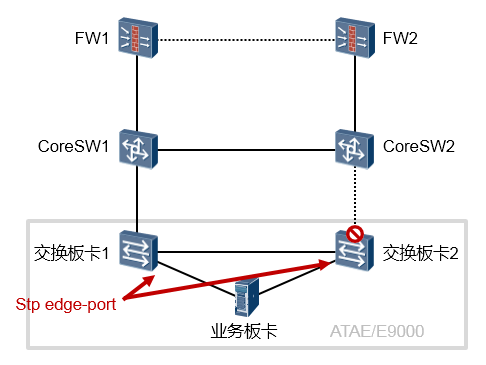
运行了STP的交换机,在其连接终端设备的接口上都可以开启该特性。
在实际的项目中,如果网络中采用ATAE/E9000设备,如下图所示,那么我们会将ATAE/E9000的交换板连接业务板的内部接口配置为边缘端口,因为这些端口用于连接刀片服务器的网卡(网卡工作在三层模式),如图中所示。
BPDU保护(Protection)¶
技术背景¶
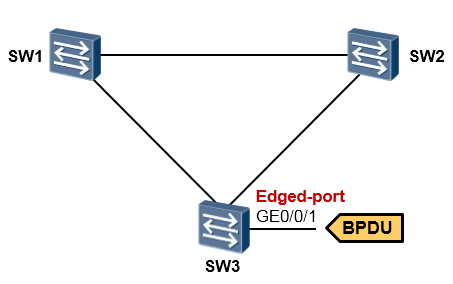
边缘端口一般用于直接和用户终端相连,正常情况下,边缘端口不会收到BPDU报文(因为连接的是终端,而不是交换设备)。但是如果攻击者伪造BPDU恶意攻击交换机那就会存在安全隐患(或者接口误接了交换机,那么就有可能产生环路),当边缘端口接收到BPDU时,设备会自动将边缘端口设置为非边缘端口,并重新进行生成树计算,这个过程就有可能引起网络的震荡。
通过使能BPDU保护可以防止伪造BPDU恶意攻击。
基本概念¶
交换机上启动BPDU保护功能后,如果边缘端口收到BPDU报文,设备将关闭(shutdown)这些端口, 同时通知网管系统。缺省情况下,交换机的BPDU保护功能并未开启。
配置实现¶
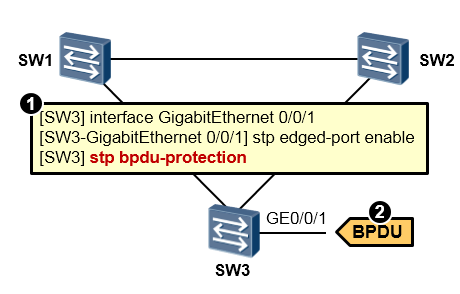
在上图所示的场景中,我们在SW3上将GE0/0/1 配置为边缘端口,随后在SW3上开启了BPDU-
Protection特性。当SW3的GE0/0/1口收到BPDU报文时,交换机将产生如下提示信息,并将GE0/0/1口shutdown:
此时在SW3上查看接口的STP信息如下:
要恢复被shutdown的BPDU受保护边缘端口,可使用手工在接口下执行**undo shutdown**命令的方式, 或者采用自动恢复的方式,即在系统视图下执行命令**error-down auto-recovery cause cause-item interval** interval-value,激活接口管理状态自动恢复为Up的功能,并设置接口自动恢复为Up的延时时间,使被关闭的端口经过延时时间后能够自动恢复。对于参数interval,取值范围是30~86400,单位是秒,配置时需要注意两点:
- 取值越小表示接口的管理状态自动恢复为Up的延迟时间越短,接口Up/Down状态震荡频率越高。
- 取值越大表示接口的管理状态自动恢复为Up的延迟时间越长,接口流量中断时间越长。
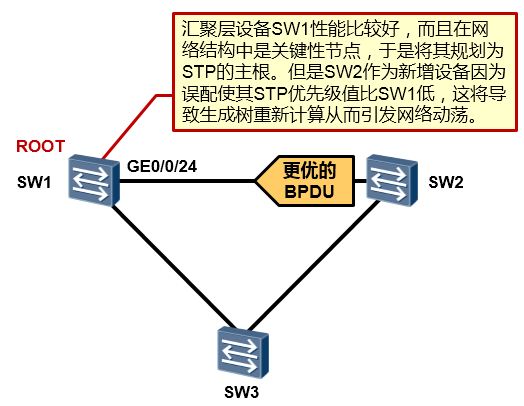
根保护(Root Protection)¶
技术背景¶
基本概念¶
在SW1的GE0/0/24口上部署了根保护后,当该接口再收到更优的BPDU报文后,SW1将这个接口切换到Discarding状态,如此一来SW1的根桥宝座就能够坐的很稳当。
配置实现¶
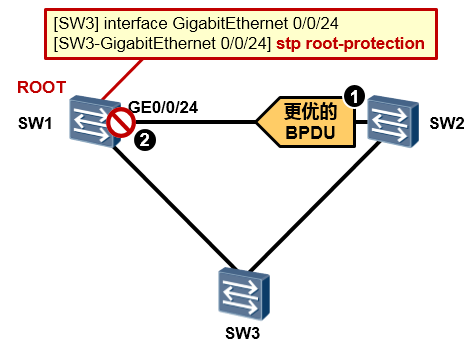
在交换设备上配置根保护功能,通过维持指定端口的角色来保护根交换设备的地位。根保护是指定端口上的特性。当端口的角色是指定端口时,配置的根保护功能才生效。若在其他类型的端口上配置根保护功能,则不会生效。
环路保护(Loop Protection)¶
技术背景¶
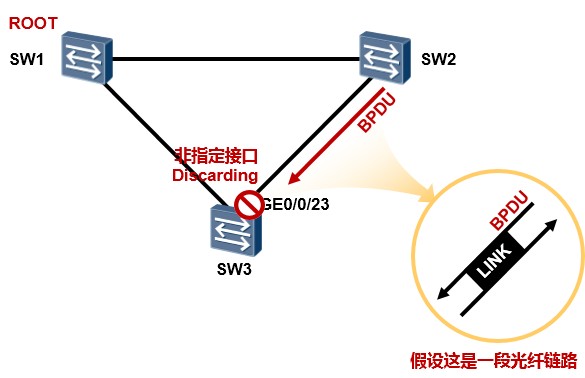
在上图所示的网络环境中,SW1为STP根桥,SW3的GE0/0/23由于被选举为非指定端口因此处于
Discarding状态,该接口虽然处于Discarding状态,但是仍然会持续侦听SW2发来的BPDU报文。
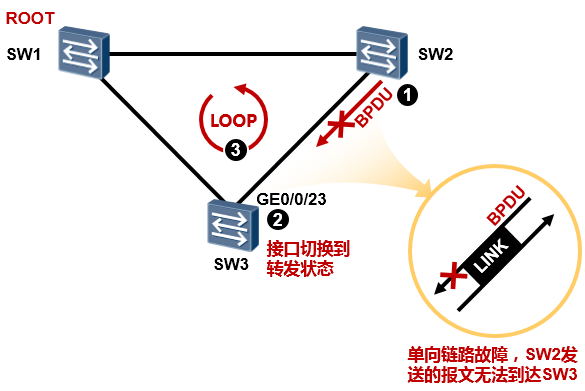
现在,SW2、SW3之间的链路突然发生了单向链路故障,SW2发送的报文无法到达SW3,这将导致SW3的GE0/0/23口无法再收到BPDU,因此它认为SW2发生了故障,于是重新进行STP计算,最终GE0/0/23 口的角色将切换成指定端口,而状态也将切换到转发状态,至此就出现了环路,因为从SW3到SW2的单向链路仍然在工作。
基本概念¶
交换机的根端口及处于Disacarding状态的接口会源源不断的收到BPDU报文,当这些端口由于链路的
单向故障导致收不到BPDU报文的时候,就会进行STP的重新计算。原来的根端口就会变成指定端口, 原来处于Discarding状态的端口会切换到Forwarding状态,从而导致环路的出现。
在根端口上启用了Loop Protection后,如果其端口角色发生变化,例如切换为指定端口,那么该端口将会被阻塞,也就是进入Discarding状态,直到再次收到BPDU。在阻塞端口上启用了Loop Protection后, 端口将一直处于Discarding状态,即使该端口被选举为指定端口。在STP中,此功能只能配置在根端口、替代端口及备份端口上。
配置实现1(该特性在根端口上部署)¶
LOOP Protection 部署前:¶
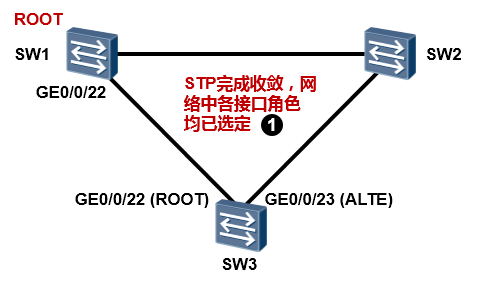
在STP完成收敛后,SW3的GE0/0/22口是根端口,GE0/0/23是替代端口处于Discarding状态。
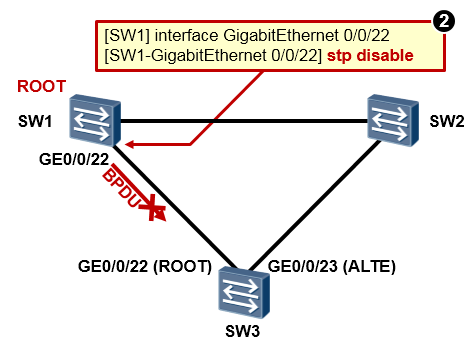
在SW1的GE0/0/22口上执行**disable stp**,来模拟链路出现单向故障的情况,如此一来SW3将无法再从GE0/0/22口收到ROOT SW1发送过来的BPDU了。
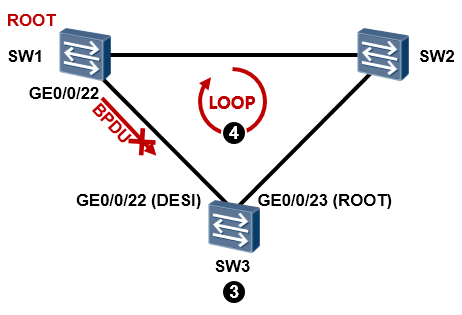
STP再次完成收敛后,SW3的GE0/0/23口被选举成为根端口,而GE0/0/22口成为指定端口,如此一来,环路就产生了。
LOOP Protection 部署后¶
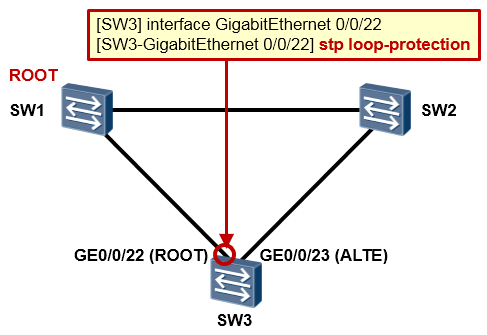
现在我们在SW3的GE0/0/22口上部署loop protection特性。
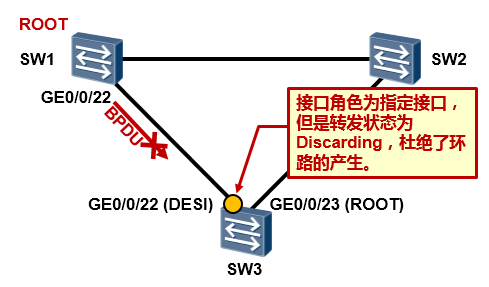
SW3重新进行STP的计算,GE0/0/23口成为根端口,GE0/0/22口成为指定端口,但是由于GE0/0/22口上部署了Loop Protection,因此该接口虽然角色为指定端口,状态却会保持在Discarding状态, 从而避免了环路的出现。
配置实现2(该特性在替代端口上部署)¶
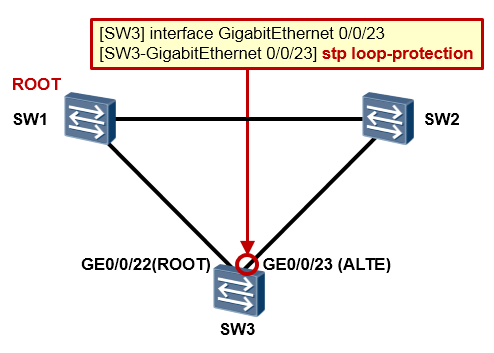
另外一个示例是,LoopProtection部署在替代端口上,如上图所示。
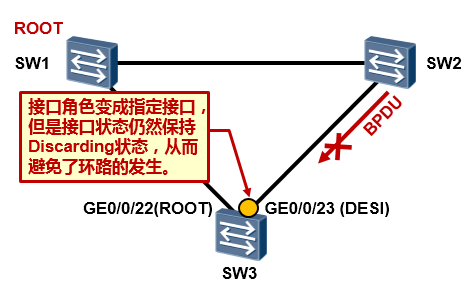
那么当SW2及SW3之间出现单向链路故障时,SW3将无法从GE0/0/23口再收到BPDU,于是SW3重新进行STP计算,此时GE0/0/23口成为了指定端口,但是由于配置了Loop Protection特性,因此该接口会保持在Discarding状态,从而避免了环路的产生。
TC Protection¶

设备在收到TC-BPDU后会执行MAC地址表项及ARP表项的删除操作,如果有攻击者伪造大量的TC-
BPDU报文对交换机进行攻击,交换机将频繁的进行上述表项的删除及刷新操作从而造成极大的负担,
给网络的稳定带来很大的隐患。
在交换机上开启TC-Protection后,交换机会在收到TC-BPDU后删除上述表项的同时启动周期为10s的定时器,在此周期内,如果交换机再次收到TC-BPDU报文,则最多可以进行1次删除上述表项的操作, 从而实现对交换机的保护。
- MSTP
背景¶
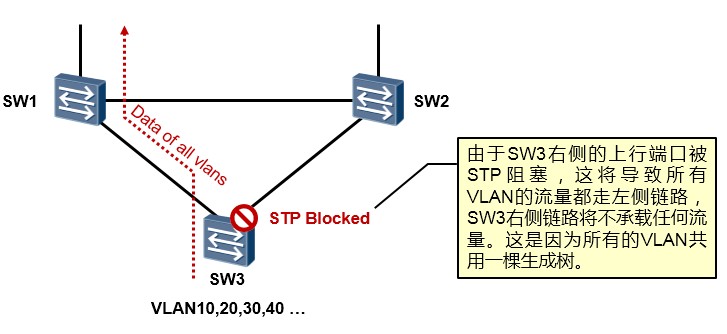
古老的STP 802.1D标准是所有VLAN共用一棵生成树,也就是说,不管交换网络中存在多少个VLAN,STP 计算的结果都是一棵生成树,拿上图来说,STP最终将如图所示的接口阻塞掉,这就造成所有VLAN的流量均走SW3的左侧链路,而右侧链路无法得到有效的利用。
于是后来业界又出现了perVLAN的生成树协议,也就是一个VLAN一棵生成树,如此一来,每个VLAN都有其自己独立的生成树,基于不同的VLAN,我们可以进行不同的优先级、接口开销的配置从而实现阻塞不同的端口,这样就能够实现不同的VLAN流量分流的目的。但是这种方案也是有一定弊端的,由于网络中的交换机需要为每一个VLAN单独进行生成树计算,因此当VLAN数量较多时,生成树的数量也是非常多的,网络的每一次震荡都将触发交换机们的重新计算,这是相当耗资源的。
这就提到了接下去要介绍的**MSTP(Multiple Spanning Tree Protocol)**,MSTP协议是IEEE 802.1S标准。所谓MSTP也就是多生成树实例,通过将多个VLAN映射到一个生成树实例(Instance),从而基于实例来计算生成树,同属于一个实例的VLAN享有同一棵生成树,不同的实例对应不同的生成树,这样,既可实现数据分流,又能够极大程度的减小交换机的计算负担。
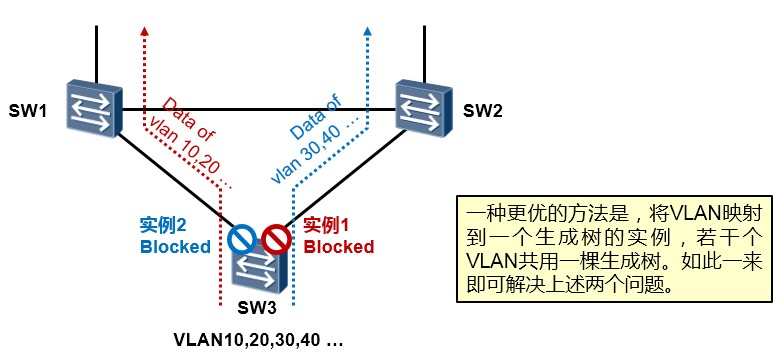
在上图所示的网络中,我们将VLAN10、VLAN20映射到MSTP实例1,将VLAN30、VLAN40映射到MSTP实例2(要求为三台交换机配置完全相同的VLAN与实例的映射关系),然后将SW1配置为实例1的主根、将
SW2配置为实例1的次根;将SW2配置为实例2的主根、将SW1配置为实例2的次根,如此一来,网络中就会针对实例1及实例2分别产生一棵生成树,而且阻塞不同的接口。那么VLAN10及VLAN20的流量即会从
SW3的左侧链路转发,而VLAN30及VLAN40会从右侧链路转发,流量即可实现负载分担。
基本术语¶
| 缩写 | 全称 | 描述 |
|---|---|---|
| MST Region | Multiple Spanning Tree Region | 一个域包含域名(Configuration Name)、修订级 别(Revision Level)、格式选择器(Configuration Identifier Format Selector)、VLAN与实例的映射关系(mapping of VIDs to spanning trees)等信息。 |
| MSTI | Multiple Spanning Tree Instance | MSTP的非实例0的其他实例 |
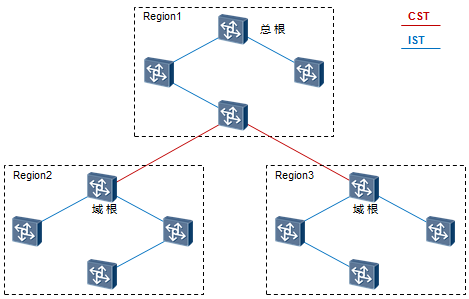
| CST | Common Spanning Tree 公共生成树 | 是连接交换网络内所有MST域的一棵生成树。如 果把每个MST域看作是一个节点,CST就是这些节点通过STP或RSTP协议计算生成的一棵生成树。 |
| IST | Internal Spanning Tree 内部生成树 | 内部生成树IST(Internal Spanning Tree)是各 MST域内的一棵生成树。 IST是一个特殊的MSTI,MSTI的ID为0,通常称为 MSTI0。IST是CIST在MST域内的一个片段。 |
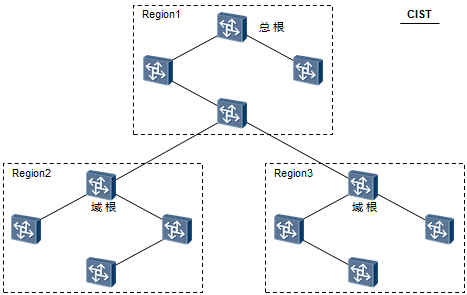
| CIST | Common Internal Spanning Tree 公共内部生成树 | 连接一个交换网络内所有交换设备的单生成树。 所有MST域的IST加上CST就构成一棵完整的生成树,即CIST。 |
|---|---|---|
| CIST Root | CIST Root 总根 | 总根是一个全局概念,对于所有互连的运行 STP/RSTP/MSTP的交换机只能有一个总根,也即是CIST的根 |
| 域根 | Regional Root | 分为IST(Internal Spanning Tree)域根和MSTI 域根 |
域¶
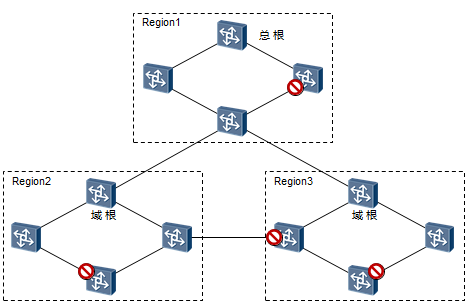
对于一个大型的交换网络,我们可以根据实际需要进行MSTP域的规划,当然如果网络规模有限,全网用一个域也是很平常的。一个“域”由同属一个域的交换机组成。例如在上图中,网络中存在三个MSTP域。
域包含域名(Region Name)、修订级别(Revision Level)、格式选择器(Configuration Identifier Format
Selector)、VLAN与实例的映射关系(mapping of VIDs to spanning trees)等内容,其中域名、格式选择器和修订级别在BPDU报文中都有相关字段,而VLAN与实例的映射关系在BPDU报文中表现摘要信息
(Configuration Digest),该摘要是根据映射关系计算得到的一个16字节签名。只有上述四者都一样且相互连接的交换机才认为在同一个域内。
同一个域内所有交换机都有相同的MST域配置。缺省时,域名就是交换机的桥MAC地址,修订级别等于0, 格式选择器等于0,所有的VLAN都映射到实例0上。
需强调的是:同一个域内的交换机,VLAN的映射必须完全一致。
实例¶
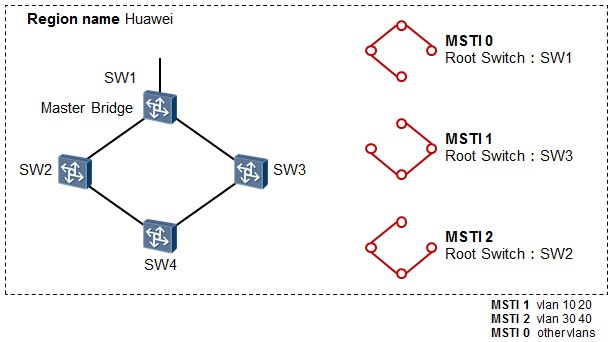
单独拿一个域来说,如上图所示,域名为Huawei,这个域包含四台交换机,域内存在多个VLAN,一共有三个MSTP实例,实例与VLAN的映射关系如下:
- MSTI 1:vlan 10 20
- MSTI 2:vlan 30 40
-
MSTI 0:其他(默认所有的VLAN都映射到实例0)
所谓“实例”就是多个VLAN的一个集合。在MSTP中,各个实例拓扑的计算是独立的,一个MSTP实例单独计算一棵生成树,在这些实例上就可以实现负载均衡。使用的时候可以把多个相同拓扑结构的VLAN映射到同一个实例中,这些VLAN在端口上的转发状态将取决于对应实例在MSTP里的转发状态。
端口角色¶
外部路径开销和内部路径开销¶
外部路径开销是相对于CIST而言的,同一个域内外部路径开销是相同的;内部路径开销是域内相对于某个实例而言的,同一端口对于不同实例对应不同的内部路径开销。
域边缘端口¶
域边缘端口是指位于MST域的边缘并连接其它MST域或SST的端口。
在进行MSTP计算的时候,域边缘端口在MSTI上的角色和CIST实例的角色保持一致,即如果边缘端口在CIST实例上的角色是Master端口(连接域到总根的端口),则它在域内所有MST实例上的角色也是
Master端口。
Alternate端口¶
从发送BPDU来看,Alternate端口就是由于学习到其它交换机的发送的BPDU而被阻塞的端口。从转发用户流量来看,Alternate端口提供了从指定交换机到根交换机的一条备份路径。
Alternate端口是根端口的备份端口,如果根端口被阻塞后,Alternate端口将成为新的根端口。
Backup端口¶
当同一台交换机的两个端口互相连接时就存在一个环路,此时交换机会将其中一个端口阻塞,Backup 端口就是被阻塞的那个端口。
从发送BPDU来看,Backup端口就是由于学习到自己发送的BPDU而被阻塞的端口。从转发用户流量来
看,Backup端口,作为指定端口的备份,提供了一条从根交换机到叶节点的备份通路。
Master端口¶
Master端口是MST域和总根相连的所有路径中最短路径上的端口,它是交换机上连接MST域到总根的端口。Master端口是域中的报文去往总根的必经之路。
Master端口是特殊域边缘端口,Master端口在IST/CIST上的角色是Root Port,在其它各实例上的角色都是Master。
基础配置:MSTP单实例部署¶
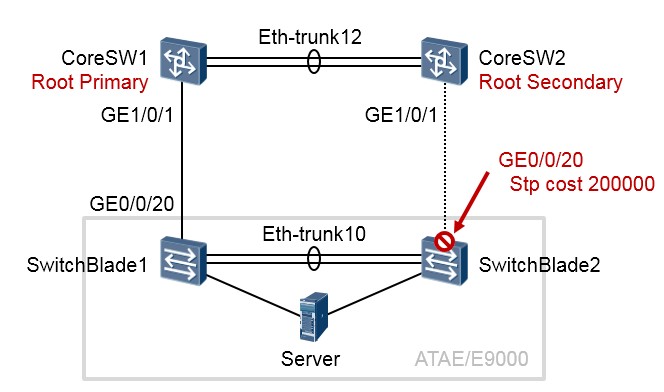
上图所示的拓扑是典型的电信软件数据网络组网场景, CoreSW1及CoreSW2 是两台核心交换机,
SwitchBlade1及SwitchBlade2是ATAE/E9000机框的两块交换板,您可以把它们也当做普通的交换机。这四台设备构成了一个口字型的二层环路。现在我们在四台设备上部署MSTP来消除环路,所有的交换机都加入相同的MSTP域,并且都使用一个实例,也就是实例0,缺省时所有的VLAN都映射到实例0。
我们将CoreSW1规划为主根桥,CoreSW2规划为次根桥,并且将SwitchBlade2上联核心交换机CoreSW2的接口的STP cost调节成一个非常大的值,从而使得该接口被MSTP阻塞,网络中存在的二层环路就此打破。另外,为了优化STP的运行,在所有交换机上开启TC保护及BPDU保护功能。参考配置如下:
CoreSW1:
CoreSW2:
ATAE/E9000交换板1:
ATAE/E9000交换板2:
对于CoreSW1而言,由于它是根桥,因此该设备所有接口的STP角色应该都是指定接口(Designated Port,
简写为DESI),而且所有的接口状态都是Forwarding:
| \<CoreSW1>display stp brief | ||||
|---|---|---|---|---|
| MSTID | Port | Role | STP State | Protection |
| 0 | GigabitEthernet1/0/1 | DESI | FORWARDING | NONE |
| 0 | Eth-Trunk12 | DESI | FORWARDING | NONE |
对于CoreSW2,其Eth-trunk12连接着根桥SW1,这个接口应该是根端口(Root Port,简写为ROOT),GE1/0/1
接口应该是指定端口,而且所有的接口状态都是Forwarding:
对于SwitchBlade1,其直连主根的接口GE0/0/20应该为根端口,Eth-trunk10端口为指定端口,而且所有的接口状态都是Forwarding:
对于SwitchBlade2,其Eth-trunk10接口应该为根端口,而GE0/0/20端口将处于Discarding状态,从而被阻塞,如此一来网络中不再存在二层环路:
| [SwitchBlade2] display stp brief | ||||
|---|---|---|---|---|
| MSTID | Port | Role | STP State | Protection |
| 0 | GigabitEthernet0/0/20 | ALTE | DISCARDING | NONE |
| 0 | Eth-Trunk10 | ROOT | FORWARDING | NONE |
常见问题¶
1. 由于实例与VLAN的映射不一致导致MSTP状态异常¶

SW1及SW2运行MSTP,SW1作为汇聚交换机,其上有VLAN:10、20、30、40;SW2作为接入层交
换机,其上只有VLAN10。
SW1的配置如下:
SW2的配置如下:
配置完成后,发现SW2的生成树状态异常,它认为自己是实例1的根。原因在于两台交换机的MSTP实
例1的VLAN映射不一致,导致SW2忽略SW1传递过来的关于实例1的信息,因此认为自己是根。将SW2 的配置修改如下:
即可,注意SW2上不需要创建VLAN 20 30 40(如果该交换机没有连接这几个VLAN的用户),也就是
说即使SW2没有创建VLAN 20 30 40也是能够按照上述配置,将VLAN 10 20 30 40映射到实例1。
- Smart Link 及 Monitor Link
技术背景¶
在一个交换网络中,为了提高网络的可靠性,我们会设计冗余的物理环境,然而冗余的物理环境会带来二层环路的问题,在此前的章节中已经介绍了STP生成树协议,利用STP确实可以解决环路的问题,但STP首先需要在参与到拓扑的每一台交换机上都进行配置,并且采用兼容的STP协议类型,再者需要依赖BPDU的泛洪才能够正常工作。另外,STP的计算也是比较缓慢的,这使得当拓扑发生变更时,STP的收敛可能需要数秒的时间,而这在某些业务场景中是不可接受的,例如对延迟非常敏感的业务。实际上,对于现代园区网而言,STP虽然曾经是二层交换网络的典型应用,但是正在被逐步取代。
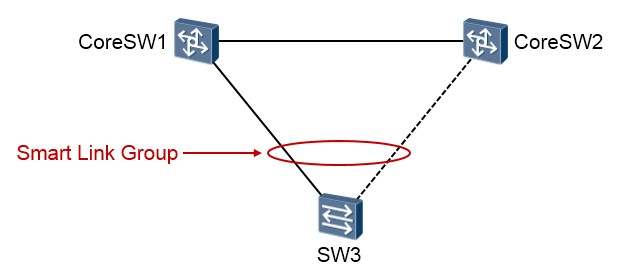
Smart Link是一种为双上行组网量身定做的解决方案。什么叫双上行组网呢?说的好像很流弊似的,其实非常简单,拿上面的拓扑来说,SW3有两根链路上联到核心交换机,这就是双上行组网。Smart Link在这种组网中,被部署在SW3上。Smart Link具有如下特点:
- 在双向行的设备上部署,当网络正常时,这两根上行链路其中一根处于活跃状态,而另一根链路处于备份状态从而被阻塞。如此一来环路就会被打破。
- 当主用链路发生故障后,流量会在**毫秒级**的时间内迅速切换到备用链路上,保证了数据的正常转发。
- 配置简单,便于用户操作。
- 无需协议交互报文,因此大大提升的收敛的速度和可靠性。
- Smart Link是华为私有特性。
基础术语¶
Smart Link Group¶
Smart Link组,也称为灵活链路组,一个Smart Link组包含两个成员接口,一个主接口(Master Port) 一个从接口(Slave Port)。正常情况下,只有一个接口(主接口或从接口)处于活跃(Active)状态, 另一个接口处于非活跃(Inactive)状态被阻塞。
当处于活跃状态的接口出现链路故障时(这里的链路故障包括接口down、OAM单通等),Smart Link
组会自动将该接口阻塞,并将原阻塞的、处于非活跃状态的接口切换到活跃状态,开始转发数据。
Master/Slave接口¶
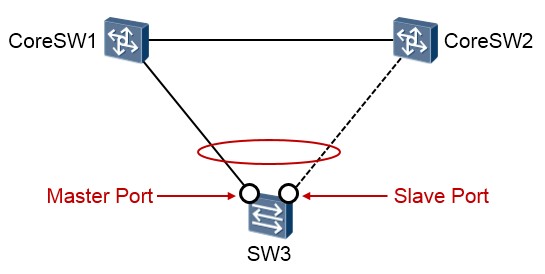
主/从接口是Smart Link组中的两个接口角色,是通过命令指定的。当两个接口都正常工作时,主接口进入active状态,而从接口保持inactive。当主接口或其所在链路发生故障时,从接口切换为active。
发送控制VLAN¶
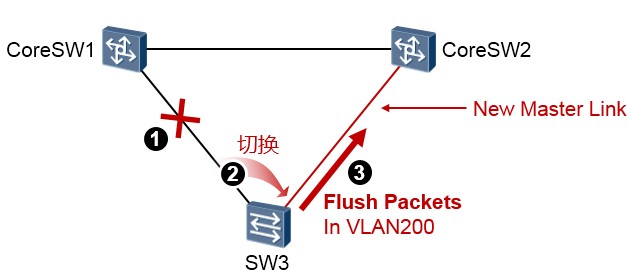
发送控制VLAN(Send Control VLAN)是Smart Link组用于泛洪flush报文的VLAN。在上图中,当SW3 交换机发生SmartLink的切换时——显然是网络拓扑发生了变化——这个变化可能对于网络中的其他设备来说(例如上游交换机CoreSW1及CoreSW2)并不一定能够“感知”,此刻对于它们而言原有的
MAC表等表项可能已经不可用了,必须尽快刷新,flush报文就是用来刷新他们的相关表项的。
如果在SW3上开启了flush报文发送功能,当发生链路切换时,设备会在新的主用链路上、在发送控制
VLAN内组播发送flush报文,以便刷新上游交换机的相关转发表项,加快网络收敛。
接收控制VLAN¶
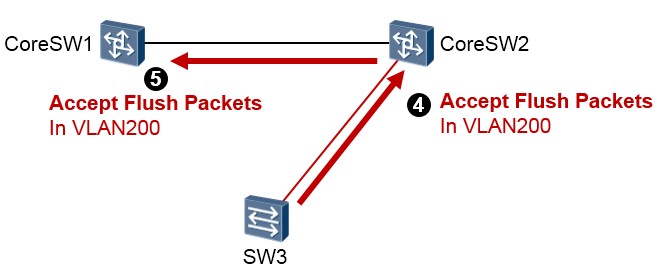
接收控制VLAN是上游设备用于接收并处理flush报文的VLAN。如果上游设备CoreSW1及CoreSW2能够识别flush报文,并开启了flush报文接收处理功能,当发生链路切换时,上游设备会处理收到的属于接收控制VLAN的flush报文,进而执行MAC地址转发表项和ARP表项的刷新操作。要注意在SW3上配置的发送控制VLAN要和CoreSW1及CoreSW2上配置的接收控制VLAN一致。
工作机制¶
拓扑环境¶
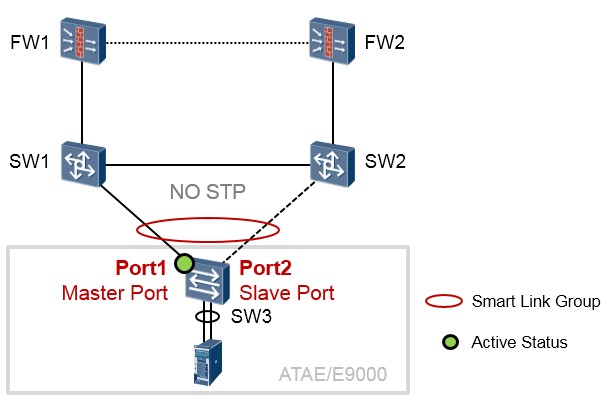
上图展示的是一个使用了ATAE/E9000的典型组网。SW1及SW2是核心交换机,SW3是部署了堆叠的交换板卡,可以将其理解为一台交换机。此时SW3正是双链路上行,这个场景非常适合部署Smart Link。值得注意的是Smart Link是配置在SW3交换机上的,其他的交换机上无需配置。在SW3上创建一个Smart Link组,然后将Port1添加到该组中,并设置其接口角色为Master;同时将Port2口也添加到该Smart Link组中,并设置其角色为Slave。
网络工作正常时¶
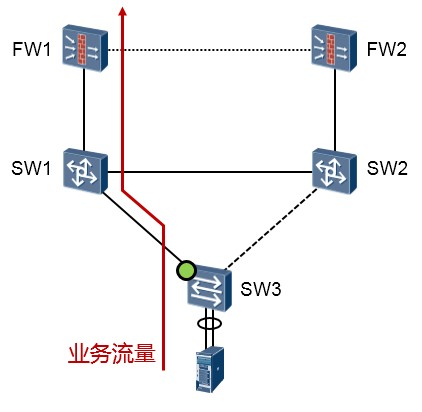
当网络工作正常时,也就是双上行链路都正常的情况下,Master口Port1处于活跃状态(Active),其所在的链路是主用链路(Master Link);Slave端口处于非活跃状态(Inactive),所在链路是备用链路。如此一来,SW3的Port2相当于被阻塞了,不会转发数据,因此数据沿着红色线条所表示的路径进行传输,网络中不存在环路,不会产生广播风暴。
网络发生故障时¶
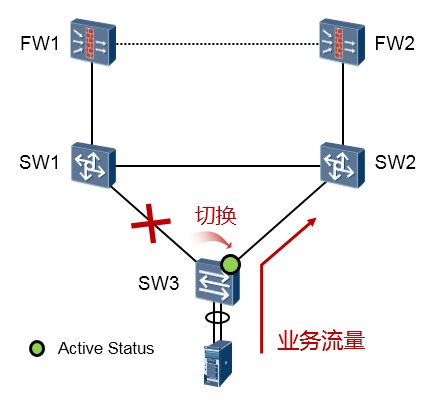
当SW3的Port1或者其直连的链路发生故障时,Master端口Port1切换到Inactive状态,Slave端口Port2 切换到Active状态。这个过程是以非常快的速度完成的,因为无需任何的协议报文的交互,完全由SW3 设备自己感知、完成切换,所以收敛的速度是毫秒级别。
网络拓扑变更机制¶
机制概述¶
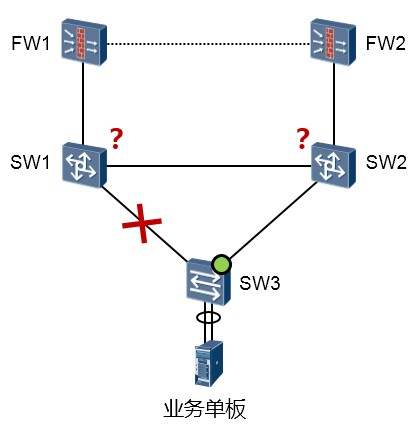
当 Smart Link 发生链路切换时,网络中各设备上的MAC地址转发表项和ARP/ND表项可能已经不是最
新状态,为了保证报文的正确发送,需要提供一种MAC地址转发表项和ARP/ND表项的更新机制。目前更新机制有以下两种:
-
由Smart Link 设备从新的Master 链路上发送flush报文。此方式需要上行的设备都能够识别
SmartLink的flush报文并进行更新MAC地址转发表项和ARP/ND表项的处理。
- 自动通过流量刷新MAC地址转发表项和ARP/ND表项。此方式适用于和不支持Smart Link功能的设备(包括其他厂商设备)对接的情况,需要有上行的流量触发。
方式一:通过flush报文通知设备更新表项¶
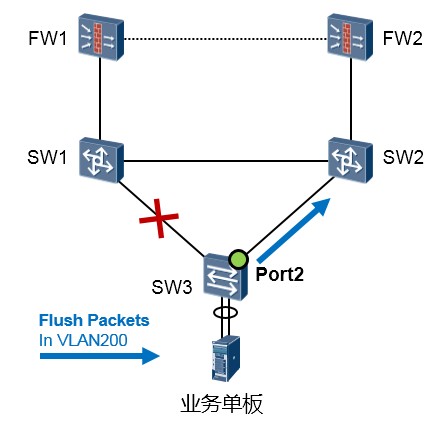
这种方式适用于上游设备(如图中的SW1、SW2)支持SmartLink功能、能够识别flush报文的情况。为了实现快速链路切换,需要在SW3上开启flush报文发送功能,另外,在上游设备所有处于双上行网络的接口开启接收处理flush报文功能。
SW3发生链路切换后,会在新的主用链路上发送flush报文。Flush报文的VLAN Bitmap字段填充链路切换前组内处于转发状态的Port1口所在Smart Link组的保护VLAN ID,Control VLAN ID 字段填充Smart
Link组配置的发送控制VLAN ID。
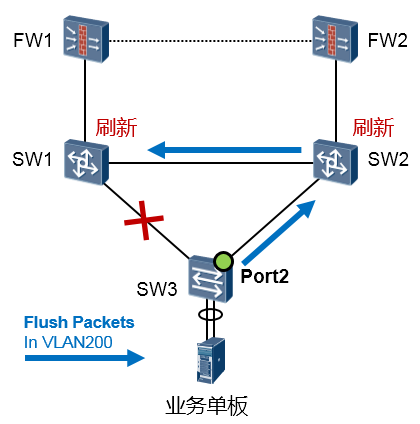
当上游设备收到flush报文时,判断该flush报文的发送控制VLAN是否在收到报文的端口配置的接收控制
VLAN列表中。如果不在接收控制VLAN列表中,设备对该flush报文不做处理,直接转发;如果在接收控制VLAN列表中,设备将提取flush报文中的VLAN Bitmap数据,将设备在这些VLAN内学习到的MAC 及ARP表项删除。
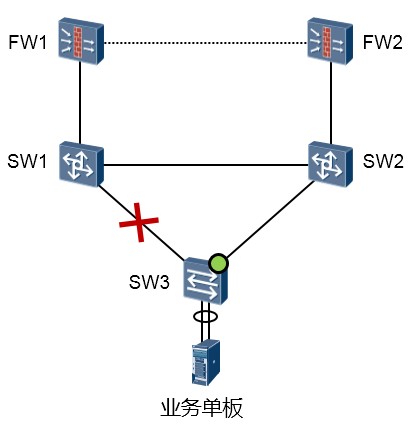
为了保证flush报文在发送控制VLAN内正确传送,请确保双上行网络上的所有端口都允许发送控制
VLAN通过,否则,flush报文将发送或转发失败。建议以保留Tag的方式发送flush报文,若想以去掉Tag 的方式发送flush报文,需确保对端端口缺省VLAN和发送控制VLAN一致,否则将导致flush报文不在发送控制VLAN内传送。
方式二:无flush方式¶
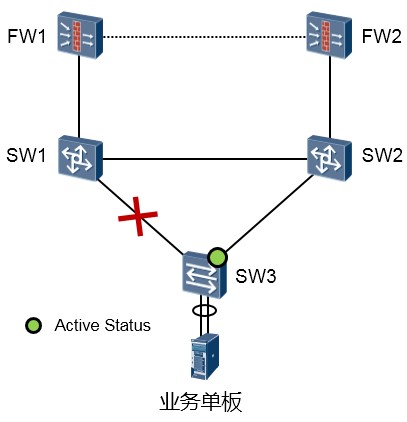
这种方式适用于与不支持Smart Link功能的设备(包括其他厂商设备)对接的情况,需要有上行流量触发。例如上图中SW3是支持Smart Link的设备,而SW1、SW2不支持Smart Link的情况。
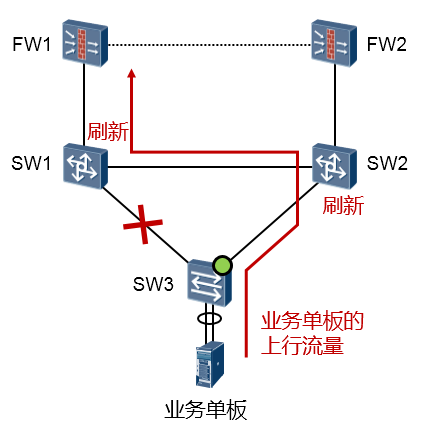
如果没有SW3的上行流量(这些流量可能来自SW3下联的终端)去触发SW1、SW2的MAC及ARP表项更新,那么当SW1、SW2收到目的设备为业务单板的数据时,流量就可能会发生中断。以SW2为例, 如果其关于下游业务单板的MAC地址表项的关联接口还是老旧的(还是关联到与SW1对接的接口), 那么当SW2有下行流量要转发(外部网络发往业务单板的流量)时,只有在其表项自动老化、重新学习后,流量才能被正确发送到SW3。当业务单板的上行流量通过SW3到达SW2后,后者会更新自己的
MAC表,那么当SW2再收到目的MAC为业务单板MAC地址的数据时,SW2会通过其连接SW3的接口转发出去,报文才可以经由SW3到达单板。因此这种方式相比于通过Flush报文的方式而言,效率就要低得多。
通过flush报文通知设备更新的机制无须等到表项老化后再进行更新,可以大大减少表项更新所需时间。
一般情况下,链路的整个切换过程可在毫秒级的时间内完成的,基本无流量丢失。但是要求上联的交换机都支持Smart Link功能。
链路恢复机制¶
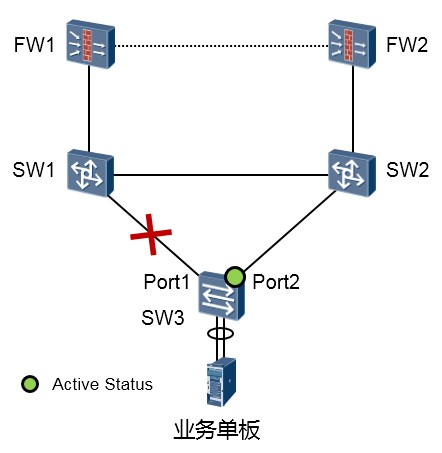
在上图中SW3交换机的Port1口为Smart Link组的Master接口,Port2口为Slave接口。缺省时,Port1为active 状态。现在,Port1口或其直连链路发生了故障,导致Smart Link组发生切换,Slave接口Port2处于active状态,那么当Master接口Port1恢复后,会发生什么事情呢?
Smart Link组支持两种模式:角色抢占模式和非角色抢占模式。
角色抢占模式:¶
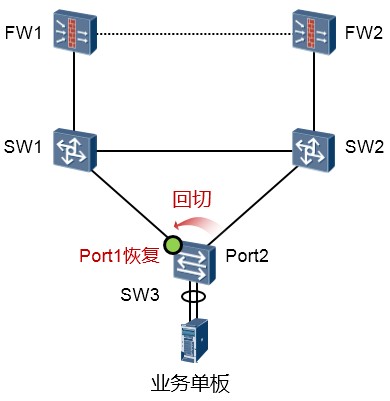
若Smart Link组配置为角色抢占模式,当主用链路故障恢复后,Master接口将抢占为active状态,Slave
接口则进入inactive状态,如上图所示。
非角色抢占模式:¶
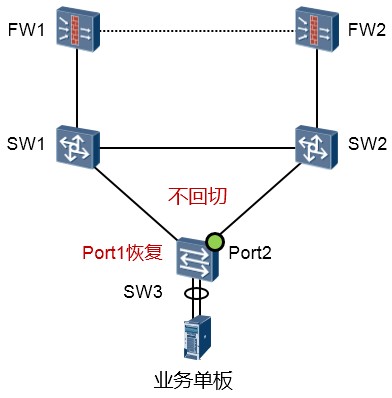
若Smart Link组配置为非角色抢占模式,当Master Link从故障中恢复后,Port2将继续处于active状态,
Master口Port1继续处于inactive状态,这样可以保持流量的稳定。缺省情况下就是非抢占模式。使用**smart-link manual switch**命令可手工执行链路倒换。
配置及验证¶
实验拓扑¶
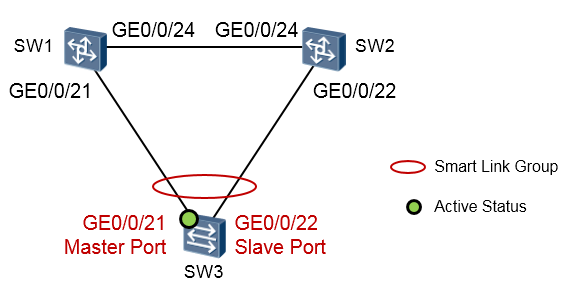
内网有VLAN10及20(SW3下挂的用户,在上图中并未画出);VLAN99为Smart Link控制VLAN。在SW3上创建SMLK组, GE0/0/21为Master 口; GE0/0/22为Slave口。内网流量在网络正常时走
GE0/0/21,当GE0/0/21挂掉的时候自动切换到GE0/0/22;当GE0/0/21故障恢复的时候,能重新进入转
发状态,流量仍然从GE0/0/21进行转发。
配置及实现¶
SW3的配置如下:
[SW3] vlan batch 10 20 99
#配置接口类型为trunk并放行相关VLAN(用户VLAN及控制VLAN) [SW3] Interface gigabitethernet0/0/21
[SW3-gigabitethernet0/0/21] port link-type trunk
[SW3-gigabitethernet0/0/21] port trunk allow-pass vlan 10 20 99 [SW3] Interface gigabitethernet0/0/22
[SW3-gigabitethernet0/0/22] port link-type trunk
[SW3-gigabitethernet0/0/22] port trunk allow-pass vlan 10 20 99
#关闭接口下的STP。加入到Smart Link组的接口必须关闭STP: [SW3] Interface gigabitethernet0/0/21
[SW3-gigabitethernet0/0/21] stp disable [SW3] Interface gigabitethernet0/0/22 [SW3-gigabitethernet0/0/22] stp disable
#创建Smart Link Group1 [SW3] smart-link group 1
[SW3-smlk-group1] port gigabitethernet0/0/21 master #添加接口GE0/0/21到Smartlink组并指定为Master接口
[SW3-smlk-group1] port gigabitethernet0/0/22 slave #添加接口GE0/0/22到Smartlink组并指定为Slave接口 [SW3-smlk-group1] flush send control-vlan 99 password simple 123 #配置发送控制VLAN并设置密码 [SW3-smlk-group1] restore enable #激活回切功能,缺省时,该功能为关闭状态
SW1的配置如下:
SW2的配置如下:
| 完成上述配置后,我们来做一下验证及查看: | ||||
|---|---|---|---|---|
| [SW3] display smart-link group 1 Smart Link group 1 information : Smart Link group was enabled Wtr-time is: 30 sec. There is no Load-Balance There is no protected-vlan reference-instance DeviceID: 4c1f-cc2c-1dd9 Control-vlan ID: 99 Member Role State Flush Count Last-Flush-Time ----------------------------------------------------------------------------------------------------------------------- | ||||
| GigabitEthernet0/0/21 | Master | Active | 1 | 2014/09/02 14:02:34 UTC-08:00 |
| GigabitEthernet0/0/22 | Slave | Inactive | 0 | 0000/00/00 00:00:00 UTC+00:00 |
| 从上面的输出可以看到,GE0/0/21口目前处于active状态,而GE0/0/22口处于inactive状态。接下去看 看当SW3的GE0/0/21口发生故障时,发生的现象。手工将SW3的GE0/0/21口shutown。 | ||||
| [SW3]display smart-link group 1 Smart Link group 1 information : Smart Link group was enabled Wtr-time is: 30 sec. There is no Load-Balance There is no protected-vlan reference-instance DeviceID: 4c1f-cc2c-1dd9 Control-vlan ID: 99 Member Role State Flush Count Last-Flush-Time ----------------------------------------------------------------------------------------------------------------------- | ||||
| GigabitEthernet0/0/21 | Master | Inactive | 1 | 2014/09/02 14:02:34 UTC-08:00 |
| GigabitEthernet0/0/22 | Slave | Active | 1 | 2014/09/02 14:05:34 UTC-08:00 |
我们看到GE0/0/21口的状态变成了inactive,而GE0/0/22口的状态变成了active。同时GE0/0/22口的
Flush Count变成了1,表示在拓扑变更后,向GE0/0/22口发送过一次Flush报文。
Monitor Link¶
技术背景¶
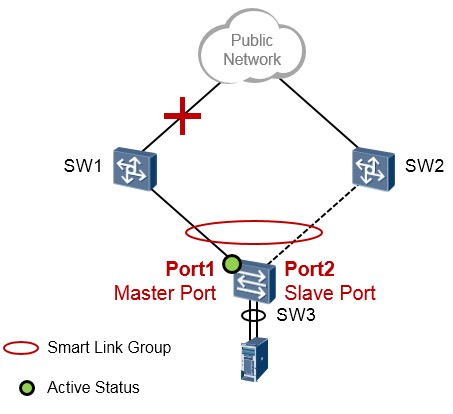
考虑上面的拓扑,由于SW3交换机是双上行的组网,非常适合部署Smart Link,因此我们将交换机的生成树关闭,并且部署Smart Link,将Port1口设置为Master接口,Port2口设置为Slave接口。当Port1口或者其直连链路发生故障时,SW3交换机能够感知并且迅速切换,但是如果SW1的上行接口发生故障,如图所示,SW3交换机是无法感知的,因此也就无法实现切换。为了解决这个问题,需要一个新的技术与Smart Link搭配使用,这就是Monitor Link。
关于Monitor Link¶
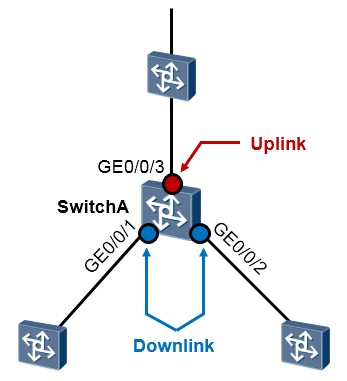
Monitor Link组也称为监控链路组,由一个或多个上行和下行接口组成。下行接口的状态随上行接口状态的变化而变化。
-
上行接口(Uplink Port)是Monitor Link组中的监控对象,是通过命令行指定的Monitor Link组的一种接口角色。如果多个接口被配置为Monitor Link组的上行接口,只要这些接口中有一个接口处于转发状态,那么Monitor Link组的状态就为UP;只有当所有上行接口都发生故障时,Monitor Link 组的状态才为Down,这时所有下行接口将都将被关闭。当Monitor Link组的上行接口未指定时,则认为上行接口故障,所有下行接口都将被关闭。
-
下行接口(Downlink Port)是Monitor Link组中的监控者,是通过命令行指定的Monitor Link组的另外一种接口角色。Monitor Link组的下行接口可以是以太网接口(电口或光口)或聚合接口(Eth-
trunk接口)。
-
当Monitor Link组的上行接口恢复正常时,Monitor Link只会开启因上行接口故障而被Monitor Link 阻塞的下行接口,不能开启通过命令shutdown手工关闭的下行接口。并且某个下行接口故障对上行接口和其他下行接口没有影响。
-
Smart Link与Monitor Link的搭配¶
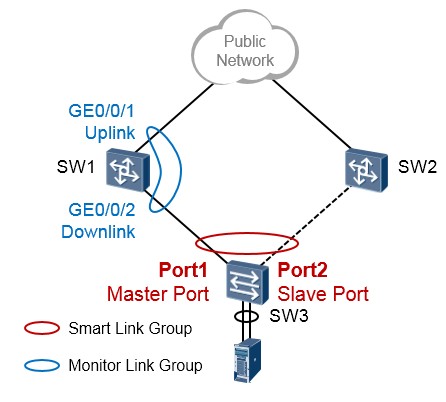
在上图中,我们在SW3交换机上部署Smart Link。同时在SW1上部署Monitor Link,将SW1的GE0/0/1
设置为Uplink接口,将SW1的GE0/0/2设置为Downlink接口。
如此一来,当SW3交换机的Port1接口或者与SW1之间的互联链路发生故障,SW3交换机的Smart Link 能够实现切换。而当SW1交换机的上行接口GE0/0/1接口发生故障或者其与Public Network之间的链路发生故障的话,SW1的GE0/0/1口将会立即down掉,而这将导致SW1的GE0/0/2被Monitor Link关闭, 这样一来SW3交换机的Port1也就Down了,于是Smart Link能够进行正常的切换。如下图所示:
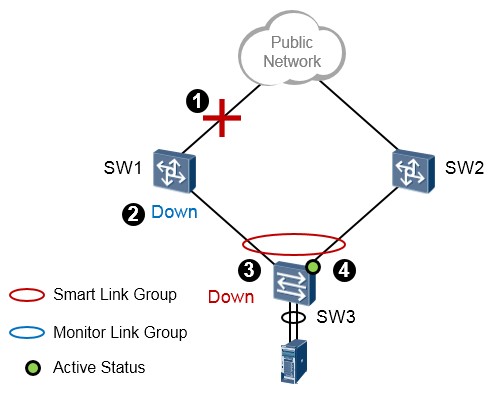
实验验证¶
先做一个简单的测试,在SW1验证一下Monitor Link:
完成后检查一下配置:
| Recover-timer is 3 sec. | ||||
|---|---|---|---|---|
| Member | Role | State | Last-up-time | Last-down-time |
| GigabitEthernet0/0/1 | UpLk | UP | 0000/00/00 00:00:00 UTC+00:00 | 0000/00/00 00:00:00 UTC+00:00 |
| GigabitEthernet0/0/2 | DwLk[1] | UP | 0000/00/00 00:00:00 UTC+00:00 | 0000/00/00 00:00:00 UTC+00:00 |
| 从上述输出可以看出,uplink接口GE0/0/1是UP的,因此downlink接口GE0/0/2也是UP的。接着我们把 GE0/0/1口shutdown,然后就能观察到: | ||||
| [SW1] display monitor-link group 1 Monitor Link group 1 information : Recover-timer is 3 sec. | ||||
| Member | Role | State | Last-up-time | Last-down-time |
| GigabitEthernet0/0/1 | UpLk | DOWN | 0000/00/00 00:00:00 UTC+00:00 | 2014/09/09 10:26:40 UTC-08:00 |
| GigabitEthernet0/0/2 | DwLk[1] | DOWN | 0000/00/00 00:00:00 UTC+00:00 | 2014/09/09 10:26:41 UTC-08:00 |
随着uplink接口down掉,downlink接口GE0/0/2也被自动地shutdown。
- 实现 VLAN 间的互访
- 通过子接口实现 VLAN 间的互访
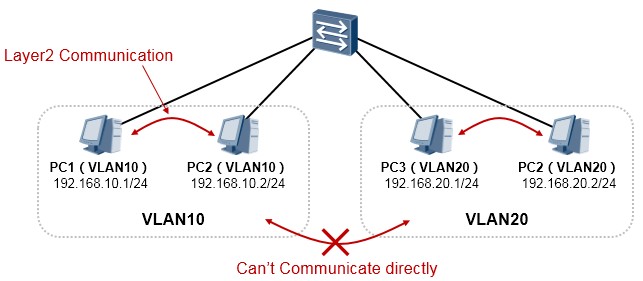
在二层交换环境下,一个VLAN就是一个广播域,相同VLAN内的节点如果配置相同网段的IP地址即可直接通信,我们将这种通信称为二层通信。不同VLAN是不同的广播域,一般也是不同的逻辑子网,而且相互隔离,无法直接互访,这样能起到隔绝广播的作用,如上图所示。
但是实际网络中往往VLAN之间有互访的需求,例如同一公司不同的部门划分在不同的VLAN,那么如果这些部门之间有数据往来的需求呢,此时二层交换机就无法实现了,需要借助三层设备(路由设备)。一个最简单的方法,就是使用路由器:
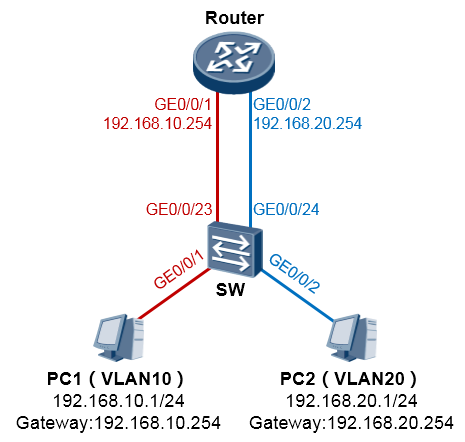
在上图中,交换机将GE0/0/1及GE0/0/23口都配置为access类型并都加入VLAN10;将GE0/0/2及GE0/0/24
都配置为access类型并都加入VLAN20。然后将路由器Router的GE0/0/1口作为VLAN10用户的网关,
GE0/0/2作为VLAN20用户的网关,从而利用路由器的路由功能实现两个VLAN之间的互访,这么做看似可行,但是一个VLAN就需要路由器拿出一个接口,那么如果内网有10个VLAN呢?路由器表示鸭梨很大。所以另一种稍微改进点的方法是,在路由器的一个物理接口上,配置逻辑的子接口(Sub-interface)来实现同样的需求,这种解决方案叫单臂路由:
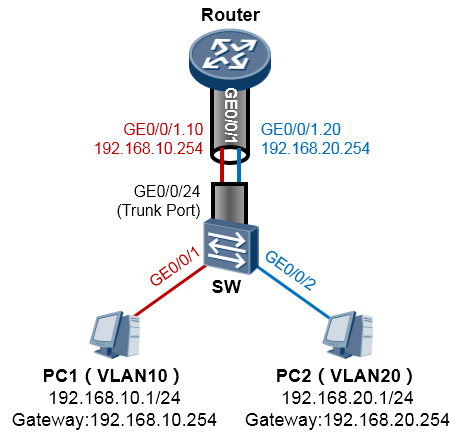
在上图中,交换机与路由器之间仅需一根物理链路即可,这段链路由于要承载多VLAN的数据,因此在交换机上就要将与路由器对接的接口(GE0/0/24)设置为Trunk类型。路由器这边呢虽然只有一个物理接口
(GE0/0/1)与交换机相连,但是我们可以基于这个物理接口创建多个子接口,子接口GE0/0/1.10对应
VLAN10,它能够识别VLAN10的标记,并且能够处理带VLAN10标记的数据帧,同理GE0/0/1.20对应
VLAN20。如此一来,在路由器上仅使用一个物理接口,即可支持多个VLAN的数据。
子接口是一个软件的、逻辑的接口,是基于物理接口创建的。路由器会把子接口当成是一个普通接口来对待。通过子接口的方式我们可以大大的节省硬件成本。具体的配置如下:
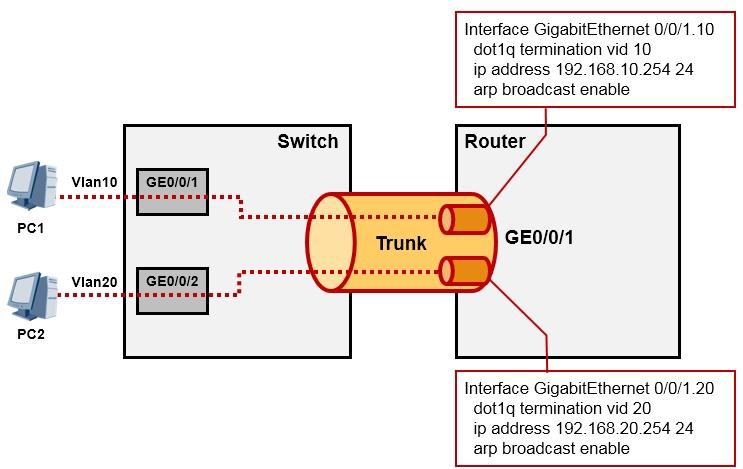
完成如上配置后,交换机连接PC的接口添加到相应的VLAN则PC即可互通。从上面这个碉堡的图可以更加形象地理解子接口的概念,其实就是相当于在一个大管道里套着两个小管道。值得注意的是一旦我们在物理接口上创建了子接口,那么后续的配置将不会再在物理接口上做,而是在子接口上进行,我们只要保证物理接口没有被shutdown即可。
以太网子接口技术可部署在路由器上,也可以部署在防火墙上,我们来看一个例子。
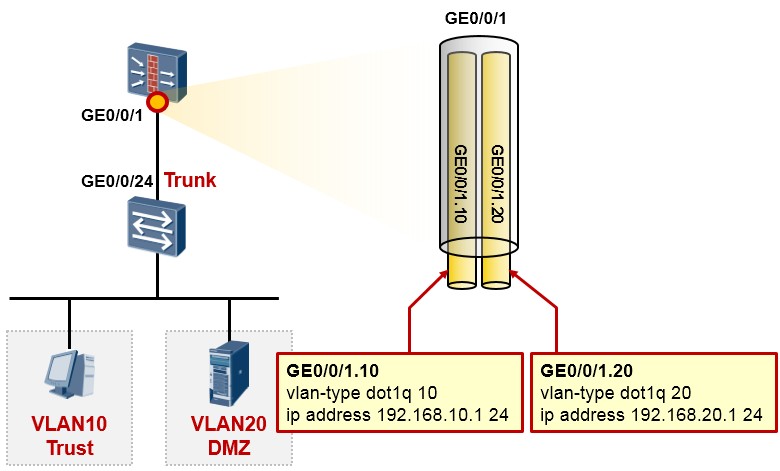
上面是一个非常简单的组网场景,站点内网有两个VLAN,VLAN10及VLAN20。现在的需求是,要求VLAN10 及VLAN20能够实现互访,而且互访流量必须经过防火墙做安全检查。VLAN10内的网元非常重要,属于高安全级别的网络,而VLAN20内的网络则安全级别更低。
解决的办法:¶
上图中的交换机工作在二层模式,连接终端的接口配置为access类型并且分别加入到相应的VLAN。同时交换机连接防火墙的接口GE0/0/24配置为Trunk类型并且放通VLAN10及VLAN20。
随后在防火墙的GE0/0/1口上创建两个子接口:GE0/0/1.10及GE0/0/1.20,子接口的配置如图所示,这两个子接口分别对应VLAN10及VLAN20。最后别忘了要将子接口添加到相应的安全域中,例如VLAN10这个网络如果比较重要,则可将防火墙的GE0/0/1.10接口添加到高安全级别的区域,如Trust,而VLAN20可能需要接受来自外部的访问,因此规划在DMZ域,故将子接口GE0/0/1.20添加到DMZ区域。接下去就可以部署域间包过滤规则了。
- 通过 vlan-interface 实现 VLAN 间的互访
在理解了子接口之后,再来看看三层交换机是如何实现VLAN间的数据互访的,从这里切入,开始理解并部署三层交换。我们知道二层交换机是可以实现二层交换的,它关心的是数据帧,对帧头的二层信息进行读取并且根据自己的MAC地址表进行转发。而三层交换机相当于在二层交换机的基础上,多了个路由模块,于是乎它就能支持路由功能了:支持路由选择协议、支持三层数据转发、支持IP路由查找、支持三层接口等等。
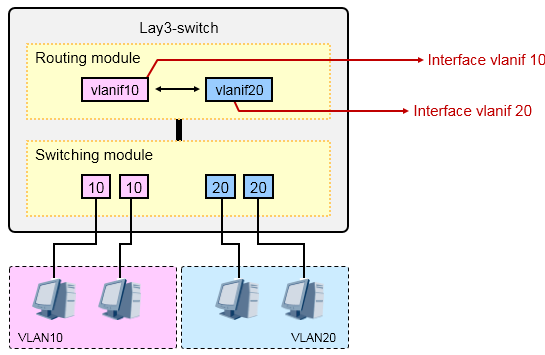
先来认识一下vlan-interface(简称vlanif),这是一个逻辑接口,也就是说这并不是一个真实的物理接口, 当我们在交换机上创建了一个VLAN之后,紧接着就可以创建一个与这个VLAN对应的vlanif,例如我们创建了VLAN10,那么VLAN10对应的vlanif就是interface vlanif 10,这个vlanif10是一个三层接口,你可以为这个
vlanif10配置IP地址,与VLAN10内的PC用户的IP地址同一网段,这样一来,VLAN10内的用户就能够将网
关指向这个vlanif,当VLAN10的PC需要访问本网段以外的网络时,它们将数据交给网关,也就是vlanif10, 再由三层交换机去做路由查找及数据转发。实际上,在这个理解过程中,我们可以拿单臂路由那个模型对类比。
所以看上面这图,在三层交换机上创建了两个VLAN:10和20,同时为两个VLAN的vlanif分配了地址作为各自VLAN的用户网关,这样一来,这台交换机的路由表里就有了两个VLAN网段的路由。那么当两VLAN之间要互访时,VLAN10的用户将数据丢给自己的网关,也就是vlanif10,数据到了vlanif10之后,三层交换机查看数据包的目的地址IP并在路由表中进行匹配,发现目的地是VLAN20的所在网段,因此将数据从VLAN20 扔出去,最终抵达目的地的VLAN20的PC。
Vlanif的基础配置:¶
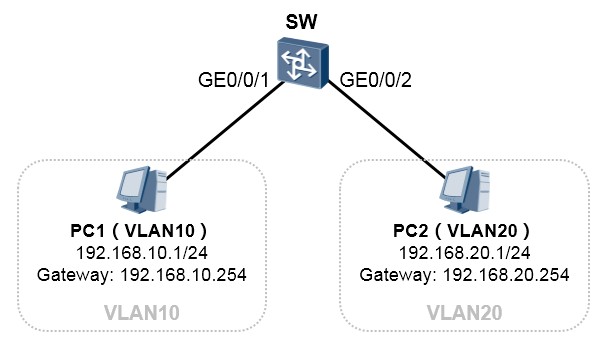
实验拓扑如上图所示。PC1及PC2分别位于VLAN10及VLAN20,现在要求完成三层交换机SW的配置,使得两个VLAN的用户能够相互通信。
SW的配置如下:
[SW-vlanif10] ip address 192.168.20.254 24
完成上述配置后,PC1将自己的IP地址设置在192.168.10.0/24网段,同时将网关配置为192.168.10.254;
PC2的IP地址则配置在192.168.20.0/24,网关设置为192.168.20.254,两者就能够互相通信了。
二、三层交换机、路由器简单组网:¶

实验拓扑如上图所示。PC1及PC2分别处于VLAN10及VLAN20,它们的缺省网关都设置在三层交换机SW2 上。SW1是接入层交换机,只具备二层交换功能。SW2与路由器Router实现三层对接,用于两者对接的VLAN 是VLAN99。上述拓扑,我们可以画一个逻辑图来帮助理解:

SW1的配置如下:
SW2的配置如下:
Router的配置如下:
- 链路聚合
- 链路聚合技术背景
在一个网络中,某些关键链路承载的流量可能非常大,链路的负载可能会很高,带宽就会成为数据传输的瓶颈。如果增加带宽,那就需要增加硬件投入,例如将链路从千兆电口换成万兆光纤接口,这就不得不增加成本。另一个问题是单点故障的问题,一旦这根链路发生故障,那么不可避免的将影响到网络的可达性。如下图所示:
以太网链路聚合技术(Link Aggregation),或者称为端口捆绑、链路捆绑技术,是一种通用的以太网技术。通过该技术,我们能够将多条以太网链路进行“捆绑”,捆绑之后的这些物理链路就形成了逻辑上的一条新的链路(Eth-Trunk),这条聚合链路不仅仅在带宽上成倍的增加,还同时提供了负载均衡及链路冗余。有人可能会问,为啥要那么麻烦,交换机之间多连几根线不就完了么?多连几根线实际上就多创造了几个环路,这时由于生成树的作用,必然会阻塞掉几个端口,如此一来仍然只有一条链路在转发数据,还是达不到我们的预期。但是使用链路聚合功能,则可将这几根链路捆绑成逻辑上的一条,交换机会将捆绑后的这根聚合链路当做一条链路来对待,自然也就不存在环路的问题了。

举个非常简单的例子,上图中,两台交换机的GE0/0/1到GE0/0/2接口两两对接,如果在SW1及SW2上分别将自己的GE0/0/1到GE0/0/2接口进行捆绑,则会产生出一个聚合接口,也就是Eth-trunk接口。链路聚合技术能够部署在交换机之间、防火墙之间、交换机与防火墙之间、交换机与特定的服务器之间等等,是一种应用非常广泛的技术。华为交换机上的Eth-trunk支持两种工作方式:手工负载分担及LACP。
- 工作方式:手工负载分担(Manual load-balance)
手工负载分担方式允许在聚合组中手工加入多个成员接口,并且所有的接口均处于转发状态,分担负载的流量。在这种模式下,Eth-Trunk的创建、成员接口的加入都需要手工配置完成,没有LACP(link Aggregation Control Protocol)协议报文的参与。手工负载分担模式通常用在对端设备不支持LACP协议的情况下。
基础配置命令如下:
[Huawei-Eth-Trunk1] least active-linknumber ?
- 工作方式:LACP
LACP方式是一种利用LACP协议进行聚合参数协商、确定活动接口和非活动接口的链路聚合方式。该模式下,需手工创建Eth-Trunk,手工加入Eth-Trunk成员接口,但是,由LACP协议协商确定活动接口和非活动接口。
LACP模式也称为M∶N模式。这种方式同时可以实现链路负载分担和链路冗余备份的双重功能。在链路聚合组中M条链路处于活动状态,这些链路负责转发数据并进行负载分担,另外N条链路处于非活动状态作为备份链路,不转发数据。当M条链路中有链路出现故障时,系统会从N条备份链路中选择优先级最高的接替出现故障的链路,同时这条替换故障链路的备份链路状态变为活动状态开始转发数据。
LACP模式与手工负载分担模式的主要区别为:LACP模式有备份链路,而手工负载分担模式所有成员接口均处于转发状态,分担负载流量。此外,LACP模式下,交换机之间会交互LACP报文。
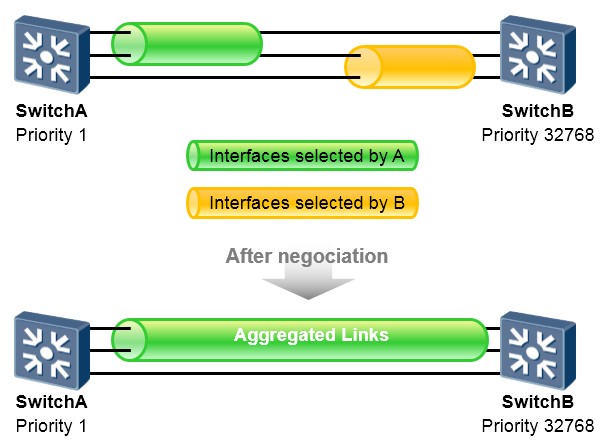
LACP模式中有一个主动、被动端的概念。设备LACP优先级较高(值越小越优)的一端为主动端,设备LACP
优先级较低的一端为被动端。如果两端设备的LACP优先级一样时,则MAC地址小的胜出。
在上图所示的场景中,SwitchA及SwitchB之间部署了Eth-Trunk,该Eth-Trunk中包含三条直连链路,并且采用的是LACP方式。两者会交互LACP报文使得聚合链路能够协商建立。A和B会比较两者的设备LACP优先级,值最小的胜出成为主动端,这里假设A胜出。从图中我们看到A选择了上面两条链路作为活动链路,而
B选择了下面两条链路,由于A是主动端,因此最终AB之间建立起来的聚合链路中的活动链路由A来确定, 也就是上面两条链路成为活动链路。
基础配置命令(此处以S5700 V200R001C00版本为例,不同的软件版本,在配置上可能存在细微差异):¶
#创建Eth-Trunk,并将工作方式修改为LACP:
[Huawei] interface eth-trunk 1
[Huawei] mode lacp-static #缺省情况下,Eth-Trunk的工作模式为手工负载分担方式。
#添加成员接口到Eth-Trunk中(根据实际情况添加): [Huawei] interface GigabitEthernet0/0/1
[Huawei-GigabitEthernet0/0/1] eth-trunk 1 [Huawei] interface GigabitEthernet0/0/2 [Huawei-GigabitEthernet0/0/2] eth-trunk 1 [Huawei] interface GigabitEthernet0/0/3 [Huawei-GigabitEthernet0/0/3] eth-trunk 1
#(可选)配置Eth-trunk成员链路的负载分担模式:
[Huawei-Eth-Trunk1] load-balance ?
#(可选)配置设备LACP优先级: [Huawei] lacp priority ?
系统LACP优先级值越小优先级越高,缺省情况下,系统LACP优先级为32768。在两端设备中选择系统LACP优先级较小一端
作为主动端,如果系统LACP优先级相同则选择MAC地址较小的一端作为主动端。
#(可选)配置接口LACP优先级:
[Huawei-GigabitEthernet0/0/1] lacp priority ?
缺省情况下,接口的LACP优先级是32768。取值越小,表明接口的LACP优先级越高。优先级越高的接口越有可能成为活动的成员接口。
#(可选)配置活动接口数上限阈值:
[Huawei-Eth-Trunk1] max active-linknumber ?
配置链路聚合活动接口数上限阈值,缺省情况下,活动接口数上限阈值为8。
配置LACP模式活动接口数目上限阈值可以控制Eth-Trunk中活动接口的最大数M,剩余的成员接口处于备份状态。
#(可选)配置活动接口数下限阈值:
[Huawei-Eth-Trunk1] least active-linknumber ?
配置链路聚合活动接口数下限阈值,缺省情况下,活动接口数下限阈值为1。
配置LACP模式活动接口数目下限阈值可以决定Eth-Trunk中活动接口数的最小值,如果静态模式下活动接口数目小于该值,
Eth-Trunk的接口状态将变为DOWN的状态。
#(可选)使能LACP抢占并配置抢占等待时间: [Huawei-Eth-Trunk1] lacp preempt enable [Huawei-Eth-Trunk1] lacp preempt delay ?
- 基础实验
实验1:手工负载分担模式¶
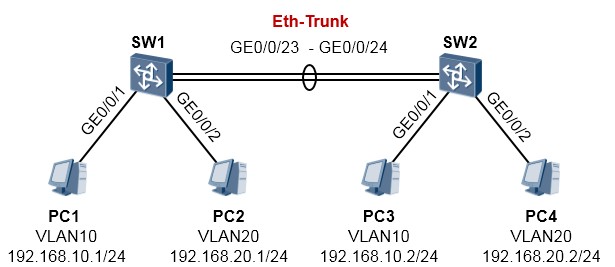
SW1及SW2通过GE0/0/23及24口互联,配置Eth-trunk将这两条链路进行捆绑。捆绑后的链路配置为
Trunk模式,使得两台交换机下相同VLAN内的用户能够互访,也就是PC1与PC3能够互访;PC2与PC4
也能够互访。
SW1的配置如下:
SW2的配置如下:
完成配置后,在SW1上查看一下:
| PortName | Status | Weight |
|---|---|---|
| GigabitEthernet0/0/23 | Up | 1 |
| GigabitEthernet0/0/24 | Up | 1 |
实验2:LACP方式¶
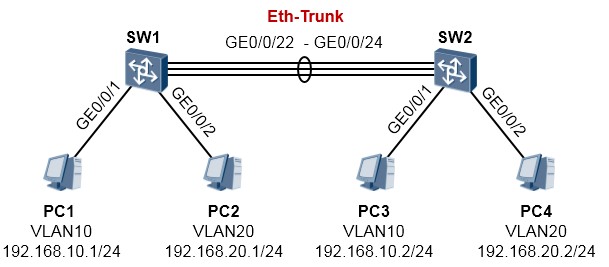
SW1及SW2的GE0/0/22到GE0/0/24口分别互联,将这三条链路捆绑为Eth-Trunk,使用LACP方式,
SW1为主动端,在该聚合链路中,两条链路为活动链路,其余一条做备份。
SW1的配置如下:
SW2的配置如下:
完成后检查一下配置:
| System Priority: 1 System ID: 4c1f-ccbe-289e Least Active-linknumber: 1 Max Active-linknumber: 2 Operate status: up Number Of Up Port In Trunk: 2 -------------------------------------------------------------------------------- | |||||||
|---|---|---|---|---|---|---|---|
| ActorPortName | Status | PortType | PortPri | PortNo | PortKey | PortState | Weight |
| GigabitEthernet0/0/22 | Selected | 1000TG | 32768 | 23 | 401 | 10111100 | 1 |
| GigabitEthernet0/0/23 | Selected | 1000TG | 32768 | 24 | 401 | 10111100 | 1 |
| GigabitEthernet0/0/24 | Unselect | 1000TG | 32768 | 25 | 401 | 10100000 | 1 |
| Partner: -------------------------------------------------------------------------------- | |||||||
| ActorPortName | SysPri | SystemID | PortPri | PortNo | PortKey | PortState | |
| GigabitEthernet0/0/22 | 32768 | 4c1f-cc77-6cf4 | 32768 | 23 | 401 | 10111100 | |
| GigabitEthernet0/0/23 | 32768 | 4c1f-cc77-6cf4 | 32768 | 24 | 401 | 10111100 | |
| GigabitEthernet0/0/24 | 32768 | 4c1f-cc77-6cf4 | 32768 | 25 | 401 | 10110000 |
在上述输出中,我们可以看到SW1的eth-trunk1聚合接口的状态。Operate status显示整个聚合接口的
状态为UP。而由于我们设置了max active-linknumber 2,因此三个成员接口中,仅有两个接口(两条链路)是活跃的,它们会转发数据,而剩下的接口则作为备份。我们看到GE0/0/22及GE0/0/23是Select 状态,因此它们是活跃接口,而GE0/0/24是Unselect状态,则它们是非活跃的备份接口。因为SW1是主动端设备,因此由它决定哪些接口是活跃,哪些是非活跃的。
- 交换安全
- 端口镜像
端口镜像概述¶
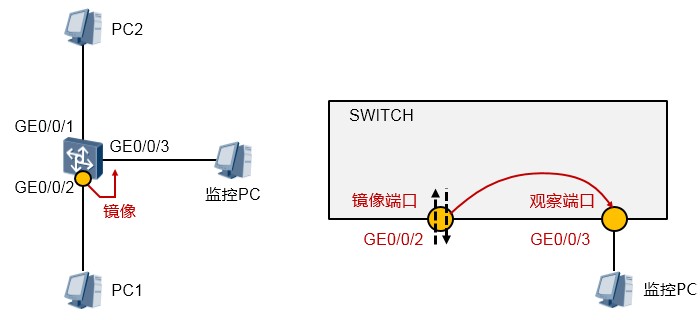
在某些场景中,我们可能需要监控交换机特定端口的入站或出站报文,或者需要针对特定的流量进行分析,例如上图中,我们期望抓取PC1收发的报文并进行分析,那么便可以在交换机的GE0/0/3口接一个监控PC,在监控PC上安装协议分析软件,然后在交换机上部署端口镜像,将GE0/0/2的入、出站流量镜像到GE0/0/3口上来,接下来我只要在监控PC上通过协议分析软件查看报文即可。
注意到,如果没有端口镜像技术,除非数据包的目的地是监控PC(所连接的端口),否则报文是不会发向该端口的。因此事实上端口镜像就是将某个特定端口的流量拷贝到某个监控端口,就这么简单。
端口镜像常用于:流量观测及统计;故障定位等。
镜像的分类:¶
-
基于端口的镜像:
端口镜像就是将被监控端口上的数据复制到指定的监控端口,对数据进行分析和监视。
-
基于流的镜像:
流镜像就是将匹配访问控制列表的业务流复制到指定的监控端口,用于报文的分析和监视。
-
基于端口的镜像¶
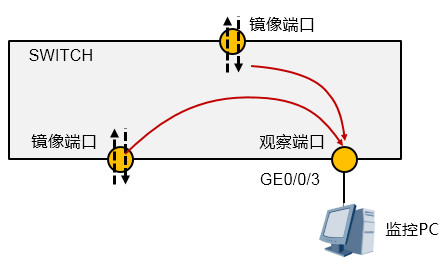
端口镜像是指交换机复制一份从镜像端口流经的报文(可以指定入站或出站),并将此报文传送到指定的观察端口进行分析和监视。在端口镜像中,镜像端口流经的所有报文都将被复制到观察端口。
以太网交换机支持多对一的镜像,即将多个端口的报文复制到一个监控端口上。注意区分这里的观察端口和镜像端口。
端口镜像分为本地端口镜像和远程端口镜像:
- 本地端口镜像:本地端口镜像中,监控PC与观察端口直接相连。
-
远程端口镜像:远程端口镜像中,监控PC与观察端口所在设备之间通过二层网络或三层网络相联。
二层端口镜像(RSPAN:Remote Switched Port Analyzer):若通过二层网络互联,以S9300交换机为例,它将镜像端口的报文封装VLAN,然后通过观察端口将报文在远程镜像VLAN中进行广播。远程的设备收到报文后,比较报文的VLAN ID,如果相同,则将该报文转发到远程观察端口。
三层端口镜像(ERSPAN:Encapsulated Remote SPAN):若通过三层网络互联,以S9300交换机为例,它使用GRE报文头封装和解封装镜像报文,使得镜像报文可以穿透三层网络,从而实现镜像端口所在设备与观察端口所在设备之间通过三层网络相连时的端口镜像。
-
基于流的镜像¶
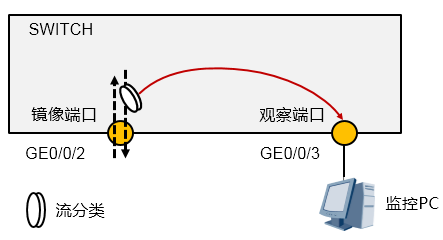
流镜像就是将流镜像端口上的特定数据复制到指定的观察端口或CPU进行分析和监视。流镜像端口是指应用了包含流镜像行为的流策略的接口,从流镜像端口流过的报文,如果匹配此接口上流策略中的流分类,则将被复制并传送到观察端口或CPU。
流镜像分为两种,即流镜像到接口和流镜像到CPU:
- 流镜像到接口,是把通过配置了流镜像的接口上的符合要求的报文复制一份,然后发送到观察端口以供分析诊断。
- 流镜像到CPU,是把通过配置了流镜像的接口上的符合要求的报文复制一份,然后发送到CPU以供分析诊断。这里的CPU指的是配置了流镜像的接口所在接口板上的CPU。
配置本地端口镜像¶
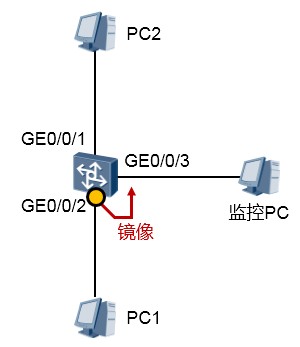
将交换机GE0/0/2端口的进、出口报文镜像到GE0/0/3。交换机配置如下:
报文分析¶
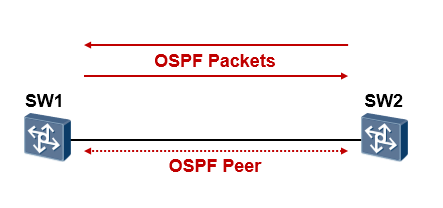
在IP网络中,有着各种各样的流量。协议或业务的正常运转得益于报文的正常交互。例如上图中SW1 及SW2运行OSPF,那么实际上在SW1、SW2之间就在源源不断的交互着OSPF的报文,使得OSPF能够正常工作。再如从SW1去telnet SW2,实际上这个行为在底层也是由相关的报文交互来完成。普通的网络用户仅需要关注能否ping通,或者跑在网络上的业务是否正常,但是作为数通工程师的我们,应该具备从报文层面理解协议或机制的素质。
对于一个职业网络工程师,应该能够从报文层面理解IP数据,进而理解各种协议,以及利用这种技术理解对网络进行管理和排障。许多网络故障都可以通过分析包文来定位。网络工程师的成长之路:

报文分析工具¶
常用的报文分析工具有:Wireshark、Ethereal、Sniffer。
例如下图就是Wireshark软件的界面,在完成软件安装后,启动该软件,然后选择监听本地的哪个网卡, 即可开始在该网卡上侦听报文。下图中显示的就是我们抓取到的各种报文。
小练习:

按照如图所示完成PC及交换机的IP配置。在交换机上开启Telnet服务。
在PC上打开wireshark抓包工具,监控以太网卡,然后从PC telnet交换机,观察抓到的报文,telnet是明文传输的,因此能够通过抓包,将telnet输入的用户名和密码,以及telnet上交换机之后输入的各种操作都抓取下来,因此telnet协议并不安全。
温馨提醒:wireshark是非标软件,擅自安装属信息安全违规,因此如若需安装学习该软件的使用,请自行走相关流程或在私人PC上完成。
注意事项¶
- 观察端口专门用于故障定位或流量分析,不能用作普通业务口。
- 捕获业务报文
在实际项目中,在进行问题定位及分析时,我们可能并不具备在交换机上进行端口镜像的条件,例如管理
PC不在机房,工程师通过远程登录的方式连接到网络设备,而如果此时又需要进行报文捕获,那么就可以使用**capture-packet**命令。
场景一:捕获交换机接口上收到的报文,并将捕获的结果输出到终端界面¶

在上图所示的场景中,我们希望在交换机上抓取接口GE6/0/13收到的报文,并将捕获的报文呈现在终端界面上,以此进行简单的判断:PC1 ping PC2所产生的ICMP报文是否通过该交换机。以S9300交换机为例,执行如下命令:[SW] capture-packet interface GigabitEthernet 6/0/13 destination terminal
交换机便会开始捕获接口GE6/0/13所接收的所有报文,并将报文呈现在终端界面上,在这个过程中, 交换机会持续在终端界面上显示捕获到的报文,直到捕获超时(缺省60s):
当PC1开始ping PC2时,我们就能在终端界面看到如上输出,上面截取了捕获到的两个报文。以第一个
报文为例,这实际上是一个数据帧,红色字体部分是该帧的目的MAC地址,蓝色字体部分是源MAC地址。我们可以通过这些简单的信息判断目标报文是否到达(实际上,你还能在上述输出中,看到报文的源、目的IP地址等信息)。
场景二:捕获交换机接口上收到的特定报文,并将捕获的结果输出到终端界面¶
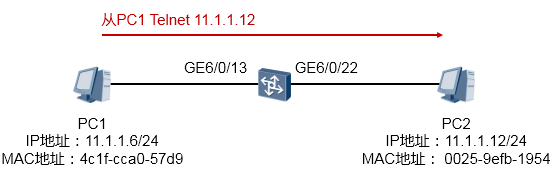
在上图所示的场景中,在交换机上进行报文捕获,只抓取PC1 Telnet PC2的报文。使用ACL3000来匹配感兴趣的流量,然后用capture-packet执行报文捕获。
执行上述命令后,当PC1 telnet PC2时,可以看到如下输出:
另外,在capture-packet interface GigabitEthernet 6/0/13 acl 3000 destination terminal命令的基¶
础上增加**file**关键字并指定文件名,例如**capture-packet interface GigabitEthernet 6/0/13 acl 3000 destination terminal file test.cap**,那么当交换机捕获到报文后,不仅会在终端界面呈现,还会将报文保存到该网络设备的存储空间中,以test.cap的名字存放,这样便可以再完成抓包后,将该文件下载到管理PC并通过抓包软件更加直观地分析捕获的报文。
再者,在**capture-packet**命令中使用**timeout**关键字,还可定义报文捕获的超时时间;使用**vlan**关键字, 可以指定捕获的vlan。该命令目前只支持捕获接口入方向报文,不支持捕获接口出方向报文。捕获的报文有速率限制,缺省值是64kbps,如果有突发流量,超过捕获报文的速率限制,可能会存在丢包现象。最后,设备不支持捕获BFD和802.1ag。
- 端口隔离
基本概述¶

上图中,PC1、2、3同属一个VLAN(假设是VLAN10),使用相同的IP子网。默认情况下三台PC可互相访问,这是典型的二层互访。现在有这么一个需求,在不修改IP子网及VLAN规划的情况下,使得PC1-
PC2之间无法互访,而PC1与PC3可互访、PC2与PC3可互访。这就可以用到端口隔离特性。
这里需要用到端口隔离组的概念,交换机的端口可以加入到特定的隔离组中,同一端口隔离组的端口之间互相隔离,不同端口隔离组的端口之间不隔离。因此要实现上述需求,配置的思路非常简单,在交换机上将端口1、2放置在同一隔离组中,端口3不做隔离组配置或者放入另一个隔离组中,然后开启端口隔离特性即可。
实验验证¶

在上图中,PC1、PC2、PC3同属VLAN10、同属1.1.1.0/24子网,IP地址如上图所示。配置端口隔离, 使得PC1与PC2无法互访;PC1与PC3,PC2与PC3可互访。
交换机的配置如下:
完成上述配置后,检查一下:
将端口1及端口2都加入隔离组1,这样PC1及PC2就二层隔离了,也就无法互访了。但是PC1及PC2都
能够与PC3互访。**Port-isolate mode l2**这条命令是将隔离模式设置为二层隔离三层不隔离。所谓的三层不隔离指的是同一个隔离组的节点之间仍然能够通过三层进行互访,例如:
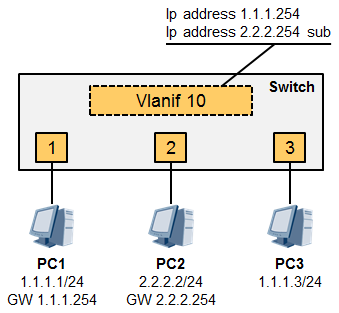
PC1的IP为1.1.1.1,网关为vlanif10的IP 1.1.1.254,PC2的IP为2.2.2.2,网关为vlanif10的IP 2.2.2.254,
Vlanif10配置了两个IP地址,也就是同一个VLAN我们用了两个IP子网。那么端口1与端口2现在虽然是二层隔离,ARP啥的无法透过来,但是PC1与PC2仍然能够借助自己的网关实现三层互访,这就是所谓的二层隔离但是三层不隔离。那么如果要彻底将端口1及端口2隔离呢?使用系统视图命令**port-isolate mode all**即可。
路由基础¶
- IP 路由基础
- 什么是 IP 路由
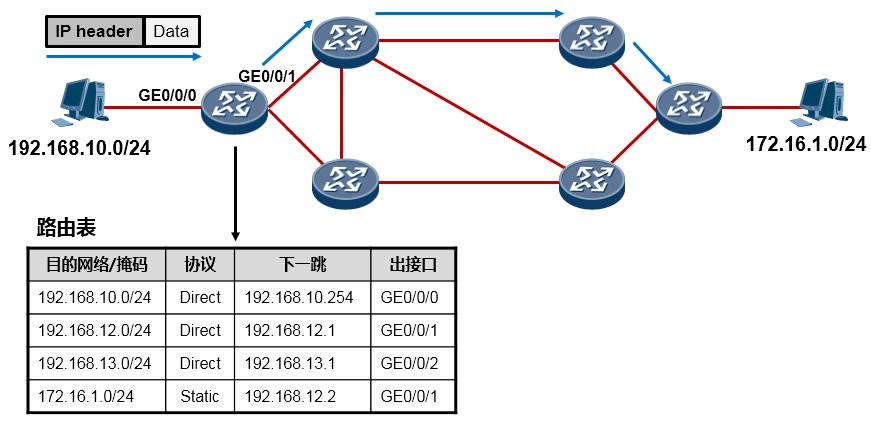
在一个IP网络中,路由(Routing)是个非常非常基本的概念。网络的基本功能是使得处于网络中的两个IP 节点能够互相通信,而通信实际上就是数据交互的过程,数据交互则需要网络设备帮助我们来将数据在两个通信节点之间进行传输。当路由器(或者其他三层设备)收到一个IP数据包时,路由器会找出报文中的IP 头里的目的IP地址,然后拿着目的IP地址到自己的路由表(Routing Table)中进行查询,找到“最匹配”的路由条目后,将数据包根据路由条目所指示的出接口或下一跳IP转发出去,这就是路由。
每台路由器都会在本地维护一个路由表,路由表中装载着路由器通过各种途径获知的路由条目(Route), 每一条路由条目可能包含:目的网络号及掩码长度、路由协议类型、出接口或下一跳IP、路由协议优先级、开销等信息元素。路由器通过直连、静态的或者动态的方式获取路由条目并维护自己的路由表,路由表是每台支持路由功能的设备进行数据转发的依据和基础,是一个非常重要的概念,任何一台支持路由功能的设备要执行数据转发或路由的动作,就必须拥有及维护一张路由表。
- IP 路由表
任何一台支持路由功能的设备要执行数据转发或路由的动作,就必须拥有及维护一张路由表,路由表可以理解为将数据包转发到特定目的地所依据的一张“地图”。在我司三层设备(如路由器、防火墙、三层交换机等)上查看IP路由表的命令如下:
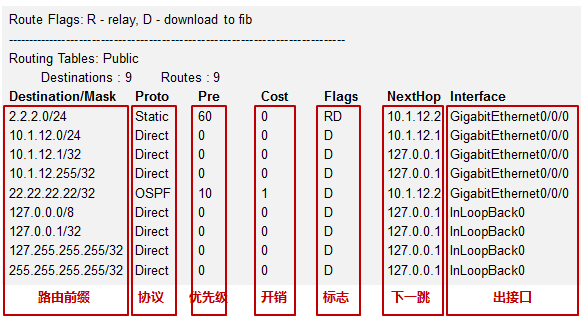 [Huawei] display ip routing-table¶
[Huawei] display ip routing-table¶
每个路由条目必须包括下面几个信息元素:
**目的网络/掩码:**也被称为路由前缀,这是路由条目所关联的目的网络地址及网络掩码。一条完整的路由前缀由:网络地址+前缀长度(或者网络掩码)构成,两者缺一不可,例如192.168.1.0/24与192.168.1.0/25, 虽然网络地址相同,都是192.168.1.0,但是两者绝对是两条不同的路由,因为他们的前缀长度不相同。
**协议类型:**本条路由是通过什么途径学习到的,例如是直连的,或是静态的,或者是通过OSPF、IS-IS、
EIGRP、BGP等动态路由学习到的。
优先级:与协议类型对应,路由表中路由的获取来源有多种,每种协议类型对应不同的优先级,优先级值越小则路由越优。当一台路由器同时从多种不同的路由协议学习到去往同一个目的地的路由时,它将优选路由协议优先级值最小的那条路由。
**开销:**路由的度量值,在许多书籍或文档中也使用metric来描述。直连及静态路由的Cost为0。通过动态路由协议学习到的Cost则根据实际情况而定。不同的路由协议计算Cost的方法不同。
下一跳:去往目标网络的下一跳IP地址。
出接口:去往目标网络从本设备的哪个接口出去。
- 路由优先级
路由器可以通过多种途径获知路由条目:如通过静态手工配置,或通过各种动态路由协议学习等等。当路由器从多种不用的协议获知去往同一个目的地的路由时,路由器会比较这些路由的优先级(Preference),优选Preference值最小的路由。如果Preference值相等,例如是同种路由协议获取到的路由,则进一步比较开销值(Cost),当然,这其中还牵涉到不同的路由协议内在的工作机制问题,这就要针对不同的路由协议具体讨论了,我们这里暂时不讨论这么深入。
如下图,R3与R1运行的是RIP路由协议,R3又通过OSPF与R2建立邻接关系。R3同时从RIP及OSPF学习到了去往目的地1.1.1.0/24的路由,它最终会将OSPF的路由装载进路由表,也就是将R2作为实际去往
1.1.1.0/24的下一跳,因为OSPF协议的优先级值比RIP要小——优先级更高。当然,如果此时R2发生故障, 那么R3路由表中该条OSPF路由失效,则R3将RIP路由加载到路由表中。
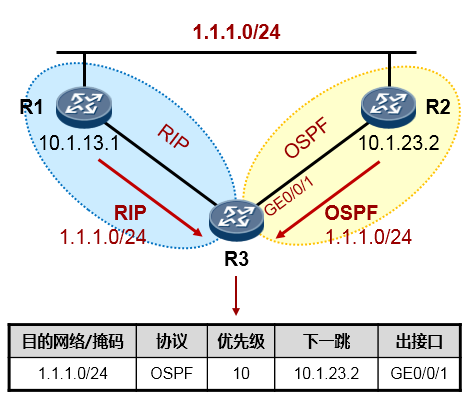
针对不同的路由协议,对应的优先级见下表,这是个众所周知的约定(不同的厂家,可能有所不同,下表中罗列的是我司的产品特性):
| 路由协议或路由种类 | 优先级 | ||
|---|---|---|---|
| DIRECT | 0 | ||
| OSPF | 10 | ||
| IS-IS | 15 | ||
| STATIC | 60 | ||
| RIP | 100 |
|---|---|
| OSPF ASE | 150 |
| OSPF NSSA | 150 |
| IBGP | 255 |
| EBGP | 255 |
- 静态路由
关于静态路由¶
路由器的天职,就是维护路由表以及依据路由表进行数据转发。而路由表中包含通过各种途径学习到的路由表项(路由条目),主要有如下几种途径:
- 直连路由自动学习;
- 通过手工的方式为设备添加静态路由条目;
- 使用动态路由协议使得设备之间能够进行路由信息的更新及学习,动态地维护路由表项。以下图为例:

PC1的网关设置为172.16.1.254,也就是R1的GE0/0/0口IP;PC2的网关设置为172.16.2.254也就是R2 的GE0/0/0口IP。在初始情况下,对于R1而言,当接口UP以后,路由器会自动学习活跃的接口所在网络的网络地址及掩码并且维护自己的路由表,例如R1的路由表,可能像下面这样(省略了无关信息):
| 目的网络/掩码 | 协议 | 优先级 | 出接口 | 下一跳 |
|---|---|---|---|---|
| 172.16.1.0/24 | Direct | 0 | GE0/0/0 | 172.16.1.254 |
| 172.16.100.0/24 | Direct | 0 | GE0/0/1 | 172.16.100.1 |
R2的路由表类似,这里不再赘述。现在当PC1要访问PC2时,由于PC1的网关设置为R1的GE0/0/0口的
IP地址,于是PC1将目的地址为172.16.2.1的IP数据包发送给它的网关。而当R1收到这个数据包时,R1
发现这个数据包的目的地址是172.16.2.1,它就去查询自己的路由表,结果发现路由表中,并没有匹配
172.16.2.1的条目,因此数据包被丢弃,到目前为止PC1是无法与PC2互访的。那么如何才能使R1正常转发这个数据包呢?当然需要R1的路由表中有相关的条目来做指示。
最简单的一种方式是,通过手工的方式为R1添加去往172.16.2.0/24的路由条目,这种方式添加的路由称为静态路由。
静态路由的配置的命令非常简单:
[Quidway] ip route-static 172.16.2.0 24 172.16.100.2 命令中的红色字体部分是这条路由的目的网络地址(172.16.2.0)及掩码长度(24);蓝色字体部分是 去往这个目的地的“下一跳IP地址”。于是R1的路由表变成下面这个样子:
我们看到,R1的路由表里出现了一个新增的条目,路由前缀是172.16.2.0/24,协议类型为“静态”, 优先级为60,出接口为GE0/0/1,去往目的地的下一跳IP是172.16.100.2。这样一来,当R1收到PC1发往172.16.2.1的数据包时,它查看路由表,发现路由表中有一个条目匹配,于是R1将该数据包丢给该条路由指示的下一跳172.16.100.2,这个数据包被转发到了R2,再由R2查它的路由表,R2发现数据包的目的地172.16.2.1在本地路由表中有路由条目匹配,而且是直连网络,因此R2将数据包根据路由条目的指示从GE0/0/0口发送出去,最终PC2收到了这个数据包。
现在问题来了,我们在R1上增加了这条静态路由后,PC1与PC2就能够互通了么?答案是否定的,为什么?因为两个节点之间的数据通信往往是双向的,有去得有回,在R1上增加去往172.16.2.0/24的静态路由后,PC1发往PC2的数据包是能够被转发到PC2的,但是如果此刻PC2要回送报文呢?PC2回送的数据包目的IP地址就是172.16.1.1,这个数据包首先被PC2发往自己的网关也就是R2,R2查看路由表,却没有发现匹配目的地址172.16.1.1的路由,于是就丢包。
因此,为了使得PC1与PC2之间能够相互通信,我们还需要做一步动作,也就是在R2上也增加一条路由,路由的目的地是172.16.1.0/24网络,下一跳呢?当然就是172.16.100.1了。如此一来PC1及PC2互相通信就没有问题了。
静态路由的配置¶
方法一:关联下一跳IP的方式:¶
[Quidway] ip route-static 172.16.2.0 24 172.16.100.2
红色字体部分为该路由条目的网络地址;
蓝色字体部分为该目的网络的网络掩码或者掩码长度;此处24等同于255.255.255.0。绿色字体部分为去往该网络的下一跳IP地址;
方法二:关联出接口的方式:¶
[Quidway] ip route-static 172.16.2.0 24 GigabitEthernet0/0/1
红色字体部分为该路由条目的网络地址; 蓝色字体部分为网络掩码或者掩码长度;
绿色字体部分为去往该网络的出接口,注意,在华为路由器上,静态路由可关联出接口或下一跳IP,或两者都关联。如果路由的出接口为点对点接口(例如采用HDLC或PPP封装的串行接口),则可只关联出接口。但若出接口为广播多路访问型接口,例如以太网口,那么就必须关联下一跳,如**ip route-static 172.16.2.0 24 GigabitEthernet0/0/1 172.16.100.2**,或者**ip route-static 172.16.2.0 24 172.16.100.2**。
- 静态路由简单实验

在上图所示的网络中,SW1连接着PC1,PC1属于VLAN10,使用的网段是192.168.10.0/24;SW2连接着
PC2,PC2属于VLAN20,使用的网段是192.168.20.0/24;PC1及PC2的网关分别为SW1及SW2。两台交换机通过VLAN200实现三层对接,要求完成交换机的配置,使得PC1与PC2能够相互通信。
SW1的配置如下:
SW2的配置如下:
完成上述配置后,PC1即可与PC2相互通信。在SW1上检查一下路由表:
| \<SW1>display ip routing-table Route Flags: R - relay, D - download to fib ------------------------------------------------------------------------------ Routing Tables: Public | ||||||
|---|---|---|---|---|---|---|
| Destinations : 7 | Routes : 7 | |||||
| Destination/Mask | Proto | Pre | Cost | Flags | NextHop | Interface |
| 127.0.0.0/8 | Direct | 0 | 0 | D | 127.0.0.1 | InLoopBack0 |
| 127.0.0.1/32 | Direct | 0 | 0 | D | 127.0.0.1 | InLoopBack0 |
| 192.168.10.0/24 | Direct | 0 | 0 | D | 192.168.10.254 | Vlanif10 |
| 192.168.10.254/32 | Direct | 0 | 0 | D | 127.0.0.1 | Vlanif10 |
| 192.168.20.0/24 | Static | 60 | 0 | RD | 192.168.200.2 | Vlanif200 |
| 192.168.200.0/30 | Direct | 0 | 0 | D | 192.168.200.1 | Vlanif200 |
| 192.168.200.1/32 | Direct | 0 | 0 | D | 127.0.0.1 | Vlanif200 |
在以上输出中能看到我们配置的静态路由,SW2同理。
当然此时在SW1 上也可以直接ping 通PC2 , 但是实际上, SW1 在ping PC2 时, 报文的源IP 地址是192.168.200.1 , 因此如果我们要验证192.168.10.0/24 网段到PC2 的可达性,可以在SW1 执行ping
192.168.20.1测试时,强制指定探测报文的源IP地址为192.168.10.254:
在网络设备上,执行ping命令时,关联-a关键字可指定ICMP探测报文的源地址(需为本设备上的IP地址)。
- 默认路由(缺省路由)
在上图中,对于R1而言,如果要到达R2所直连的172.16.1.0/24、2.0/24、3.0/24网络,就必须有路由。如果采用静态路由的方式为R1添加路由,三个目的网络就需要配置三条静态路由。这样不仅仅增加了配置工作量,另一方面,也增加了R1的负担,因为它需要维护更多的路由条目,而承载路由条目的路由表是需要占用设备内存资源的。因此从网络设计及优化的角度,我们往往在保证网络路由可达性的同时,尽量减少路由器路由表的条目数量。
在这个环境中,由于R1仅有一条出口线路,因此我们可以在R1上配置一条**默认路由(Default route)**,下一跳为R2,如此即可在保证R1到R2后方三个网络可达的同时,路由条目达到最简。具体的配置如下:
默认路由的网络地址和掩码都是全0,可匹配任意目的网络前缀,可作为路由器的“最后求助对象”使用。
默认路由的使用非常广泛。通常用于一个网络的出口设备上,例如出口路由器或出口防火墙,这些设备连接外部网络,往往并不能知晓外部网络的所有网段信息——当然也不可能完全知晓,那么此时就可以在设备上书写默认路由,指向外部网络,从而使得设备能够顺利将去往外部网络的流量转发出去。
- 浮动静态路由
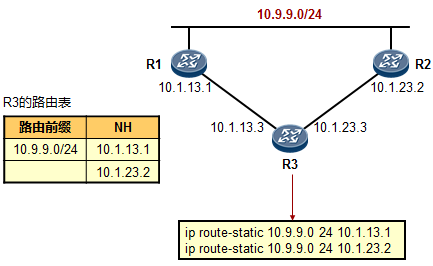
在上图中,对于R3及其下挂的网络而言,要去往10.9.9.0/24网络,通过R1及R2都可达。那么如果在R3上, 分别配置静态路由:
这两条路由都是去往同一个目的地,但分别采用不同的下一跳IP地址,同时这两条路由具备相同的优先级,
以及相同的开销(Cost都为0),因此这两条去往10.9.9.0/24的路由被同时装载进了R3的路由表。这种现象我们称为路由的等价负载均衡。最终的结果是,R3转发去往10.9.9.0/24的流量时,可能会同时采用R1及R2 作为下一跳。这种方法是有利弊的,优势很明显,而弊端之一是有可能出现到达目的地的数据包是非顺序的情况。那么如果希望R3去往10.9.9.0/24的流量始终先走单边(如R1),当R1宕机或R1-R3之间的互联链路出现故障时,R3能够自动将流量切换到R2呢?
这里就可以使用到浮动静态路由的概念。我们已经知道使用**ip route-static**命令可以为设备添加静态路由, 在默认情况下,这条命令所添加的静态路由的优先级为60(在华为设备上,静态路由的优先级默认为60, 其他设备厂商可能有所不同),这个静态路由的优先级事实上是可以自定义的,例如,在R3上配置修改为:
上述配置中,我们为R3添加了两条静态路由,目的网络都是10.9.9.0/24,下一跳分别为10.1.13.1及10.1.23.2,
留意到下一跳为R1的静态路由并没有设置优先级,因此该条路由的优先级为默认的60,另一条静态路由使用**preference**关键字指定了优先级80。这样一来,经过优先级比较,优先级值更小的路由将被优选,并放进路由表作为数据转发的依据,另一条优先级为80的路由,则“潜藏”起来,并不出现在路由表中。
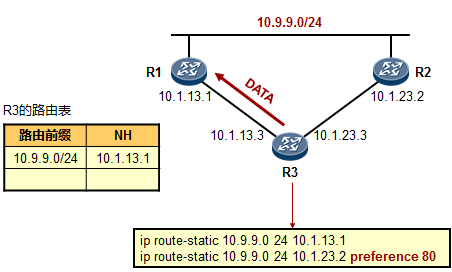
当R1宕机,或者R1-R3之间的直连链路发生故障时,**ip route-static 10.9.9.0 24 10.1.13.1**这条静态路由失
效,**ip route-static 10.9.9.0 24 10.1.23.2 preference 80**则浮现出来了,如下图所示。因此这是一种不错的路径备份机制。
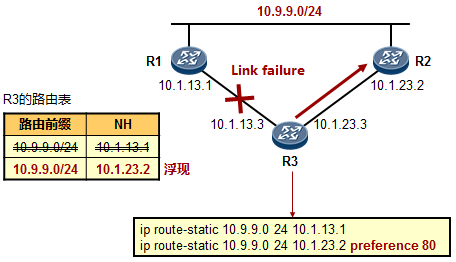
- 路由汇总(路由聚合)
路由汇总技术背景¶
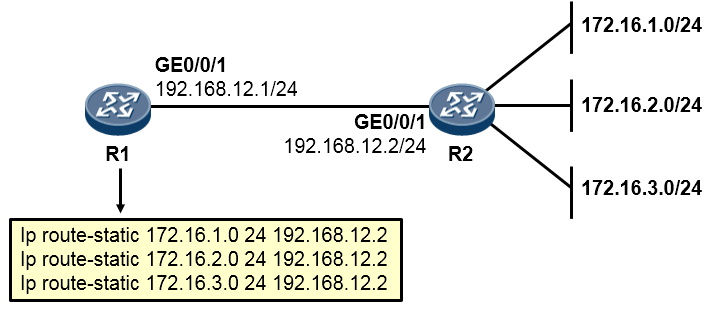
上图中,对于R1而言,如果要去往R2身后的172.16.1.0/24、172.16.2.0/24、172.16.3.0/24网络,自然是要有路由的,如果是采用静态路由的方式,意味着要给R1配置三条静态路由分别对应上述三个网段, 前文已经说过了,这样的配置,一来工作量大,想想看,如果R2身后不仅仅有三个网络呢?如果有100 个网络呢?再者这也意味着R1的路由表将变得非常臃肿。
在上一小节我已经介绍过了默认路由,默认路由固然可以解决一部分问题,但是默认路由的“路由颗粒度”太大,无法做到对路由更为细致的控制,而且如果R1左侧(另一个接口)连接了一个外部网络并且已经占用了默认路由,那么这里只能另想他法了。
路由汇总可以很好的解决这个问题:
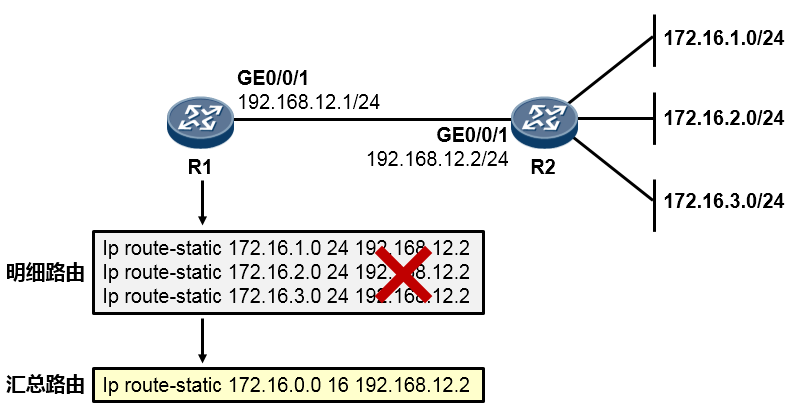
与R1使用3条明细路由不同,在上图中,我们仅仅使用一条路由即可实现相同的效果,这条路由是上一个场景中3条明细路由的汇总路由。这样配置的一个直接的好处就是,路由器的路由表条目数量大大减少了。这种操作被称为路由汇总。路由汇总是一个非常重要的网络设计思想,通常在一个大中型的网络中,必须时刻考虑网络及路由的可优化性,路由汇总就是一个时常需要关注的工具。这里实际上是部署了静态路由的汇总,当然除此之外我们也可以在动态路由协议中进行路由汇总,几乎所有的动态路由协
议都支持路由汇总。
路由精确汇总的算法¶
路由的汇总实际上是通过对网络掩码的操作来完成的。对于下面的例子来说:

在R2上,为了到达R1左侧的网络,R2使用了路由汇总,配置了一条汇总路由:
虽然这确实起到了网络优化的目的,但是,这条汇总路由太“粗犷”了,它甚至将R3这一侧的网段也
囊括在内,我们称这种路由汇总行为不够精确。因此,一种理想的方式是,使用一个“刚刚好”囊括这些明细路由的汇总路由,这样一来就可以避免汇总不够精确的问题。
这里不得不强调一点,网络可以部署路由汇总的前提是网络中的IP子网规划及网络模型设计具备一定的科学性和合理性。如果网络规划得杂乱无章,路由汇总部署起来就相当的困难了。那么如何进行汇总路由的精确计算呢?下面来看一个例子:
现有明细路由:172.16.1.0/24、172.16.2.0/24、…、172.16.31.0/24,请计算最精确的汇总路由:
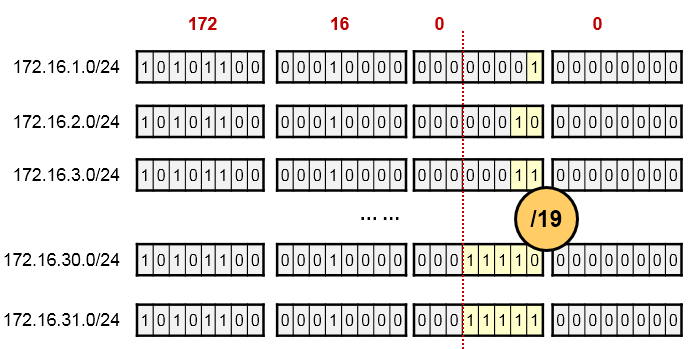
我们要做的事情非常简单,将明细子网都换算成二进制,然后排列起来。所要做的事情就是找出每个子网中的“相同的比特位”。由于这些明细子网是连续的,因此其实只要挑出首尾的两到三个网络号来计算就足够了:
- 将这些IP地址写成二进制形式,实际上只要考虑第三个8位组即可,因为只有它是在变化的。
- 现在画一根竖线,这根线的左侧,每一列的二进制数都是一样的,线的右侧则是变化的,这根线的
最终位置,就是汇总路由的掩码长度。注意这根竖线可以从默认的掩码长度,也就是/24开始,一格一格的往左移,直到你观察到线的左端每一列数值都相等,即可停下,这时候,这根线,所处的位置就刚刚好。
-
如上图,线的位置是16+3=19,所以我们得到汇总地址:172.16.0.0/19,这就是一个最精确的汇总地址。
因此,上面的例子,我们可以这么配置:
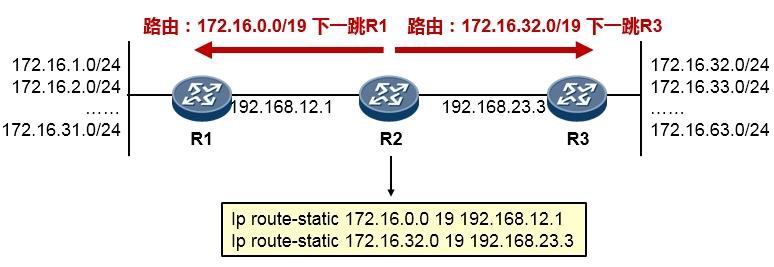
路由汇总的潜在问题¶
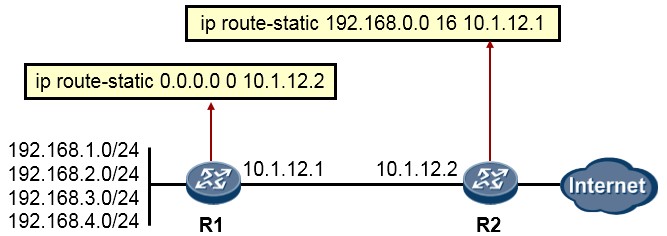
路由汇总是一个非常重要的网络优化手段,然而如果使用不当,也有可能带来问题,在上图中,R1左侧有192.168开头的一系列网络,为了让它们能够访问Internet,R1配置了指向R2的默认路由。而R2为了让数据能够回程,又为了精简路由表,配置了一条汇总路由192.168.0.0/16,并指向R1。这个网络看似没什么问题,但……
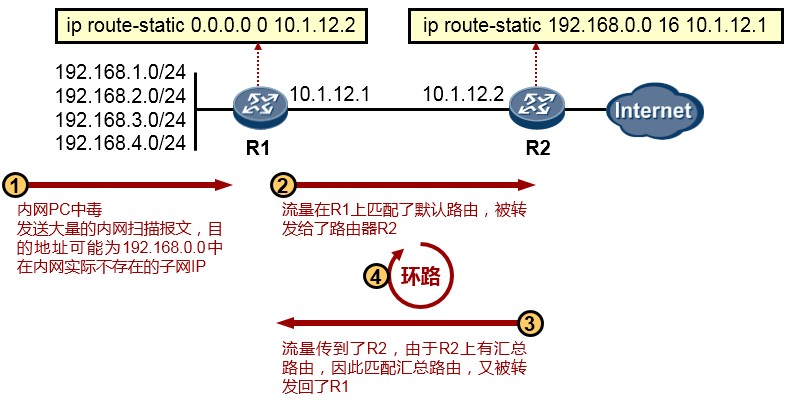
解决办法:
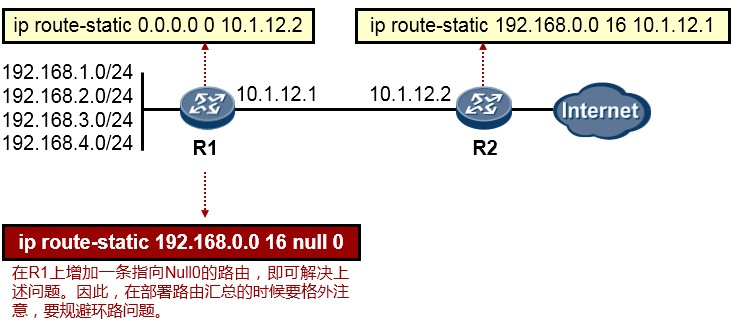
在R1上配置一条**ip route-static 192.168.0.0 16 null0**,即可解决上述问题。这是一条黑洞路由,Null0 有点类似垃圾桶的概念。当R1收到非法扫描报文(发往192.168网络下不存在的目的)时,这些报文就会被R1直接丢弃,而不会再被转发给R2了,这就解决了数据环路的问题。这个思路在路由汇总的时候非常关键,许多动态路由协议在使用命令执行路由汇总后,会在本地路由表中自动产生一条指向null0 的汇总路由。因此,无论是采用静态路由,或者是动态路由协议来部署路由汇总,都应格外留意路由汇总是否可能引发数据环路。
- 最长匹配原则
最长匹配原则是华为支持IP路由的设备的默认路由查询方式(事实上几乎所有支持IP路由的设备都是这种查询方式)。当路由器收到一个IP数据包时,会将数据包的目的IP地址与自己本地路由表中的路由表项进行
bit by bit的逐位查找,直到找到匹配度最长的条目,这叫最长匹配原则。
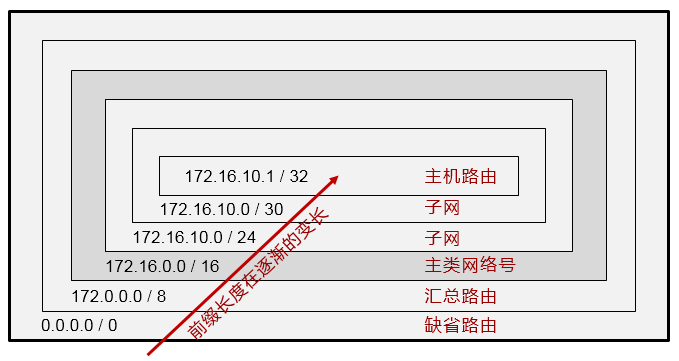
看上面的图,这是一个形象化的二维空间图。深灰色的空间172.16.0.0/16,这个网络我们称之为主类网络
(Classful Network),所谓主类网络,意思是该网络是按照其所属的IP地址类别区分之后,对应默认的掩码长度后得到的网络。例如172.16.0.0 , 这是一个B类地址, B类地址的默认掩码长度是/16 ,因此
172.16.0.0/16就是一个主类网络。再举另外一个例子:10.1.12.0/24,首先10开头的是一个A类地址,A类地址的默认掩码是255.0.0.0(/8),因此10.1.12.0/24的主类网络是10.0.0.0/8。10.1.12.0/24被包含在10.0.0.0/8之中。
回到上面的图,从172.16.0.0/16开始往里走,下一个看到的网络是172.16.10.0/24,很明显这是应用了VLSM
(可变长子网掩码)之后得到的172.16.0.0/16这个主类网络里的一个子网(Subnet)。所谓子网,我们可以理解为是在一个网络所属类别的默认掩码长度的基础上,将掩码“拉长”或者向主机位借位从而得到的一个子网络。实际上172.16.0.0/16是将172.16.10.0/24囊括在内的。那么如果我们有一个IP地址:172.16.10.1, 实际上这个IP地址既可以理解为在172.16.0.0/16网络内,也是在172.16.10.0/24网络内,那么这两个网络地址,哪一个更能精确匹配172.16.10.1这个IP地址呢?很明显是172.16.10.0/24。
当然172.16.10.0/24还可以进一步划分子网,得到172.16.10.0/30,甚至172.16.10.1/32,那么如果这些前缀都存在时,当我要去查找172.16.10.1,谁的匹配度最高呢?很明显,是172.16.10.1/32这条主机前缀。
现在回到172.16.0.0/16这个主类网络,然后向外走。172.0.0.0/8实际上是将这个B类地址的掩码向左移了8bit, 此时得到的网络实际上是囊括了172.16.0.0/16在内的一个大的网络,我们称其为超网。
下面我们通过一个具体的例子来深入理解最长匹配原则:
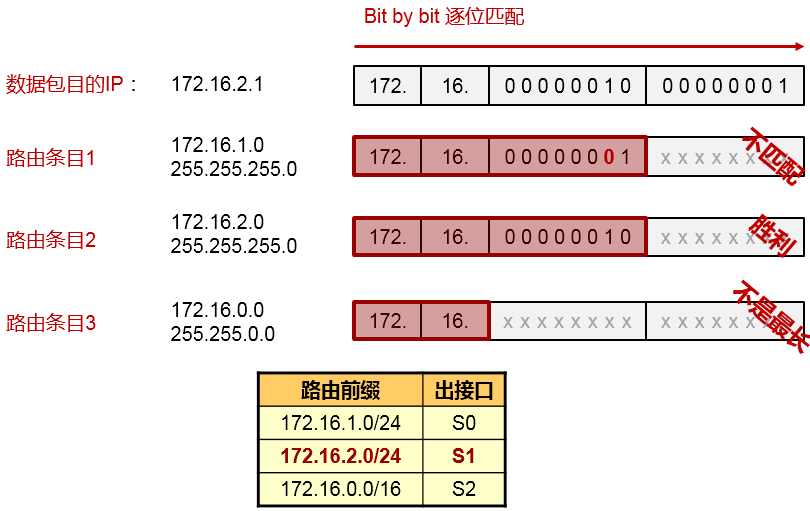
在上面的例子中,路由表一共有三个条目:172.16.1.0/24、172.16.2.0/24以及172.16.0.0/16,这三个路由条目分别指向不同的出接口。那么当路由器收到去往172.16.2.1的数据包时,它该怎么做决策呢?很简单, 把三个路由条目都写成二进制格式,对应各自的网络掩码(前缀长度),掩码为1的位是需要严格匹配的, 掩码为0的位则无所谓(图中标识x的位)。然后把数据包的目的IP地址172.16.2.1也写成二进制格式,接下来与三条路由从左往后逐位匹配。剔除不匹配的路由条目1,剩下路由条目2和3,由于目的地址172.16.2.1 和路由条目172.16.2.0/24的匹配长度最长,因此路由条目2胜出,该路由用于指导路由器如何转发前往
172.16.2.1的数据。最终数据包从接口S1转发出去。这就是最长匹配原则。下面看几个宏观的例子:
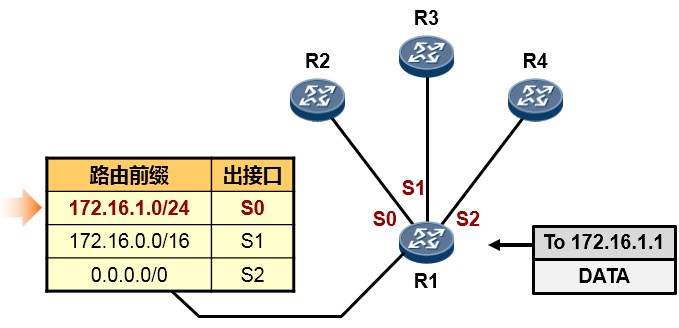
在上图中,当R1收到一个发往172.16.1.1的数据包时,数据包将命中哪一条路由呢?实际上,172.16.1.1是
“掉落”在172.16.1.0/24及172.16.0.0/16网络中的,两者貌似皆可,但是172.16.1.0/24匹配度更长,因此,
根据路由条目“172.16.1.0/24”的指示,这个数据包被转发给了R2。
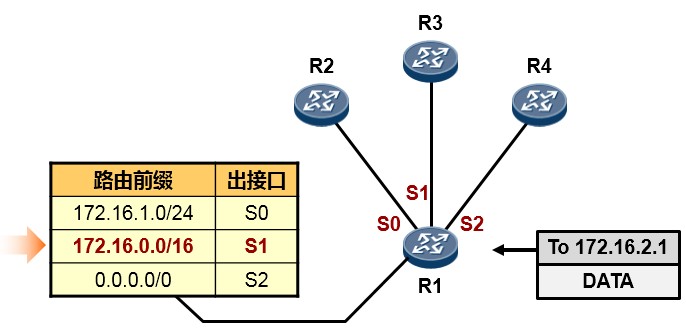
再如上图所示,若有数据包去往172.16.2.1呢?首先路由表中172.16.1.0/24这条路由肯定是不匹配该目的IP 地址的,最后,172.16.0.0/16这个条目的匹配长度最长,因此路由器使用该路由来转发前往172.16.2.1的数据包。
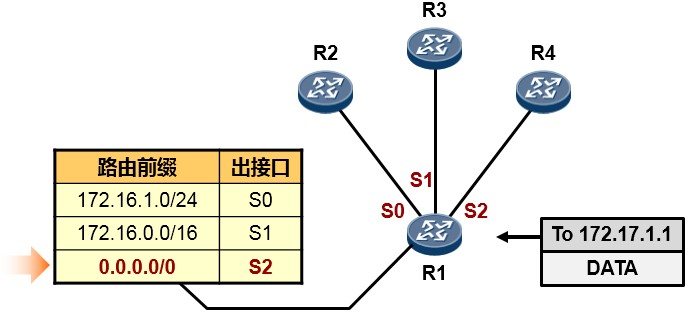
而当有数据包去往172.17.1.1时,由于172.16.1.0/24及172.16.0.0/16这两条路由均不匹配该目的IP地址,于 是路由器只能“求助于”0.0.0.0/0这条缺省路由,将无法匹配任何具体路由的数据包按照默认路由的指示, 从S2接口转发出去。
下面总结一下路由器关于路由查找的几个关键点:
- 不同的路由前缀(注意路由前缀包含目的网络地址与网络掩码,两者缺一不可),在路由表中属于不同的路由。例如192.168.10.0/24及192.168.10.0/30,这在路由表中是两条不同的路由。
- 相同的路由前缀(目的网络地址与网络掩码都分别相同),如果通过不同的协议获取,则先比路由的优先级,优选优先级值更小的路由加载到路由表,如果路由来源于相同的路由协议,那么它们的优先级便会是相等的,此时再比路由的Cost,优选Cost更优的路由加载到路由表。这是一般情况,当然有二般情况,这就要看特定的环境和特定的路由协议了。
- 路由器默认采用最长匹配原则,在其路由表中查询报文的目的IP地址,并试图找到匹配度最长的表项。如果找到了匹配的表项,则转发数据包;如果没有任何具体路由匹配该目的IP地址,则求助于默认路由,
如果路由表中不存在默认路由,则只能丢弃该数据包。
- IP路由的行为是逐跳执行的,因此从源到目的网络的路径中,沿途的每个路由器都必须拥有到达目的网络的路由。
- 网络的通信往往是双向的,因此在网络中调试设备的路由功能时,一般需考虑双向的路由。
- 动态路由协议基础
为什么要有动态路由协议¶
路由器是依赖自己维护的路由表来进行数据转发的,而通常路由表又是由许多路由条目构成的,路由器要将数据转发到目的地就必须有路由。一台路由器可以从多种来源学习路由条目:
直连路由¶
路由器在初始启动后,如果我们为其接口配置了IP地址,并且接口的物理及协议的状态都为UP,则路由器能够自动地学习到达该接口所在网络的直连路由,并将这条直连路由装载进路由表,这其实很好理解,因为这是我“家门口”的网络嘛,无需人为干预,自动学习。
静态路由¶
路由器对于到达直连网络的路由(直连路由)能够自动学习,可是对于到达非直连网络的路由可就无法自动学习了,一种最简单的方式就是通过手工配置的方式为路由器创建静态的路由表项,这叫静态路由。静态路由是网络管理员手工配置的,因此可管理性非常高,但是也有明显的缺陷,因为你要到一个目的地,就必须做一条静态路由的配置,那么如果网络特别庞大、设备数量特别多呢?工作量就相当大了,这是低效且不切实的;再者静态路由无法根据网络拓扑的变更做出动态响应,因此当网络发生变化时,管理员可能不得不重新配置或调整静态路由。因此,我们迫切需要一种动态的机制,来帮助路由器更加灵活地维护路由信息。
动态路由协议的分类¶
根据作用的范围,动态路由协议可分为:
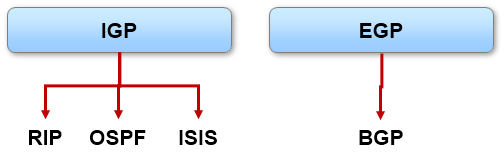
- 内部网关协议(Interior Gateway Protocol,简称IGP):在一个自治系统内部运行。
-
外部网关协议(Exterior Gateway Protocol,简称EGP):运行于不同自治系统之间。
BGP路由协议几乎是目前业界唯一在使用的EGP。笔者将在本手册的“BGP”一章中介绍BGP路由协议。
根据使用的算法,路由协议可分为:
-
距离矢量协议(Distance-Vector):典型的有RIP和BGP。其中,BGP也被称为路径矢量协议(Path-
Vector)。
-
链路状态协议(Link-State):典型的有OSPF和IS-IS。
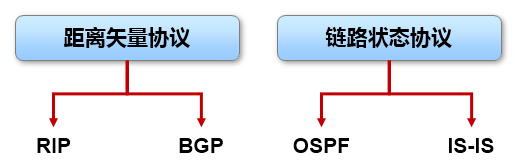
关于链路状态路由协议¶
运行了距离矢量路由协议的路由器直接将自己的路由表更新给直连的邻居路由器,并且这些路由器并不了解整个拓扑结构,这很容易在特定情况下产生诸如路由环路之类的问题(因此距离矢量路由协议定义了一系列防止环路的特性)。
相比之下,运行了链路状态路由协议的路由器之间则更新的不是路由表或路由条目,而是包括对链路
(接口)的描述在内的相关信息,这些信息被称为链路状态信息,通过链路状态信息的泛洪,路由器搜集这些信息并将其装载进链路状态数据库,随后运行特定的算法,计算出一个无环的拓扑。因此运行链路状态路由协议的路由器是知晓网络的拓扑结构的。
链路状态路由协议应该说是目前业内IGP应用的主流,其中最具代表性的当属OSPF和ISIS。
- OSPF
- OSPF 概述
OSPF是典型的链路状态路由协议,也是目前使用得最为广泛的动态路由协议之一。下面我们先简略地了解一下OSPF的基本工作过程:
LSA的泛洪¶

运行链路状态路由协议的路由器之间首先会基于路由协议建立邻居关系,之后彼此之间开始交互LSA
(Link State Advertisement,链路状态通告),注意这里交互的不是路由信息,而是链路状态通告,这些LSA有助于路由器还原网络的拓扑结构、网段信息,并依据这些信息计算最佳路由。
LSDB的组建¶
每台路由器都会产生LSA,路由器将网络中所泛洪的LSA搜集起来、放入自己的LSDB(Link State
DataBase,链路状态数据库),有了LSDB,路由器也就清楚了全网的拓扑。
SPF计算¶
接下来,每台路由器基于LSDB、使用SPF(最短路径算法)进行计算。SPF是OSPF路由协议的一个核心算法,用来在一个复杂的网络中做出路由优选的决策。经过SPF算法的计算后,每台路由器都计算出一棵以自己为根的、无环的、拥有最短路径的“树”。有了这棵“树”,事实上路由器就已经知道了到达网络各个角落的最优路径。
维护路由表¶
最后,路由器将计算出来的最优路径,加载进自己的路由表。
OSPF(Open Shortest Path First)开放最短路径优先协议,是一种链路状态路由协议,也是目前业内使用得最为广泛的IGP。OSPF中的字母O意为Open,也就是开放、公有。与距离矢量路由协议直接交互路由器的路由表不同,OSPF作为链路状态路由协议,路由器之间交互的是LSA,路由器将网络中泛洪的LSA搜集到自己的LSDB中,这有助于OSPF理解整张网络拓扑,并在此基础上通过SPF算法计算出以自己为根的、到达网络各个角落的、无环的树,最终,路由器将计算出来的路由装载进路由表中。
- OSPF 基本概念
Router-ID¶
OSPF Router-ID用于在OSPF域中唯一地标识一台OSPF路由器,从OSPF网络设计的角度,我们要求全
OSPF域内,禁止出现两台路由器拥有相同RouterID的情况。
Router-ID的格式与IPv4地址的格式相同,例如192.168.1.1。Router-ID的设定可以通过手工配置的方式进行, 或者通过协议自动选取的方式进行。当然,在实际网络部署中,强烈建议网络管理员手工配置OSPF的Router-ID,因为这关系到协议的稳定性。一般情况下,我们会将路由器的Router-ID指定为该设备上的某个
Loopback接口地址。
Cost¶
OSPF使用开销(Cost)作为路由度量值。首先,每一个激活OSPF的接口都有一个接口的Cost值。OSPF 接口Cost=100M / 接口带宽,其中100M为OSPF的参考带宽(Reference-Bandwidth)。换句话说,接口的带宽越高,该接口的OSPF Cost越小。一条OSPF路由的Cost由该路由从路由的起源一路到达本地的所有入接口Cost值的总和。
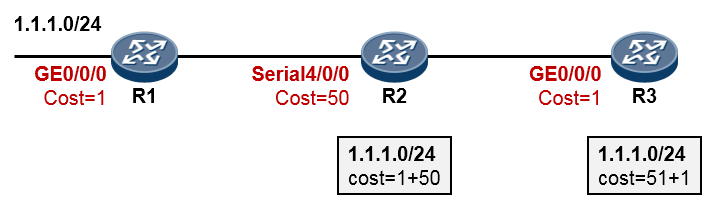
在上图中,对于R2而言,其到达R1的直连网络1.1.1.0/24的OSPF路由的Cost值为R1-GE0/0/0接口的Cost 加上R2-S4/0/0接口的Cost,也就是1+50=51。相对的,R3如果通过OSPF学习到1.1.1.0/24路由,该路由的
Cost值就是1+50+1=52。
另外,由于默认的参考带宽是100M,这意味着更高带宽的传输介质(高于100M)在OSPF协议中将会计算出一个小于1的分数,这在OSPF协议中是不允许的(会被四舍五入为1)。而现今网络设备满地都是大于
100M带宽的接口,这时候路由COST的计算其实就不精确了。所以可以使用**bandwidth-reference**命令修改,但是这条命令要谨慎使用,一旦要配置,则建议全网OSPF路由器都配置。
报文类型¶
OSPF一共有五种报文,各有各的用途:
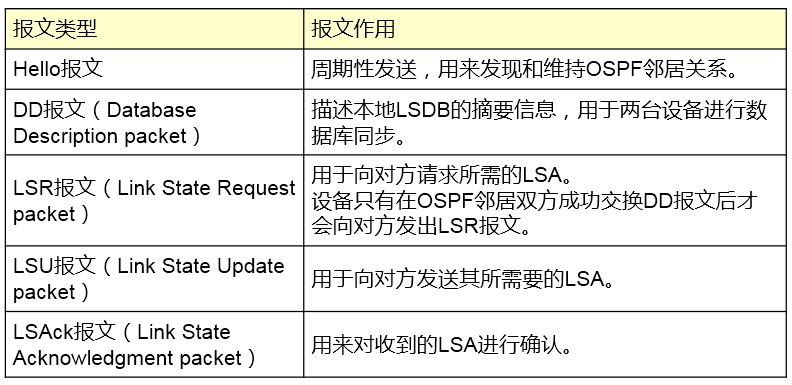
OSPF的三张表¶
邻居表(Peer table):¶
路由器的OSPF邻居表里存放的是该路由器发现的、直连链路上的OSPF邻居。只有直连的路由器之间才能够建立OSPF邻居关系。OSPF通过Hello报文发现直连链路上的邻居。
链路状态数据库LSDB(Link-state Database):¶
OSPF用LSA来描述网络拓扑信息、网段信息或路由信息。路由器用LSDB来存储网络中的LSA。OSPF 将自己产生的以及邻居通告的LSA搜集并存储在LSDB中,然后基于这些数据,运行SPF算法并最终得到一棵无环的树。掌握LSDB的查看以及对LSA的深入分析才能够深入理解OSPF。
OSPF路由表(Routing table):¶
基于LSDB进行SPF计算后得出的OSPF路由被加载到OSPF路由表中。
OSPF邻居关系建立过程¶

OSPF邻居关系的建立过程是我们在学习OSPF过程中的一个重点,而且非常具有研究价值,就OSPF的实际部署而言,掌握这里头的机制也是很有必要的,因为邻居关系的建立是OSPF工作的基本,如果连邻居关系都建立不起来,就别谈其他的了。在实际业务部署中,可能会碰到各种问题导致OSPF邻居关系无法正常建立,因此这个内容非常值得推敲。
本文描述数据通信基础性知识,因此更加深入的内容暂不涉及。
OSPF网络类型¶
一旦我们在路由器的某个接口上激活了OSPF,那么路由器将会根据这个接口的数据链路层封装协议,选择对应的OSPF网络类型并进行工作,注意,针对不同的网络类型,OSPF在接口上的操作将有所不同。因此简单地说,OSPF网络类型实际上是OSPF的一个接口级别的属性,它将影响OSPF在该接口上的操作。
OSPF支持的网络类型:¶
- 点到点网络(Point-To-Point Network)
- 广播型多路访问网络(Broadcast Multiple Access Network)
- 非广播型多路访问网路(Non-Broadcast Multiple Access Network)
- 点到多点网络(Point-To- MultiplePoint Network)
常见数据链路层协议对应的默认网络类型:¶
| 网络类型 | 含义 |
|---|---|
| 广播类型 | 当链路层协议是Ethernet、FDDI时,缺省情况下,OSPF认为网络类型 是Broadcast。在该类型的网络中: 通常以组播形式发送Hello报文、LSU报文和LSAck报文。其中, 224.0.0.5的组播地址为OSPF设备的预留IP组播地址;224.0.0.6的组播地址为OSPF DR/BDR的预留IP组播地址。 以单播形式发送DD报文和LSR报文。 |
|---|---|
| NBMA类型 | 当链路层协议是帧中继、X.25时,缺省情况下,OSPF认为网络类型是 NBMA。 在该类型的网络中,以单播形式发送协议报文(Hello报文、DD报文、 LSR报文、LSU报文、LSAck报文)。 |
| 点到多点P2MP类型 | 没有一种链路层协议会被缺省的认为是Point-to-Multipoint类型。点到多 点必须是由其他的网络类型强制更改的。常用做法是将非全连通的 NBMA改为点到多点的网络。在该类型的网络中: 以组播形式(224.0.0.5)发送Hello报文。 以单播形式发送其他协议报文(DD报文、LSR报文、LSU报文、 LSAck报文)。 |
| 点到点P2P类型 | 当链路层协议是PPP、HDLC和LAPB时,缺省情况下,OSPF认为网络 类型是P2P。 在该类型的网络中,以组播形式(224.0.0.5)发送协议报文(Hello报文、DD报文、LSR报文、LSU报文、LSAck报文)。 |
如果一个接口是以太网接口,那么该接口激活OSPF后,其缺省的OSPF网络类型为Broadcast,也就是广播型。而如果一个接口是Serial接口,二层封装为HDLC或者PPP,那么激活OSPF后,其缺省的OSPF网络类型就是P2P(Point-to-Point,点对点)。接口的OSPF网络类型是可以通过命令修改的。
DR、BDR¶
MA(Multi-Access,多路访问)网络指的是一个可以同时接入多个节点的网络,在这个环境中,任何一个节点都能通过这个网络访问其他节点。MA网络可以分为BMA(Broadcast Multi-Access,广播型多路访问)网络和NBMA(Non-Broadcast Multiple Access,非广播型多路访问)网络。对于BMA网络,典型的代表是以太网,而对于NBMA,典型的代表是帧中继。
我们以以太网为例,例如上图所示,所有的路由器都连接在同一台以太网二层交换机上(图片中并没有绘制出交换机),并且属于相同的VLAN,而且规划相同的IP网段,在这个环境中,任何一台路由器都能通过接入该交换机的接口访问其他路由器,这就是多路访问网络的体现。此外这个网络还支持广播。在这个网络中,如果将所有路由器的接口都激活OSPF并且这些接口两两建立OSPF邻居关系,那么这就意味着网络中共有:
n(n-1)/2¶
这么多个OSPF邻居关系,维护如此多的邻居关系不仅会对设备性能造成影响,更增加了网络中LSA的泛洪数量,如上图(右)所示。
为减少MA网络中的OSPF流量、优化OSPF邻居关系结构,OSPF会在每一个MA网络中选举一个指定路由器 (DR) 和一个备用指定路由器 (BDR)。
- DR选举规则:在一个MA网络中,最高OSPF接口优先级的拥有者被选作DR,如果优先级相等(默认值为1),则具有最高的OSPF Router-ID的路由器被选举成DR。DR具有非抢占性,也就是说如果该MA 网络中已经选举出了DR,那么后续即使有具备更高优先级的设备加入,也不会影响当前DR的角色。
- 指定路由器 (DR):DR负责侦听MA网络中的拓扑变更信息并将变更信息通知给其他路由器,同时负责代表该MA网络发送Type-2 LSA。在一个MA网络中,所有的OSPF路由器都与DR(以及BDR)建立全毗邻的OSPF邻接关系。
- 备用指定路由器 (BDR):BDR会监控DR的状态,并在当前DR发生故障时接替其角色。
- 注意:DR及BDR的身份状态是基于OSPF接口的,所以如果我们说:“这台路由器是DR”,那么这种说法是不严谨的,严格的说,应该是:“这台路由器的这个接口,在这个MA网络上是DR”。
- 在一个MA网络中,所有的DRother路由器(既非DR,又非BDR)均只与DR和BDR建立全毗邻的邻接关系,DRother间不建立邻接关系,如此一来,该MA网络中的设备需要维护的OSPF邻居关系数量大幅减小:M= (n-2)×2+1,设备性能也会得到优化。
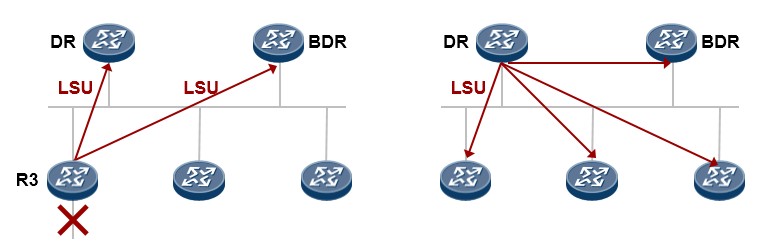 OSPF在Broadcast及NBMA网络中都会选举DR,但是在P2P或P2MP网络中则不会。接下去看看在MA网络中,有了DR、BDR之后,LSA的泛洪过程:
OSPF在Broadcast及NBMA网络中都会选举DR,但是在P2P或P2MP网络中则不会。接下去看看在MA网络中,有了DR、BDR之后,LSA的泛洪过程:- 假设网络已经完成了OSPF收敛,现在突然R3下挂的一个网络发生了故障;
- 路由器R3用224.0.0.6(即R3以该组播地址为目的IP地址,发送OSPF报文)通知DR及BDR;
- DR、BDR监听224.0.0.6这一组播地址,获知了该更新;
- DR向组播地址224.0.0.5发送更新以通知其它路由器;
- 所有的OSPF路由器监听224.0.0.5这一组播地址;
-
路由器收到包含变化后的LSA的更新后,刷新自己的LSDB,过一段时间(SPF延迟),对更新的链路状态数据库执行SPF算法,必要时更新路由表。
OSPF使用两个知名的组播地址:224.0.0.5及224.0.0.6,这是一个常识,需熟记。所有的OSPF路由器(的接口)都会侦听发向224.0.0.5的报文,在此基础之上,DR/BDR会侦听224.0.0.6。
OSPF 区域(Area)的概念¶
单区域存在的问题:¶
设想一下,如果OSPF没有多区域的概念,或者整个OSPF网络就是一个区域,那么会有什么问题?在一个区域内,LSA会被泛洪到整个区域,每一台路由器都会收到区域内的LSA并且存储在自己的LSDB 中,OSPF规定同属于一个区域的路由器必须有统一的LSDB,因为只有这样才能够让OSPF进行准确的计算。
如果网络规模特别大,容纳的路由器数量特别多,则区域内泛洪的LSA数量就会特别多,那么所有的路由器将不得不维护一个庞大的LSDB,显然这增加了路由器的资源消耗。另外,一旦网络中发生拓扑变更,则又将引发大量的LSA泛洪,同时所有的路由器又要重新的进行SPF计算。同时,每台路由器都需要维护的路由表越来越大,因为单区域内路由无法实施汇总。
OSPF多区域:¶
基于上述原因,OSPF设计了区域(Area)的概念,每个区域都使用area-ID进行标识,通常area-ID采用十进制形式标识,例如area 0,area 1等,也可采用点分十进制的形式(与IPv4地址格式相同)来标识, 例如area 0.0.0.0(等同于area 0)。当然,为了简便起见,我们通常采用前面一种形式。
- 多区域的设计减小了LSA洪泛的范围,有效地把拓扑变化控制在区域内,达到网络优化的目的;
- 在区域边界可以做路由汇总,减小了路由表规模;
- 充分利用OSPF特殊区域的特性,进一步减少LSA泛洪,从而优化路由;
- 多区域特性提高了网络的可扩展性,有利于组建大规模的OSPF网络。
OSPF区域中的骨干区域area0:¶
在部署OSPF时,如果存在多区域,则要求OSPF域内必须有且只能有一个area0。
Area 0为OSPF的骨干区域,骨干区域负责在非骨干区域之间发布由区域边界路由器汇集的路由信息, 从而实现区域之间的互通。为避免区域间的路由环路,非骨干区域之间不允许直接相互发布区域间路由。因此,每个非骨干区域都必须连接到骨干区域。
OSPF路由器的角色¶
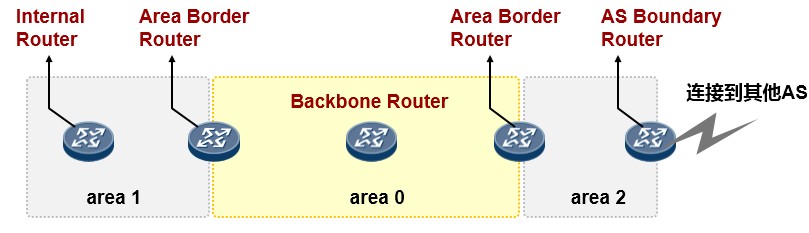
OSPF路由器的角色:
- 区域内路由器(Internal Router)
- 区域边界路由器(Area Border Router)
- 骨干路由器(Backbone Router)
- AS边界路由器(AS Boundary Router)
- OSPF 的基础配置
基础配置¶
创建一个OSPF进程,并指定OSPF进程号及Router-ID¶
[Router] ospf [ process-id | router-id router-id ]
其中process-id为进程号。另外**Router-ID**关键字指定的是本台路由器在该OSPF进程中使用的Router-
ID,建议在创建OSPF进程时采用该方法手工配置Router-ID。如果在创建OSPF进程时,没有手工指定Router-ID,则路由器会自动为该进程指定一个Router-ID。
进入OSPF区域视图,将特定的接口激活OSPF¶
上面的**network**命令用于在特定接口上激活OSPF。在激活某个接口的OSPF功能时,必须先进入特定
的OSPF区域配置视图。在**network**关键字后,紧跟着的是IP地址,然后是通配符掩码,这两者是息息相关的,它们在一起的运算决定了本设备哪些接口会激活OSPF。
通配符掩码Wildcard-mask:¶
通配符掩码是一个用于决定IP地址中哪些比特位该严格匹配(为0的比特位代表需严格匹配)、哪些比特位无需匹配(为1的比特位)的32bit数值。通配符掩码也常用于处理访问控制列表(ACL)。下面看一下网络掩码netmask和通配符掩码wildcard-mask的区别:
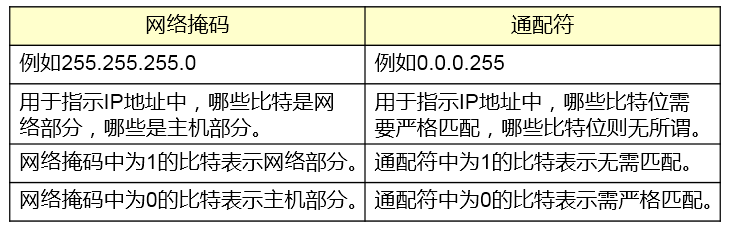
接下去看几个例子:
在上面的例子中,如果我们在路由器上采用如下配置:
注意,我们在**network**命令后关联的IP地址是172.16.1.0,通配符掩码是0.0.0.255,将这两个数都转成
二进制,然后将各个比特位一一对应(如图所示),通配符为0的比特位,必须严格匹配,为1的位则无所谓。现在,我们看路由器的接口IP地址,将这些IP地址拿去做对应,如果能匹配上,那么接口就激活
OSPF,否则就不激活。例如路由器配置了172.16.1.1这个IP地址的接口,由于该IP地址满足要求—— 前3个八位组与172.16.1.0的前3个八位组相同,最后一个八位组无需相同,因此该接口会激活OSPF。而另外两个接口不满足条件,因此不激活OSPF。
再看下面的例子:
由于**network**命令使用的IP地址和通配符掩码是172.16.0.0 0.0.255.255,也就是最后两个八位组无所谓,前两个八位组必须是172.16,因此如上图所示,路由器将有两个接口激活OSPF。当然,如果还是以上图为例,假设我们想只激活172.16.3.1/24这个接口,而且要求尽可能精确,那么**network**命令完全可以这么写:network 172.16.3.1 0.0.0.0。
通常,我们在配置OSPF时,如果想要在某个接口上激活OSPF,例如该接口的IP地址为192.168.1.1/24, 那么一般会使用命令**network 192.168.1.0 0.0.0.255**,留意到接口地址的网络掩码是255.255.255.0, 而用于激活OSPF 的命令中,通配符是0.0.0.255 , 这实际上是用255.255.255.255 与网络掩码
255.255.255.0做“减法”,从而得到0.0.0.255,因此,我们经常将通配符掩码称为“反掩码”。

示例(单区域)¶

网络拓扑中包含三台路由器及两台PC;每台路由器使用x.x.x.x的地址作为OSPF的RouterID,其中x为设备编号,例如R1的RouterID为1.1.1.1,设备的接口编号及IP编址如图所示。
R1的配置如下:¶
R2的配置如下:¶
R3的配置如下:¶
完成配置后我们来做一下查看及验证,首先看一下OSPF的邻居关系,这是OSPF路由收敛的基础,如果邻
居关系的状态不正确,那么路由肯定是无法正常获悉的,首先看一下R1的邻居表:
使用**display ospf peer**命令能查看OSPF邻居关系,上面的输出就是R1的OSPF邻居表,我们看到R1发现
了一个OSPF 邻居, 这个OSPF邻居是连接在R1的GE0/0/0口上,且其Router-ID 为2.2.2.2,接口IP为
192.168.12.2,最重要的是状态为Full,表示R1与R2的OSPF邻居关系已经为全毗邻状态。一般来讲,两台
设备如果正常地建立了邻接关系,那么状态必须为Full。
同理在R2上应该能看到两个OSPF邻居,而在R3上能看到一个OSPF邻居。接下去看看路由表。
| [R1] display ip routing-table Route Flags: R - relay, D - download to fib ------------------------------------------------------------------------------ Routing Tables: Public Destinations : 12 Routes : 12 | ||||||
|---|---|---|---|---|---|---|
| Destination/Mask | Proto | Pre | Cost | Flags | NextHop | Interface |
| 192.168.1.0/24 | Direct | 0 | 0 | D | 192.168.1.254 | GigabitEthernet0/0/1 |
| 192.168.1.254/32 | Direct | 0 | 0 | D | 127.0.0.1 | GigabitEthernet0/0/1 |
| 192.168.1.255/32 | Direct | 0 | 0 | D | 127.0.0.1 | GigabitEthernet0/0/1 |
| 192.168.2.0/24 | OSPF | 10 | 3 | D | 192.168.12.2 | GigabitEthernet0/0/0 |
| 192.168.12.0/24 | Direct | 0 | 0 | D | 192.168.12.1 | GigabitEthernet0/0/0 |
| 192.168.12.1/32 | Direct | 0 | 0 | D | 127.0.0.1 | GigabitEthernet0/0/0 |
| 192.168.12.255/32 | Direct | 0 | 0 | D | 127.0.0.1 | GigabitEthernet0/0/0 |
| 192.168.23.0/24 | OSPF | 10 | 2 | D | 192.168.12.2 | GigabitEthernet0/0/0 |
| 255.255.255.255/32 | Direct | 0 | 0 | D | 127.0.0.1 | InLoopBack0 |
在上述输出中,我们看到R1已经学习到两条OSPF路由,分别是192.168.2.0/24及192.168.23.0/24;同理在
R2就R3上也能看到相应的OSPF路由。现在PC1及PC2就能够互相通信了。
示例(单区域综合实验)¶
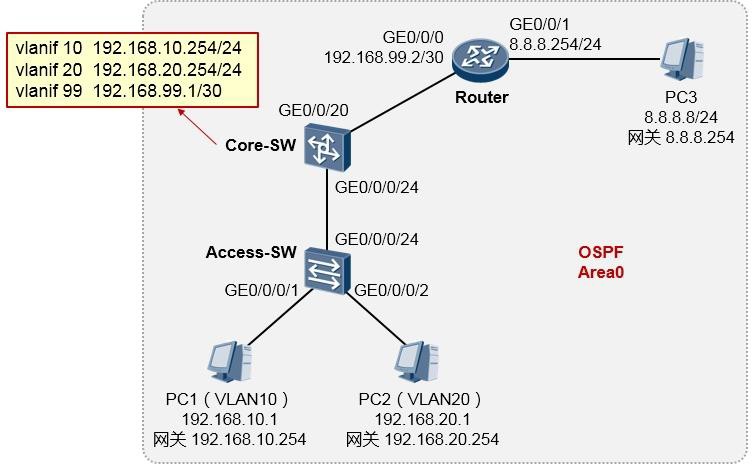
在上图中,PC1及PC2分别属于VLAN10及VLAN20,它们的网关都在核心交换机Core-SW上。Access-SW 是接入层交换机,只做二层透传。路由器Router连接着PC3,并且与核心交换机对接。要求在网络中部署
OSPF,使得PC1及PC2能够与PC3互通。Access-SW的配置如下:
Core-SW的配置如下:
Router的配置如下:
完成上述配置后,来做一下相关验证,首先查看Core-SW的OSPF邻居表:
从输出中可以看出,它已经于Router建立了全毗邻的邻接关系。再看看它的路由表中的OSPF路由:
我们看到Core-SW已经学习到了8.8.8.0/24路由。同样在Router上查看路由表,也会发现其已经学习到
192.168.10.0/24及192.168.20.0/24路由,如此一来,PC1/PC2即可与PC3实现相互通信。
示例(多区域)¶
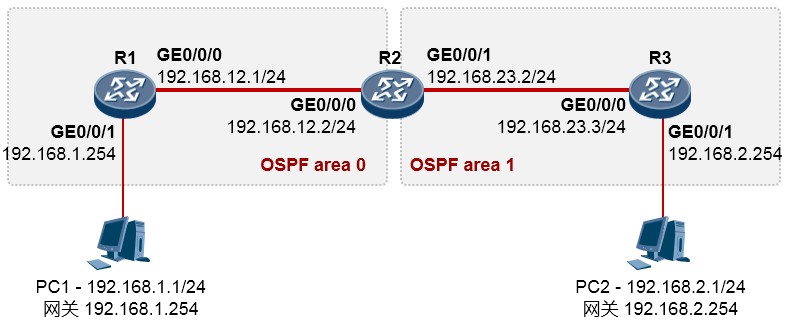
网络中包含三台路由器及两台PC;每台路由器使用x.x.x.x的地址作为OSPF的RouterID,其中x为设备编号, 例如R1的RouterID为1.1.1.1;OSPF区域的规划如图所示;
设备的接口编号及IP编址如图所示。注意到我们在网络中规划了两个OSPF区域。值得注意的是,路由器的接口必须在正确的区域中激活。两台直连的设备要建立OSPF邻接关系,那么直连的两个接口需在相同的区域中激活OSPF。例如R1的GE0/0/0及R2的GE0/0/0接口,都必须在area0中激活,而R2的GE0/0/1及R3的
GE0/0/0接口必须在area1中激活OSPF。
R1的配置如下:
R2的配置如下:
R3的配置如下:
完成配置后,PC1与PC2即可互相ping通。
查看及验证¶
-
查看OSPF协议相关运行参数:
display ospf brief
-
查看OSPF邻居表:
display ospf peer
-
查看LSDB表:
display ospf lsdb
-
查看OSPF路由:
display ospf routing
-
OSPF LSA 及特殊区域
OSPF LSA类型¶
LSA是OSPF中非常关键的概念,也是OSPF网络正常运行的根本。LSA是描述网络拓扑、网段信息、路由信息等内容的一系列链路状态信息。完整的LSA信息只在OSPF LSU报文中存在。
常见的OSPF LSA类型及描述如下:
| LSA类型 | LSA名称 | LSA描述 |
|---|---|---|
| 1 | Router-LSA | 每个设备都会产生,描述了设备的链路状态和开销,在所属的区域内传播。 |
| 2 | Network-LSA | 由DR产生,描述本网段的链路状态,在所属的区域内传播。 |
| 3 | Network-summary-LSA | 由ABR产生,描述区域内某个网段的路由,并通告给发布或接收此LSA的非 Totally STUB或NSSA区域。 |
| 4 | ASBR-summary-LSA | 由ABR产生,描述到ASBR的路由,通告给除ASBR所在区域的其他相关区域。 |
| 5 | AS-external-LSA | 由ASBR产生,描述到AS外部的路由,通告到所有的区域(除了STUB区域和 NSSA区域)。 |
| 7 | NSSA LSA | 由ASBR产生,描述到AS外部的路由,仅在NSSA区域内传播。 |
特殊区域详解¶
为了优化OSPF的运行,使得OSPF能够支撑更大规模的网络,OSPF定义了几种特殊的区域类型。首先看一下本小节用于讲解相关知识点所使用的拓扑:
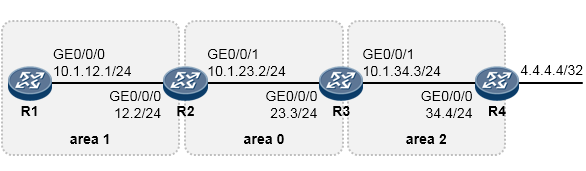
拓扑中包含四台路由器,接口IP地址如图所示,现在按照图示的要求完成OSPF的配置,同时在R4上创建
Loopback1接口,接口配置IP地址4.4.4.4/32,然后将这条直连路由重发布到OSPF中。
接下来是我们的分析步骤:¶
- R1、R2、R3、R4运行OSPF,在相应的接口上激活OSPF,OSPF的区域规划如图所示;
- R4将Loopback0接口的直连路由重发布到OSPF。完成配置后,观察各台路由器的路由表和LSDB;
- 将area1配置为Stub区域,观察路由和LSA的变化;
- 将area1修改为Totally-Stub区域,观察路由和LSA的变化;
-
将area1恢复为常规区域,在R1上创建Loopback0接口,配置地址:1.1.1.1/32并将直连路由重发布到
OSPF;将area2配置为NSSA,观察路由及LSA的变化;
-
将area2修改为Totally NSSA,观察路由和LSA的变化。
完成基础配置¶
R1的配置如下:
R2的配置如下:
R3的配置如下:
R4的配置如下:
| 完成上述配置后,观察一下各个路由器的路由表及LSDB。 | ||||||
|---|---|---|---|---|---|---|
| [R1] display ip routing-table protocol ospf | ||||||
| Destination/Mask | Proto | Pre | Cost | Flags | NextHop | Interface |
| 4.4.4.4/32 | O_ASE | 150 | 1 | D | 10.1.12.2 | GigabitEthernet0/0/0 |
| 10.1.23.0/24 | OSPF | 10 | 2 | D | 10.1.12.2 | GigabitEthernet0/0/0 |
| 10.1.34.0/24 | OSPF | 10 | 3 | D | 10.1.12.2 | GigabitEthernet0/0/0 |
| R1学习到了全网的路由,包括R4注入的外部路由4.4.4.4/32,这条外部路由在路由表中标记为O_ASE, 表示为OSPF AS External,也就是OSPF的域外路由。接下来检查R1的OSPF LSDB: | ||||||
| [R1] display ospf lsdb OSPF Process 1 with Router ID 1.1.1.1 Link State Database Area: 0.0.0.1 | ||||||
| Type | LinkState ID | AdvRouter | Age | Len | Sequence | Metric |
| Router | 2.2.2.2 | 2.2.2.2 | 258 | 36 | 80000005 | 1 |
| Router | 1.1.1.1 | 1.1.1.1 | 261 | 36 | 80000004 | 1 |
| Network | 10.1.12.2 | 2.2.2.2 | 258 | 32 | 80000002 | 0 |
| Sum-Net | 10.1.23.0 | 2.2.2.2 | 294 | 28 | 80000001 | 1 |
| Sum-Net | 10.1.34.0 | 2.2.2.2 | 227 | 28 | 80000001 | 2 |
| Sum-Asbr | 4.4.4.4 | 2.2.2.2 | 215 | 28 | 80000001 | 2 |
| AS External Database | ||||||
|---|---|---|---|---|---|---|
| Type | LinkState ID | AdvRouter | Age | Len | Sequence | Metric |
| External | 4.4.4.4 | 4.4.4.4 | 222 | 36 | 80000001 | 1 |
| External | 10.1.34.0 | 4.4.4.4 | 222 | 36 | 80000001 | 1 |
以上输出的是R1的OSPF LSDB,从中可以看出在R1的LSDB中有1、2、3、4、5类LSA。其中3类LSA
(上面显示的Sum-Net)描述的是到达10.1.23.0/24及10.1.34.0/24这两个网段的区域间路由。4类LSA
(上面显示的Sum-Asbr)描述的是到达ASBR(R4)的路由,这条LSA由ABR R2产生。另外还有2条
AS外部LSA(上面显示的External),描述到达4.4.4.4/32和10.1.34.0//24的路由。此时R1是全网可达的。
将area1配置为Stub区域,观察路由及LSA的变化¶
R1的OSPF配置修改如下:
R2的OSPF配置修改如下:
注意,一旦将某个区域设置为Stub区域,则所有连接到这个区域的路由器都要将该区域配置为Stub区域,否则OSPF邻居关系将无法正确建立。
完成上述配置后,area1就变成了一个stub区域。Stub区域会阻挡来自骨干区域的5类LSA,这使得该区域内LSA泛洪的数量在一定程度上减少了,从而减小该区域中路由器的路由表规模,同时降低设备负担, 另外,Stub区域的ABR会为该区域产生一条使用3类LSA描述的缺省路由,用于Stub区域内的路由器走出该区域从而能够访问OSPF外部网络:

现在,再来观察R1的路由表和LSDB。
相比于area1为常规区域的情况,area1被设置为Stub区域后,R1的路由表更精简了,那是因为R2阻挡掉了来自OSPF的域外路由4.4.4.4/32。当然R1可以通过缺省路由0.0.0.0/0到达这些域外网络,这条缺省路由是R2下发的,使用3类LSA描述,且缺省路由的外部Cost为1,可以在R2的area1视图下使用**default-cost**命令来修改这个缺省的Cost值。再观察一下R1的LSDB:
| [R1] display ospf lsdb OSPF Process 1 with Router ID 1.1.1.1 Link State Database Area: 0.0.0.1 | ||||||
|---|---|---|---|---|---|---|
| Type | LinkState ID | AdvRouter | Age | Len | Sequence | Metric |
| Router | 2.2.2.2 | 2.2.2.2 | 616 | 36 | 80000004 | 1 |
| Router | 1.1.1.1 | 1.1.1.1 | 615 | 36 | 80000004 | 1 |
| Network | 10.1.12.1 | 1.1.1.1 | 615 | 32 | 80000002 | 0 |
| Sum-Net | 0.0.0.0 | 2.2.2.2 | 626 | 28 | 80000001 | 1 |
| Sum-Net | 10.1.23.0 | 2.2.2.2 | 627 | 28 | 80000001 | 1 |
| Sum-Net | 10.1.34.0 | 2.2.2.2 | 627 | 28 | 80000001 | 2 |
显然,R1的LSDB也精简了,此时在R1的LSDB中,没有4、5类LSA。仅有1、2、3类LSA。
将area1配置为Totally-Stub区域,观察路由及LSA的变化¶
在上一个需求的配置基础上,R2的OSPF配置修改如下:
[R2] ospf 1
将一个区域指定为Totally-Stub后,该区域将不会再收到来自骨干区域的3、4、5类LSA,也就是在stub
区域的基础上进一步抑制3类LSA的泛洪,同时该区域的ABR下发一条3类LSA缺省路由:

完成配置后再去R1上看看路由表和LSDB:
此时,R1的路由表变得非常简洁,只有一条缺省路由,除此之外,区域间路由10.1.23.0/24、10.1.34.0/24,以及域外路由4.4.4.4/32都已经消失了,R1的负担将变得非常小,并且当它需要去往这些网络时,又可以通过这条缺省路由出去。
再查看一下R1的LSDB:
| [R1] display ospf lsdb OSPF Process 1 with Router ID 1.1.1.1 Link State Database Area: 0.0.0.1 | ||||||
|---|---|---|---|---|---|---|
| Type | LinkState ID | AdvRouter | Age | Len | Sequence | Metric |
| Router | 2.2.2.2 | 2.2.2.2 | 347 | 36 | 80000005 | 1 |
| Router | 1.1.1.1 | 1.1.1.1 | 346 | 36 | 80000009 | 1 |
| Network | 10.1.12.1 | 1.1.1.1 | 347 | 32 | 80000002 | 0 |
| Sum-Net | 0.0.0.0 | 2.2.2.2 | 348 | 28 | 80000005 | 1 |
R1的LSDB也是非常简洁的,只有1、2类LSA,也就是用于计算本区域内路由的LSA,另外还有一条3
类LSA,这条3类LSA是描述0.0.0.0/0缺省路由的,由ABR R2产生。
将area1还原为常规区域,并重发布直连路由进OSPF;将area2配置为NSSA。¶
在上一个需求的配置基础上,R1的配置修改如下:
从以上配置可以看出,R1创建了一个Loopback接口,然后area1恢复为了常规区域,同时直连路由被
注入OSPF。1.1.1.1/32这条路由是我们接下去需观察的目标路由之一。
R2的配置修改如下:
此时R4的路由表如下:
| [R4] display ip routing-table protocol ospf | ||||||
|---|---|---|---|---|---|---|
| Destination/Mask | Proto | Pre | Cost | Flags | NextHop | Interface |
| 1.1.1.1/32 | O_ASE | 150 | 1 | D | 10.1.34.3 | GigabitEthernet0/0/0 |
| 10.1.12.0/24 | OSPF | 10 | 3 | D | 10.1.34.3 | GigabitEthernet0/0/0 |
| 10.1.23.0/24 | OSPF | 10 | 2 | D | 10.1.34.3 | GigabitEthernet0/0/0 |
从R4的路由表可以看出,R4此时能够学习到区域间路由10.1.12.0/24、10.1.23.0/24,以及域外路由
1.1.1.1/32。现在把area2配置为NSSA:
R3的配置修改为:
R4的配置修改为:
当一个区域被配置为NSSA区域(非完全末梢区域)后,该区域将不再允许来自骨干区域的4、5类LSA
泛洪,但是允许该区域内的路由器注入外部路由,这些外部路由被重发布进NSSA后以7类LSA描述, 这些7类LSA由NSSA的ABR执行转换变成5类LSA后进入骨干区域:
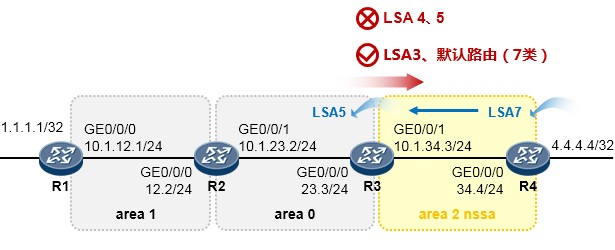
所以,当area2被配置为NSSA后,R3将不能再把4、5类LSA泛洪到area2中,因此R1引入的外部路由
1.1.1.1/32不会被注入到area2中。当然为了让NSSA内的路由器到达AS外部,R3自动下发一条使用7类
LSA描述的缺省路由。R3不会阻挡3类LSA进入NSSA,所以R4依然能够学习到去往其他区域的路由。
另一方面,NSSA允许本区域内的路由器执行路由重发布动作,这一点与Stub区域存在较大的区别。R4 上执行路由重发布动作,将4.4.4.4/32这条外部路由引入OSPF,这条外部路由被引入后是以7类LSA的形式在NSSA内泛洪,并且不允许直接进入骨干区域area0。另一方面,NSSA的ABR R3会把7类LSA转换成5类LSA,然后在骨干区域中泛洪,因此R1、R2都能学习到外部路由4.4.4.4/32。
综上,NSSA的使用场景是:这个区域不希望学习到其他区域重发布进OSPF的域外路由,但是该区域自己依然有注入域外路由的需求或能力。
查看一下R4路由表中的OSPF路由:
| [R4] display ip routing-table protocol ospf | ||||||
|---|---|---|---|---|---|---|
| Destination/Mask | Proto | Pre | Cost | Flags | NextHop | Interface |
| 0.0.0.0/0 | O_NSSA | 150 | 1 | D | 10.1.34.3 | GigabitEthernet0/0/0 |
| 10.1.12.0/24 | OSPF | 10 | 3 | D | 10.1.34.3 | GigabitEthernet0/0/0 |
| 10.1.23.0/24 | OSPF | 10 | 2 | D | 10.1.34.3 | GigabitEthernet0/0/0 |
R4的路由表中,已经看不到1.1.1.1/32这条AS外部路由了,但是R4依然是能够访问1.1.1.1/32的,因为
NSSA的ABR R3为NSSA下发了一条7类的缺省路由,通过这条缺省路由,R4依然能够穿越骨干区域访问AS外部网络。
再看一下R4的LSDB:
| Router | 4.4.4.4 | 4.4.4.4 | 902 | 36 | 80000004 | 1 |
|---|---|---|---|---|---|---|
| Router | 3.3.3.3 | 3.3.3.3 | 901 | 36 | 80000006 | 1 |
| Network | 10.1.34.3 | 3.3.3.3 | 901 | 32 | 80000002 | 0 |
| Sum-Net | 10.1.23.0 | 3.3.3.3 | 1103 | 28 | 80000001 | 1 |
| Sum-Net | 10.1.12.0 | 3.3.3.3 | 1103 | 28 | 80000001 | 2 |
| NSSA | 4.4.4.4 | 4.4.4.4 | 910 | 36 | 80000001 | 1 |
| NSSA | 10.1.34.0 | 4.4.4.4 | 910 | 36 | 80000002 | 1 |
| NSSA | 0.0.0.0 | 3.3.3.3 | 1103 | 36 | 80000001 | 1 |
R4的LSDB中已经没有5类LSA了,其自身重发布进OSPF的直连路由4.4.4.4/32及10.1.34.0/24以7类
LSA的形式被创建。另外,R3还向NSSA中放入一条7类LSA的0.0.0.0/0缺省路由。看一下R3路由表中的OSPF路由:
R3的路由表中,有一条1.1.1.1/32的外部路由,这是通过5类LSA计算得出的。还有一条4.4.4.4/32的外部路由,这是通过7类LSA计算得出的(因此在路由表中的标记为O_NSSA)。当然R3作为NSSA 的
ABR,是不允许把7类LSA直接注入骨干区域的,而是会执行一个7转5的动作,把7类LSA转换成5类LSA, 这是因为7类LSA只能存在于NSSA中。
而R2路由表中的OSPF路由:
有两条AS外部路由,分别是1.1.1.1/32和4.4.4.4/32,其中1.1.1.1/32是由R1引入的,而4.4.4.4/32是经由R3执行7类LSA转5类LSA后引入的。
将area2配置为Totally-NSSA¶
在上面的需求中,area2变成一个非常特殊的区域:NSSA,该区域内泛洪的LSA其实是可以进一步减少的。既然area2已经从R3获取一条缺省路由,通过这条缺省路由能够穿越骨干区域到达AS外部,那么为什么不进一步把描述区域间路由的3类LSA也一并抑制掉呢?这就出现了最后一种特殊区域: Totally-NSSA。
R3的配置修改如下:
[R3] ospf 1
一旦将area2变成Totally-NSSA,area2的ABR——也就是R3将会阻挡3类、4类和5类LSA进入该区域,
同时还会向该区域下发一条使用3类LSA描述缺省路由。当然该区域依然是可以从区域本地注入外部路由的:
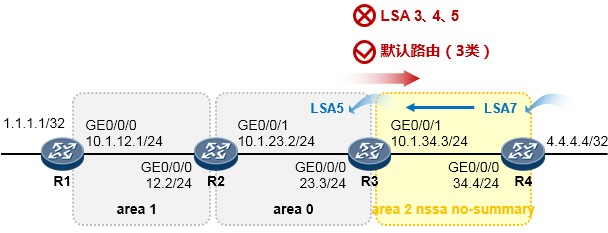
此时R4路由表中的OSPF路由:
| [R4]display ip routing-table protocol ospf | ||||||
|---|---|---|---|---|---|---|
| Destination/Mask | Proto | Pre | Cost | Flags | NextHop | Interface |
| 0.0.0.0/0 | OSPF | 10 | 2 | D | 10.1.34.3 | GigabitEthernet0/0/0 |
R4的路由表已经被最大限度的简化了,此时在路由表中仅有一条缺省路由。这条缺省路由实质上是由
R3下发的,使用3类LSA描述。查看一下R4的LSDB:
在R4的LSDB中,除了一条描述缺省路由的3类LSA,没有其他的3类LSA和4、5类LSA了。
OSPF各种LSA类型及特殊区域小结¶
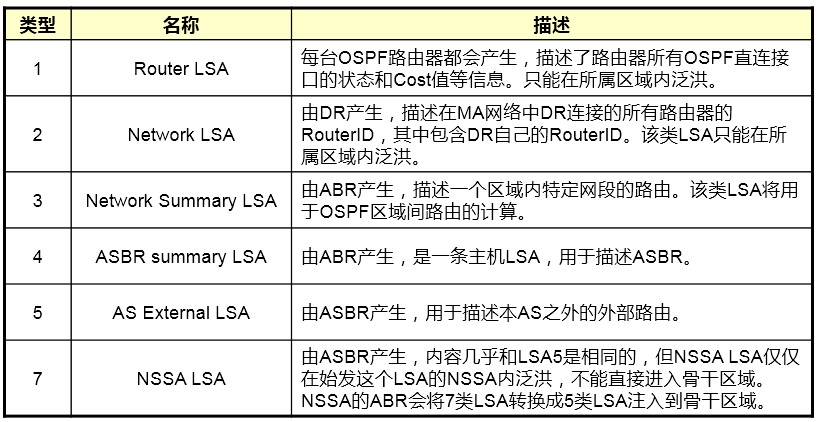

3.5.5 OSPF 高 级
最近有同事在HI 3MS上问了个关于OSPF的问题(OSPF启用filter-policy import后无法收到NSSA路由问题),简单的说,场景如下图所示,R1与R2在Area0中建立了OSPF邻接关系,而R2与R3在Area1中建立了OSPF 邻接关系。Area1被配置为了NSSA,同时R3将外部路由100.1.1.0/24重发布(Import-route)到了OSPF中。 完成配置后,R1应该能学习到OSPF区域间路由23.1.1.0/24,以及外部路由100.1.1.0/24,如下图所示:
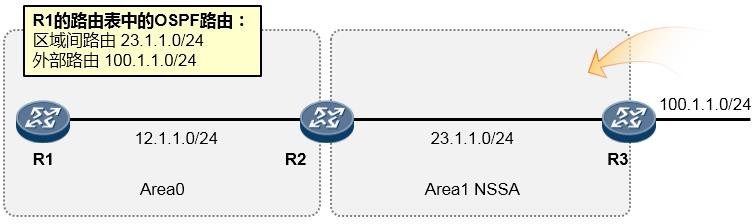
此时如果希望R1的路由表中从OSPF获取到的路由只出现100.1.1.0/24,其他的OSPF路由全部过滤掉,那么R1可以采用如下配置:
这些配置看起来没啥问题,但是执行完成后,你会发现R1的路由表中并没有到达100.1.1.0/24的路由。为什
么配置中明明允许了100.1.1.0/24路由,但是这条路由却被过滤掉了呢?其实这是一个非常基础的OSPF问题。产生这个现象的关键在于OSPF FA(Forwarding Address,转发地址)。简单地说,FA是OSPF Type-
5、Type-7 LSA才会携带的一个字段,主要用于规避次优路径问题。
FA在OSPF外部路由计算过程中的影响¶
都知道OSPF路由器是依据LSA进行路由计算的,而根据Type-5、Type-7 LSA,路由器可计算出到达域外的路由。以Type-5 LSA为例,路由器使用某个Type-5 LSA计算外部路由时,如果发现该LSA所携带的FA为0.0.0.0,那么路由器会将到达发布该LSA的ASBR的下一跳视为到达这个域外网段的下一跳;而如果该LSA所携带的FA为非0.0.0.0,那么路由器会将到达该FA的下一跳视为到达这个域外网段的下一跳。
简单点说,就是如果Type-5 LSA的FA为0.0.0.0,我就从ASBR出去、到达对应的外部网段;如果Type- 5 LSA的FA为非0.0.0.0,我就认为这个FA就是到达外部网段的“出口”。而且,当Type-5 LSA的FA为非0.0.0.0时,OSPF路由器会在其路由表中查询到达FA的路由,仅当它发现路由表中存在到达这个FA 的OSPF内部路由时(OSPF区域内路由或OSPF区域间路由),路由器才会使用这个Type-5 LSA进行外部路由计算,否则将忽略这个LSA。
回到这个例子¶
在上面提到的例子中,R3将外部路由100.1.1.0/24引入OSPF后,它作为ASBR将向Area1中注入Type- 7 LSA,而R2作为ABR,则会将该LSA转换成Type-5 LSA并注入Area0,在执行转换的过程中,缺省时
R2会保留Type-7 LSA的FA,如下图所示。
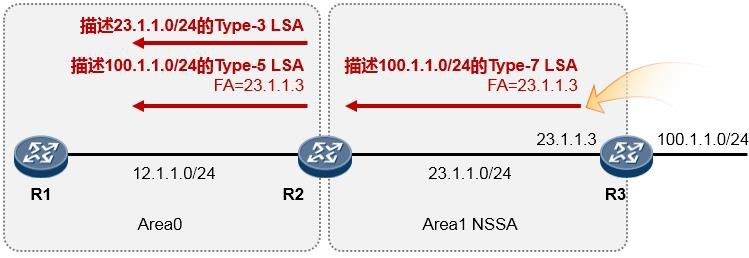
在R1上查看Type-5 LSA可以看到如下输出:
留意到用于描述外部路由100.1.1.0/24的Type-5 LSA的FA为23.1.1.3(R3的接口IP地址),显然这是一
个非0.0.0.0的地址。R1必须在其路由表中发现到达23.1.1.3的OSPF内部路由,才会使用该LSA计算到达100.1.1.0/24的外部路由,否则将忽略该Type-5 LSA。
而R1所配置的入站filter-policy虽然允许了外部路由100.1.1.0/24,但是却将其他所有的OSPF路由全部过滤,其中包括23.1.1.0/24这条区域间路由,因此虽然R1的OSPF LSDB中存在关于100.1.1.0/24的Type-5 LSA,但是它却无法计算出外部路由。这就是问题的根因。
解决这个问题的办法有几个,例如,可以让R2将Type-7 LSA转换成Type-5 LSA时,把FA字段值擦除, 改写为0.0.0.0,R2的配置如下:
这样一来,R1的路由表中便会出现100.1.1.0/24路由,而且只会出现这一条OSPF路由(其他路由都被
过滤了)。R1在使用该Type-5 LSA计算到达100.1.1.0/24的外部路由时,仅需保证自己能够到达ASBR
(产生该Type-5 LSA的ASBR为R2)即可,如下图所示:
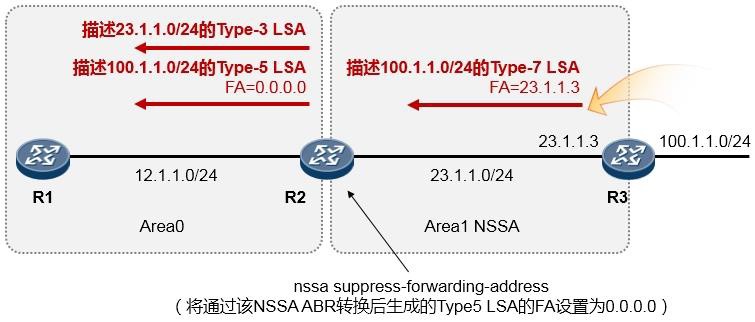
OSPF引入外部路由生成Type-5 LSA或Type-7 LSA时,FA的填写规则是什么¶
Type-5 LSA通过引入外部路由生成。当被引入路由的出接口在OSPF中激活时(注:不能被配置为Silent-
Interface),而且该出接口为Broadcast类型,则FA为被引入路由的下一跳地址;否则取值为0。Type-7 LSA的FA取值不会为0。当被引入路由的出接口在同一个NSSA内激活,而且该出接口为
Broadcast类型,则FA为被引入路由的下一跳地址;否则:
- 如果ASBR在该NSSA内存在loopback接口,则FA的值选取loopback接口的IP地址。
-
如果没有loopback接口,则FA的值选取ASBR在该NSSA内第一个UP的接口的IP地址。
在本例中,R3作为NSSA的ASBR引入了外部路由100.1.1.0/24,它会向Area1中注入Type-7 LSA,并且将该LSA的FA设置为自己在Area1内第一个UP的接口的IP地址——23.1.1.3。
-
交换提高¶
- S5300 交换机堆叠
- 理论部分
堆叠(iStack)/集群(CSS)的技术使得多台物理设备能够协同工作,从而形成逻辑上的一台设备,这项技术将大大简化我们的网络逻辑架构、网络配置和设备管理。例如两台原本独立工作的交换机在部署了堆叠/ 集群技术之后,可以形成逻辑上的一台设备,相当于一台交换机。ATAE3.0/E9000也支持交换板卡的堆叠, 两块交换板卡也可以形成逻辑上的一台交换机。
堆叠技术主要是应用于华为盒式交换机,而集群技术则主要应用于华为框式交换机,两者技术原理不同,但是核心思想是一样的。

如上图所示,SW1及SW2均是S5300-EI交换机,它们均配备了堆叠卡,并使用堆叠线缆进行连接。在完成堆叠系统的组建后,这两台独立的交换机将形成逻辑上的一台设备,你可以简单地将该堆叠系统想象为拥有两个业务板卡的框式交换机。
S5300-EI交换机只支持使用堆叠卡的方式进行堆叠。堆叠卡堆叠的方式必须配套使用ES5D00ETPC00堆叠后插卡和PCIe线缆。需注意的是ES5D00ETPC00堆叠后插卡不支持热插拔,因此安装堆叠卡时,需先将设备下电。堆叠卡的安装如下图所示:

ES5D00ETPC00提供2个12Gbit/s速率的电接口用于设备间堆叠卡堆叠,使用专用的PCIe电缆进行连接,
PCIe电缆的外观如下图所示:

堆叠线缆的链接如下图(以链形链接为例):

使用堆叠卡堆叠时,可以连一条堆叠线,也可以连两条(当然,建议连接两根线缆),总之是设备A的Stack1 接口连设备B的Stack2接口,设备A的Stack2接口连设备B的Stack1接口,也就是交叉连线。
- 配置指导
此处以两台S5300-EI交换机(SW1及SW2)部署堆叠为例,讲述堆叠的步骤:
SW1及SW2先下电,安装“ES5D00ETPC00堆叠后插卡”,然后将设备上电。¶
ES5D00ETPC00堆叠后插卡不支持热插拔,如果设备处于上电状态,安装前需要先将设备下电。堆叠卡安装完成之后,才能进行相关配置。
设备启动后,使能堆叠功能并配置成员交换机的堆叠ID和优先级。¶
SW1的配置如下:
SW2的配置如下:
说明:多台物理交换机可以通过部署堆叠技术并形成逻辑上的一台交换机,我们将这些物理交换机称为堆叠成员交换机。堆叠ID也被称为成员交换机的槽位号(Slot ID),用来标识和管理成员交换机,堆叠中所有成员交换机的堆叠ID都是唯一的。当堆叠系统建立起来之后,堆叠ID还用于体现成员交换机对应的“槽位号”(在交换机堆叠之前,每台设备都是独立的个体,堆叠之后,每台设备就相当于堆叠系统的一个槽位)。
缺省情况下堆叠ID为0,当然可以通过命令stack slot 0 renumber来修改这个值,修改之后,必须重启交换机,新的堆叠ID才会生效。如果参与堆叠的交换机的堆叠ID都为0,那么在堆叠系统建立时,由
Master交换机来分配堆叠ID,以确保堆叠ID的唯一性。
堆叠优先级是成员交换机的一个堆叠属性,主要用于角色选举过程中确定成员交换机的角色,优先级值越大表示优先级越高,优先级越高当选为主交换机的可能性越大。
堆叠系统建立完成后,如果某台交换机的堆叠ID为1,那么堆叠之前该设备的接口如果编号为GE0/0/1,则堆叠后变为GE1/0/1(三个数字中的第一个数字为堆叠ID)。
将SW1及SW2下电,使用PCIe线缆按照规范连接堆叠端口,然后将设备上电(先上电SW1,再上电SW2)。¶
设备完成启动后,堆叠系统将会建立起来,可以使用相关命令查看堆叠系统。¶
此时登录一台成员交换机即可管理整个堆叠系统。
堆叠系统建立完成后,配置MAD。¶
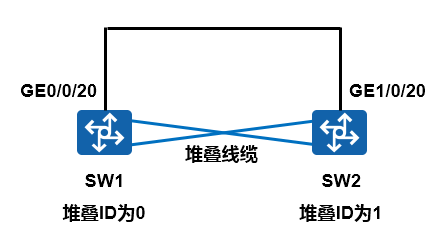
两台交换机组建堆叠系统后,它们便形成逻辑上的一个整体,如果堆叠线缆全部发生故障,那么堆叠系统将会分裂,这两台成员交换机变成两个独立的个体,而且它们的配置还是相同的,此时就会发生各种问题,例如IP地址冲突问题等。多主检测MAD(Multi-Active Detection),是一种检测和处理堆叠分裂的协议,用于解决上述问题。
在上图中,SW1及SW2完成堆叠系统的组建后,在交换机之间增加一条连线(普通的以太网线或光纤),将堆叠组中的SW1的GE0/0/20接口与SW2的GE1/0/20接口互联(此时SW2的新堆叠ID已经生效),这条线缆将被配置为MAD线缆(它并不会承载任何业务流量,因此不存在环路),当堆叠系统分裂时, 两台交换机通过该条线缆交互协商报文,协商完成后,其中一台交换机会由于竞争失败自动将所有业务接口关闭,从而规避堆叠分裂后的IP地址冲突等问题。
MAD配置如下:
完成配置后,检查一下:
注意事项:¶
- 堆叠系统组建完成后,务必使用display stack命令确认堆叠系统的状态。
- 堆叠系统组建完成后,所有的成员交换机在逻辑上就是一个整体,因此在做网络规划时,需注意此时整个堆叠系统就是“一台大交换机”。
- S6300 交换机堆叠
- 理论部分
堆叠方式及线缆¶
S63全系列交换机支持堆叠特性。S63交换机系列不需要额外配置堆叠卡,可以使用前面板上任意的
10GE业务口堆叠,堆叠连接有两种方式:
- 光纤连接,支持长距40km堆叠。
- 专用堆叠线缆连接,堆叠线缆有如下三种类型:
- S6300,LS6MCAS01,SFP+ 堆叠线缆(100cm,含有两个堆叠模块)。
- S6300,LS6MCAS03,SFP+ 堆叠线缆(300cm,含有两个堆叠模块)。
- S6300,LS6MCAS10,SFP+ 堆叠线缆(1000cm,含有两个堆叠模块)。
- 专用堆叠线缆连接,堆叠线缆有如下三种类型:
以LS6MCAS01专用堆叠线缆:SFP+Stacking Cable(100cm, 含两个堆叠光模块)为例,外观如下(线缆两头各自带一个光模块,图为线缆一端):

Stack-Port及堆叠成员端口¶
堆叠端口(Stack-Port)是专用于堆叠的逻辑端口,需要和堆叠成员端口(物理端口)绑定。堆叠系统的每台成员交换机上支持两个Stack-Port,分别为Stack-Port n/1和Stack-Port n/2,其中n为成员交换机的堆叠ID。
堆叠成员端口指的是设备上用于堆叠连接的物理端口。堆叠成员端口用于转发需要跨成员交换机的业务报文或成员交换机之间的堆叠协议报文,如下图所示。
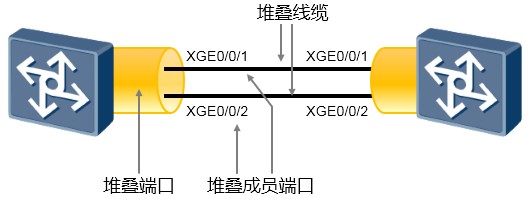
堆叠系统对堆叠端口的配置是有要求的。我们已经知道堆叠端口是一个逻辑口,一个设备上支持两个Stack-Port,配置堆叠时,要求本设备的Stack-Port n/1只能和邻居设备的Stack-Port n/2相连,而本设备的Stack-Port n/2只能与邻居设备的Stack-Port n/1相连(注:ATAE交换板在进行堆叠时,则没有这个限制)。如下图所示,S6300-1的XGE0/0/1及XGE0/0/2接口使用堆叠线缆与S6300-2的XGE0/0/1及
XGE0/0/2互联,现在两台交换机要建立堆叠系统。我们在S6300-1上将XGE0/0/1及XGE0/0/2这两个堆叠成员端口添加到堆叠端口Stack-Port 0/1中(假设S6300-1的堆叠ID为0),那么在S6300-2上进行配置时,就要将其XGE0/0/1及XGE0/0/2这两个堆叠成员端口添加到堆叠端口Stack-Port ½中(假设S6300-2的堆叠ID为1)。
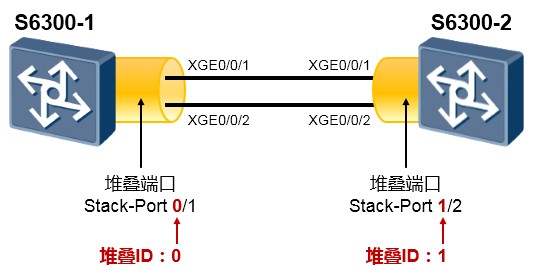
堆叠注意事项¶
S6300系列设备使用前面板上任意10GE业务口做堆叠口,由于设备芯片结构的原因,前面板上的10GE 口,从端口1开始,每4个口为一组(如下图所示),一组中的4个口必须都是堆叠口或者都是业务口, 因此,只要一组中的其中一个被配置为堆叠口,其他的都不能作为业务口使用。还需要再强调一下,一旦接口被配置为堆叠成员端口,那么该接口将不能作为普通业务口使用。

- 配置指导
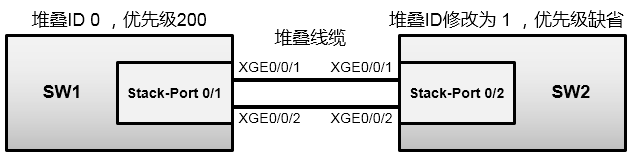
在上图所示的拓扑中,两台S6300交换机进行堆叠。SW1的XGE0/0/1口通过堆叠线与SW2的XGE0/0/1口互联,另外SW1的XGE0/0/2口通过堆叠线与SW2的XGE0/0/2口互联。也就是说,交换机之前采用两条堆叠线缆进行堆叠。
一个推荐的堆叠流程是,先规划设备的堆叠ID并明确哪一台是主设备,接着配置设备的堆叠ID以及堆叠优先级,再配置Stack-Port,完成上述配置后保存,然后将设备下电、连线、再上电,最后完成堆叠。
设备配置(设备的Stack-Port、堆叠ID以及堆叠优先级)¶
SW1(V200R002之后的版本)的配置如下:
\<SW1> save
SW2的配置如下:
SW1及SW2下电,连接堆叠线缆。¶
将SW1及SW2上电(先将SW1上电,再将SW2上电)。¶
完成堆叠后,查看一下堆叠系统:
MAD配置¶
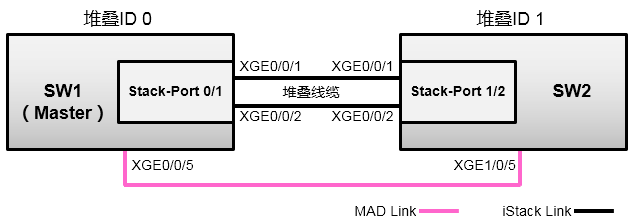
在上图SW1及SW2进行堆叠,双方的XGE0/0/1及XGE0/0/2是堆叠成员端口。当交换机完成堆叠配置并且建立堆叠系统后,SW1及SW2的配置是相同的,此时它们是一个整体。该堆叠系统采用两条堆叠线缆,如果其中一条发生故障,堆叠系统不会分裂,但是一旦所有的堆叠线全部发生故障,则SW1及SW2 会拆分成两个独立的“堆叠系统”,此时它们的配置是完全相同的,如果这台交换机依然保持在现网中, 则会发生IP地址冲突等一系列问题。
多主检测MAD(Multi-Active Detection),是一种检测和处理堆叠分裂的协议。链路故障导致堆叠系统分裂后,MAD可以实现堆叠分裂的检测、冲突处理和故障恢复,降低堆叠分裂对业务的影响。在上图中,SW1及SW2在堆叠系统组建完成后,增加一条互联线缆(SW1的XGE0/0/5及SW2的XGE1/0/5互联,注意此时堆叠系统已经建立,SW2的堆叠ID被修改为1),该条线缆没有特殊要求,可以是普通的网线或光纤,但是用于MAD的接口必须是普通业务口,不能是堆叠成员端口。
随后在SW1及SW2完成以下配置,将该互联接口指定为MAD接口,如此一来,当SW1及SW2之间的堆叠线缆全部故障时,SW1及SW2能够通过MAD链路进行协商,并且将其中一台交换机的所有业务端口关闭,从而规避以上提及的冲突问题。
MAD配置如下:
完成配置后,检查一下:
注意事项:¶
- 堆叠端口的配置不保存到配置文件中,使用display current-configuration命令是无法查看到堆叠的相关配置的。配置完成后,可以使用display device、display stack及display stack port等命令查看堆叠的相关信息。
- 在S6300交换机上,由于芯片原因,每4个10GE接口为一组,每组接口要么都是业务口,要么都是堆叠成员口。S6300支持面板上任意10GE接口作为堆叠成员口使用,在配置堆叠时,要注意同一个组内的接口都需工作在10GE模式,如果有同组的其他闲置接口安装了光转电的模块(使得该接口的工作速率在GE),则即使该接口未被使用(甚至没有连线),也可能导致同组中的其他接口由于模式问题无法被配置成堆叠成员口。
- Traffic-policy 流量统计
场景说明¶
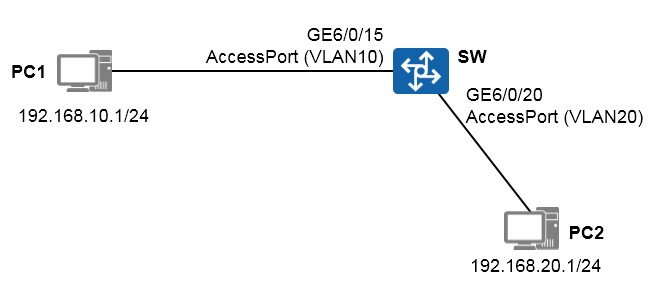
- PC1、PC2分别属于VLAN10及VLAN20。PC1及PC2的缺省网关都设置成SW(相应Vlanif的IP地址)。缺省时PC1与PC2可相互通信。
- 在SW上完成配置,对PC2 ping PC1的过程中所穿越SW的报文进行统计。
配置指导¶
SW(此处以S9300交换机V2R3版本为例)的配置如下:
完成上述配置后,当PC2 ping PC1时,所产生的ICMP流量会被SW进行记录:
[SW] display traffic policy statistics interface GigabitEthernet 6/0/20 inbound
| Interface: GigabitEthernet6/0/20 Traffic policy inbound: p1 Rule number: 1 Current status: OK! --------------------------------------------------------------------- Board : 6 Item Packets Bytes --------------------------------------------------------------------- | ||
|---|---|---|
| Matched | 5 | 510 |
| +--Passed | 5 | 510 |
| +--Dropped | 0 | 0 |
| +--Filter | 0 | 0 |
| +--CAR | 0 | 0 |
要复位上述统计结果,可以执行reset traffic policy statistics interface GigabitEthernet 6/0/20 inbound
命令。完成流量统计操作后,需将接口上配置的traffic-policy删除。
- VLAN 映射
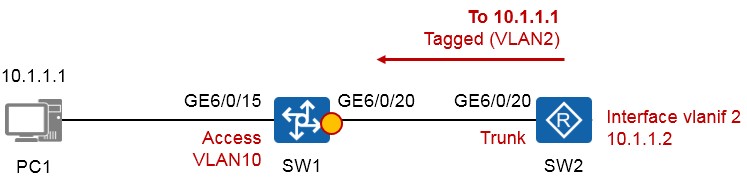
如图所示,SW1连接着一些PC,这些PC都属于VLAN10,使用10.1.1.0/24网段的IP地址。另一方面,SW1 也通过GE6/0/20接口连接着SW2,SW2连接着VLAN2,并且该VLAN使用的IP地址也是10.1.1.0/24网段(单个IP 地址与SW1 上接入的主机不存在冲突) 。现在要在SW1 上部署VLAN Mapping ( 也叫做VLAN
Translation),使得SW2及其下联的VLAN2(中的设备)能够直接与PC1进行二层通信。此时网络的逻辑结构类似如下:

SW1(以S9300 V2R1版本为例)的配置如下:
上述配置中,**port vlan-mapping vlan 2 map-vlan 10**命令使得该接口收到携带了VLAN2 Tag的数据帧时,
将该帧的Tag修改为VLAN10,然后进入交换机。数据帧进入交换机后,交换机将其识别为VLAN10的数据帧,因此在SW1的GE6/0/20接口上,必须放通VLAN10。
完成上述配置后:

SW2即可ping通PC1,而反过来,PC1也可主动访问SW2(10.1.1.2)。可以看出,**port vlan-mapping vlan 2 map-vlan 10**这条命令实现了双向的转换。VLAN Mapping发生在报文从入端口接收进来之后,以及从出端口转发出去之前。强调一下:配置VLAN Mapping功能的接口类型必须为Trunk或Hybrid,接口必须加入
(或者说放通)映射后的map-vlan。
路由提高¶
5.1 路由重发布
5.1.1 技术背景
在同一个网络拓扑结构中,如果存在两种不同的路由协议,由于不同的路由协议的工作机制各有不同,对路由的理解也不相同,这就在网络中造成了路由信息的隔离,然而由于这很有可能是同一个自治系统内的网
络,全网需要互通,这时候咋办?例如一个网络包含两个片区,每个片区使用自己的动态路由协议,如果要实现两个片区的网络互通,就需要在两者之间打通路由,但是这两种动态路由协议毕竟是不同的协议,路由信息是完全隔离的,如何实现交互?这就需要使用路由重发布(也被称为路由引入,route-importation)了。
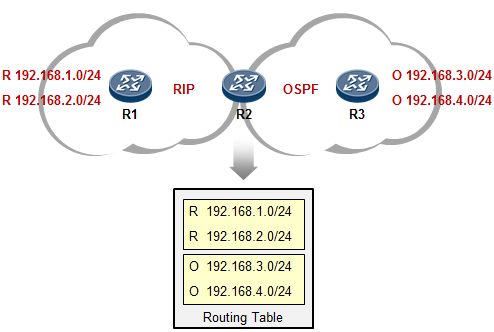
我们看上图,R1与R2之间,运行RIP(路由协议)来交互路由信息,R2通过RIP学习到了R1通告的
192.168.1.0/24及2.0/24的路由。同时R2与R3又建立了OSPF邻接关系,因此R2也从R3那通过OSPF学习到了两条路由:3.0及4.0/24,也装载进了路由表。那么对于R2而言,它自己就有了去往全网的路由,但是R2 不会将从RIP学习过来的路由告诉R3,也不会将从OSPF学习来的路由告诉R1。对于R2而言,虽然它自己的路由表里有完整的路由信息,但是,就好像冥冥之中,R和O的条目之间有道鸿沟,无法逾越。而R2就也就成了RIP及OSPF域的分界点。那么如何能够让R1学习到来自OSPF的路由、让R3学习到来自RIP的路由呢?关键点在于R2上,通过在R2上部署路由重发布,可以实现路由信息在不同路由选择域间的传递。
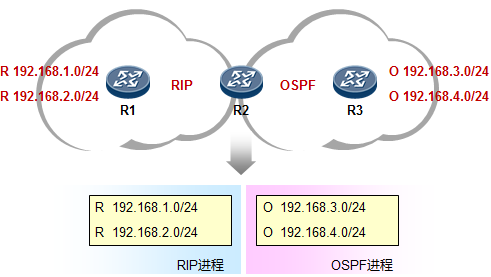
上图是初始状态。R2分别从RIP及OSPF都学习到了相应的路由。但是在默认情况下,通过这两个路由协议所学习到的路由是互相隔离的,R2不会自动的将OSPF路由“翻译”成RIP,反之亦然。那么此时,R1自然是无法访问到R3这一侧的网络的,R3也是一样。
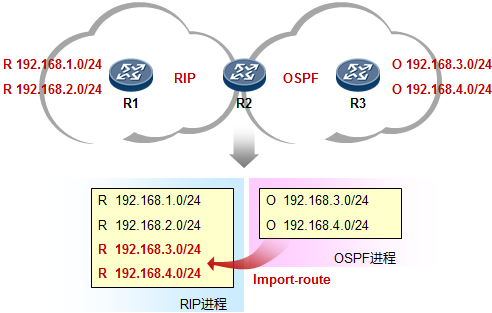
上图中,我们开始在R2上执行重发布的动作,我们将OSPF的路由“注入”了RIP进程之中,如此一来,R2 就会将3.0/24及4.0/24这两条OSPF路由“翻译”成RIP,然后传递给R1,R1也就能够学习到3.0和4.0路由了。注意重发布的执行地点,是在R2上,也就是在路由域的分界点上执行,另外,路由重发布是有方向的, 我们执行完上述相关动作后,R3仍然是没有RIP域内的那些路由的,需进一步在R2上,将RIP路由重发布进
OSPF,才能让R3学习到1.0/24及2.0/24路由。
- 实施要点
部署路由重发布的过程需要谨慎,尤其在一些复杂的网络环境中部署重发布时,更加应该考虑周祥。下面针对执行重发布的过程中需要关注的几个问题进行介绍。
路由优先级问题¶
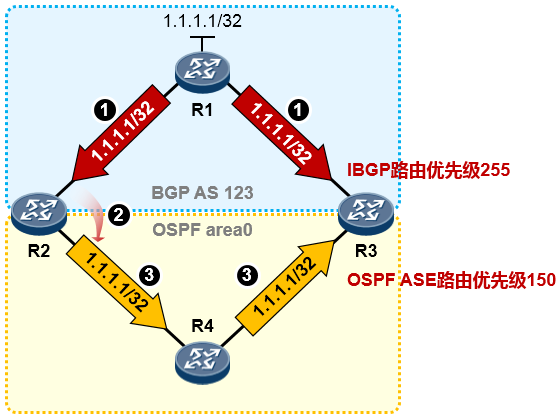
路由优先级问题,是在部署重发布过程中需要关注的问题之一,尤其是在双点双向路由重发布的场景中,这种场景中两个ASBR(AS边界路由器)上会同时部署双向的路由重发布,这是一个非常值得关注的模型。
在上图所示的网络环境中,存在两个路由域:BGP及OSPF。R1上有一条直连路由1.1.1.1/32被network 进BGP并传递给了R2及R3,那么此刻R2及R3的路由表中是有到达1.1.1.1/32的IBGP路由的。
接下去R2部署了IBGP到OSPF的路由重发布,1.1.1./32的路由被引入了OSPF,形成外部路由条目并传递给了R3。现在R3同时从OSPF及IBGP学习到1.1.1./32路由,OSPF外部路由的优先级是150,而IBGP 路由优先级为255,因此OSPF的外部路由要优于IBGP路由,如此一来R3会把OSPF路由1.1.1.1/32装载进路由表,该路由的下一跳为R4,这时R3就出现了“次优路径问题”,其访问1.1.1.1/32的流量走向是R4-R2-R1——绕了远路了。
造成这个现象的原因是路由协议的优先级在这里影响了R3的路由优选,为了规避这个现象,我们可以在R3上使用相关命令来调节1.1.1.1/32路由的优先级,使得R3优选来自IBGP的路由。
路由倒灌¶
还是上面的环境,刚才我们已经分析过了,如果不做任何干预,R3是会存在次优路径问题的,因为R3 会优选到达1.1.1.1/32的OSPF路由,而不是IBGP路由。而如果R3又部署了OSPF到BGP的路由重发布, 那么1.1.1.1/32路由又会被R3给倒灌回BGP,这就存在一个引发路由环路的隐患。
规避方法在上一个小节中已经探讨了一些。因此,双点双向重发布在部署起来的时候,需要格外小心。
- 路由重发布的配置
不同协议之间的路由重发布的配置大同小异,我们先看一下从其他路由协议注入路由到OSPF的配置:
在一台设备上,将其路由表中通过A路由协议学习到的路由重发布到B路由协议中,是在该设备的B路由协议的配置视图下完成相关配置的。
OSPF与RIP的互重发布¶
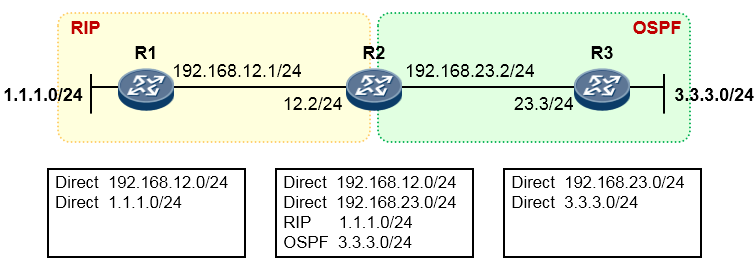
在上图中,R1与R2运行着RIP,R2与R3则建立了OSPF邻接关系,我们最终要实现的目标是让全网能够互通。首先R2已经通过OSPF及RIP学习到了1.1.1.0/24及3.3.3.0/24路由,它已经同时拥有了OSPF及RIP路由域内的路由。但是默认情况下,它是不会将OSPF路由注入RIP域的,反之亦然。那么现在我们就要在R2上做路由重发布了。
首先是将OSPF路由注入RIP:
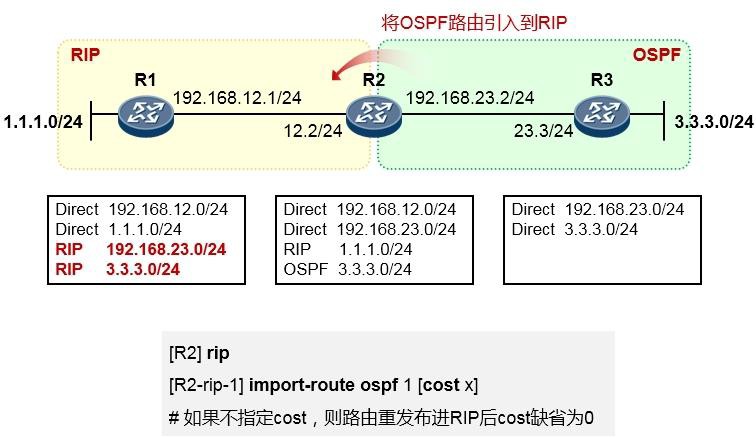
注意,上面只是给出了关键配置。完成这一步动作之后,R1的路由表就发生了变化,由于R2部署了从OSPF 到RIP的路由重发布,因此它会将其路由表中的所有OSPF路由(3.3.3.0/24)以及本地直连的OSPF接口路由(192.168.23.0/24)都注入RIP,从而R1便能够通过RIP学习到192.168.23.0/24及3.3.3.0/24路由。
接着是将RIP路由注入到OSPF:
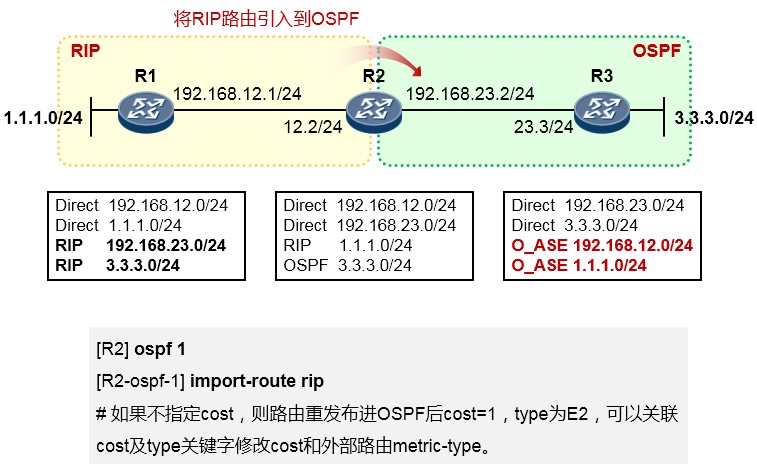
完成上述配置后,R3即可学习到RIP域中的路由192.168.12.0/24以及1.1.1.0/24。如此一来,全网的路由就互通了。因此要注意,将路由协议A注入到路由协议B,是在路由协议B的配置视图中完成相应的import-route 配置。并且,路由重发布是单向的。
重发布直连路由到OSPF¶

常规情况下,要将一条直连路由通告给路由域,就必须network相应的直连接口。如果没有使用network命令在路由进程中激活相应的接口,则对于该路由域而言,这个接口所关联的网段就是外部网络。
另一种将到达直连网络的路由引入路由域的方式是使用路由重发布的方式,将直连路由注入,例如上图中
R3的初始配置如下:
它并没有配置**network 33.33.33.0 0.0.0.255**,那么R1、R2是无法从OSPF学习到33.33.33.0/24路由的,因
为R3的Loopback1接口并未激活OSPF。我们可以使用如下方式来将直连路由注入OSPF(下面只是粘贴了关键配置,省略了其他配置):
在OSPF配置视图中使用**Import-route direct**命令,会将路由器上所有的直连接口路由都注入OSPF。因此
当R3执行上述命令时,其路由表中的直连路由192.168.23.0/24以及33.33.33.0/24都会被注入OSPF——以外部路由的形式。当然,如果此时Loopback1接口失效,那么该接口的直连路由重发布也就会被撤销。
重发布静态路由到OSPF¶
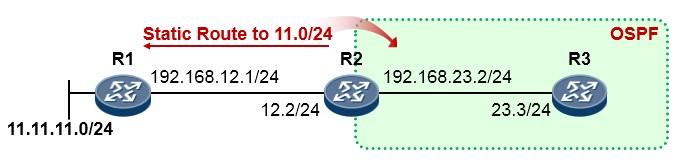
在上图中,R1直连着网络11.11.11.0/24,R1不支持动态路由协议,R2配置了去往11.11.11.0/24的静态路由,且下一跳为R1。R2与R3建立OSPF邻接关系。现在对于整个OSPF域而言,它们是感知不到11.11.11.0/24 网段的存在的,因为对于OSPF而言,R2所配置的静态路由是一条域外的路由。为了让OSPF内的路由器能够通过OSPF学习到11.11.11.0/24路由,我们需要在R2上部署路由重发布,将静态路由重发布到OSPF:
在OSPF配置视图下使用**import-route static**命令后,R2会将其路由表中所有的静态路由都会重发布到
OSPF。如此一来,R3便能够通过OSPF学习到11.11.11.0/24路由。
- 路由策略
- Route-policy
概述¶

如上图所示,我们要在R2上部署RIP到OSPF的重发布,经过前面的学习,大家已经能够很轻松地给出配置, 在执行重发布的命令中,可以关联**cost**关键字来指定路由注入ospf之后的cost。但是这是针对所有被注入的路由的。另外**import-route rip**命令会将R2路由表中的RIP路由全都注入OSPF。
如果希望只注入特定的路由,或在注入过程中过滤掉某些路由呢?或者针对不同的路由在注入后设置不同的OSPF cost呢?这个时候就可以使用到route-policy了。

Route-policy是一个非常重要的基础性策略工具。你可以把它想象成一个拥有多个节点(node)的列表(这些node按编号大小进行排序)。在每个节点中,可以定义条件语句及执行语句,这就有点像程序设计里的if-then语句,如上图所示。
route-policy执行的时候,是自上而下进行计算的。首先看节点1(这里假设编号最小的节点为1),对节点1 中的“条件语句”进行计算,如果所有的条件都满足,则执行该节点下的“执行语句”,并且不会再继续往下一个节点进行匹配了。而如果节点1中,有任何一个条件不满足,则继续看下一个节点,到节点2中去匹配条件语句,如果全都满足则执行该节点中定义的执行语句,如果不满足,则继续往下一个节点进行,以此类推。下图就是一个route-policy:
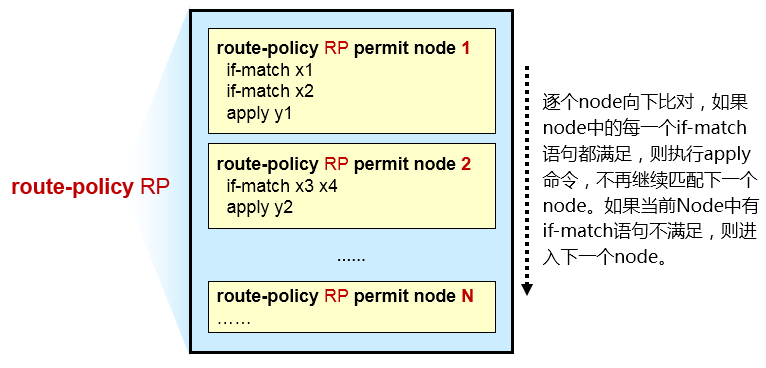
Route-policy的配置¶
创建route-policy¶
[Huawei] route-policy name { permit | deny } node node
-
**Permit**关键字指定节点的匹配模式为允许。当该节点下所有的条件都被满足时,将执行该节点的
apply子句,不进入下一个节点;如果有任何一个条件不满足,将进入下一个节点继续计算。
- **Deny**关键字指定节点的匹配模式为拒绝,这时apply子句不会被执行。当该节点下所有的条件都被满足时,将被拒绝通过该节点,不进入下一个节点;如果有任何一个条件不满足,将进入下一个节点继续计算。
- 默认情况下,所有未匹配的路由将被拒绝通过route-policy。如果Route-Policy中定义了一个以上的节点,则各节点中至少应该有一个节点的匹配模式是permit。
配置If-match子句¶
[Huawei-route-policy] if-match ?
-
对于同一个route-policy节点,命令**if-match acl**和命令**if-match ip-prefix**不能同时配置,后配置的
命令会覆盖先配置的命令。
-
对于同一个Route-Policy节点,在匹配的过程中,各个if-match子句间是“与”的关系,即路由信息必须同时满足所有匹配条件,才可以执行apply子句的动作。但命令**if-match route-type**和**if-match**
**interface**除外,这两个命令的各自if-match子句间是“或”的关系,与其它命令的if-match子句间仍是“与”的关系。
-
如不指定if-match子句,则所有路由信息都会通过该节点的过滤。
-
配置apply子句¶
Route-policy配置示例¶
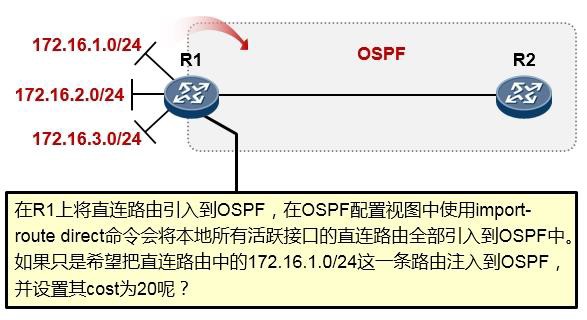
R1的配置如下:¶
由于route-policy在末尾隐含“拒绝所有”的节点,因此172.16.2.0/24及172.16.3.0/24路由因为没有满足任
何节点的if-match语句,从而不被注入到OSPF中。
5.2.2 IP-Prefix
技术背景¶
在部署路由策略的过程中,我们往往需要通过一些手段“抓取”路由,从而能够针对特定的路由来执行相应的策略,以实现差异化。在“抓取”路由的工具中,ACL无疑是最常用的工具之一。
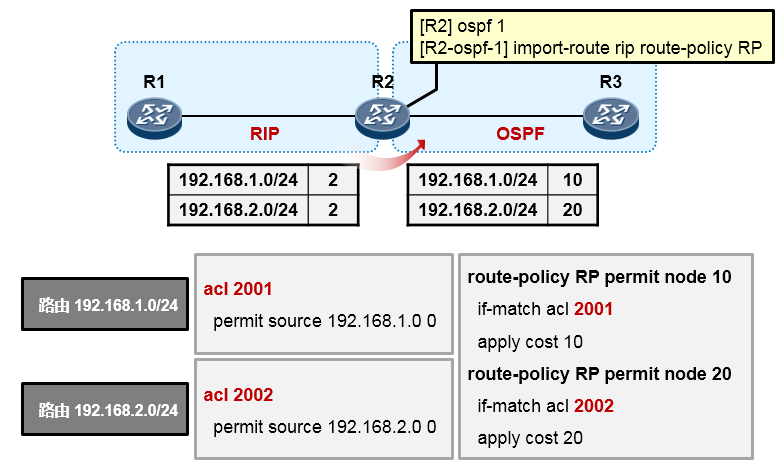
在上图中,R2部署了RIP到OSPF的路由重发布,在这个场景中,我们有个特殊需求:将引入OSPF后的外部路由192.168.1.0/24的cost设定为10、192.168.2.0/24的cost设定为20,那么我们便要先匹配或者说“抓取”相关路由,然后针对不同的路由在route-policy中apply不同的cost,从而实现策略。
使用ACL来应对这个需求是完全没问题的,定义一个ACL2001,匹配192.168.1.0,定义一个ACL2002 匹配192.168.2.0,然后在route-policy RP中写两个node分别针对这两条路由apply不同的cost值,很简单。但是……

上面这个环境,ACL就无能为力了。为什么呢?因为ACL只能够匹配路由前缀的网络地址部分,无法匹配路由前缀的网络掩码(或者说前缀长度)。准确的说,一条路由前缀是包含网络地址和网络掩码(前缀长度)的,对于192.168.1.0,这算不上一条完整的路由,应该采用192.168.1.0 255.255.255.0或者
192.168.1.0/24的方式呈现,这才是一条完整路由。而只要网络地址或者网络掩码中有任何一项不同, 这就是两条不同的路由了,例如192.168.1.0/24和192.168.1.0/25,这就是两条不同的路由。
ACL是无法匹配路由前缀的掩码部分的,因此上图所示的需求用ACL是无法完成的。这里顺便多嘴一句, 如果使用Basic ACL匹配路由,那么建议在书写ACL时,反掩码使用0.0.0.0,否则会造成匹配不精确的现象。例如要匹配192.168.1.0/24这条路由,如果acl的rule这么写:
rule permit source 192.168.1.0 0.0.0.255 这事实上是不严谨的,因为它将192.168.1.0、192.168.1.1、192.168.1.2、192.168.1.3…………等众多 网络地址全匹配住了。也就是说,上面的0.0.0.255,并不能用于匹配网络掩码255.255.255.0,它只不过是与前面的192.168.1.0组合,并用于匹配网络地址而已。所以,建议这么写:
rule permit source 192.168.1.0 0.0.0.0
或者:
rule permit source 192.168.1.0 0
IP-Prefix(IP前缀列表)¶
- IP前缀列表匹配路由的可控性比ACL高得多,也更为灵活;
- IP前缀列表可匹配路由前缀中的网络地址及网络掩码(前缀长度),增强了匹配的精确度;
- IP前缀列表除了能够匹配具体的网络掩码长度,还能够匹配掩码长度范围,非常灵活。
-
一个IP前缀列表可以包含一个或多个表项(语句),在匹配过程中依序进行计算。表项中的索引号
(序号)决定了每个表项在整个IP前缀列表中的位置。
IP前缀列表的配置¶
创建一个IP前缀列表的配置如下:
- *Name*参数是本IP前缀列表的名称。
- **Index**关键字及参数指示本表项在本IP前缀列表中的序号(或索引号),该关键字及参数是可选的。缺省情况下,该序号值按照配置先后顺序依次递增,每次加10,第一个序号值为10。
- **Permit**及**deny**关键字用于配置本表项的匹配模式。
- *ip-address mask-length*参数用于分别制定IP地址及掩码长度。
-
[ greater-equal greater-equal-value ] [ less-equal less-equal-value ]是可选配置,用于指定掩码长度的范围。
如果在命令中只指定了**greater-equal**,则前缀范围为[greater-equal-value,32];
如果在命令中只指定了**less-equal**,则前缀范围为[mask-length,less-equal-value]。
IP前缀列表由列表名称进行标识,每个IP前缀列表可以包含多个表项。下面的配置展示了一个名为abcd, 它包含两个表项:
在IP前缀列表的匹配过程中,设备按索引号升序依次检查各个表项,只要有一个表项满足条件,就不再
去匹配后续表项。
以**ip ip-prefix abcd index 10 deny 1.0.0.0 8**为例,这个表项属于IP前缀列表abcd,它的索引号为10, 并且匹配模式为拒绝,在该表项中IP前缀为1.0.0.0,掩码长度为8,因此这个表项用于匹配路由1.0.0.0/8, 只有该路由才会被匹配,并且该路由将会被该表项过滤(deny)。这个命令中没有定义掩码长度范围。
如果一条路由无法被一个IP前缀列表中的所有表项匹配,那么这条路由被视为被该前缀列表拒绝通过。也就是说,一个IP前缀列表的末尾,隐含着一条拒绝所有的表项。
4 配置示例¶
-
示例1:
匹配某条特定路由192.168.1.0/24:
ip ip-prefix ipprefix1 192.168.1.0 24
匹配默认路由0.0.0.0/0:
ip ip-prefix ipprefix2 permit 0.0.0.0 0 注意:IP前缀为0.0.0.0时表示通配地址。此时不论掩码指定为多少,都表示掩码长度范围内的所有 路由全被匹配。
匹配所有/32主机路由:
ip ip-prefix ipprefix3 permit 0.0.0.0 0 greater-equal 32
匹配任意路由(any):
ip ip-prefix ipprefix4 permit 0.0.0.0 0 less-equal 32
-
示例2:
匹配以下路由(用最精确最简洁的方式):
192.168.4.0/24
192.168.5.0/24
192.168.6.0/24
192.168.7.0/24
ip ip-prefix abcd permit 192.168.4.0 22 greater-equal 24 less-equal 24 上面这条命令的意思是,允许那些网络地址的前22bit与192.168.4.0的前22bit相同,并且网络掩码 长度为24的路由。注意此处“greater-equal 24 less-equal 24”要求网络掩码长度既大于或等于24,又小于或等于24,因此只能是24。
- 示例3:

在以上配置中,我们首先创建了一个名称为1的IP前缀列表,该列表中包含一个表项,这个表项要求被匹配路由的网络地址的前16bit与192.168.0.0的前16bit相同,并且路由的网络掩码长度为16, 因此该表项只能用于匹配路由192.168.0.0/16。由于该表项的匹配模式为permit , 因此路由
192.168.0.0/16被该IP前缀列表允许。
随后我们定义了一个route-policy RP,它包含一个节点,且该节点的匹配模式为permit。该节点调用了IP前缀列表1,如此一来,192.168.0.0/16将被route-policy RP所允许,而由于route-policy的末尾隐含着一个拒绝所有的节点,因此对于route-policy RP而言,只允许了路由192.168.0.0/16。
- BGP
- BGP 基本概念
BGP概述¶
IGP也即内部网关路由协议,典型代表有OSPF、IS-IS等。IGP工作的“着眼点”在AS(自治系统)内部, 它的主要职责就是负责AS内的路由发现和快速收敛,而且其承载的路由前缀就是本AS内的前缀。
这里先介绍一下AS的概念,AS(Autonomous system,自治系统)指的是在同一个组织或机构管理下、使用相同策略的设备的集合。我们可以简单的将AS理解为一个独立的机构或者企业——例如中国联通——所管理的网络。另一个AS的例子是一家大型企业的网络,在网络的规划上将全球各个区域划分为一个个AS: 中国区是一个AS,南美区是一个AS以此类推。
不同的AS通过AS号区分,AS号取值范围1-65535,其中64512-65535是私有AS号,在私有网络可随意使用。IANA负责AS号的分发,如果要使用公有AS号,则需要向IANA申请。
BGP(Border Gateway Protocol,边界网关协议),是一种距离矢量路由协议,严格的说应该叫路径矢量路由协议,主要用于在AS之间传递路由信息,适用于大规模的网络环境,Internet的骨干网络正是得益于BGP才能承载如此大批量的路由前缀。总的来说,无论是内部网关路由协议,或者外部网关路由协议,最终的目的都是为了实现路由的互通,从而最终实现数据的互通。
BGP的协议特征¶
- BGP在传输层使用TCP以确保可靠传输,所使用的TCP目的端口号为179;
- BGP会在需要交换路由的路由器之间建立TCP连接,这些路由器被称为BGP对等体,也叫BGP邻居。有两种BGP邻居关系:EBGP邻居关系,以及IBGP邻居关系。
- BGP的邻居关系可以跨路由器建立,而不像OSPF及RIP那样,必须要求直连。
- BGP对等体在邻居关系建立时交换整个BGP路由表。
- 在邻居关系建立完成后,BGP路由器只发送增量更新或触发更新(不会周期性更新)。
- BGP具有丰富的路径属性和强大的策略工具。
- BGP能够承载大批量的路由前缀,用于大规模的网络中。
BGP报文¶
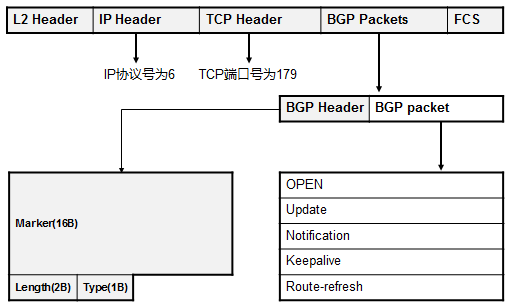
BGP报文是被承载在TCP报文之上的,使用端口号179。共有五种报文:
| 报文名称 | 作用是什么 | 什么时候发包 |
|---|---|---|
| OPEN | 协商BGP邻居的各项参数,建立邻 居关系 | 通过TCP建立BGP连接,发送open报文 |
| UPDATE | 进行路由信息的交换 | 连接建立后,有路由需要发送或路由变化时,发送 UPDATE通告对端路由信息 |
| NOTIFICATION | 报告错误,中止邻居关系 | 当BGP在运行中发现错误时,要发送NOTIFICATION报文 通告BGP对端 |
| KEEPALIVE | 维持邻居关系 | 定时发送KEEPALIVE报文以保持BGP邻居关系的有效性 |
| Route-refresh | 为保证网络稳定,触发更新路由的 机制 | 当路由策略发生变化时,触发请求邻居重新通告路由 |
BGP对等体类型¶
运行BGP的路由器被称为BGP speaker。BGP路由器之间要交互BGP路由,前提是要建立正常的BGP邻居关系。要建立正确的BGP邻居关系,首先BGP对等体之间要先建立TCP连接,由于BGP是承载在TCP之上的,因此BGP没有“邻居必须直连”的限制。
有两种BGP邻居关系:
EBGP邻居(External BGP peer):位于不同AS的BGP路由器之间的BGP邻居关系¶
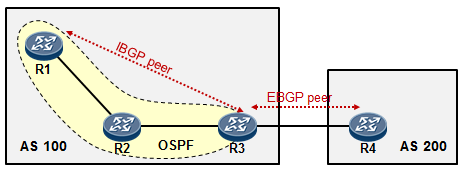
在上图中,R1、R2、R3属于一个AS,AS号为100;R4属于另一个AS,AS号为200。由于R3及R4分别属于两个不同的AS,因此它们之间建立的BGP邻居关系就是EBGP邻居关系。
要建立eBGP邻接关系必须至少满足两个条件:1)两个eBGP邻居所属AS号不同;2)Peer命令所指定的IP地址要路由可达,并且两者之间TCP连接能够建立。
IBGP邻居关系(Internal BGP peer):位于相同AS的BGP路由器之间的BGP邻接关系¶
在上图中,在AS100内,R1、R2、R3运行了一个IGP,也就是OSPF,运行OSPF的目的是为了让AS 内的路由能够打通。另一方面,R1与R3之间建立一个BGP邻居关系,由于R1及R3同属一个AS,因此它们之间建立的BGP连接是IBGP的邻居关系。
值得注意的是,R2并没有运行BGP,R1-R3之间并非直连,这在BGP中是被允许的,因为BGP是被承载在TCP之上的。建立IBGP邻接关系,必须至少满足两个条件:1)两个IBGP邻居所属AS号相同;2)
Peer命令所指定的IP地址要路由可达,并且TCP连接能够建立。不同的BGP邻居关系,对路由的操作是有明显区别的。
BGP的路径矢量特征¶
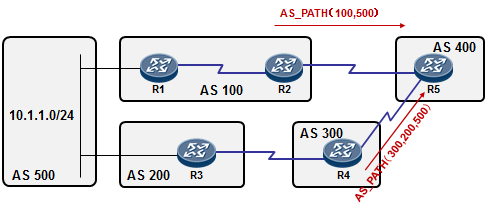
BGP是一个路径矢量路由协议。在某些层面上,它与RIP非常相似,在BGP邻居之间互相更新的是路由表,
BGP路由同样有距离的概念,只不过这里的距离,与RIP的所谓跳数是完全不同的。
BGP在将路由更新给邻居时,会给每条路由粘附许多路径属性(Path Attribute)。BGP定义了丰富的路径属性,使得BGP对路由的操控及策略部署变得异常的灵活。每条BGP路由都携带了若干路径属性,路径属性是BGP的一个非常重要的基本概念,可以理解是为用于描述每条路由的特征的一系列属性值。就好像一个人,有身高、体重、年龄等这么一些属性。其中一个非常重要的路径属性就是AS_PATH,称为AS列表, 它用于描述一条路由经过的AS号。每条BGP路由都必须携带AS_PATH属性。
相比于IGP着眼于AS内,BGP的“心胸”可就开阔得多了,在BGP眼里,一跳,就是一个AS。在上图中,
AS500内有条路由10.1.1.0/24,这条路由被AS500的边界路由器(在图中未画出)通告给了EBGP邻居R1及
R3。在路由传出AS500的时候,边界路由器会将路由的AS_PATH属性值设置为500。现在R1收到了这条路由,它又将路由通告给了自己的IBGP邻居R2,由于这条路由没有被传出AS100,因此AS_PATH没有发生改变,值依然为500。接下去R2将路由通告给了EBGP邻居R5,由于这时路由要传出AS,因此R2为路由的
AS_PATH插入一个值为100的号码(也就是本地AS号,在列表的前面插入),这样一来R2传递给R5的BGP 路由10.1.1.0/24中,AS_PATH属性值就变成了100,500,这是一个AS的列表,当R5收到这条路由时,它就知道,我要去往10.1.1.0/24,是需要先到AS100,然后再到AS500,只需要经过2跳AS。
另一方面,R5也从R4收到了关于10.1.1.0/24的BGP路由更新,AS_PATH为300 200 500,R5就知道,从
AS300也能到达10.1.1.0/24,不过需要经过3跳AS。
AS_PATH在BGP中是非常重要的路径属性。一方面能够用来作为BGP路由优选的依据,另一方面可用于在
AS之间防止路由环路的发生。例如在上图中,R5同时收到两条到达10.1.1.0/24的路由,在不考虑其他因素的情况下,R5会优选AS_PATH更短的路由,因为“距离的AS跳数”更少,所以最终优选从R2走。另外,
10.1.1.0/24被AS500的边界路由器通告给R1后,完全有可能从R2-R5-R4-R3再通告回来,这就形成了路由环路,庆幸的是有AS_PATH这个路径属性。如果AS500的边界路由器发现,EBGP邻居R3通告给它的路由的AS_PATH属性值里出现了自己的AS号,它就认为出现了环路,因此将忽略这个路由更新。
IBGP水平分割¶
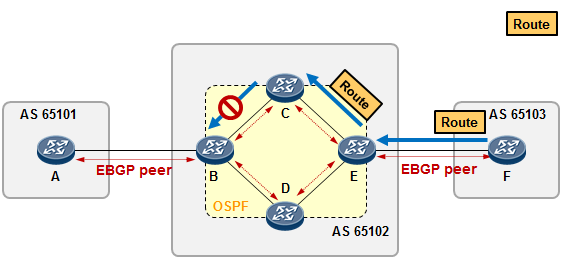
在AS之间,BGP的路由防环很大程度上是通过AS_PATH实现的,而AS_PATH仅仅在路由离开AS才会被更改,因此在AS内,IBGP路由就没有EBGP路由那样的防环能力了,这就是为什么我们需要“IBGP水平分割”:为了防止路由环路的出现,BGP路由器不会将自己从IBGP邻居学习过来的路由再通告给其他IBGP邻居。
IBGP水平分割在华为网络设备上默认已经开启。
IBGP水平分割加上AS_PATH路径属性,能够在极大程度上解决BGP的路由环路问题,但是,在某些环境中,IBGP水平分割也带来一些问题。
在上图中:路由器A属于AS65101、路由器BCDE属于AS65102、路由器F属于AS65103;
AB,EF之间建立EBGP邻居关系;BC,CE,BD,DE之间建立IBGP邻居关系;
现在F路由器将一条路由通过BGP更新给了E,E从EBGP邻居学习到这条路由后,会将其通告给C,而C从自己的IBGP邻居E那学习到这条路由后,根据iBGP水平分割规则,它不能再将该路由通告给自己的IBGP邻居B了,因此B路由器无法学习到去往AS65103的路由。这就是IBGP水平分割带来的问题。
那么,为了规避这个问题,我们就不得不在AS65102内建立IBGP全互联,也就是BCDE四台路由器两两都建立IBGP邻居关系。这种方法在路由器数量较少的时候尚且可行,可是如果数量很多,路由器就将会因为需要维护过多的BGP邻居关系而导致性能下降。为了解决这个问题,BGP设计了两个机制:路由反射器, 以及联邦,这在后文中讨论。
同步规则及中转AS内的IBGP互联问题¶
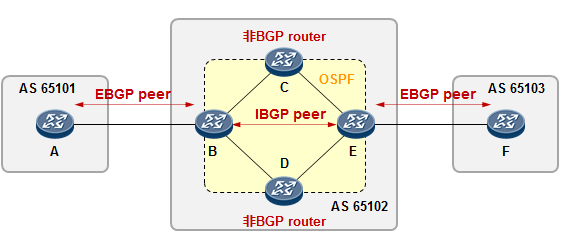
在上图所示的网络中:
- 路由器A属于AS65101;路由器BCDE属于AS65102;路由器F属于AS65103;
- BCDE运行OSPF,打通AS65102内的路由;
-
BE路由器运行BGP,两者之间建立IBGP邻居关系;CD路由器不运行BGP。
A上有个直连网段1.1.1.0/24,A将到达该网段的路由注入BGP,并且将路由通告给B,B又会将其通告给IBGP邻居E(这个传递过程其实是B将BGP报文放置于IP包内经过C或D最终传递给E,对于CD而言,这些数据包都是普通IP包,目的地址是E,因此直接转发不查看)。
最终E将1.1.1.0/24路由传递到了F。然而,虽然F能通告BGP学习到这条路由,但是当有数据前往1.1.1.0/24 时,F将数据包丢给下一跳E,而E发现1.1.1.0/24路由的下一跳是B,B并非直连,因此需递归得到其前往B 的下一跳,到B的下一跳是D或C(通过OSPF得知),于是E将数据包丢给D或C,而C和D是并不知道如何到达1.1.1.0/24的(它们只运行了OSPF,没有运行BGP),于是它们将数据包丢弃,至此形成了路由黑洞。
【BGP同步规则的概念】BGP路由器从IBGP邻居学到一条路由后,是不启用的(不优选的),也不会将其通告给EBGP邻居,除非它再次从IGP学习到相同的路由,才会启用并通告给EBGP邻居。这是为了防止出现上面所描述的路由黑洞问题。¶
回到上文的场景,为了规避路由黑洞问题,可以考虑在B、E上,将BGP路由重发布进OSPF,这样一来B、
E就都能从BGP,以及IGP学习到路由,从而形成同步(如下图所示)。但这么做后果是不可预估的,毕竟
BGP承载的路由条目是相当巨大的。

另一个解决方案是AS内路由器都运行BGP,并实现IBGP全互联,那么该AS内的路由器就都能获得BGP路由,如此即可解决路由黑洞问题。但是这个方法有个缺陷,即如果设备数量太多,管理这些IBGP的邻接关系将会是个挑战,并且设备的负担也较大。此时可以使用BGP联邦或者路由反射器技术。
综上所述,我们可以通过多种手段解决路由黑洞问题,因此BGP同步规则也就不再有必要了。实际上这是一个很老旧的特性,华为路由器缺省时关闭了BGP同步规则。因此当BGP路由器从IBGP邻居学习到一条路由时,该路由器无需再从IGP再次学习到相同路由,可以直接将该BGP路由通告给EBGP邻居。
BGP路由通告规则概述¶
- BGP路由器会将其发现的BGP路由存储在BGP路由表中。当到达同一个目的地存在多条BGP路径时, 路由器会将这些路径(路由)都存储在BGP路由表中,但是,到达每一个目的网络,路由器只会选取最 优(Best)的路由来使用,并将该BGP路由加载到全局路由表中(在没有激活路由负载分担的情况下)。
- BGP路由器只把自己使用的、最优的路由通告给其他邻居。
- BGP路由器会将其从EBGP邻居学习到的路由通告给所有BGP邻居(包括EBGP和IBGP邻居)。
- BGP路由器不会将其从IBGP邻居学习到的路由通告给它的IBGP邻居(IBGP水平分割;存在路由反射器的情况除外)。
5.3.2 BGP 入门实验
5.3.2.1 基础配置¶
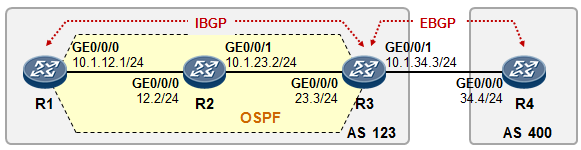
- R1、R2、R3属于AS 123;R4属于AS 400;
- R1、R2、R3运行OSPF,运行OSPF的目的是为了打通AS 123内的路由;
- R3-R4之间建立EBGP邻居关系,R2不运行BGP;
- R1-R3之间建立IBGP邻居关系;
-
在R4上,将路由4.4.4.0/24发布到BGP。
R1的配置如下(省略接口IP地址的配置):
R2的配置比较简单,就是运行OSPF而已,这部分配置不再赘述。
R3的配置如下:
R4的配置如下:
完成上述配置后,在R3上查看BGP路由表:
| [R3] display bgp routing-table BGP Local router ID is 10.1.23.3 Status codes: * - valid, > - best, d - damped, h - history, i - internal, s - suppressed, S - Stale Origin : i - IGP, e - EGP, ? - incomplete Total Number of Routes: 1 | ||||||
|---|---|---|---|---|---|---|
| *> | Network 4.4.4.0/24 | NextHop 10.1.34.4 | MED 0 | LocPrf | PrefVal 0 | Path/Ogn 400 i |
我们看到R3已经学习到了R4通告过来的BGP路由4.4.4.0/24。并且该条BGP路由的NextHop属性值为
10.1.34.4,这个下一跳地址是路由可达的。该条路由在R3的BGP路由表里有“* >” 标记,其中“*”表示这条路由是可用的(valid),只有当BGP路由的NextHop为路由可达时,该BGP路由才会被视为可用;而
“>”则表示这条路由是被优选的路由,或者说是到达该目的网络的最优路由。
BGP路由的NextHop属性是一个非常重要的属性,它是所有BGP路由都会携带的路径属性,它指示了到达目的网络的下一跳地址。
在R3上查看路由表:
R3已经将到达4.4.4.0/24的BGP路由加载到了全局路由表中。
对于R3而言,到达4.4.4.0/24的路由已经被优选,接下来,它会将该路由通告给IBGP邻居R1。在R1上查看BGP路由表:
我们看到,R1的BGP路由表中已经出现了4.4.4.0/24路由,而这条路由的NextHop属性值是10.1.34.4,但是
R1在本地路由表中没有到达10.1.34.4的路由,因此10.1.34.4不可达,如此一来,该BGP路由也就不可用了
(在BGP路由表中没有*号标记),既然不可用,自然就不能装载进路由表中使用。
那么怎么解决这个问题呢?一个最简单的方法是,为R1配置一条静态路由:ip route-static 10.1.34.0 24
10.1.23.3,这样一来R1的路由表里就有了到达10.1.34.4的路由,那么BGP路由4.4.4.0/24的下一跳地址就可达了,对应的BGP路由自然也就可用了。但是这种方法太“笨拙”。另一种方法是,在R3的OSPF进程中将10.1.34.0/24网段也注入进去,使得R1能够通过OSPF学习到10.1.34.0/24路由,这种方法也是可行的。但是由于R3-R4之间的互联链路被视为AS外部链路,因此10.1.34.0/24作为外部网段往往不会被宣告进AS内的IGP。那么还有什么其他办法能解决这个问题么?
修改下一跳为自身¶
-
BGP路由器在向EBGP对等体发布某条路由时,会把该路由信息的下一跳属性设置为本地与对端建立
BGP邻居关系的接口地址。如下图所示,R4将4.4.4.0/24通告给R3时,下一跳为10.1.34.4,也就是R4
的GE0/0/0接口地址。
-
BGP路由器将本地始发路由发布给IBGP对等体时,会把该路由信息的下一跳属性设置为本地与对端建立BGP邻居关系的接口地址。
- BGP路由器在向IBGP对等体发布从EBGP对等体学来的路由时,并不改变该路由信息的下一跳属性。例如下图所示,R3收到R4通告的EBGP路由,该路由的下一跳属性值为10.1.34.4,它将该条路由通告给IBGP对等体R1的时候,路由的下一跳属性值不会发生改变,仍然为10.1.34.4。
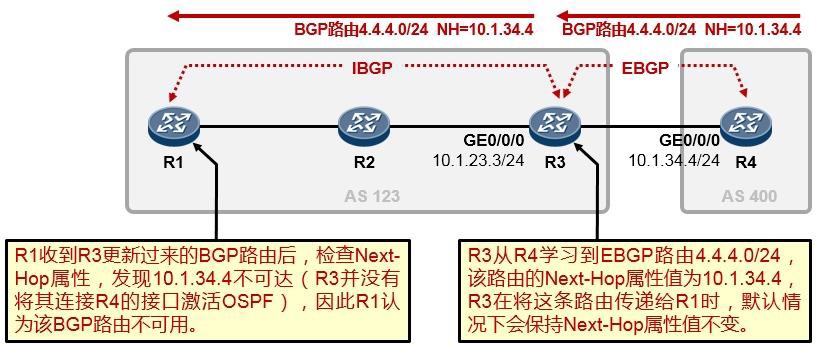
这就造成了我们上面所述的问题,由于R1没有到达10.1.34.0/24的路由,因此下一跳地址10.1.34.4不可达, 从而导致BGP路由4.4.4.0/24不可用。
还有一个方法可以解决这个问题:在R3上使用**next-hop-local**命令,可修改BGP路由的下一跳属性值为自身。在下图中,我们在R3上增加了**peer 10.1.12.1 next-hop-local**命令,那么这样一来,当R3再将EBGP路由通告给R1的时候,会将这些路由的下一跳属性值修改为自己的更新源地址(10.1.23.3),而R1已经通过
OSPF获知到达10.1.23.0/24的路由,因此10.1.23.3是可达的。
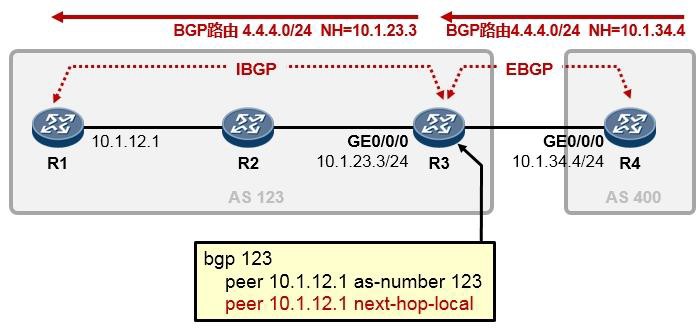
完成配置后,我们在R1上查看BGP路由表:
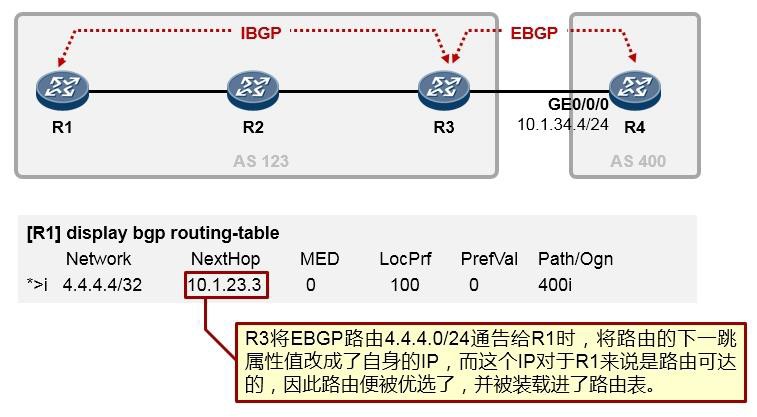
指定更新源IP地址¶
可以手工指定用于建立BGP连接的源接口及源IP地址。命令如下:
[Router-bgp] peer x.x.x.x connect-interface intf [ ipv4-src-address ] 缺省情况下,BGP使用报文的出接口作为BGP报文的源接口。当用户完成**peer**命令的配置后,设备会在自 己的路由表中查询到达该对等体地址的路由,并从该路由得到出接口信息。如果**peer**命令中没有指定接口
(connect-interface)和IP地址(ipv4-src-address),那么设备将会使用前述出接口和该接口的IP地址作为BGP报文的源接口和源地址。
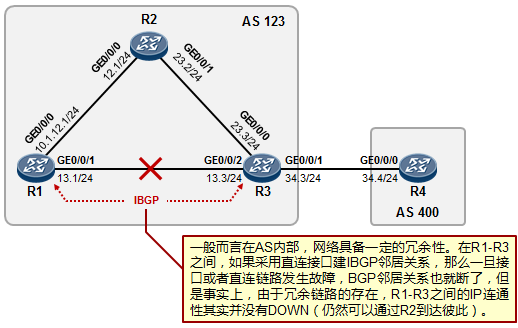
为了使物理接口在出现问题时,设备仍能发送BGP报文,可将发送BGP报文的源接口配置成Loopback接口。在使用Loopback接口作为BGP报文的源接口时,必须确认BGP对等体的Loopback接口的地址是可达的。由于一个AS内往往会运行IGP协议,因此AS内的设备能够通过该IGP协议获知到达其他设备的Loopback接口的路由。在AS内部,IBGP邻居关系通常基于Loopback接口建立。
EBGP邻居之间通常使用直连接口的IP地址作为BGP报文源地址,如若使用环回接口建立EBGP邻居关系, 要配置**peer ebgp-max-hop**命令,允许EBGP通过非直连方式建立邻居关系。
同样是上面的环境,我们稍作变更,在R1及R3上创建loopback0,地址分别为1.1.1.1/32及3.3.3.3/32,然后设备各自将loopback0宣告进OSPF,使得彼此都能通过OSPF学习到对方的Loopback0路由。
我们修改BGP的配置,使得R1-R3之间的IBGP邻居关系基于Loopback0来建立。
R1的关键配置如下:
R3的关键性配置如下:
注意,务必要将R1及R3的Loopback0接口激活OSPF。
完成这个实验¶
经过前面的讲解,我们的环境现在是这样的:R1-R3之间建立了基于Loopback接口的IBGP邻居关系;R3对
R1配置了**next-hop-local**;R3与R4之间仍然维持基于直连接口的EBGP邻居关系;R4在BGP中发布路由
4.4.4.0/24。
现在R1是能够学习到BGP路由4.4.4.0/24的,并且该路由也是被优选的,此时这条路由会被R1装载进全局路由表使用,但是,这是不是意味着R1就能够ping通4.4.4.4了呢?经过测试你可能会发现:无法ping通? 因为数据包在R2这里就被丢弃了,R2并没有运行BGP,因此它无法学习到BGP路由4.4.4.0/24。
怎么才能让R1 ping通4.4.4.4呢?方法之一是在R3上将BGP路由重发布进OSPF,使得R2能够通过OSPF学习到BGP路由4.4.4.0/24,但是这种方法存在一定的风险,因为我们知道BGP承载的前缀数量往往是非常庞大的;另一种方法是,让R2也运行BGP,并与R1、R3建立IBGP邻居关系,这样一来问题就解决了。那么
BGP邻居关系就变成了如下图所示。具体配置此处不再赘述。
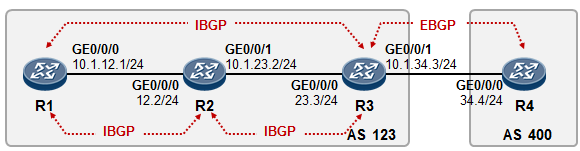
EBGP多跳¶
通常情况下,EBGP邻居之间必须具有直连的物理链路,EBGP邻居关系也将基于直连接口来建立,如果不满足这一要求,则必须使用**peer ebgp-max-hop**命令允许它们之间经过多跳建立TCP连接。
**peer ebgp-max-hop**命令用来配置允许BGP同非直连网络上的对等体建立EBGP连接,并同时可以指定允许的最大跳数。命令格式如下:
[Router-bgp] peer ipv4-address ebgp-max-hop [ hop-count ],
如上图所示,R1及R2要基于Loopback口建立EBGP邻居关系。这种情况也属于EBGP邻居之间不基于直连接口建立邻居关系的场景,必须配置**peer ebgp-max-hop**命令。图中R1与R2之间的两条物理链路是为了冗余性考虑。
R1的关键配置如下:
R2的关键配置如下:
学会看三张表¶
BGP邻居表¶
BGP表¶
查看BGP条目的详细信息:

路由表,display ip routing-table¶
- BGP 路径属性
BGP拥有丰富的路径属性。BGP的这些路径属性,将影响BGP路由的优选,同时也使得BGP的路由策略能力异常强大。
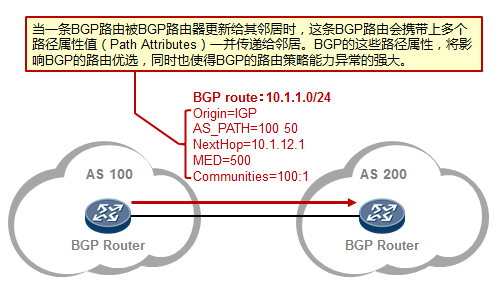
路径属性的分类:
| 公认属性 (Well-known) | 公认必遵 (Well-known mandatory) | 所有BGP路由器必须都能识别,且必须存 在于Update报文中。 如果缺少这种属性,路由信息就会出错 | Origin AS-Path Next hop |
|---|---|---|---|
| 公认自决 (Well-known discretionary) | 所有BGP路由器必须都能识别,Update 报文中可包含,也可不包含 | Local-Preference ATOMIC_Aggregate | |
| 可选属性 (Optional) | 可选传递 (Optional transitive) | 可以不支持该属性,但即使不支持,也应当接受包含该属性的路由并传递给其他邻居 | Community Aggregator |
| 可选非传递 (Optional non-transitive) | 可以不支持该属性,不识别的BGP进程忽 略包含这个属性的更新报文,并且不传递给其他BGP邻居 | MED Originator_ID Cluster_list Weight |
Preferred-Value¶
首选值(Preferred-Value)是华为设备的特有属性,该属性仅在本地有效。当BGP路由表中存在到相同目的网络的路由时,将优先选择协议首选值最大的路由。
Preferred-Value的取值范围:0~65535。路由器本地始发的BGP路由默认Preferred-Value为0,从其他BGP 邻居学习到的路由(该路由是不会携带Preferred-Value的,Preferred-Value只在本地有效,不会被通告给任何邻居),加载到本地后默认Preferred-Value也为0。
Preferred-Value是一个本地有效的华为私有属性。这个属性的含义有点像:“一条路由在我心目中的权重”。既然是在“我心目中”的,那么这个属性值自然是不能传递给别人的,只有自己知道。
在上图中,B路由器将会同时从A和C学习到两条BGP路由:10.0.1.0/24及10.0.2.0/24。默认情况下,从A及
C学习到的这两条路由Preferred-Value都是0。我们可以在B上部署策略,将A发来的10.0.1.0/24路由的
Preferred-Value调节为100,将C发来的10.0.2.0/24路由的Preferred-Value调节为100,这样一来就能够实现B上去往10.0.1.0/24的流量走A,去往10.0.2.0/24的流量走C的效果。注意,在B上部署的这个策略只会影响B自身。
 [B-bgp] display bgp routing-table
[B-bgp] display bgp routing-table
Local-Preference¶
LP(Local-Preference)属性是一个公认自决属性,属性值越大,则路由越优。Local-Preference就是本地优先级,本地的意思就是AS内部,LP只能在AS内部、在IBGP邻居之间传递,而不会传递给EBGP邻居。
上图中,ABC同属一个AS,假设A及C都有到达10.0.1.0/24的路由,并且都将路由更新给了B,那么如果我们希望B去往10.0.1.0/24网络走A,当A挂掉的时候自动切换到C,这就可以在A上部署策略,将传递给B的
BGP路由10.0.1.0/24的LP属性值设置为200,而C传递给B的路由的LP属性值保持默认100即可。这样一来
B在做路由优选时,在其他条件相同的情况下,就会优选A传递过来的这条10.0.1.0/24路由。[B-bgp] display bgp routing-table
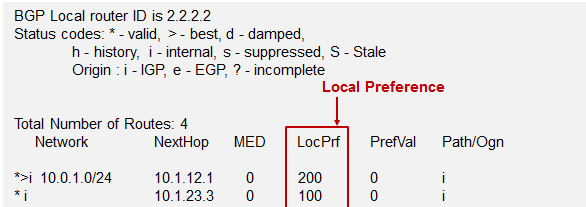
- LP属性只能在IBGP邻居之间传递(除非做了策略,否则LP值在AS内的IBGP邻居间传递过程中不会丢失),而不能在EBGP邻居之间传递。但是可以在AS边界路由器上使用In方向的策略来修改LP属性值。
- BGP路由器在向其EBGP邻居发送路由更新时,此时该EBGP路由不能携带LP属性,但是对方收到该路由后,会在本地为这条路由赋一个默认值,也就是100(可通过命令修改),然后再将路由传递给自己的IBGP邻居。
AS_PATH¶
AS_PATH属性介绍¶
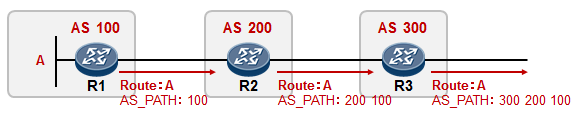
AS_PATH是公认必遵属性,用于描述到达目标网络所要经过的AS号的序列。有两个非常重要的作用: 一是用于在AS之间的路由防环,如果一台路由器收到一条BGP路由,该路由携带的AS_PATH中出现了自己所在AS的AS号,那么它知道出现了环路,因此忽略该条路由更新。AS_PATH的另一个作用是用于路由优选,我们知道AS_PATH实际上是一个列表,呈现出来就是一串AS号,那么既然是列表它就有长度,AS_PATH越短则该路由被视为越优,因为这条路径距离目的地所要经过的AS跳数更少。
AS_PATH的四种类型¶
- AS_SET:一个去往特定目的地所经路径上的无序AS号列表。
- AS_SEQENCE:一个有序的AS号列表。
- AS_CONFED_SEQUENCE:联邦内特有的AS_PATH类型,一个去往特定目的地所经路径上的有
序AS号列表,其用法与AS_SEQUENCE一样,区别在于该列表中的AS号属于本地联邦中的AS号。
-
AS_CONFED_SET:联邦内特有的AS_PATH类型,一个去往特定目的地所经路径上的无序AS号列表,用方法与AS_SET一样,区别在于列表中的AS号属于本地联邦中的AS号。
以上四种类型是通过AS_PATH属性中的类型代码进行区分。关于这两个联邦特有的AS_PATH类型, 详细内容请见本文档“联邦”一小节。
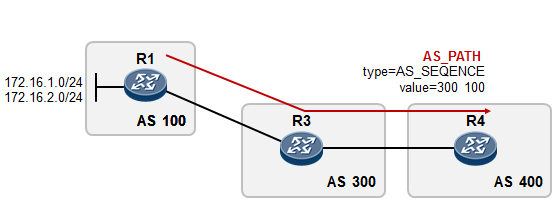
AS_Sequence很好理解,上图在不做任何策略的情况下,传递到R4的BGP路由携带的AS_PATH的类型即为AS_Sequence,这是个有序的AS号列表,当R4收到路由更新的时候,AS_PATH为300,100,
R4就知道要去目的地,需经AS300再到AS100,才可达目的。
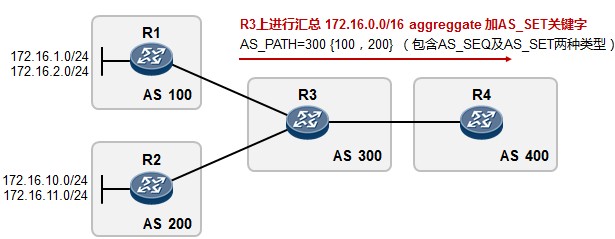
再看上面这张图,R1通告明细路由:172.16.1.0/24及172.16.2.0/24;R2通告明细路由172.16.10.0/24 及172.16.11.0/24。这些明细路由被通告给了R3。现在在R3上做路由汇总,这条汇总路由由R3产生并且传递给了R4,这条汇总路由的AS_PATH为300,丢失了其下的明细路由的AS_PATH属性,那么如果
R4与R1或R2之间如果有EBGP的连接,就有可能产生路由环路,R1、R2都会收到这条汇总路由并且接受路由更新。这是因为这条汇总路由并未携带任何关于AS100及AS200的信息。
所以其实还是需要在汇总路由上保留其明细路由的AS_PATH , 而至于保留下来的明细路由的
AS_PATH中的AS号是什么顺序已经不重要了,因为出于防环的目的只要AS号就够了。使用**aggregate**
命令加上**as-set**关键字,可以使产生的汇总路由继承明细路由的部分路径属性,其中包括AS_PATH属
性值。此时R3产生的这条汇总路由的AS_PATH 将携带两个AS_PATH 类型( 两段信息) ,一是
AS_Sequence,值为300,另一个类型为AS_Set,包含{100,200}两个AS号,并且是无序的。于是乎R4 上收到的路由所携带的AS_PATH综合起来就是300 {100,200}。值得注意的是,这个括号里的AS号, 在进行AS_PATH长度计算的时候,只当一跳来算,关于这点的验证,请看选路规则章节。
使用route-policy修改AS_PATH¶
示例1¶
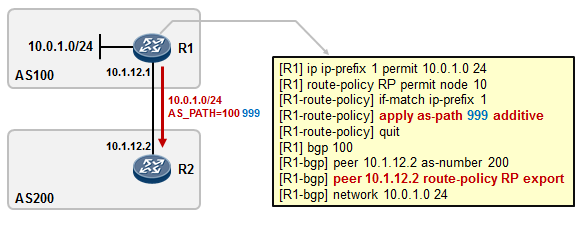
上图中,R1将BGP路由10.0.1.0/24更新给R2,在没有部署策略的情况下,R2收到10.0.1.0/24路由的AS_PATH为:100。我们可能基于某种需求,希望修改路由的AS_PATH,例如我们想插入一个
AS号999,就可以在route-policy中使用**apply as-path 999 additive**命令来实现。注意我们是在R1 上对R2做export方向的route-policy,10.0.1.0/24路由在没有被R1更新出去之前AS_Path是空的, 然后被插入了上面所说的AS号999,紧接着路由被送给EBGP邻居R2,那么R1所在的AS号码100 又被追加到了路由的AS_PATH前,所以最终路由的AS_PATH就是100 999。
值得一提的是,对于BGP而言AS_PATH属性是一个相当重要的路径属性,使用route-policy固然能够根据需求灵活的修改AS_PATH,但是任何针对AS-PATH的策略都必须谨慎执行,因为BGP的工作——例如防止路由环路等对AS_PATH的依赖很高。就拿上面的例子来说,实际上添加999的AS 号码是没有意义的,因为999的AS在这里并不存在,如果只是为了加长AS_PATH,可以考虑添加一个值为100的AS号,而不是999。
示例2¶
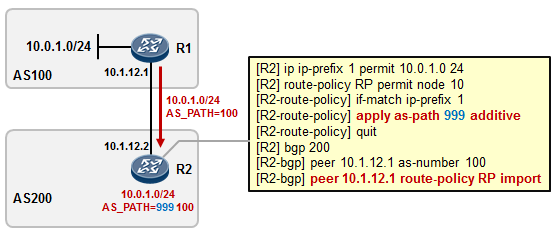
上图的实验中,我们是在R2做import方向的route-policy,同样是使用命令**apply as-path 999**
additive,结果与示例1是不一样的。由于策略是部署在R2上的,因此R1将路由更新给R2的时候路由的AS_PATH是100,R2收到该路由后,由于配置了import方向的route-policy,因此在该路由的AS_PATH前追加AS号999,于是最终在R2的BGP表里10.0.1.0/24的路由AS_PATH是999 100。
示例3¶
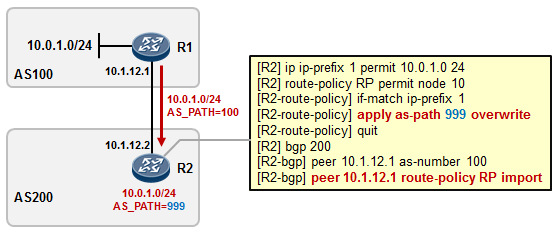
如果不是想在AS_PATH中插入AS号,而是想覆盖AS_PATH呢?可以在route-policy中使用**apply as-path overwrite**命令。在上图的示例中,我们在R2上对R1做import方向的route-policy,那么当
R1将路由10.0.1.0/24更新给R2的时候,路由的AS_PATH属性值为100,随后由于R2部署了策略, 因此该路由的AS_PATH被覆盖为999,所以最终在R2的BGP表中,10.0.1.0/24的路由AS_PATH 属性值为999。
Origin¶
公认必遵属性,明确了路由的来源,BGP路由来源有三种途径:
| 名称 | 标记 | 说明 |
|---|---|---|
| IGP | i | 通过BGP network的路由,也就是起源于IGP的路由,因为BGP network必须保证该网 络的路由在路由表中 |
| EGP | e | 是由EGP这种早期的协议重发布而来的路由 |
| Incomplete | ? | 从其他渠道学习到的(确认该路由来源的信息不完全),重发布进BGP的路由origin都 是这个标记 |
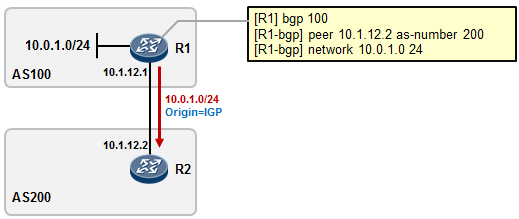
上图中,R1采用network的方式,将直连路由10.0.1.0/24引入了BGP,那么该条路由的Origin属性值就为IGP,在BGP表中,标记为i:
 [R2] display bgp routing-table
[R2] display bgp routing-table
当然,如果R1改用重发布(import-route)的方式引入这条直连路由,那么该条路由的origin属性值就是
incomplete,在BGP表中的标记就是?。
MED¶
关于MED属性¶
MED(MULTI_EXIT_DISC)是可选非传递属性,是一种度量值,用于向外部邻居指出进入AS的首选路径,即当入口有多个时,AS可以使用MED动态地影响其他AS如何选择进入路径。MED属性值越小, 则路由越优。MED主要用于在AS之间交互,MED属性值随路由通告给EBGP对等体后,对方在AS内传播该路由时,会携带该MED属性值,但是,这个MED属性值不会被通告给下一个AS。
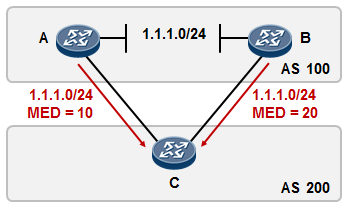
在上图中,C路由器所在的AS200双归属到AS100(有两条出口路径到AS100),可以利用MED属性来控制C进入AS100选择的路径。AS100中有路由1.1.1.0/24被A及B通告给了C。那么我们在A上部署策略, 将该路由的MED设置为10;在B上部署策略,将MED设置为20。这样一来在C上关于1.1.1.0/24路由就分别从A和B各学习到一条BGP路径,C会比较这两条路径的MED,在其他条件相同的情况下,优选MED小的路径,因此最终优选从A通告过来的路由。
MED的比较原则及配置注意事项¶
-
默认情况下,只比较来自同一相邻AS的BGP路由的MED属性,就是说如果同一个目的地的两条路由通告自不同的AS,则不进行MED的比较。
- MED只在直接相连的AS间影响业务量,而不会跨AS传递。
-
一台BGP路由器将路由通告给EBGP邻居时是否携带MED值,需要根据以下条件进行判断(在不对
EBGP邻居使用路由策略的情况下):
- 如果该BGP路由是本地始发(network或import-route)的,则携带MED值发送给EBGP邻居。
-
如果该BGP路由是从其他BGP邻居学习过来的,那么将该路由通告给EBGP邻居时不携带
MED。
-
在IBGP邻居之间传递路由时,MED值会被保留并传递,除非部署了策略,否则MED值在传递过程中不发生改变也不会丢失。
MED默认值¶
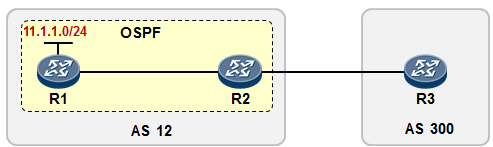
-
如果BGP路由器通过**IGP学习到一条路由**,并且通过network或import-route的方式将路由引入BGP, 产生的BGP路由的MED值继承路由在IGP中的metric。例如上图中如果R2通过OSPF学习到了
11.1.1.0/24路由,并且该路由在R2的全局路由表中OSPF Cost=100,那么当R2将路由network进
BGP的时候,产生的BGP路由MED值将继承这条路由的OSPF Cost值100。
-
如果BGP路由器将**本地的直连路由**通过network或import-route的方式引入BGP,那么这条BGP路由的MED默认为0,因为直连路由cost为0。
如果BGP路由器将**本地的静态路由**通过network或import-route的方式引入BGP,那么这条BGP路由的MED默认为0,因为静态路由cost为0。
-
如果BGP路由器通过BGP学习到其他邻居传递过来的一条路由,那么将路由更新给自己的EBGP 邻居时,默认是不携带MED的。
- 可以使用**default med**命令修改默认的MED值,default med**命令只对本设备上用import-route命令引入的路由和BGP的汇总路由生效。例如在R2上配置**default med 999,那么R2通过import-route 及aggregate命令产生的路由传递给R3时,路由携带的MED为999。
-
NEXT_HOP¶
NEXT_HOP属性是一个公认必遵属性,也就是在所有的Update报文里都必须携带的属性。这个属性描述了去往目的网络的下一跳地址。
NEXT_HOP属性的默认操作¶
将路由更新给EBGP邻居¶
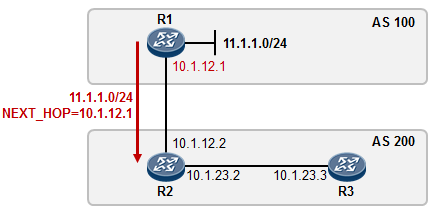
当一台BGP路由器将路由通告给自己的EBGP邻居时,该路由的NEXT_HOP属性值会被设置为其
BGP更新源IP地址。
在上图中,R1及R2之间使用直连接口IP地址建立EBGP连接,那么R1将路由11.1.1.0/24通告给R2 的时候,路由携带的NEXT_HOP属性值就是R1的接口地址10.1.12.1。
R2将收到的BGP路由11.1.1.0/24装载进路由表后,该路由在路由表中的下一跳就是10.1.12.1,也就是路由的NEXT_HOP属性值。
将EBGP邻居传递过来的路由更新给自己的IBGP邻居¶
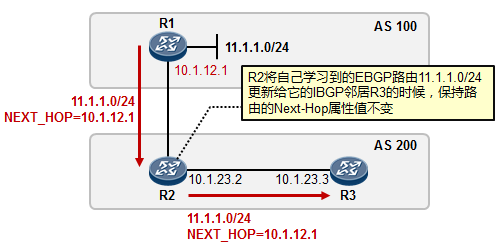
当BGP路由器把从EBGP邻居学习到的路由传递给自己的IBGP邻居时,会保留路由的NEXT_HOP 属性值不变。例如上图中,R2从EBGP邻居R1学习到的路由的NEXT_HOP属性值为10.1.12.1,那么当R2将路由再通告给自己的IBGP邻居R3的时候,路由的NEXT_HOP属性值保持不变,仍然为
10.1.12.1。
R3将学习到的BGP路由11.1.1.0/24装载进全局路由表时,该路由的下一跳地址就是10.1.12.1,这里值得一提的是, 对于R3 而言10.1.12.1 并非处于本地直连网络, 因此当R3要转发数据到
11.1.1.0/24网络的时候,实际上还需要做一次递归,也就是需要再在路由表中查找到10.1.12.1的路由。
通过aggregate命令注入的BGP汇总路由,NEXT_HOP属性值为执行汇总的路由器的更新源IP地址。¶
在多路访问网络中的NEXT_HOP¶
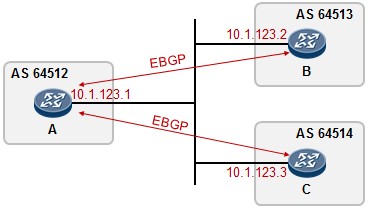
在前面的内容中,我们已经了解到:“当一台BGP路由器将路由更新自己的EBGP邻居时,该路由的
NEXT_HOP属性值会被设置为其BGP更新源IP地址”。但是这有一个例外的情况。
如上图,ABC三台路由器连接到一个多路访问网络中,例如以太网,ABC的接口属于一个IP子网。ABC 三者的EBGP邻居关系如图所示,那么当B路由器有条BGP路由100.100.100.0/24更新给A的时候,路由的NEXT_HOP属性值为B的接口IP地址也就是10.1.123.2,随后,A收到这条路由并且准备更新给C,而这时候,由于ABC处于同一个IP子网,因此A将路由更新给EBGP邻居C的时候,会做一个特殊处理: 保持路由的NEXT_HOP属性值不变。为什么这样做呢?实际上这样操作是非常有好处的,因为C收到这条路由时,发现NEXT_HOP属性为10.1.123.2,那么当C转发到达100.100.100.0/24的报文时,只需直接将数据转发给下一跳10.1.123.2即可,而不用从A去绕一下。
Community¶
关于Community属性¶
Community也被称为团体字,是可选传递属性。Community是一种BGP路由标记,用于简化路由策略的执行。可以将某些路由分配特定的Community属性值,之后就可以基于Community值而不是基于前缀信息来抓取路由并执行相应的策略了。
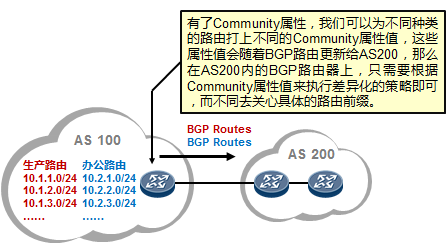
有了Community属性,我们可以在AS100引入这些办公及生产的路由的时候,就分别“打上”相应的
Community值以作标记,例如但凡生产的路由,就打上标记100:1,但凡办公的路由就打上标记100:2, 那么这些属性值随着路由传递给了AS200,在AS200上需要分别对办公及生产路由做策略的时候,只需要抓取相应的Community值即可。例如抓取100:1的Community属性值也就抓取了所有生产的路由。
Community属性是一组4个8位组的数值,RFC1997规定前2B表示AS号,后2B表示基于管理目的设置的标示符,格式为AA:NN。
Community属性对邻居起作用,在设置后,需要向邻居发送该属性(advertise-community)。
使用route-policy设置Community属性值¶
几个公认的的Community属性值¶
业内针对特殊的需求定义了公认的Community属性值,这些属性值比较特殊,而且都有自己的定义,接下去我们分别来看一下:
no-advertise¶
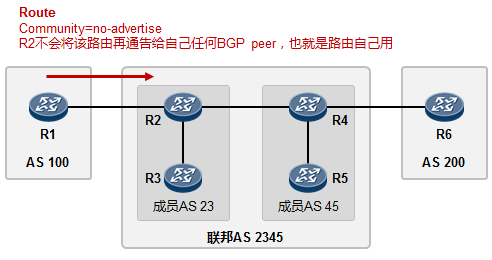
R1引入了一条BGP路由,并且为路由打上了“no-advertise”的Community属性值,这条路由传递给了R2,R2发现路由携带了“no-advertise”的Community属性值,因此这条路由自己用,不会再传递给任何BGP邻居。
no-export¶
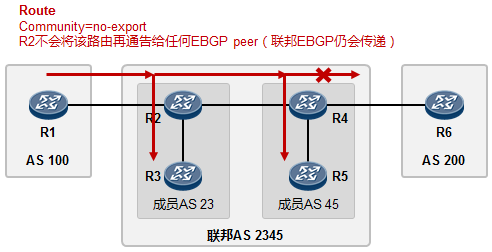
no-export-subconfed¶
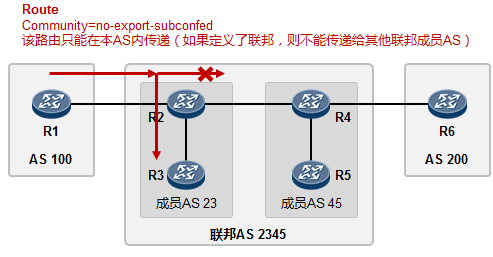
Atomic_Aggregate及aggregator¶
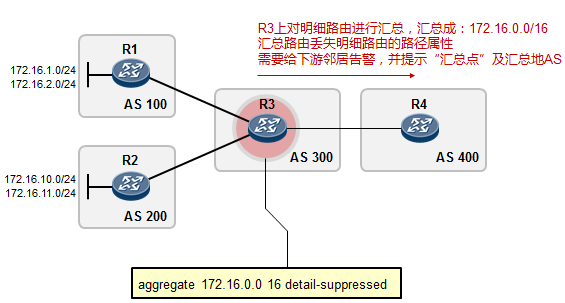
路由汇总是许多动态路由协议都支持的特性,也是一个非常基本的协议特性,BGP当然是支持路由汇总的。然而路由汇总在优化路由条目数量的同时,也带来一定的问题,例如明细路由在路由汇总的执行点之后就被抑制了,取而代之的是新产生的这条汇总路由,而汇总路由可能会丢失明细路由的路径属性,其中包括最重要的AS_PATH属性,而AS_PATH是BGP路由防环的重要依据。
因此BGP定义了这两个路径属性:Atomic_Aggregate及Aggregator,分别用于告诉下游BGP路由器:1、这是条汇总路由,2、汇总路由发生的地方(也就是汇总路由的始发AS和始发路由器)。
R4# display bgp routing-table 172.16.0.0
- BGP 路由策略
BGP路由汇总¶
BGP路由自动汇总¶

BGP支持路由自动汇总,首先需要在BGP视图下配置**summary automatic**命令,这条命令开启了BGP
路由自动汇总的功能。另外,BGP的自动汇总功能仅对使用import-route方式引入的路由有效。
在上图中,R1打开了BGP自动汇总的开关,同时使用import-route引入了直连路由1.1.1.0/24,这条路由被注入BGP后就会被自动汇总成主类路由:1.0.0.0/8,然后传递给R2。
BGP手工路由汇总(使用aggregate命令执行路由汇总)¶
在BGP中部署路由手工汇总的命令如下:
我们看到**aggregate**命令包含了许多关键字,每个关键字都有特定的用途,接下去我们来逐个分析分析:
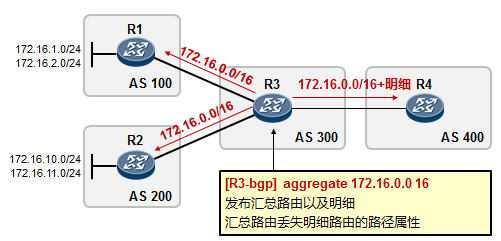 aggregate¶
aggregate¶
在上图中R1所在的AS100内有明细路由172.16.1.0/24及2.0/24;R2所在的AS200内有明细路由
172.16.10.0/24及11.0/24,这几条明细路由通过BGP通告给了R3,然后R3通告给了R4。
现在为了优化网络中的路由条目数量,我们在R3上部署BGP路由汇总,使用**aggregate 172.16.0.0**
**16**命令之后,R3就会去检验自己的BGP路由表,只要表中有172.16.0.0/16这个主类网络的子网路由并且是被优选的,R3就会产生一条172.16.0.0/16的汇总路由,并将汇总路由通告给BGP邻居。
值得注意的是,直接使用**aggregate 172.16.0.0 16**命令后,R3将同时把那四条明细路由,以及汇总路由一起通告给R4,另一方面,汇总路由172.16.0.0/16也会被通告给R1及R2,这里事实上有一个路由环路的隐患(至于如何解决这个问题,请看下文)。
aggregate detail-suppressed¶

如果我们只希望R3通告汇总路由、不通告明细路由呢?就在上述命令的基础上增加一个**detail-**
**suppressed**关键字即可。
完成上述配置后,我们看到在R3的BGP路由表里,四条明细路由都被抑制了,行首的s意思就是
suppressed(抑制)。这样就起到了路由数量优化的作用:
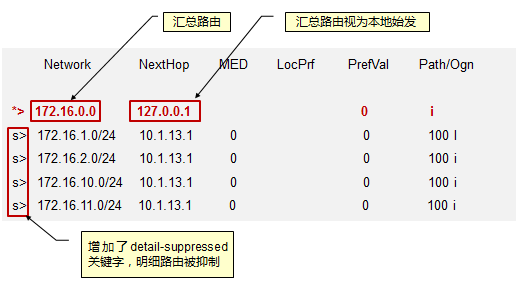 [R3] display bgp routing-table
[R3] display bgp routing-table
再来看一下这条汇总路由的详细信息:
[R3] display bgp routing-table 172.16.0.0¶
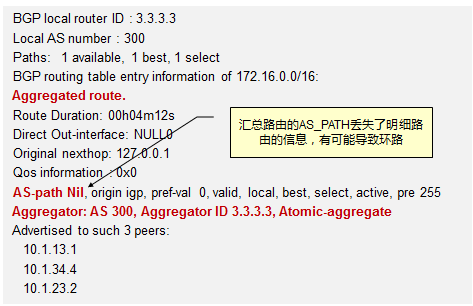
Aggregated route字样指示这是一条汇总路由。AS_PATH Nil指示这条汇总路由丢失了明细路由的路径属性,其中包括AS_PATH,这就带来了产生环路的隐患(怎么规避,继续看下文)。
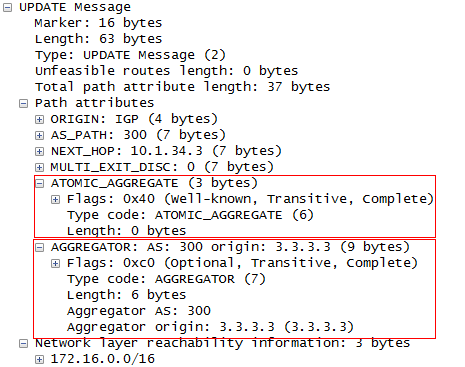
aggregate detail-suppressed as-set¶
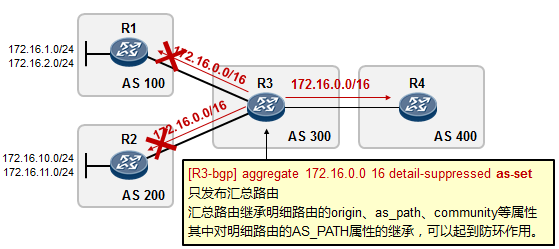
使用**aggregate 172.16.0.0 16 detail-suppressed**命令的话,R3将会抑制明细路由,同时产生一条/16的汇总路由并通告出去。值得注意的是这条汇总路由到目前为止是一条全新的路由,由R3始发,它丢失了那四条明细路由的路径属性,其中尤以AS_PATH属性的丢失最为可怕。
我们看到,这条汇总路由实际上是被传递给了R1、R2及R4,注意到汇总路由被传递给R1及R2后, 这就产生了路由环路隐患,R1及R2会将这条路由加载进路由表,因为这条汇总路由的AS_PATH 为300,因此BGP不认为存在环路。那么怎么规避呢?**aggregate**命令为我们提供了一个**as-set**关键字,在命令**aggregate 172.16.0.0 16**命令中增加**as-set**关键字后,所产生的汇总路由将继承明细路由的路径属性,我们重点分析AS_PATH属性的继承。来看一下命令配置后的效果:
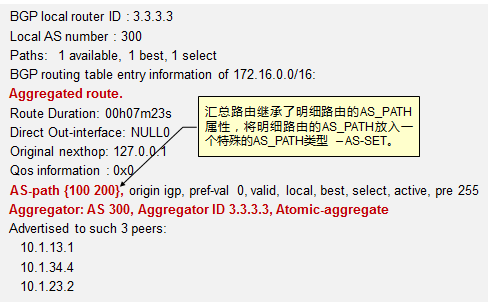 [R3-bgp] display bgp routing-table 172.16.0.0¶
[R3-bgp] display bgp routing-table 172.16.0.0¶
注意到汇总路由的AS_PATH发生了变化,变成了{100 200},这个实际上是一种特殊的AS_PATH
类型(as-set类型),关于这种类型的详细描述请参考本系列文档的路径属性相关章节。在{}中的
AS号是没有顺序的,因为新产生的汇总路由所汇总的明细分别来自于AS100和AS200,这里100及
200作为防环的依据时其顺序是不重要的。
汇总路由携带这个AS_PATH属性,再传递到R1及R2的时候,AS_PATH会变成300 {100 200},R1 和R2在路由的AS_PATH中看到自己本地的AS号,因此认为出现了路由环路,于是忽略这个路由更新。去R4上看看该汇总路由:
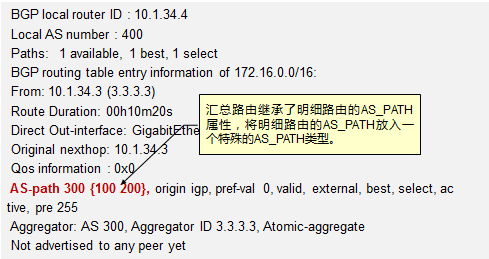 [R4-bgp] display bgp routing-table 172.16.0.0¶
[R4-bgp] display bgp routing-table 172.16.0.0¶
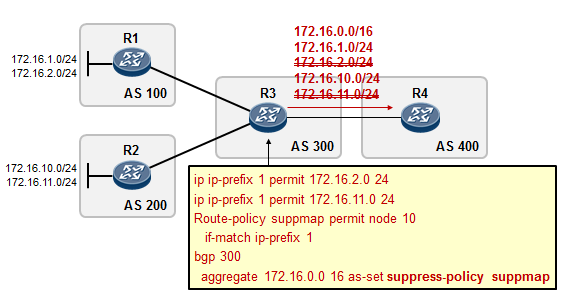 aggregate suppress-policy¶
aggregate suppress-policy¶
**suppress-policy**关键字用于通告汇总路由及选定的明细路由(抑制特定的明细路由)。使用**suppress-policy**关键字时,需在其后调用定义好的route-policy,那些被route-policy permit的明细路由将被过滤,其他明细路由则被放行。**suppress-policy**虽然调用route-policy ,但是route-policy 只能用于匹配(if-match),不能用于设置属性(不能用apply命令)。
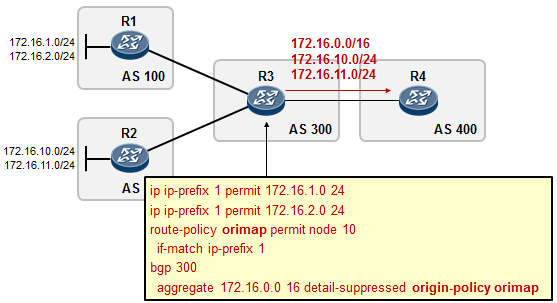 aggregate origin-policy¶
aggregate origin-policy¶
**origin-policy**关键字可调用一个route-policy,在该route-policy中使用if-match语句去抓取明细路由。关联origin-policy的aggregate命令所产生的汇总路由相当于是为上述route-policy中所匹配的明细 路由而生的,只要这些明细路由中有一条路由活跃,那么汇总路由就会产生,如果route-policy所 匹配的所有明细路由都失效,那么汇总路由也就跟着消失。
注意**aggregate 172.16.0.0 16 detail-suppressed origin-policy orimap**这条命令产生的汇总路由172.16.0.0/16是与orimap中所匹配的路由强关联的,也就是说,只要orimap里所匹配的明细路由至少有一条是活跃的,那么汇总路由就是活的,而如果所匹配的路由全DOWN了,那么汇总路由也就消失了。另外,没有被orimap匹配的明细路由,即使它是172.16.0.0/16的子网路由,也视为与本汇总路由无关,因此这里即使使用 了 detail-suppressed 关键字,却并没有 抑制掉
172.16.10.0/24及172.16.11.0/24这两条路由。
aggregate attribute-policy¶
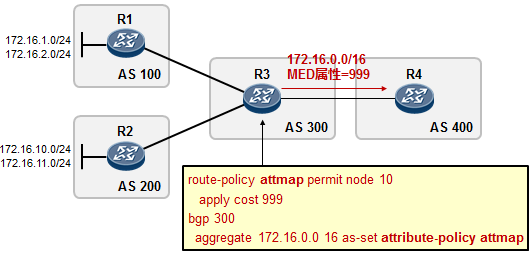
在**aggregate**命令中使用**attribute-policy**关键字调用一个route-policy,可以设置汇总路由的路径属性。例如上图中,写一个route-policy,设置MED为999,然后在**aggregate**命令中加上**attribute-**
**policy**来调用定义好的route-policy,就可以为产生的这条汇总路由设置MED值。
as-path-filter及正则表达式¶
正则表达式概述¶
正则表达式(regular expression)是按照一定的模板来匹配字符串的公式。是一种使用非常广泛的工具。我们日常上网的过程中,也都经常与正则表达式有交集,例如在一个站点注册的时候,要输入手机号码,那么后台程序如何判断用户输入的手机号码是有效的、都是数字?这时就可以使用正则表达式来匹配。
在BGP策略部署中,也可以灵活的使用正则表达式来抓取路由。一条BGP的路由包含AS_PATH属性, 而在一个复杂的大型网络中,AS_PATH肯定也是复杂的,在特定的需求下,可能要针对特定的AS或者特定的AS_PATH内容来抓取路由,此时就可以使用正则表达式了。
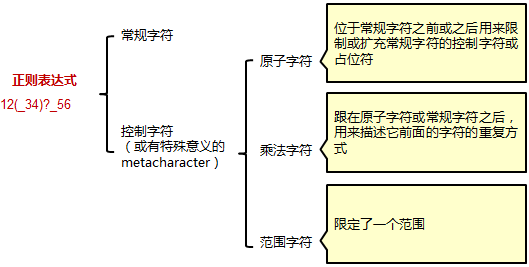
一般来说一个正则表达式可以包含两种字符:常规字符,以及控制字符。其中控制字符可以是原子字符、乘法字符、范围字符等。例如正则表达式100,非常简单,就一个100,这个正则表达式有什么功能呢?它能匹配任何包含100这几个数字的字符串,例如100 200,10000,21412100,等等,而如果想要再精确点,就可以搭配控制字符来进一步控制匹配的结果。
下面我们来看一下正则表达式可能会用到的各种字符:
原子字符¶
原子字符示例:
| ^a.$ | 匹配一个以a开始,任意单一字符结束的字符串,如a0,a!等 |
|---|---|
| ^100_ | 匹配100、100 200、100 300 400等 |
| ^100$ | 匹配100 |
| 100$|400$ | 匹配100、1400、300 400等 |
| ^\(65000\)$ | 仅仅匹配(65000) |
| [123].[7-9] | 匹配123中的一个加上任意字符再加上7到9中的一个,如167、3空格7等 |
乘法字符¶
| * | 匹配前面字符0次或多次出现 |
|---|---|
| + | 匹配前面字符1次或多次出现 |
|---|---|
| ? | 匹配前面字符的0次或1次出现 |
一个乘法字符可以应用于一个单字符或多个字符,如果应用于多字符,需将字符串放入()中。
乘法字符示例:
| abc*d | 匹配abd、abcd、abccd、abcccd等 |
|---|---|
| abc+d | 匹配abcd、abccd、abcccd等 |
| abc?d | 匹配abd、abcd、abcdefg等 |
| a(bc)?d | 匹配ad、abcd、aaabcd等 |
范围字符¶
范围字符示例:
| [abcd] | 匹配只要出现了a、b、c、d的内容 |
|---|---|
| [a-c 1-2]$ | 匹配a、a1、62、1b、xv2等 |
| [^act]$ | 匹配不以a或c或t结尾的内容 |
| [123].[7-9] | 159 220、91 70 |
关于as-path-filter¶
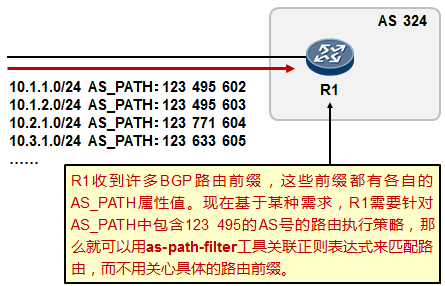
AS_PATH可以当做字符串并使用正则表达式进行匹配,例如123 495 602这个AS_PATH属性值,实际上是三个数字通过两个空格隔开的这么一个字符串,通过**as-path-filter**命令,搭配正则表达式,就可以匹配BGP路由的AS_PATH属性,抓出我们感兴趣的路由来进一步执行策略。

上图就是一个例子,命令:“ip as-path-filter 1 permit 443”就定义了一个as-path-filter过滤器,它的名字为1,使用的正则表达式是443,这个表达式实际上是匹配任何含有443的字符串。
注意,如果AS_PATH包含多个AS号,那么这些AS号实际上是通过空格分隔的,而这个空格符也是能通过正则表达式匹配的。下面看几个例子:
| ^$ | 匹配不包含任何AS号的AS_PATH,也就是本AS内的路由 |
|---|---|
| .* | 一个点和一个星号,匹配所有,任何 |
| ^100$ | 就匹配100的这个AS_PATH |
| _100$ | 以100结束的AS_PATH,也就是路由起源于100AS的路由 |
| ^10[012349]$ | 匹配100、101、102、103、104、109这些AS_PATH |
| ^10[^0-6]$ | 匹配除了100~106外的AS_PATH |
| ^10. | 匹配100~109,以及10,因为“.” 也包含空格 |
| ^(100|200)$ | 匹配包含100及200的AS_PATH |
| 12(_34)?_56 | 匹 配 12 56 及 12 34 56 |
使用as-path-filter匹配路由¶

在应用方式1中,我们定义了一个as-path-filter并关联了一个正则表达式^100$,这个as-path-filter可以匹配AS_PATH严格为100的路由(不包含任何其他的AS号或其他数字),随后我们将as-path-filter应用在了**peer**命令上,这样一来,只有被as-path-filter 1所匹配的路由,才会被通告给BGP邻居10.1.34.4。
在应用方式2中,我们在route-policy中的if-match命令调用定义好的as-path-filter,随后使用apply命令设置LP路径属性值,并在BGP配置模式下应用在了peer命令上(import方向)。这样一来,该路由器在收到BGP邻居10.1.34.4所发送过来的BGP路由中,将所有被as-path-filter匹配的路由的LP路径属性值设置为100。
as-path-filter配置示例1¶
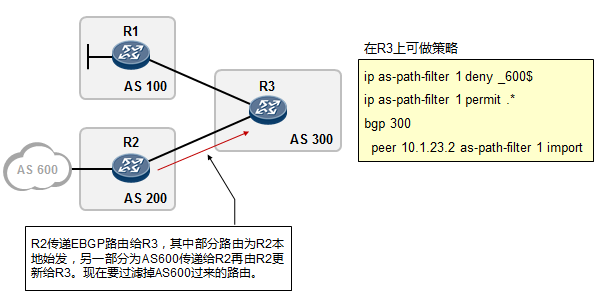
as-path-filter配置示例2¶
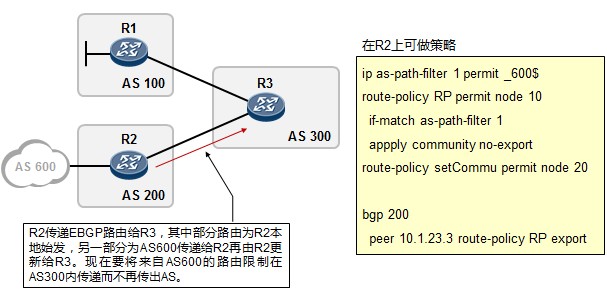
使用Community执行策略¶
使用route-policy设置路由的Community属性值¶
为路由设置Community属性值¶
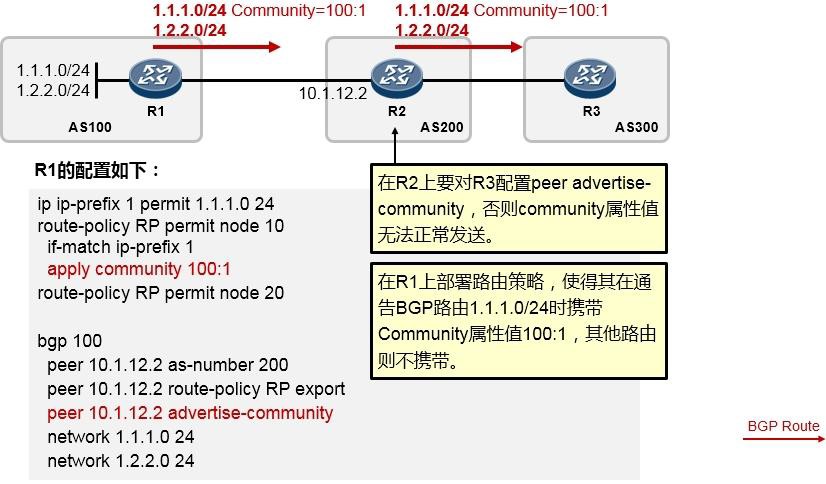
R1使用network命令向BGP发布了两条路由:1.1.1.0/24及1.2.2.0/24,并在BGP进程中对R2应用export
方向的策略,为1.1.1.0/24这条路由设置一个community属性值100:1,以便下游邻居能够使用这个
Community属性值进一步部署策略。
Community 属性默认是不会跟随路由更新给邻居的, 因此一定要加上**peer x.x.x.x advertise-**
**community**命令,在R1上要做这一步的配置,在R2上也要对R3配置该条命令。
上面命令中的**route-policy RP permit node 20**,实际上有点类似允许所有的意思,如果不配置该条命令,1.2.2.0/24这条路由就不会被通告给R2了。
为路由追加Community属性值¶

R1更新了两条路由:1.1.1.0/24及1.2.2.0/24给R2,同时1.1.1.0/24这条路由携带了一个Community属性值100:1,现在R2基于某种需求,要为这条路由追加一个no-export的community属性值。那么在R2上可以做如上配置,关键点在**additive**关键字,如果该关键字不加,则是覆盖原有community属性值。
在R3上查看配置结果:
使用ip community-filter匹配团体属性¶
上游路由器为路由设置了Community属性值,这些属性值会随着路由传递下来,那么下游的路由器就能够根据Community属性来匹配路由从而进一步执行策略。
BGP提供了一个工具:ip community-filter,这个工具可以用来匹配Community属性。
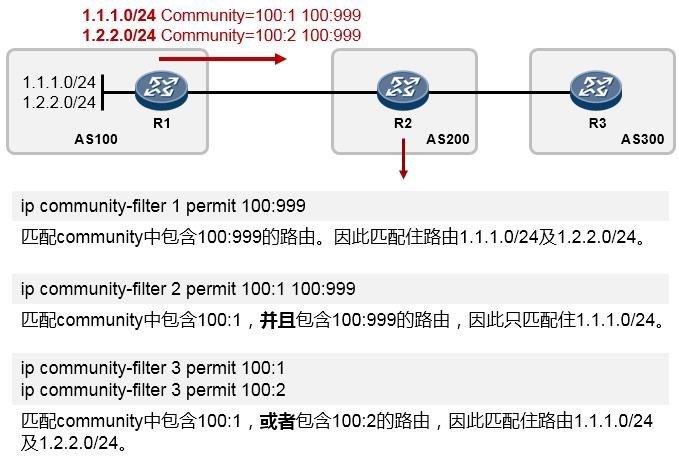
使用ip community-filter匹配团体属性(internet属性):
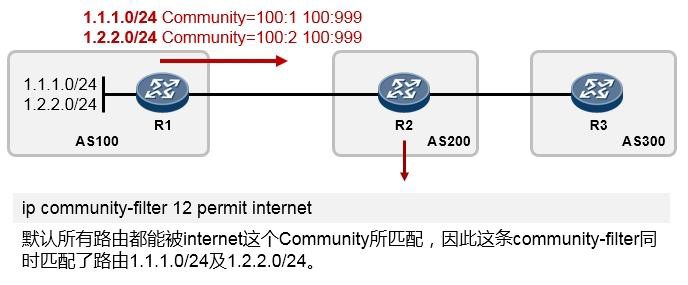
使用ip community-filter匹配团体属性(严格匹配):
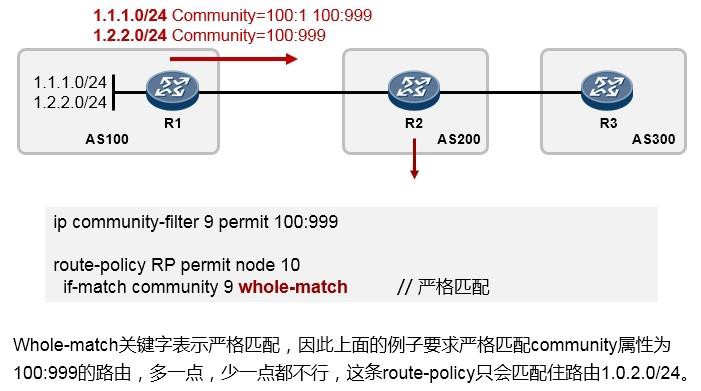
删除一个community值:
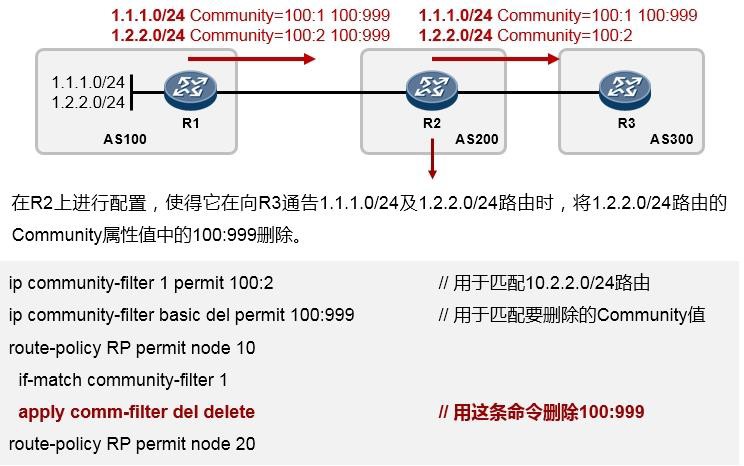
删除多个community值:
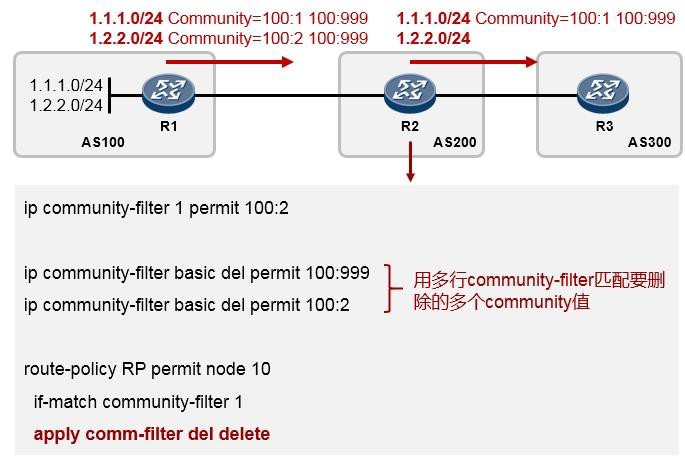
IP前缀列表¶
在BGP的部署中,经常有过滤特定路由的需要,事实上能够用于BGP路由过滤的工具还挺多,我们先看IP 前缀列表。在上图中,R1、R2、R3各自处于一个AS,并且维护着EBGP邻居关系。R1将两条直连路由
1.0.1.0.24及1.0.2.0/24引入BGP,并且传递给了R2。那么在初始情况下,R2会将这两路由更新给R3,但这里我们有这么一个需求,希望R2将路由1.0.2.0/24过滤掉,只更新1.0.1.0/24给R3。
R2的配置如下:
我们首先定义了一个IP前缀列表,在该前缀列表中,deny掉了想要过滤的路由条目,同时放行其他路由条
目。随后在BGP进程中使用ip-prefix过滤工具调用已经定义好的前缀列表,即可执行路由过滤。
5.3.4.5 Filter-policy¶
另外一个可用于路由过滤的工具是filter-policy。
配置示例1¶
在上图中,R1、R2、R3各自处于一个AS,并且维护着EBGP邻居关系。R1将两条直连路由1.0.1.0.24及
1.0.2.0/24引入BGP,并且传递给了R2。那么在初始情况下,R2会将这两路由更新给R3,但这里我们有这么一个需求:不希望R3学习到10.0.2.0/24,那么可以在R2上部署filter-policy,将1.0.2.0/24路由过滤掉。
R2的配置如下:
首先使用acl定义需要放行或者过滤的路由。然后在BGP配置视图下,使用**peer 10.1.23.3 filter-policy 2000**
**export**命令,调用定义好的acl2000,关联邻居10.1.23.3并且方向为export,因此当R2更新BGP路由给R3
的时候,只更新被acl2000允许的路由。
配置示例2¶
Filter-policy除了能够在BGP配置视图下关联**peer**使用(示例1所示),还能直接使用。关联peer使用的时候所定义的路由过滤功能仅对该邻居有效,而直接在BGP配置视图下使用则对所有邻居有效。并且使用这种方法,除了能关联ACL,还能关联前缀列表。
在上图中,R1、R2、R3各自处于一个AS,并且维护着EBGP邻居关系。R1将两条直连路由1.0.1.0.24及
1.0.2.0/24引入BGP,并且传递给了R2。那么在初始情况下,R2会将这两路由更新给R3,现在我们不希望
R3学习到10.0.2.0/24,同样是这个需求,看看另一种配置方式:
在BGP配置视图下直接使用filter-policy可调用ACL或ip-prefix前缀列表。并且对所有邻居有效。
这种方式一般搭配import-route使用:
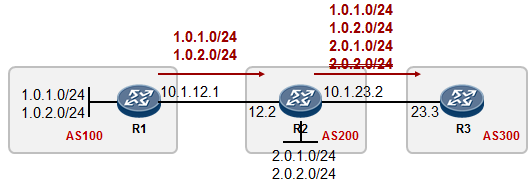
R1将路由1.0.1.0/24及1.0.2.0/24引入了BGP,路由被传递给了R2,同时R2使用**import-route**命令引入本地两条直连路由2.0.1.0/24及.0.2.0/24到BGP,现在要针对这些重发布的直连路由进行过滤,将2.0.2.0/24过滤掉,其他放行。
5.3.4.6 Route-policy¶
route-policy在BGP的策略部署中扮演一个非常重要的角色,应该说是BGP最重要的策略工具之一,可以执行BGP路由策略(设置BGP各种路径属性值),也可用于路由的过滤等,功能强大。
在BGP中使用network命令关联route-policy¶
在使用**network**命令将路由发布到BGP时,可以关联route-policy来设置路由的路径属性,例如在上图中,R1将本地两条直连路由1.0.1.0/24及1.0.2.0/24都network进BGP,并且要将这两条路由分别打上
Community属性值,1.0/24的路由打上community 100:1,2.0/24的路由打上community 100:2,R1的配置如下:
在BGP中使用peer命令关联route-policy¶
同样是上面的环境和需求,还可以使用另一种方法来配置:
仍然是使用IP前缀列表来匹配路由,然后定义一个route-policy针对不同的路由设置不同的Community
属性值,然后在BGP的配置视图下,先使用network命令发布两条直连路由到BGP,但是**network**命令不关联route-policy,而是在**peer**命令中关联route-policy,这样一来该策略将只对R2这个BGP邻居生效。
在BGP中使用peer命令关联route-policy来过滤路由¶
R1在BGP中发布了三条路由,现在基于某种原因,我们不希望BGP邻居R2学习到1.0.1.0/24这条路由, 那么可以考虑如下配置:
- BGP 路由反射器
路由反射器概述¶
BGP在AS之间的路由防环依赖AS_PATH属性,但是AS_PATH属性只当路由在EBGP邻居之间传递时才会发生改变,在AS内部,AS_PATH是不会改变的,那么在AS内部的路由防环,就无法依赖AS_PATH了,因此BGP定义**IBGP水平分割:一台BGP路由器从它的IBGP邻居学习到的BGP路由不能再传递给任何IBGP邻**
居。
由于存在IBGP水平分割,使得AS内的BGP路由器之间不得不两两建立IBGP连接(IBGP全互联),以求获得完整的BGP路由更新,然而这是个扩展性非常低的做法,同时也给网络设备带来了负担,解决IBGP扩展性问题的两种有效的办法是路由反射器及联邦。
路由反射器相比于联邦,优势在于,在联邦中所有路由器都需要支持联邦功能,而路由反射器只需要RR支持反射器功能即可,另外,路由反射器的实现机制也相对简单一些。
在上图中,由于IBGP水平分割的限制,使得R4在收到IBGP邻居R3发来的路由更新后,不能再发送给IBGP 邻居R5。如此一来R5就无法正常学习到路由,除非在R3-R5之间也建立一条IBGP连接,这样就形成了IBGP 全互联。
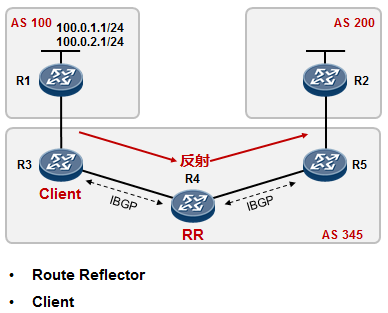
采用路由反射技术即可解决这个问题,首先我们定义一个RR(Route Reflector,路由反射器),同时定义
这个RR的Client(客户),如此一来,当RR收到她的Client发送过来的路由时,就可以像一面镜子一样,将路由反射给其他IBGP路由器。如上图所示。
在上图中,R4可以配置为RR,与它的Client R1构成了一个路由反射簇。思考路由反射器时,将簇当作一个逻辑的整体去考虑即可,RR和Client共同构成反射簇,但是只有RR知道(配置只是在RR上完成)这种路由反射器与客户的关系。注意RR只通告或反射它所知道的最佳路径。
为了维护一致的BGP拓扑,RR在反射路由的时候不修改某些BGP路径属性,这些属性包括NEXT_HOP、
AS_PATH、LOCAL_PREF和MED,并且增加了ORIGINATOR_ID和CLUSTER_LIST属性用于防环。
路由反射器的反射规则¶
我们先看一下路由反射的规则:
- 如果路由学习自非Client IBGP邻居,则**反射**给所有Client;
- 如果路由学习自Client,则**反射**给所有非Client IBGP邻居和除了该Client以外的所有Client(我司设备可以关闭RR在Client之间的路由反射行为);
-
如果路由学习自EBGP邻居,则**发送**给所有Client和非Client IBGP邻居。注意红色关键字,需区分反射和发送的区别。
下面看几个例子:
-
- 如果路由学习自Client,则**反射**给所有非Client IBGP邻居和除了该Client以外的所有Client(我司设备可以关闭RR在Client之间的路由反射行为);
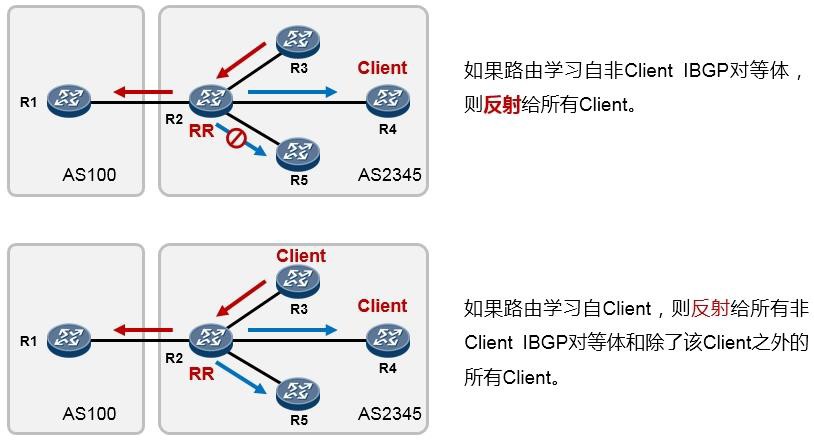
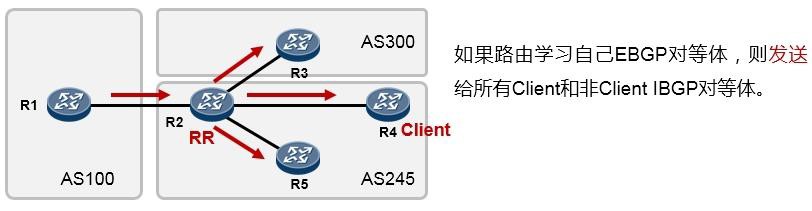
注意此处“反射”和“发送”的区别。“发送”指的是传统情况下(相当于RR不存在的场景下)的BGP路由传递行为,而“反射”指的是遵循路由反射规则的情况下,RR执行的路由反射动作,被反射出去的路由会被RR插入特殊的路径属性。
路由反射器环境下的防环¶
由于AS_PATH属性在AS内部不会发生变化(仅当路由离开本AS才会被修改),因此AS内才有水平分割的机制用于防止环路,而路由反射器实际上是放宽了水平分割原则,这就会引入路由环路隐患,因此路由反射器需使用以下两个属性防止环路:ORIGINATOR_ID和CLUSTER_LIST是路由反射器使用的可选非传递属性,用来防止环路。
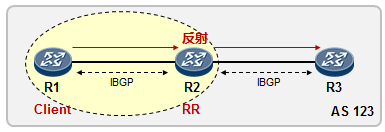
在上图中,R1为R2的Client,R2为RR。R1传递一条路由给R2,根据路由反射器的反射规则,R2作为RR将来自Client 的路由反射给非Client R3 , 并且为反射的路由加上两个新的路径属性: Originator_ID 及
Cluster_list。下面我们分别讲解一下这两个属性。
Originator_ID属性¶
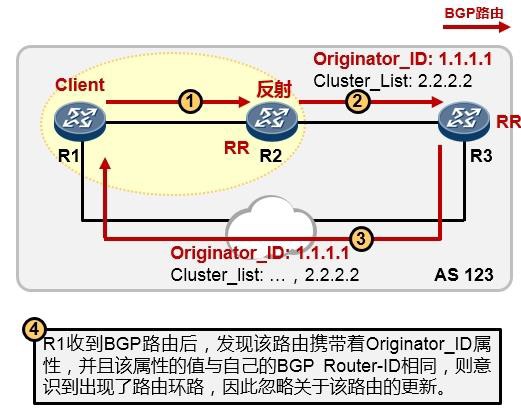
每当一条路由被RR反射时,RR会为反射后的路由创建一个Originator_ID属性,值为该路由的始发IBGP路由器的BGP Router-ID。当一台路由器收到邻居发来的IBGP路由且路由的Originator_ID属性值与自己的Router_ID相同时,它意识到发生了路由环路,因此忽略该条路由。
在上图中, R1发布了一条BGP路由,这条BGP路由在被R2反射后,被添加了两个属性,其中
Originator_ID属性值为R1的Router-ID,现在假设AS123是一个高冗余度的拓扑环境(例如,可能部署了多个路由反射蔟),而这条路由又被传回了R1。R1查看该路由,发现路由携带了Originator_ID属性并且值与自己的Router-ID相等,于是知道存在了路由环路因此忽略该路由更新。
Originator_ID及Cluster_List属性将会影响BGP路径决策。
Cluster_List属性¶
路由反射簇(Cluster)包括反射器RR及其Client。每一个簇都有唯一的簇ID(Cluster_ID)。每当一条路由被RR反射后,该路由反射簇的Cluster_ID就会被添加至路由的Cluster_List属性中。当RR接收到一条路由时,RR会检查Cluster_List,如果Cluster_List中已经有本地Cluster_ID,则忽略该路由;如果没有本地Cluster_ID,则将其加入Cluster_List,然后反射该路由。
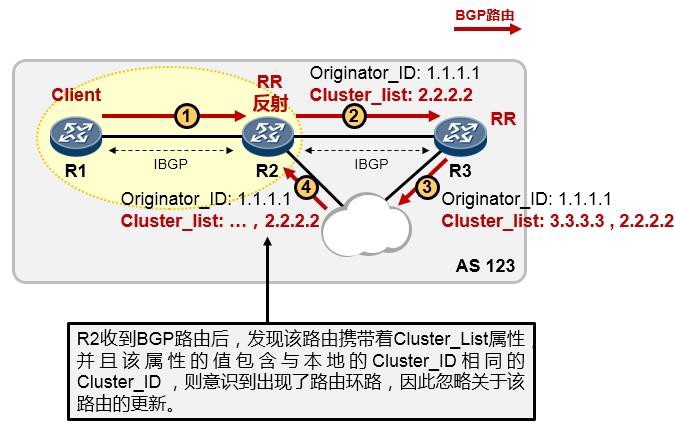
上图中,R1发布了一条BGP路由,该路由被R2反射后,被添加两个属性:Originator_ID及Cluster_List, 其中Cluster_List属性值中插入了Cluster_ID 2.2.2.2,这个Cluster_ID默认时是RR的Router-ID,所以这里值为2.2.2.2。假设AS123内有一个高度冗余的网络环境(可能部署了多个路由反射蔟),这条路由又被传回了R2,R2收到路由后发现路由携带了Cluster_List属性,并且属性值中包含自己的Cluster_ID, 它将忽略该更新。
Cluster_List属性对路由优选的影响¶
环境描述:R2为RR,设置R1为其Client;R3为RR,设置R1为其Client;R4为RR,设置R3为其Client;也
就是说,在该网络中,存在多个路由反射蔟。所有的路由器的Loopback0口地址为x.x.x.x(路由器的Router-
ID与该地址相同),x为设备编号,IBGP邻居关系基于该Loopback口建立。
现在R1将路由11.11.11.0/24引入BGP,路由会通过两条路径最终传递给R5,我们看看R5对这两条路径是如何优选的?
我们看到最终R5优选的是由R2传递过来的路由,从上面的输出我们可以看出,为什么从R4传递过来的这条
路由没有被优选,因为:“not preferred for Cluster List”,实际上是输在了Cluster_List的长度上。R1发送的路由传递给了R2,被R2反射后,路由会被插入两个路径属性: Originator_ID及Cluster_List,其中
Cluster_List属性值为2.2.2.2,然后这条路由被反射给了R5;另一边,R1发送的路由传递给了R3,被R3反射后插入了两个路径属性:Originator_ID及Cluster_List,其中Cluster_List属性值为3.3.3.3,接着,R4收到了这条路由,由于R3是它的Client,因此R4继续反射该路由,在反射时它发现路由中已经有了Cluster_List 属性,因此它将本地Cluster_ID插入已有的Cluster_List属性中,那么这样一来这条路由的Cluster_List就变成了“4.4.4.4 3.3.3.3”,最后,路由被更新给了R5。
现在R5收到了关于1.1.1.0/24路由的两条更新,它会看看谁更优。BGP有一套复杂的规则来判定这种情况, 我们称为BGP的选路规则。选路规则包含多条,在其他条件相同的情况下,Cluster_List所包含的Cluster_ID 越少,或者说Cluster_List越短,则路由越优。
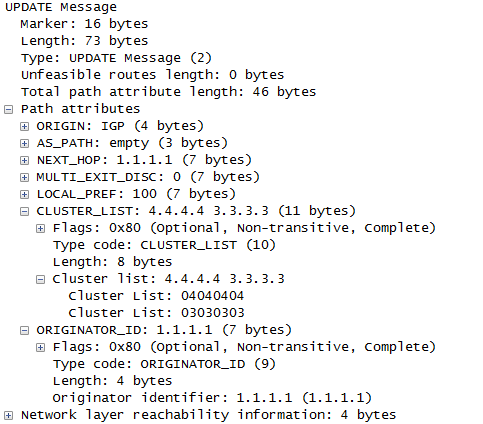
上面就是在一个Update报文中,这两个属性的呈现。
路由反射器的配置¶
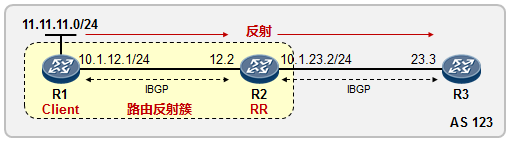
- 所有路由器的Loopback0口地址为x.x.x.x/32,x为设备编号。
- AS123内跑一个OSPF,宣告直连接口,以及各自的Loopback0接口。
- R1、R2、R3根据上图所示建立IBGP邻居关系,邻居关系基于Loopback0接口建立。
- 在R1上发布11.11.11.0/24路由进BGP,初始情况下R2能够学习这条BGP路由,但是R3无法学习到。将R2配置为RR,R1作为R2的Client,使得R3能够学习到11.11.11.0/24路由。
R1的配置(省略OSPF及接口的配置):
R2的配置(省略OSPF及接口的配置):
R3的配置(省略OSPF及接口的配置):
完成配置后,即可在R3上验证一下,查看路由11.11.11.0的详细信息:

另一个需要关注的配置是配置路由反射簇的Cluster_ID,这也是在RR上完成的配置。当RR反射一条路由时, 如果该路由不存在Originator_ID及Cluster_list属性,则插入这两个属性,同时Cluster_list属性值中写入本路由反射簇的Cluster_ID,默认情况下,Cluster_ID为RR的Router-ID,如果需要修改,可使用下面的命令;如 果RR在反射路由时,被反射路由中已经存在Cluster_List属性了,那么RR将Cluster_ID插入到已有的
CLuster_List中。
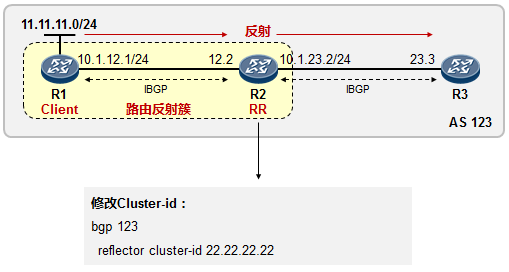
- BGP 联邦
BGP联邦概述¶
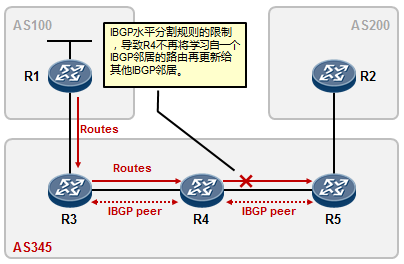
在上图中,AS345是一个Transit AS,也就是中转AS,R3-R4,R4-R5各维护一个IBGP邻居关系。
由于IBGP水平分割规则的限制,使得R4无法在将从R3学习到的IBGP路由再更新给自己的另一个IBGP邻居
R5。上一小节已经跟大家探讨过“BGP路由反射器”,这里看另一个解决这个问题的方法:BGP联邦。
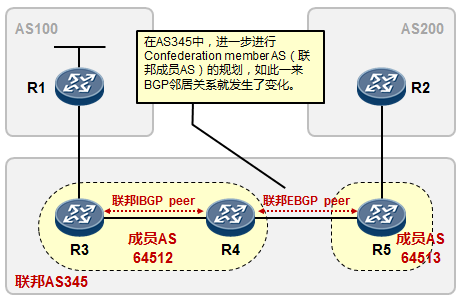
通过将AS345进行重新设计,我们将其变成一个联邦AS,可以形象的把它称为“大AS”,在这个“大AS” 中,可以进一步来部署“小AS”,也就是联邦成员AS(Confederation Member AS),如上图所示。这样
一来AS345内的BGP邻居关系就发生了变化,R3-R4,属于成员AS64512,它们之间维护联邦的IBGP邻居关系,而R5单独处于成员AS64513,它与R4之间维护的是联邦EBGP邻居关系。注意,联邦EBGP邻居关系与常规的EBGP邻居关系是有所不同的。那么既然R4-R5之间的邻居关系为联邦EBGP邻居关系,就不再有“IBGP水平分割规则”的限制了,R4从IBGP邻居R3收到的路由,就可以传递给R5了。
路由在联邦内传递时的路径属性¶
- 在联邦内部保留联邦外部路由的NEXT_HOP属性;
- 公布给联邦的路由的MED属性值在整个联邦范围内予以保留;
- 路由的Local_Preference属性值在整个联邦范围内予以保留;
- 在联邦范围内,将成员AS号压入AS_PATH,但不公布到联邦外,并且使用TYPE3、4的AS_PATH;
- AS_PATH中的联邦成员AS号用于在联邦内部防环;联邦内成员AS号不参与AS_PATH长度计算。值得一提的是,联邦外部的设备是不会知道联邦内部的成员AS的存在的。
联邦的配置¶
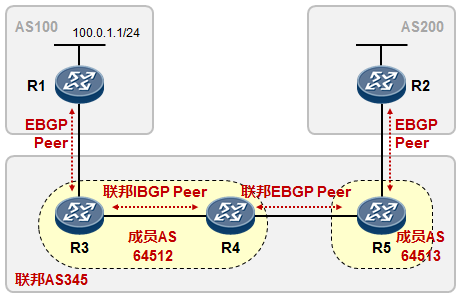
- 设备之间的互联IP地址采用10.1.xy.0/24格式,其中xy为设备编号;
- 所有路由器的Loopback0接口地址为x.x.x.x/32,其中x为设备编号;
- AS345内跑一个OSPF,宣告直连接口,以及各自的Loopback0接口;
-
路由器根据拓扑所示建立BGP邻居关系。其中R3-R4建立基于Loopback0接口的联邦IBGP邻居关系,
R4-R5建立基于Loopback0接口的联邦EBGP邻居关系;
-
在R1上发布100.0.1.0/24路由到BGP,观察路由在联邦AS内的传递;
R3的关键配置如下:
R4的关键配置如下:
R5的关键配置如下:
R1的关键配置如下:
R2的关键配置如下:
完成配置后做一下查看:


- BGP 选路规则详解
BGP路由优选规则¶
在BGP网络设计中,针对BGP路由的各种路径属性的操作都将影响路由的优选,从而对网络的流量产生影响,掌握BGP路由的优选规则十分之重要。
一台路由器有可能学习到多条去往相同目的网络的BGP路由,BGP会在这些路由中选择一条最优的路由。
BGP定义了一整套详细的选路规则,使得路由器能够在任何复杂的、冗余的网络环境下,决策出一条最优的路由:
- 优选具有最大Preferred_Value的路由;
- 优选具有最大Local_Preference的路由;
- 依次优选手动聚合路由、自动聚合路由、network命令引入的路由、import-route命令引入的路由、从对等体学习的路由;
- 优选AS_Path最短的路由;
- 依次优选Origin类型为IGP、EGP、Incomplete的路由;
- 优选MED最小的路由;
- EBGP路由优于IBGP路由;
- 优选到BGP下一跳的IGP度量值最小的路由;
- 优选Cluster_List最短的路由;
- 优选Router-ID最小的BGP邻居发来的路由;
-
优选peer地址最小的邻居发来的路由。
BGP在进行路由优选时,按照如上规则,依序进行判断。例如,当路由器学习到多条到达同一个目的网络的
BGP路由时,拥有最大Preferred_Value值的路由将会被优选,如果路由的Preferred_Value相等,则进入下一条规则进行比较,即优选具有最大Local_Preference的路由,如果路由的Local_Preference相等,则继续进入下一条规则进行比较,直到决策出最优路由为止。需要注意的是上述罗列的只是选路规则中比较有代表性的几条,并不是全部规则,另外,不同的厂商在规则的实现上存在一定的差异,而同一个厂商的不同系统软件版本,也存在实现差异。
实验环境介绍¶
拓扑及描述:¶
- IP地址规划如图所示,设备互联IP采用10.1.xy.0/24的编址,x及y为设备编号。这种编址方式能够在实验过程中更好地观察现象。同时所有的设备配置Loopback0接口,IP为x.x.x.x/32,其中x为设备编号。这个接口地址只作为设备Router-ID以及建立IBGP邻居关系时使用。
- AS345中,R3、R4、R5运行OSPF,在OSPF中,各设备宣告自己的直连接口以及Loopback0接口所在网段,但R3不在接口GE0/0/0口上激活OSPF、R5不在GE0/0/1上激活OSPF,这两个直连链路视为AS 外的链路,不将其所在网段引入OSPF中。
- 各设备的BGP连接情况如下:
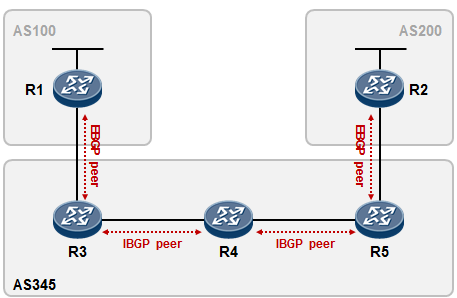
其中,IBGP邻居关系的建立基于Loopback0口,EBGP邻居关系的建立基于直连物理接口。
初始化配置:¶
注:以下罗列的设备配置中,省略了设备接口IP地址的配置。
R1的配置如下:¶
R2的配置如下:¶
R3的配置如下:¶
R4的配置如下:¶
R5的配置如下:¶
规则详解及实验验证¶
优选具有最大Preferred_Value的路由¶
规则描述¶
当路由器学习到多条到达同一个目的网络的BGP路由时,拥有最大Preferred_Value值的路由将会被优选。
Preferred_Value属性回顾¶
- 华为私有的路径属性,路由的Preferred_value可以理解为该路由在本路由器视角的权重值。
- 范围0-65535,默认值为0,值越大,则路由越优。
- 作用范围是本设备(不传递),该值不会被包含在update报文中,不会传递给任何BGP邻居。
规则验证¶
现在我们在R1和R2上配置一个Loopback1接口,配置IP地址:100.0.1.1/24,然后将这条路由发布到
BGP(这部分配置不再赘述)。如此一来,R1将更新路由100.0.1.0/24给R3,而R3从自己的EBGP邻居R1学习到这条路由后,会更新给R4;同理,R5也会将学习自EBGP邻居R2的路由100.0.1.0/24更新给R4,那么对于R4来说就从R3及R5都学习到了去往100.0.1.0/24的路由,R4将如何优选?
现在,我们希望通过操控路由的Preferred_Value值来让R4优选R5传递过来的路由。
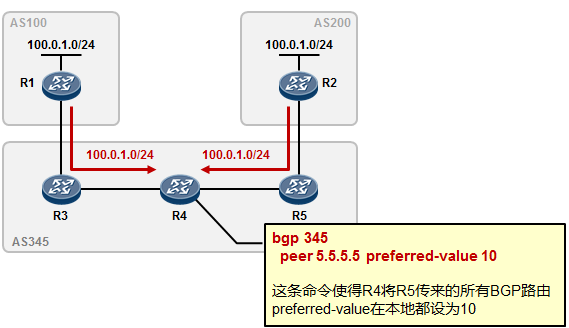
在R4配置上述命令,将R5传递过来的所有路由的Preferred_Value(在收到之后)都设置为10,而R3 传递过来的路由的Preferred_Value则在本地赋予默认值0,这么一对比,当然是优选R5所通告的路由了。但是这个方法“颗粒度”太大,如果我们只是想针对特定的路由设置Preferred_Value呢?例如:
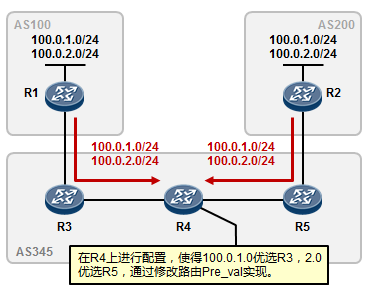
在R1及R2上新增100.0.2.0/24网段并将其发布到BGP。R1、R2的新增配置不再赘述。那么实现上图描述的需求,R4的配置可以变更成:
注意:上述配置中route-policy RP1 permit node 20及route-policy RP2 permit node 20必须配置,¶
因为route-policy在末尾隐含deny any,因此如果这两个node不加的话,相当于是只放行node 10中允许的路由。
| Origin : i - IGP, e - EGP, ? - incomplete Total Number of Routes: 4 | |||||
|---|---|---|---|---|---|
| Network | NextHop | MED | LocPrf | PrefVal | Path/Ogn |
| *>i 100.0.1.0/24 | 3.3.3.3 | 0 | 100 | 10 | 100i |
| * i | 5.5.5.5 | 0 | 100 | 0 | 200i |
| *>i 100.0.2.0/24 | 5.5.5.5 | 0 | 100 | 10 | 200i |
| * i | 3.3.3.3 | 0 | 100 | 0 | 100i |
我们看到,在R4上,对于100.0.1.0/24路由,优选的是R3传递过来的;对于100.0.2.0/24的路由,优选
的是R5传递过来的。这就实现了我们的需求。事实上还可以进一步查看路由的详细信息,例如查看
100.0.1.0/24这条路由:
OK,完成了规则一的测试后,我们将用于验证本条规则的相关配置删除,恢复成初始化配置。继续看
下一条规则。
优选具有最大Local_Preference的路由¶
规则描述¶
当路由器学习到多条到达同一个目的网络的BGP路由时,拥有最大Preferred_Value值的路由将会被优选。如果路由的Preferred_Value 值相等, 则比 较路由的Local_Preference 值,优选具有最大
Local_Preference值的路由。
Local_Preference属性回顾¶
- 公认自决属性,值越大则路由越优。
- Local_Preference只能在IBGP Peer之间传递,不能在EBGP Peer之间传递。
- 本地始发的路由默认Local_Preference为100。可用**default local-preference ?** 命令修改默认值。
规则验证¶
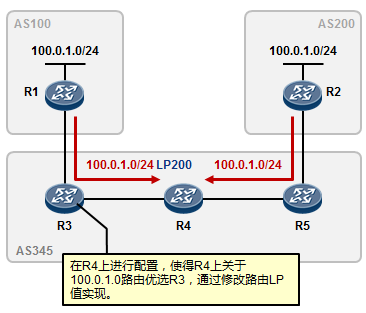
现在实验恢复成初始化环境,在R1及R2上都配置Loopback1口,IP地址为100.0.1.1/24,R1及R2都将到达100.0.1.0/24的路由发布到BGP。
我们要通过操控Local_Preference让R4优选R3传递过来的100.0.1.0/24路由。可以在R3上对R4做
export方向的策略,修改路由的Local_Preference值,将其设置为200;而R5这边则保持默认,也就是
Local_Preference=100,如此一来,在R4上,到达100.0.1.0/24的两条BGP路径,首先Preferred_Value
相等,然后继续比较Local_Preference,优选大的,因此来自R3的路由被优选。
R3的配置变更如下:
在R4上验证一下:
完成了本规则的验证后,我们将用于验证本条规则的相关配置删除,恢复成初始化配置。继续看下一条规则。
优选起源于本地的路由¶
当路由器学习到多条到达同一个目的网络的BGP 路由时,如果路由的Preferred_Value 值相等, 且
Local_Preference值也相等,那么**依次优选手动聚合路由、自动聚合路由、network命令引入的路由、import-**
route命令引入的路由、从对等体学习的路由。¶
本条规则略过不做验证。
优选AS_PATH最短的路由¶
规则描述¶
当路由器学习到多条到达同一个目的网络的BGP路由时, 如果路由的Preferred_Value属性值、
Local_Preference属性值都相等,并且这些路由都是学习自其它邻居的,那么AS_PATH最短的路由将被优选。
规则验证¶
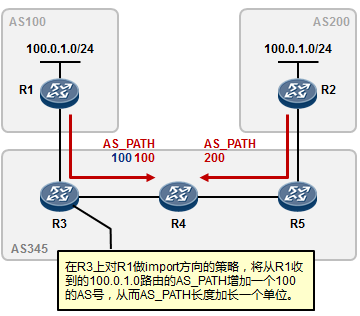
现在实验环境恢复成初始化环境,同样让R1及R2引入100.0.1.0/24路由。我们要通过操控AS_PATH属性让R4优选R5传递过来的100.0.1.0/24路由。那么可以在R3上对R1做import方向的策略,在原有
AS_PATH的基础上,增加一个100的AS号,使得路由的AS_PATH长度加长一个单位。如此一来R4将优选R5传递过来的100.0.1.0/24路由。
R3的配置变更如下:
完成配置后,在R4上验证一下:
[R4]display bgp routing-table
| BGP Local router ID is 4.4.4.4 Status codes: * - valid, > - best, d - damped, h - history, i - internal, s - suppressed, S - Stale Origin : i - IGP, e - EGP, ? - incomplete Total Number of Routes: 2 | |||||
|---|---|---|---|---|---|
| Network | NextHop | MED | LocPrf | PrefVal | Path/Ogn |
| *>i 100.0.1.0/24 | 5.5.5.5 | 0 | 100 | 0 | 200i |
| * i | 3.3.3.3 | 0 | 100 | 0 | 100 100i |
从上面的输出可以看到,R4优选了R5传递过来的100.0.1.0/24路由。当然,可以进一步查看路由的详细
信息:
另外,使用route-policy来修改BGP路由的AS_PATH时,需关注如下命令:
再有,执行**bestroute as-path-ignore**命令后,BGP在执行选路时,将忽略AS_PATH的比较,该命令
需慎用。值得强调的是:BGP的路由防环很大程度上依赖于AS_PATH,因此任何对AS_PATH的策略在实施的时候都应该考虑周全。
规则补充一¶
规则补充:AS_SET的长度为1,无论AS_SET中包括多少AS号,都将算作1个AS号。
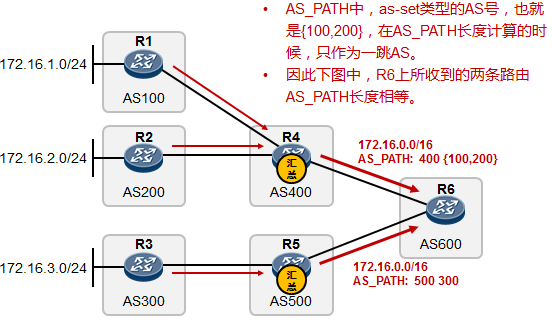
规则补充二¶
规则补充:AS_CONFED_SEQUENCE和AS_CONFED_SET长度不做计算依据。
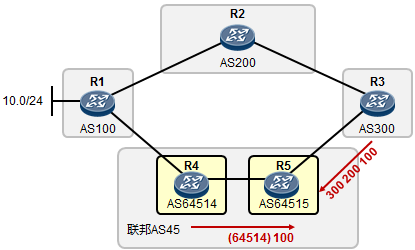
R1将自己的直连路由10.0/24发布到BGP。R1会将10.0/24的路由通过BGP更新给R4,再由R4将路由传
递给R5,此时路由的AS_PATH是:“(64514)100”,此处AS_PATH长度为1 ;另一方面R1也会将路由传递给R2,R2再传给R3,最后R3将路由传给R5,路由传递给R5时AS_PATH是:“300 200 100”,此处AS_PATH长度为3。在R5上观察到的现象是,它优选R4更新过来的这条10.0/24,这是因为该条路由的AS_PATH更短。
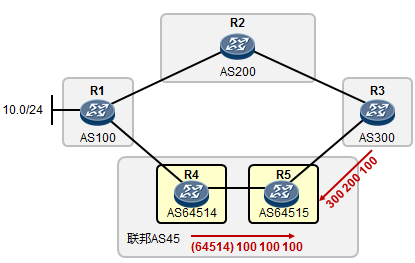
在上个环境及配置的基础之上,在R1上配置route-policy,将10.0/24路由的AS_PATH增加两个100的
AS号,也就是插入“100 100 ”并且将该route-policy对R4生效(export方向)。如此一来,R4收到的
10.0/24的BGP路由,AS_PATH为“100 100 100”,而当它将路由发送给联邦EBGP邻居R5时,路由的AS_PATH变成“(64514) 100 100 100”,此时AS_PATH的长度为3,即联邦的AS号是不做长度计算的。
另一边R3传递过来的10.0/24的BGP路由,AS_PATH长度还是3,两边的AS_PATH长度相等,因此比
AS_PATH是比不出来了,只能往后面的规则继续PK。
依次优选Origin类型为IGP、EGP、Incomplete的路由¶
规则描述¶
当路由器学习到多条到达同一个目的网络的BGP路由时,在其他条件相同的情况下,依次优选Origin属性为IGP、EGP、Incomplete的路由。
规则验证¶
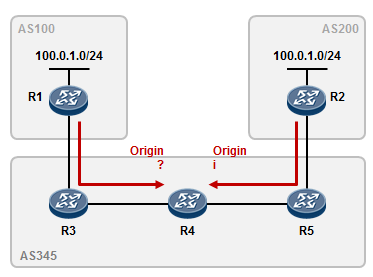
现在,继续将实验环境恢复成初始化状态。在这个规则的验证中,在R1上,改用**import-route**的方式来注入100.0.1.0/24路由,R2则仍保持**network**的方式注入。
那么R1的配置变更如下:
或者使用route-policy来修改origin,同样是修改R1的配置:
这样一来R1引入的100.0.1.0/24路由,origin属性值就为incomplete,而R2引入的100.0.1.0/24的路由
(使用**network**命令发布),origin属性值为IGP。完成配置后验证一下:
| [R4] display bgp routing-table BGP Local router ID is 4.4.4.4 Status codes: * - valid, > - best, d - damped, h - history, i - internal, s - suppressed, S - Stale Origin : i - IGP, e - EGP, ? - incomplete Total Number of Routes: 2 | |||||
|---|---|---|---|---|---|
| Network | NextHop | MED | LocPrf | PrefVal | Path/Ogn |
| *>i 100.0.1.0/24 | 5.5.5.5 | 0 | 100 | 0 | 200i |
| * i | 3.3.3.3 | 0 | 100 | 0 | 100**?** |
当然,可以进一步看详细信息:
优选MED最小的路由¶
规则描述¶
当路由器学习到多条到达同一个目的网络的BGP路由时,在其他条件相同的情况下,比较这些路由的
MED,优选拥有最小MED值的路由。
属性回顾¶
MED属性为可选非传递属性,值越小则路由越优,一般用于AS之间影响BGP路由决策。
规则详解¶
- BGP只比较来自同一个相邻AS的路由的MED值。
- 如果路由没有MED属性,BGP选路时将该路由的MED值按缺省值0来处理;而执行**bestroute med- none-as-maximum**命令后,BGP选路时将该路由的MED值按最大值4294967295来处理。
- 缺省情况下,不允许比较来自不同AS邻居的路由路径的MED属性值。而执行**compare-different- as-med**命令后,BGP将强制比较来自不同自治系统中的邻居的路由的MED值。除非能够确认不同的自治系统采用了同样的IGP和路由选择方式,否则不要使用**compare-different-as-med**命令(可能产生环路)。
规则验证¶

在本规则的实验中,我们将环境做了小小的变更,R2不再属于AS200了,我们把他规划到AS100,至于为什么,这里相信大家已经都想到了。R1、R2都向BGP发布路由100.0.1.0/24,最终R4将学习到两条路由更新。现在我们的需求是,通过操控MED值,让R4优选从R5更新过来的路由。
方法很简单,R5将100.0.1.0/24更新给R4时,MED为默认值0,那么我们只要在R1更新路由给R3时, 将MED设置为999,这条路由再经由R3更新给R4时,也会一并将MED携带,最终,R4将优选MED小的路径,也就是R5传递过来的路由。
R2及R5的配置变更这里就不再赘述了。重点看R1的配置:
完成上述配置后,仍然在R4上验证一下:
从上面的输出可以看到,R4优选了R5传递过来的100.0.1.0/24的路由。因为从R3传递过来的路由MED 为999,值更大。
相对于IBGP路由,优选EBGP路由¶
规则描述¶
当路由器学习到多条到达同一个目的网络的BGP路由时,在其他条件相同的情况下,EBGP路由的优先级高于IBGP路由。
规则验证¶
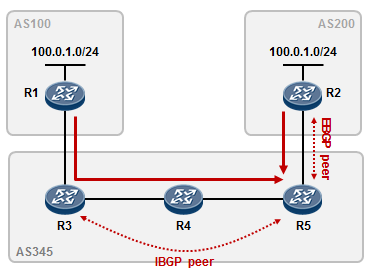
本规则的验证环境要发生一些改变,我们在R3-R5之间建立一条IBGP的邻居关系。这样一来R3会将自己从R1学习到的BGP路由传递给IBGP邻居R5,而R5又会从另一侧学习到R2更新过来的100.0.1.0/24 路由,那么R5将如何优选呢?
变更的配置这里就不在赘述了,这里有一个小细节要注意,那就是R3别忘了要配置一条**peer 5.5.5.5 next-hop-local**。
完成配置后,我们在R5上观察一下:
从上面的输出可以看到R5优选了来自R2的路由,可以进一步查看路由的详细信息:
优选到BGP下一跳IGP度量值最小的路由¶
规则描述¶
当路由器学习到多条到达同一个目的网络的BGP路由时,在其他条件相同的情况下,BGP将比较路由器到这些路由的Next_hop的IGP度量值,优选到Next_hop度量值最小的BGP路由。
规则验证一¶

仍然将实验环境恢复到初始化状态。R1将路由100.0.1.0/24更新给了R3,R3将这条路由又更新给了R4, 由于我们在R3上对R4做了next-hop-local,因此R4在收到这条路由时路由的Next_hop属性值为3.3.3.3; 同理, R4从R5 收到的路由100.0.1.0/24 的Next_hop 为5.5.5.5 。而R4又通过OSPF 学习到了去往
3.3.3.3/32及5.5.5.5/32的路由,并且此刻在R4上,到达3.3.3.3及5.5.5.5的OSPF度量值都是相等的。现在,我们在R4连接R3的接口上增加配置(该接口的缺省OSPF度量值为1):ospf cost 10。
如此一来,R4到达3.3.3.3的OSPF度量值就发生了变化,变得比到达5.5.5.5的OSPF度量值更大,因此最终,本规则将让R4优选R5传递过来的100.0.1.0/24路由。
规则验证二¶
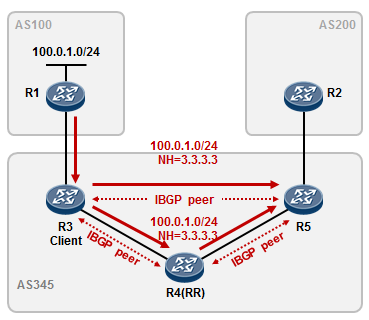
现在将网络环境再做点调整:R3-R5之间增加一条IBGP连接。R4配置为路由反射器RR,R3是她的Client。这样一来,首先,R3通过IBGP连接直接将100.0.1.0/24的路由传给了R5,另一方面又经由路由反射器
R4反射给了R5,因此,R5将同时从R3及R4学习到100.0.1.0/24的BGP路由。这时候R5怎么决策?注
意,由于这两条BGP路由Next_Hop属性值都是3.3.3.3,因此,本规则无法做出决策,因为两条路由的
Next_hop都相等,不具备度量值的可比性。只能再继续到下一条规则中决策。
优选Cluster-List最短的路由¶
规则描述¶
如果经过前面的规则,都无法决策出最优路由,那么将进一步比较候选路由的Cluster_List属性,优选最短Cluster_List的路由。
规则验证¶
略。
优选Router-ID最小的BGP邻居发来的路由¶
规则描述¶
如果经过前面的规则,都无法决策出最优路径,那么将优选Router-ID最小的BGP邻居发来的路由。
规则验证¶
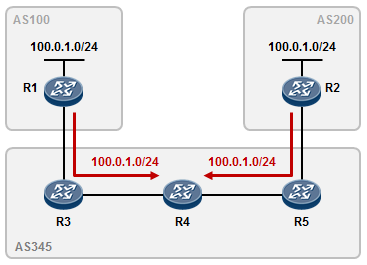
仍然是将实验环境还原成初始化状态。在R1及R2上都发布100.0.1.0/24 BGP路由。那么在不做任何路由策略配置的情况下,R4将学习到R3及R5传递过来的路由:

从上面的输出可以看到,R4已经优选了R3传递过来的路由,在其他条件相同的情况下,R4将比较通告这两条路由的邻居的Router-ID,由于R3的Router-ID 3.3.3.3要小于R5的Router-ID 5.5.5.5,因此R3传递过来的路由被优选。
规则补充¶
如果路由携带Originator_ID属性,则将使用Originator_ID代替Router-ID进行比较。
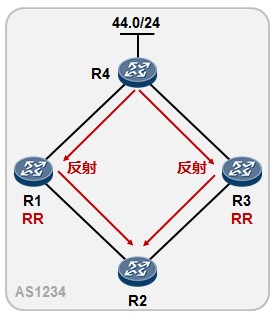
在上面的拓扑环境中:
- R1、R2、R3、R4属于AS 1234,AS内运行了OSPF,路由器都宣告各自的Loopback0接口,接口
IP地址为x.x.x.x/32,x为设备编号。
- R1-R4;R4-R3;R1-R2;R2-R3基于Loopback0建立IBGP邻居关系。
- R1配置为RR,R4是它的Client;R3配置为RR,R4是它的Client。
-
在R4上发布44.44.44.0/24路由进BGP。
当R1收到R4更新过来的路由后,会将其反射给R2并插入Originator_ID及Cluster_List属性。R3同理。那么最终R2将分别从R1和R3学习到44.44.44.0/24路由,R2会如何优选?这两条路由拥有相同的
Preferred_Value、Local_Preference,并且都通告自邻居,AS_Path长度一样,Origin也相同,MED也相等,还都是IBGP邻居通告而来,连Next_Hop属性也相同,另外,路由携带的Cluster_List长度也相同。那么能否使用本规则来决策呢?
注意,由于两条路由都携带了Originator_ID属性,因此在这一轮PK中,就不是比较R1和R3的Router-
ID 了, 而是比较这两条路由的Originator_ID 属性。结果, 由于这两条路由的起源都是R4,因此
Originator_ID相等,所以本条规则仍无法决策。那么只能在往下面的规则继续比较了,请看下文。
优选peer IP地址最小的邻居发来的路由¶
规则描述¶
如果经过前面的一系列规则仍然无法优选出最优路由,那么将比较邻居的IP地址。这个IP地址是在BGP 路由器的BGP配置中,**peer**命令后所指的那个IP地址。
规则验证¶
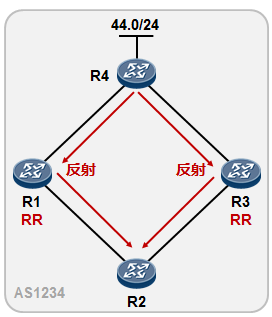
仍然看上一个小节最后的实验,在R2上,最终将比较R1及R3的peer ip,在R2上配置邻居R1时,我们用的命令是**peer 1.1.1.1 as-number 1234**;配置邻居R3时用的命令是**peer 3.3.3.3 as-number 1234**, 因此R1的地址要小于R3,故优选R1传递过来的44.44.44.0/24路由。
5.4 虚拟路由转发实例
5.4.1 VPN-Instance 部署案例
在上图所示的网络中,两个站点的网络通过核心交换机之间的一条专线实现了连接。具体背景描述如下:
-
在站点1中,核心交换机上存在VLAN10、VLAN20两个用户VLAN,其中VLAN10是业务VLAN,而
VLAN20是容灾VLAN。两个VLAN的缺省网关都在核心交换机CoreSW-Site1上;
-
CoreSW-Site1通过VLAN30与防火墙FW1/FW2实现对接(采用静态路由的对接方案)。防火墙对内接口部署了VRRP,VRRP的虚拟IP地址为192.168.30.1。
- CoreSW-Site1通过VLAN1000与CoreSW-Site2互联。Site1的VLAN20与Site2的VLAN21需实现互通。
- 对于Site1而言,VLAN10与VLAN20是需要完全隔离的。
-
要求完成配置后,VLAN10能够与防火墙通信,VLAN20能够与VLAN21通信,而VLAN10与VLAN20/21
均完全隔离。
需要强调的是,VLAN10及VLAN20的网关都放在核心交换机CoreSW-Site1上,意味着后者将配置Vlanif10 及Vlanif20,由于这两个三层接口缺省已经实现了路由互通,因此实际上此时VLAN10与VLAN20是可以通过CoreSW-Site1实现通信的,这就存在安全隐患,不满足我们的需求。当然,在CoreSW-Site1上部署ACL
可以达到目的,但是这未必是最佳的、扩展性最高的方案。
另一方案是在CoreSW-Site1上创建VPN实例(VPN Instance),从而将不同的流量彻底隔离。将VLAN10、
VLAN30保持在根设备,将VLAN20、VLAN1000放置在VPN实例中,根设备与VPN实例是彻底隔离的。
VPN实例,又被称为虚拟路由转发实例,是一个类似虚拟设备的概念。缺省时,一个网络设备的所有接口
(例如防火墙的三层接口或子接口,或交换机的Vlanif等,或路由器的三层接口等)都属于同一个转发实例
——设备的根实例。如果我们在该网络设备上创建一个VPN实例,那么就等于拥有了一台虚拟设备,我们可以将特定的接口添加到该VPN实例中,如此一来,该接口专门服务于这个VPN实例。每个VPN实例使用独立于根设备的数据转发表,例如路由表等等,它们使用不同的数据转发平面,这使得在某个VPN实例(的接口)上接收的流量,不会被转发到其他VPN实例或者根设备——彻底隔离。这个概念在MPLS VPN中有着关键的应用。当然,本文讨论的范畴仅限于使用VPN实例实现数据隔离的简单应用。
简单的说下思路:
- 在CoreSW-Site1上创建VLAN10、20、30、1000;
- 在CoreSW-Site1上配置相应的二层接口,将接口加入特定的VLAN;
- 在CoreSW-Site1上创建VPN实例,名字为test;
- 在CoreSW-Site1上将Vlanif20、Vlanif1000添加到VPN实例test,从而这两个接口与根设备彻底隔离;
- 为CoreSW-Site1的根设备配置静态默认路由,下一跳为防火墙的VRRP虚拟IP地址192.168.30.1;
-
为CoreSW-Site1的VPN实例test配置去往VLAN21的静态路由,下一跳为CoreSW-Site2;
7. 注:FW1/FW2需配置到达192.168.10.0/24的回程路由。
CoreSW-Site1的配置如下:
vlan batch 10 20 30 1000
interface GigabitEthernet0/0/11 port link-type access
port default vlan 30 description Connect-to-FW1
interface GigabitEthernet0/0/12 port link-type access
port default vlan 30 description Connect-to-FW2
interface GigabitEthernet0/0/15 port link-type trunk
port trunk allow-pass vlan 1000 undo port trunk allow-pass vlan 1
description Connect-to-CoreSwitchSite2 interface eth-trunk1
port link-type trunk
port trunk allow-pass vlan 10 undo port trunk allow-pass vlan 1
description Connect-to-E9000-2X3X interface eth-trunk2
port link-type trunk
port trunk allow-pass vlan 20 undo port trunk allow-pass vlan 1
description Connect-to-E9000-1E4E
#创建一个名为test的VPN实例:
ip vpn-instance test
route-distinguisher 100:1
#配置VLANIF接口,将VLANIF20和VLANIF1000绑定到VPN实例 test:
interface Vlanif10
ip address 192.168.10.1 255.255.255.0
interface Vlanif20
ip binding vpn-instance test
ip address 192.168.20.1 255.255.255.0
interface Vlanif30
ip address 192.168.30.4 255.255.255.0
interface Vlanif1000
ip binding vpn-instance test
注意,此时在CoreSW-Site1上使用**display ip routing-table**命令查看的是根设备的路由表,使用**display ip routing-table vpn-instance test**命令查看的是VPN实例test的路由表。另外在CoreSW-Site1执行ping命令时,交换机将使用根设备的接口作为源,并且在根设备的路由表中查询到达目的地的路由。如果希望在VPN 实例的层面进行ping的操作,例如在CoreSW-Site1上ping CoreSW-Site2的地址192.168.255.2:
冗余可靠¶
- VRRP
- VRRP 概述
技术背景¶
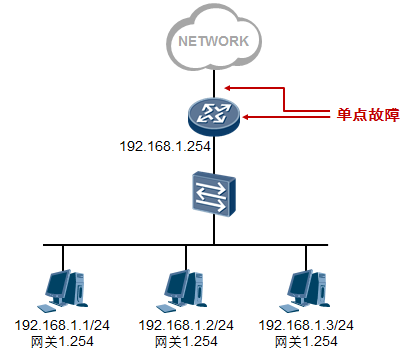
在上图中,LAN内的PC的默认网关为192.168.1.254,是图中的路由器。这个环境实际上存在单点故障的隐患,也就是说,如果路由器或者其接口发生故障,那么将出现断网,因为网关没有冗余。而如果增加一台路由器作为网关设备,又意味着内网的PC需要修改网卡配置,非常低效。
VRRP概述¶
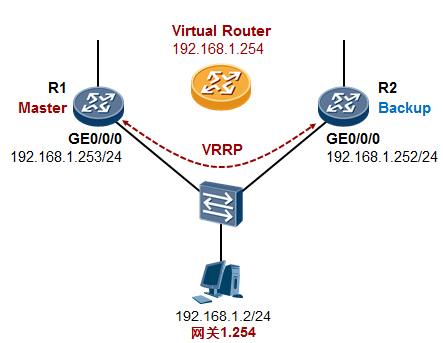
在上图中,LAN内有两台路由器,这两台路由器可以通过VRRP协议为LAN内的PC提供冗余网关。R1 的GE0/0/0 口及R2 的GE0/0/0 都连接到了一台二层交换机上, IP 地址分别是192.168.1.253 及
192.168.1.252,此刻它们属于一个广播域。
现在我们在R1的GE0/0/0口及R2的GE0/0/0口上激活VRRP,将这两个接口放到一个VRRP组中,VRRP将产生一台虚拟路由器,这台虚拟路由器的IP地址为192.168.1.254。LAN内的PC将自己的网关都指向这个虚拟路由器的IP地址。VRRP来决定该组中R1还是R2来响应PC发往192.168.1.254的数据请求。
当PC要访问外网时,首先会发送ARP报文去请求网关192.168.1.254的MAC地址,这时候由VRRP的
Master路由器来回应这个ARP请求,同时承担数据转发任务。于此同时R1的GE0/0/0口仍然在以一定的周期发送VRRP报文以便向Backup路由器通告自己的存活状态。
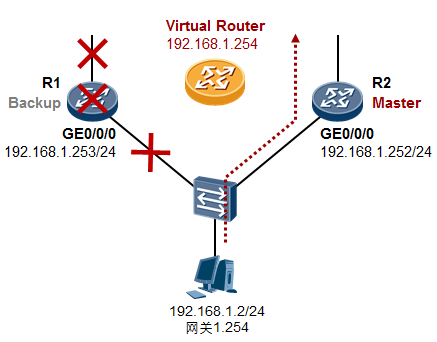
当Master路由器R1挂掉时,或者R1的上行接口发生故障时,VRRP都有相应的机制能够检测到,这时
R2就会从Backup状态切换到Master状态,并接替R1之前的工作。此时PC向192.168.1.254发送的ARP
请求,以及上行业务数据转发就由R2处理。值得注意的是,整个切换过程PC端无需做任何配置变更。
- VRRP 术语
- VRRP路由器:运行VRRP的路由器。一台VRRP路由器(的接口)可以同时参与到多个VRRP组中,在不同的组中,一台VRRP路由器可以充当不同的角色。
-
**VRRP组:**一个VRRP组由多个VRRP路由器组成,属于同一VRRP组的VRRP路由器互相交换信息,每一个VRRP组中只能有一个Master。同属一个VRRP组的路由器(的接口)使用相同的VRID。同属一个
VRRP组的路由器之间交互VRRP报文,这些路由器必须处于相同的广播域中。
-
**虚拟路由器:**对于每一个VRRP组,抽象出来的一个逻辑路由器,该路由器充当网络用户的网关,该路由器并非真实存在,事实上对于用户而言,只需知道虚拟路由器的IP地址,至于虚拟路由器的角色由谁来承担、数据转发任务由谁来承担、Master挂掉之后谁来接替,这是VRRP的工作。
-
**虚拟IP地址、虚拟MAC地址:**虚拟IP地址是虚拟路由器的IP地址,该地址一般就是用户的网关地址。与虚拟IP地址对应的MAC地址也是虚拟的,该MAC地址由固定比特位加上VRRP VRID构成,当PC发送
ARP报文去请求虚拟IP地址对应的MAC地址时,Master路由器响应这个ARP请求并告知虚拟MAC地址。
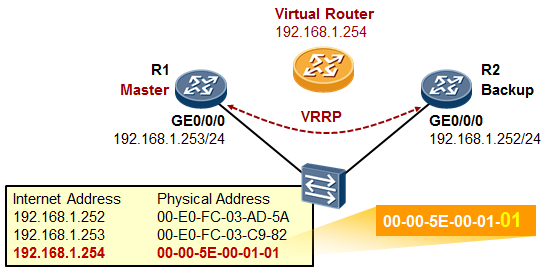
通过VRRP形成的虚拟路由器使用虚拟IP地址和虚拟MAC与网络中的PC进行通信。虚拟MAC地址的格式如上图所示,其中MAC地址的最后1个字节填充VRRP VRID,例如VRID是1,虚拟MAC地址为00-00-5E-00-01-01。
-
**Master路由器、Backup路由器:**Master路由器就是在VRRP组中的主路由器,它是实际转发业务数据包的路由器,在每一个VRRP组中,仅有Master才会响应对虚拟IP地址的ARP请求,也只有Master才会转发业务数据。Master路由器以一定的时间间隔发送VRRP报文,以便通知Backup路由器自己的存活。
Backup路由器是在VRRP组中备份状态的路由器,一旦Master路由器出现故障, Backup路由器就开始接替工作。
-
**选举依据:**先比较接口VRRP优先级(越大越优先,默认为100),如果优先级相等则比接口IP地址(IP
地址最大的胜出)。
-
VRRP 的基础配置
基础实验¶
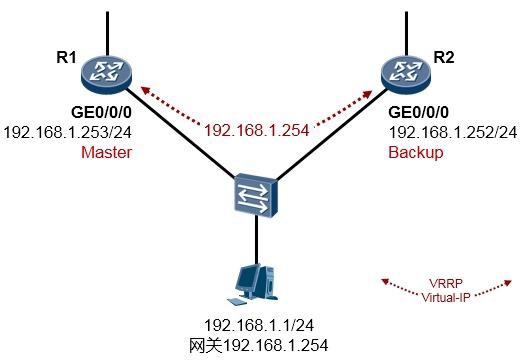
如上图所示,R1、R2及PC连接在同一台二层交换机上。R1及R2将在GE0/0/0接口上运行VRRP,实现网关冗余。要求在正常情况下R1为Master,当R1挂掉时,R2能够成为Master。
R1的配置如下:
R2的配置如下:
需注意,由于R1与R2的GE0/0/0接口工作在同一个VRRP组,因此双方配置的VRID必须相同。
完成配置后,在R1、R2上做一下查看:



track接口状态¶
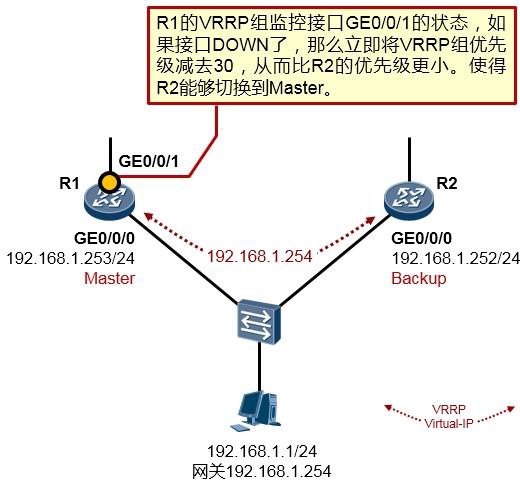
Backup路由器会不断侦听Master发出来的VRRP报文以便判断它的存活状态,当Master路由器发生故障时,Backup路由器能够感知并且进行切换。但是如果Master路由器没有发生整机故障,而只是其上行接口故障了呢?例如上图中,R1作为Master路由器,如果其GE0/0/1口DOWN掉了,那么用户的上行流量被引导到R1后,将会被丢弃。
VRRP有一个特性可以解决这个问题:通过在R1上部署VRRP track,使其能够跟踪GE0/0/1的状态,如果GE0/0/1的物理状态或者协议状态变为Down,那么R1就会主动将自己的GE0/0/0接口VRRP优先级减去一个值,从而使得R2的优先级值更大、优先级更高,那么R2将成为新的Master,R1则成为Backup,用户发往默认网关的上行流量便会被引导到R2。
R1的配置如下:
备注:R2的GE0/0/0接口VRRP优先级值为默认值100。
路由器上运行多组VRRP实现负载分担¶
R1的配置如下:
R2的配置如下:
在三层交换机上部署VRRP¶
SW1及SW2都是三层交换机,内网有VLAN10的用户,网段为192.168.10.0/24。现在要在SW1及SW2
间跑一组VRRP。正常情况下SW1的vlanif10为主,SW2为备。
SW1的配置如下:
SW2的配置如下:
VRRP+MSTP典型组网¶
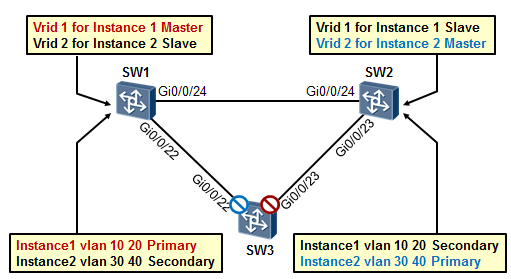
SW1及SW2为核心交换机,SW3为接入层交换机下联PC。三台交换机构成一个三角形冗余环境。内网存在四个VLAN:10、20、30和40。
要求网络正常时,VLAN10、20的用户上行的流量走SW1;VLAN30、40的上行流量走SW2,并且当SW1 或SW2发生故障时,能够进行自动切换。
这里实际上需要同时考虑两个因素,一是VRRP,二是MSTP。从三层的角度来说,SW1是VLAN10、
20的VRRP Master,SW2是VLAN30、40的VRRP Master。从二层的角度来看,网络里肯定是有环路的,因此需要借助MSTP来打破环路,但是不能随便阻塞端口,应该保证VLAN10、20的流量走左侧的链路到SW1,而VLAN30、40的流量走右侧到SW2。因此MSTP的配置上,将VLAN10、20及VLAN30、
40分别映射到不同的MST实例。例如将VLAN10、20映射到Instance 1,将vlan30、40映射到Instance2, 然后将SW1设置为Instance1的主根、SW2为Instance1的次根,将SW1为Instance2的次根,SW2为
Instance2的主根。这样一来,在Instance1的生成树中,SW3的G0/0/23将被阻塞,在Instance2的生成树中,SW3的GE0/0/22将被阻塞。
SW3的配置如下:
SW1的配置如下:
SW2的配置如下:
完成配置后,各VLAN的用户都能够ping通自己的网关;我们在SW3上看看:
我们看到,MSTP实例1中被阻塞的端口是GE0/0/23口;MSTP实例2中被阻塞的端口是GE0/0/22,符合需求。再去SW1上看看VRRP组的状态:
| [SW1] display vrrp brief | ||||
|---|---|---|---|---|
| VRID | State | Interface | Type | Virtual IP |
| -------------------------------------------------------------------------------------------------- | ||||
| 1 | Master | Vlanif10 | Normal | 192.168.10.254 |
| 2 | Master | Vlanif20 | Normal | 192.168.20.254 |
| 3 | Backup | Vlanif30 | Normal | 192.168.30.254 |
从上述输出可以看出,SW1为VRRP组1及组2的Master,同时也为VRRP组3和组4的Backup。
- VRRP 常见问题
VRRP双主问题¶
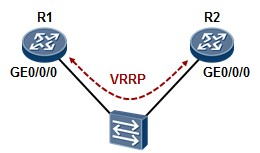
由于VRRP协议报文是以组播的方式发送的,这就提出了一个限制:VRRP的成员接口必须处于一个
LAN或者说一个广播域内,否则VRRP报文将无法正常收发,如果同一个VRRP组内的接口无法正常收发VRRP报文,就容易出现双主故障。
在上图中,R1及R2的GE0/0/0接口接入同一个交换机,此时R1、R2的GE0/0/0接口处于一个广播域内,
VRRP的协议报文收发应该没有问题,此时VRRP能够正常工作。但是如果交换机连接R1、R2的这两个接口被划分到了两个不同的VLAN中,那么就会出现双主故障。因为一台路由器发出的VRRP报文无法被另一台接收,双方感知不到对方的存在。
在上图所示的场景中,下行设备均为路由器,如果这些路由器都采用三层接口(而不是二层接口)与上面的设备对接,那么上面的设备就不具备运行VRRP的条件,因为在这种场景中,VRRP协议报文无法被下面的路由器透传。这样,上述两种组网就不能够部署VRRP,此时,可采用动态路由协议。
同一个广播域内VRRP VRID冲突¶
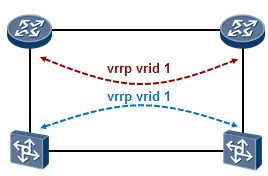
如图中所示,路由器与交换机之间通过VRRP的方式进行三层对接,但上、下行VRRP的VRID被设置为一样,由于VRRP通过VRID来区分不同的VRRP组,因此,如果出现上图这类情况就会造成VRRP的计算混乱,误认为四台设备的接口加入了同一个VRRP组。
所以在同一个广播域内,不同的VRRP组的VRID切记不能产生冲突。
- VRRP 与 NQA 的联动
技术背景¶
NQA(Network Quality Analysis)是我司数通设备上用于网络质量分析的一个特性。该特性能够检测网络的各项性能指标,最简单应用如使用NQA检测网络中某个IP地址的可达性。当然NQA的功能非常丰富,还能够用于采集网络HTTP的总时延、TCP连接时延、文件传输速率、FTP连接时延、DNS解析时延、DNS解析错误率等。NQA的采集结果可以被多种应用所使用,例如和静态路由关联,从而为静态路由带来更好的灵活性,或者与VRRP联动,提高VRRP的可靠性。
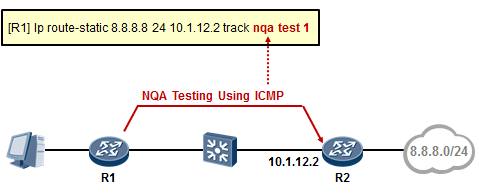
例如上图所示的环境中,R1与R2之间隔着一台二层交换机,R1配置到达8.8.8.0/24网络的静态路由, 如果R2发生故障,或者交换机与R2之间的互联线路发生故障,R1是无法感知的,这就会产生问题。为
了规避这个问题,可以在R1上运行一组NQA实例,探测到达10.1.12.2的可达性,然后,静态路由跟踪这个探测的结果,如果探测的结果是失败的,意味着10.1.12.2不可达了,则将静态路由失效。
验证实验¶
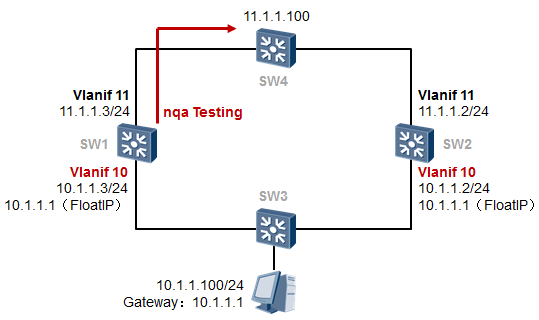
-
在上图所示的环境中,VLAN10为用户所在的VLAN。
-
SW1、SW2创建VLAN10及VLAN11,在vlanif10上运行VRRP,缺省情况下SW1为主,SW2为备。
PC的网关设置为VRRP组的虚拟IP地址。
-
SW1及SW2的VLAN11用于上联,仅做测试,不部署VRRP。在SW4上配置一个IP作为测试IP地址。
-
要求网络正常时,VRRP组的Master在SW1上。当11.1.1.100不可达时,VRRP组能够自动切换。
SW1的关键配置如下:
-
SW2的关键配置如下:
在SW4上undo掉IP地址11.1.1.100来模拟11.1.1.100不可达。注意,此刻SW1与SW4之间的连线仍然
是正常的,传统的VRRP只能跟踪直连接口的状态,但是与NQA联动的VRRP能够感知到远端IP的可达性。因此在undo掉11.1.1.100这个地址后,SW1的NQA实例会检测到目标IP地址不可达,从而NQA的测试实例状态会变成failed,而VRRP也会检测到这个变化,并将自己的优先级减去20,如此一来SW2 就会成为新的Master。
当11.1.1.100恢复时(重新配置上这个IP地址),NQA能够检测到,测试用例的状态变成Success,VRRP感知到后,将优先级变回110,如此SW1又抢占回Master,SW2则变成Backup。
注意,在部署NQA时,各项参数的配置务必注意,如果参数配置不当,有可能会导致NQA检测结果的异常。参数需遵循如下规则:
interval * probe-count + timeout \< fruency
网络安全¶
- ACL
- ACL 概述
- ACL(Access Control List,访问控制列表)是由一系列permit或deny语句组成的、有序的规则集合, 它通过匹配报文的相关字段实现对报文的分类。
- ACL本身只是一组规则,只能区分某一类报文,换句话说,ACL更像是一个工具,当我们希望通过ACL 来实现针对特定流量的过滤时,就需要在适当的应用中调用已经定义好的ACL。
- ACL是一个使用非常广泛的工具,能够在多种场景下被调用。
ACL的主要使用场景:¶
- 被流量策略调用,用于过滤流量(可基于源、目的IP地址、协议类型、端口号等元素);
- 在route-policy中被调用,用于匹配特定的路由前缀,从而执行路由策略;
- 在VPN中调用,用于匹配感兴趣数据流;
- 在防火墙的策略部署中调用,用于匹配流量;
-
其他……。
ACL(Access Control List)称为访问控制列表,顾名思义它是一个列表形式的一组规则。ACL能够识别一个IP数据包中的源IP地址、目的IP地址、协议类型、源目的端口等元素,从而能够针对上述元素进行报文的匹配。例如一个网络设备在某个接口上源源不断地接收各种网络流量,现在我们希望对这些流量中的某些特定流量进行识别,以便做进一步的动作,那么就可以用到ACL了。此外,除了能够用于匹配数据,ACL还能够用于匹配路由,使得我们能够针对不同的路由部署不同的路由策略。
- 在VPN中调用,用于匹配感兴趣数据流;
- 在route-policy中被调用,用于匹配特定的路由前缀,从而执行路由策略;

上图显示的是一个编号为xxx的ACL,这个ACL中包含了多条规则(Rule),每条规则都有一个编号,所有的规则按照规则编号的大小进行排列,编号越小,排行越前。在每一个规则中,都可定义匹配条件,以及相应的允许/拒绝的动作。在ACL的执行过程中,设备从该ACL中拥有最小编号的规则开始进行计算与匹配, 如果被匹配对象满足该条规则中的匹配条件,则执行该条规则所定义的动作,并且不会再往下计算其他规则;而如果被匹配对象不满足该条规则中的匹配条件,则继续往下一条规则进行匹配。
- ACL 的分类
ACL可以使用一个数字来命名,例如ACL 2000,也可以使用一个字符串来命名,例如Test。我们在创建ACL
时,可以选择上述两种命名方式中的一种。
按照功能不同,ACL存在多种类型,其中最主要的两种是:
基本ACL¶
基本ACL只能够针对IP报文的源IP地址等信息进行流量匹配。例如我们可以使用基本ACL来拒绝源IP地址段为192.168.1.0/24的报文。如果在交换机上使用数字命名的方式创建一个基本ACL,那么数字的范围为2000~2999。
高级ACL¶
高级ACL能够针对IP报文的源IP地址、目的IP地址、协议类型、TCP源或目的端口、UDP源或目的端口等元素进行流量匹配。因此它的功能相较基础ACL要更丰富一些。
如果在交换机上使用数字命名的方式创建一个高级ACL,那么数字的范围为3000~3999。
- ACL 的配置
创建基本ACL¶
使用数字命名的方式创建一个基本ACL,并进入ACL视图:
在基本ACL中,创建一个rule的典型命令如下:
[Huawei-acl-basic-num] rule [ rule-id ] { deny | permit } [ source { source-address source-wildcard | any }] 如果不指定规则ID,则增加一个新规则时设备自动会为这个规则分配一个ID,ID按照大小排序。在上面 的配置中,wildcard通配符掩码的概念,其实我们在OSPF的配置中已经介绍过了,此处不再赘述。
创建高级ACL¶
使用数字命名的方式创建一个高级ACL,并进入ACL视图:
在高级ACL中,创建一个rule的典型命令如下。高级ACL可以用于匹配多种协议类型,例如OSPF、ICMP、
TCP、UDP、IP等等,此处以IP为例:
- ACL 配置实例(路由器)
基本ACL配置示例¶
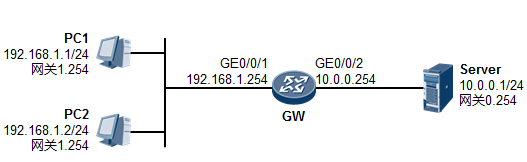
初始情况下PC1及PC2都能够访问Server。现在在GW的接口上应用ACL,使得PC2无法访问Server, 而其他用户都能够访问Server。
GW的配置如下:
高级ACL配置示例1¶
初始情况下PC1及PC2都能够访问Server。现在在GW的接口上应用ACL,使得PC2无法访问Server2, 放行其他流量。GW的配置如下:
高级ACL配置示例2¶
初始情况下PC1及PC2都能够访问Server。现在在GW的接口上应用ACL,只禁止PC2访问Server2的
Telnet服务,放行其他流量。
GW的配置如下:
- ACL 配置示例(交换机)

在S53交换机上完成ACL的配置,使得R1无法ping通R2,但其他的所有流量都放行。
完成配置后,R1无法ping通R2但是可以Telnet R2。
- 防火墙基础
- 防火墙概述
防火墙概述¶
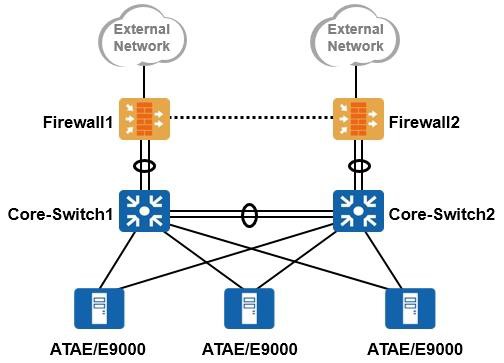
简单地说,防火墙的主要作用是划分网络安全边界,实现关键系统与外部环境的安全隔离,保护内部网络免受外部攻击。与路由器相比防火墙提供了更丰富的安全防御策略,提高了安全策略下数据报转发速率。由于防火墙用于安全边界,因此往往兼备NAT、VPN等功能,并且在这方面的相比路由器更加强劲。
防火墙分类¶
- 包过滤防火墙(Packet Filtering):包过滤利用定义的特定规则过滤数据包,防火墙直接获得数据包的IP源地址、目的地址、TCP/ UDP的源端口、和TCP/UDP的目的端口。包过滤防火墙简单,但是缺乏灵活性,对一些动态协商端口没有办法设置规则。另外包过滤防火墙每个包都需要进行策略检查,策略过多会导致性能急剧下降。
- 代理型防火墙(Application Gateway):代理型防火墙使得防火墙做为一个访问的中间节点,对客户端来说防火墙是一个服务器,对服务器来说防火墙是一个客户端。代理型防火墙安全性较高,但是开发代价很大。对每一种应用开发一个对应的代理服务是很难做到的,因此代理型防火墙不能支
持很丰富的业务,只能针对某些应用提供代理支持。
- 状态检测防火墙:状态检测是一种高级通信过滤,它检查应用层协议信息并且监控基于连接的应用层协议状态。对于所有连接,每一个连接状态信息都将被维护并用于动态地决定数据包是否被允许通过防火墙或丢弃。现在防火墙的主流产品都为状态检测防火墙。
- 防火墙的基础知识
7.2.2.1 安全区域的概念¶
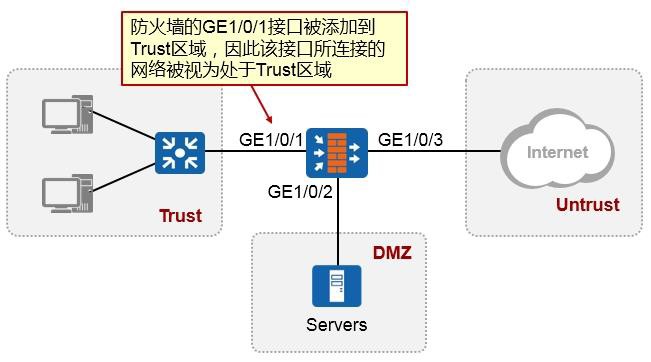
安全区域(Security Zone),简称为区域(Zone),是一个安全概念,许多安全策略都基于安全区域实施。我们在防火墙上创建安全区域,并且定义该安全区域的安全级别(也被称为优先级,通过1~100的数字表示,数字越大表示安全级别越高),然后将防火墙的接口关联到一个安全区域,那么该接口所连接的网络就属于这个安全区域。属于同一个安全区域的用户具有相同的安全属性。
在上图中,我们将防火墙的GE1/0/1接口添加到Trust区域中,那么这个接口所连接的网络就被视为处于Trust 区域。同理Internet被视为处于Untrust区域,而服务器Servers则处于DMZ区域。当图中的PC访问Internet时, 从PC发往Internet的流量到达防火墙后,防火墙认为这些流量是从Trust区域去往Untrust区域的流量。
华为Eudemon防火墙缺省已经创建如下安全区域:¶
| Zone | 优先级 | 描述 | ||
|---|---|---|---|---|
| Trust | 85 | 较高级别的安全区域,通常用于定义内网用户所在网络 | ||
| Untrust | 5 | 低级的安全区域,通常用于定义Internet等不安全的、外部的网络 | ||
| DMZ | 50 | 中度级别的安全区域,通常用于定义内网服务器所在区域。因为这些服务器虽然部署在内 | ||
| 网,但是经常需要被外网访问,存在一定的安全隐患,同时一般又不允许其主动访问外网, 所以将其部署一个安全级别比Trust低,但比Untrust高的安全区域中。 | ||
|---|---|---|
| Local | 100 | 最高级别的安全区域,Local区域定义的是设备本身,包括设备的各接口。凡是由防火墙自 身构造并主动发出的报文均可认为是从Local区域中发出,凡是目的地为防火墙的报文均可认为是由Local区域接收。用户不能改变Local区域本身的任何配置,包括向其中添加接口 |
需要注意的是,缺省已经创建的这些安全区域是不能被删除的。用户可以自行设置新的安全区域并定义其
安全优先级。
在以上安全区域中,很多人不太理解Local区域。下面来重点讲讲。
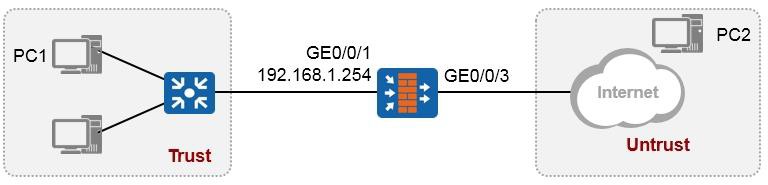
在上图中,防火墙的GE0/0/1接口被添加到Trust安全区域,GE0/0/3接口被添加到Untust区域。PC1发往
192.168.1.254的流量,被认为是从Trust区域到Local区域的流量(该流量的目的地就防火墙自身);PC1 访问PC2的流量,被认为是从Trust区域到Untrust区域的流量; 从防火墙直接访问(例如ping)PC1的流量,则被认为是从Local区域到Trust区域的流量。
安全区域的规划:¶
- 用户可自定义安全区域,也可使用系统自带的安全区域,防火墙的一个接口只能属于一个特定区域,而一个区域可以包含多个接口,接口只有划分到区域中才能正常处理报文。
- 内部网络应安排在安全级别较高的区域。外部网络应安排在安全级别最低的区域。
- 一些可对外部用户提供有条件服务的网络应安排在安全级别中等的DMZ区域。
安全区域的限制或注意事项:¶
- 在一台防火墙上不允许创建两个相同安全级别(Priority)的安全区域;
- 防火墙的接口必须加入一个安全区域,否则不能正常转发流量。
- 防火墙的一个接口只能属于一个安全区域;
- 防火墙的一个安全区域可以拥有多个接口;
- 系统自带的缺省安全区域不能删除,用户可以根据实际需求创建自定义的安全区域;
- 对于E1000E-N防火墙V1R1C30的系统软件版本而言,根系统最多支持100个安全区域(包括4个保留区域),每个虚拟系统最多支持8个安全区域(包括4个保留区域)。
区域间的概念¶
安全域间(Interzone)这个概念用来描述流量的传输通道,它是两个“区域”之间的唯一“道路”。如果希望对经过这条通道的流量进行检测等,就必须在通道上设立“关卡”,如ASPF等功能。任意两个安全区域都构成一个安全域间,并具有单独的安全域间视图。
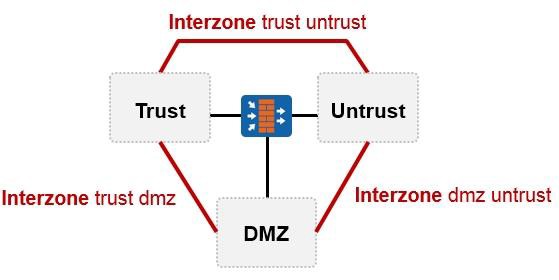
Inbound及Outbound¶
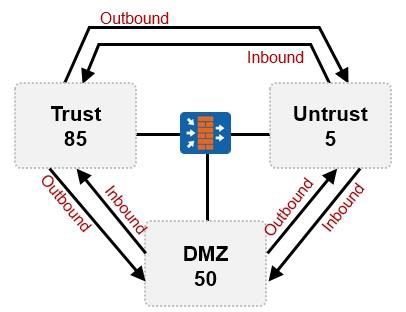
安全域间的数据流动具有方向性,包括入方向(Inbound)和出方向(Outbound):
- 入方向(inbound):数据由低级别安全区域向高级别安全区域传输的方向;
- 出方向(outbound):数据由高级别安全区域向低级别安全区域传输的方向。
安全策略¶
安全策略概述¶
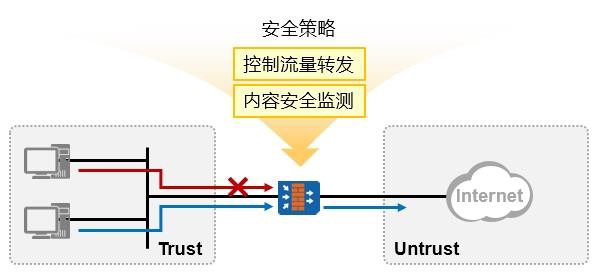
安全策略(Security Policy)是控制设备对流量的转发,以及对流量进行内容安全一体化检测的策略。
- 设备能够识别出流量的属性,并将流量的属性与安全策略的条件进行匹配。如果所有条件都匹配, 则此流量成功匹配安全策略,设备将会执行安全策略的动作(例如允许流量通行,或拒绝)。
- 内容安全一体化检测是指使用设备的智能感知引擎对一条流量的内容只进行一次检测和处理,就能实现包括反病毒、入侵防御和URL过滤在内的内容安全功能。
-
缺省情况下, NGFW的local区域到其他安全区域,以及域内的安全策略(如trust到trust)都是禁止的。
在日常中,安全策略最主要的应用之一,就是允许或拒绝流经防火墙的数据。安全策略在防火墙的
security-policy配置视图下完成,用户可以在该视图下根据需要创建安全规则(Rule)。
如上图所示,security-policy中可以包含多条规则,当安全策略中配置了多条规则时,设备将按照规则在界面上的排列顺序从上到下依次匹配,只要匹配了一条规则中的所有条件,则按照该规则中定义的动作、选项进行处理,不再继续匹配剩下的规则。所以在配置时,建议将条件更精确的规则配置在前面, 条件更宽泛的规则配置在后面。
关于安全策略中的规则¶
- 在一条规则的条件语句中,相同类型的条件内可以配置多个值,多个值之间是“或”的关系,报文的属性只要匹配任意一个值,就认为报文的属性匹配了这个条件。例如一条规则中指定了源IP地址
条件,那么用户可以指定多个源地址,报文只需要匹配其中一个地址,即被认为匹配该条件类型。
- 每条规则中可以包含多个匹配条件,如源、目的安全区域,源、目的地址,用户或应用类型等。各个匹配条件之间是“与”的关系,报文的属性与各个条件必须全部匹配,才认为该报文匹配这条规则。例如在某条规则中,定义了源地址与目的地址条件,那么报文必须同时匹配该源、目的地址才被视为匹配该条件。缺省情况下所有的条件均为any(也即该规则中没有定义任何条件时),即所有流量(包括域内流量)均可以命中该规则。
- 如果配置了多条安全规则,则设备会从上到下依次进行匹配。如果流量匹配了某个安全规则,将不再进行下一个规则的匹配。所以需要先配置条件精确的策略,再配置宽泛的策略。
- 设备默认存在一条缺省安全规则,如果不同安全区域间的流量没有匹配到管理员定义的安全规则, 那么就会命中缺省安全规则(条件均为any,动作默认为禁止)。
- 不同安全区域间传输的流量(包括但不限于从FW发出的流量、FW接收的流量、不同安全区域间传输的流量),受缺省安全策略控制,缺省转发动作为禁止。
- 同一安全区域内传输的流量不受缺省安全策略控制,缺省转发动作为允许。如需对域内流量进行转发控制,请配置具体的安全策略。
会话表¶
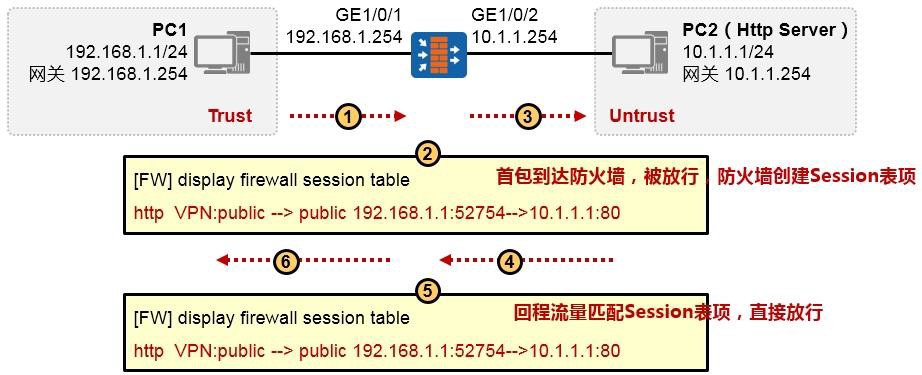
NGFW采用了基于“状态”的报文控制机制:只对首包或者少量报文进行检测就确定一条连接的状态,大量报文直接根据所属连接的状态进行控制。这种状态检测机制迅速提高了防火墙的检测和转发效率。
而会话表正是为了记录连接的状态而存在的。设备在转发TCP、UDP和ICMP报文时都需要查询会话表,来判断该报文所属的连接以及相应的处理措施。
查看会话表¶
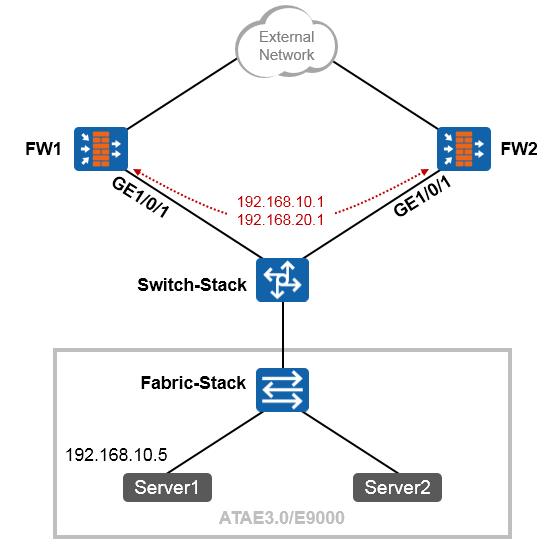
一个会话的报文能够正常被防火墙转发,通常需要具备以下几个条件:
- 防火墙的路由表中存在与该报文目的IP地址相匹配的路由,或者默认路由;
-
防火墙的安全策略允许该会话的报文通过。
当一个会话的报文被防火墙正常转发时,我们应该能够在防火墙上看到相应的会话表项(Session Entry)。
防火墙维护着一个非常关键的表项:会话表,每一个被防火墙允许的会话都能在其中找到相应的表项, 在表项中,我们能看到会话的源IP地址、目的IP地址、源端口号、目的端口号以及协议类型等信息,此外,还有该会话的入站区域、出站区域、去向报文个数以及回程报文个数等。
当网络出现故障时,可以通过查看防火墙的会话表进行基本的故障定位。例如上图所示,如果网络配置完成后,发现Server1无法ping通外部网络(External Network)中的10.8.8.8地址,而又无法直观地判断出问题出现在内部或者外部的情况下,可以在防火墙上查看会话:
-
使用**display firewall session table** 命令可以查看防火墙的会话表。从上述输出可以看到从
192.168.10.5访问10.8.8.8的会话,该会话的协议类型为ICMP。使用**display firewall session table**
**verbose**命令可以查看会话的详细内容:
HRP_A\<FW1> display firewall session table verbose
上面显示的是192.168.10.5 ping 19.8.8.8的会话详细。从中我们能发现这个会话是从Trust区域到
Untrust区域,出站接口为GE1/0/7,下一跳地址为10.1.1.2,另外该会话命中的是安全规则test1。关注红色字体部分,这部分显示的是这个会话的去向及回程的报文个数,从中我们能看到192.168.10.5发送了5个数据包出去,但是收到了0个数据包,因此从这个信息可以简单的判断出,192.168.10.5 ping
10.8.8.8的过程中,ICMP Request报文已经送达了防火墙,并且被它转发出去,同时防火墙没有收到回程的报文,因此问题可能并不出在内部。
在实际的项目中,防火墙的会话表项可能是非常多的,直接查看整个会话表,恐怕无法准确定位感兴趣的会话。可以在**display firewall session table verbose**命令后面增加一些关键字,达到筛选的目的。例如**display firewall session table verbose source inside 192.168.10.5**命令查看的是源IP地址
(inside关键字表示如果存在NAT,则为NAT之前的IP地址)为192.168.10.5的会话。再如**display firewall session table verbose service http**命令查看的是协议类型为HTTP(目的TCP端口号为80) 的会话。
如果在测试的过程中,发现在防火墙上找不到相应的会话表项,那么说明该会话的流量可能没有到达防火墙,或者到达了防火墙,但是防火墙没有相应的路由信息指导报文转发,又或者有路由信息但是该报文没有被安全策略放行等。此时需要进一步定位问题。
配置会话表的老化时间¶
当流量的第一个报文被防火墙转发时,防火墙会会话表老化时间决定一条会话在没有相应的报文匹配的情况下,何时被系统删除。当缺省的会话表老化时间不能满足现有网络的需求时,才需要重新设置。
对于一个已经建立的会话表表项,只有当它不断被报文匹配才有存在的必要。如果长时间没有报文匹配,则说明可能通信双方已经断开了连接,不再需要该条会话表项了。此时,为了节约系统资源,系统会在一条表项连续未被匹配一段时间后,将其删除,即会话表项已经老化。
如果在会话表项老化之后,又有和这条表项相同的五元组的报文通过,则系统会重新根据安全策略决定是否为其建立会话表项。如果不能建立会话表项,则这个报文是不能被转发的。
通常情况下,可以直接使用系统缺省的会话表老化时间。如果需要修改,需要首先对实际网络中流量的类型和连接数作出估计和判断。对于某些需要进行长时间连接的特殊业务,建议配置长连接功能(在下一个小节介绍),而不是通过以下命令将一种协议类型的流量的老化时间全部延长。
[FW] firewall session aging-time service-set session-type aging-time 使用上述命令修改某个特定服务的会话超时时间。例如命令:firewall session aging-time service- set ftp 1200,这条命令会针对所有FTP流量生效,将表项的老化时间修改为1200s。该命令需谨慎配置。
[FW] display firewall session aging-time
使用上述命令查看当前系统中各类会话表项的老化时间。
7.2.2.6 长连接¶
防火墙采用会话表来管理数据流,通过首包创建会话表项后,后续报文如果命中会话表项,则根据该表项进行转发。如果某个报文既不是首包,又没有命中会话就会被丢弃。而为了保证网络安全以及会话资源的合理利用,设备上的各种会话缺省老化时间都相对较短,一般只有几分钟。当一个TCP会话的两个连续报文到达设备的时间间隔大于该会话的老化时间时,设备将从会话表中删除相应会话信息。后续报文到达设备后,设备根据自身的转发机制,将丢弃该报文,导致连接中断。
在某些实际应用中,一个TCP会话的两个连续报文可能间隔时间很长。例如:用户需要查询数据库服务器上的数据,这些查询操作的时间间隔远大于TCP的会话老化时间。
为了解决FTP服务、网管服务、TUXEDO服务和数据库服务等业务的这个问题,在安全域间配置长连接功能,可以对特定的数据流设置超长老化时间,保证这些应用的会话表表项不被删除,这样当这些会话的报文长时间没有到达设备后再次到达时,仍然能够通过设备。从而使这些应用不被中断。
对于NGFW,长连接功能在安全规则配置视图下激活,例如:
- 防火墙的基础配置
防火墙登陆及管理¶

防火墙的接口服务管理¶
接口配置视图下的**service-manage**命令用来允许或拒绝管理员通过HTTP、HTTPS、Ping、SSH、SNMP 以及Telnet**访问防火墙自身**,该命令配置在防火墙的接口上。
在接口上启用访问管理功能后,即使没有开启该接口所在区域和Local区域之间的安全策略,管理员也能通过该接口访问设备。缺省情况下,管理接口(GE0/0/0)允许管理员通过HTTP、HTTPS、Ping、SSH、SNMP 以及Telnet访问设备,非管理接口不允许管理员通过HTTP、HTTPS、Ping、SSH、SNMP以及Telnet访问设备。
只有在报文的入接口开启了访问管理功能,才可以通过对应的接口访问防火墙。例如需要访问防火墙的
GE1/0/2接口,但报文从GE1/0/1接口进入设备,此时必须开启GE1/0/1接口的访问管理功能,方可以访问
GE1/0/2接口。
接口下**service-manage**的优先级高于安全策略(Security-policy)。例如虽然安全策略没有放通接口GE1/0/1所在区域访问Local接口的ping流量,但是GE1/0/1下配置了**service-manage ping permit**,则所在区域内的用户依然能ping通该接口的IP地址。当然如果GE1/0/1接口下配置了**service-manage ping deny**,则即使安全策略中配置了相应的规则允许ping流量,所在区域内的用户也无法ping通该接口,除非将**service-**
manage功能关闭(undo service-manage enable)。¶
接口及安全区域配置¶
网络拓扑如上图所示,完成防火墙接口IP地址配置,并将接口添加到相应的安全区域。其中,GE1/0/2口添加到新建的安全区域om。
SSH服务配置¶

PC连接在FW的GE1/0/1接口上,配置与防火墙相同网段的IP地址。现在要求PC能够通过SSH的方式,访问
FW的GE1/0/1接口从而SSH到防火墙。
安全策略的基础配置¶
下图通过简单的方式展示了安全策略(Security-policy)与安全规则(Security rule)的关系:
下图是一个简单的安全规则配置范例:

下面,再看几个例子:
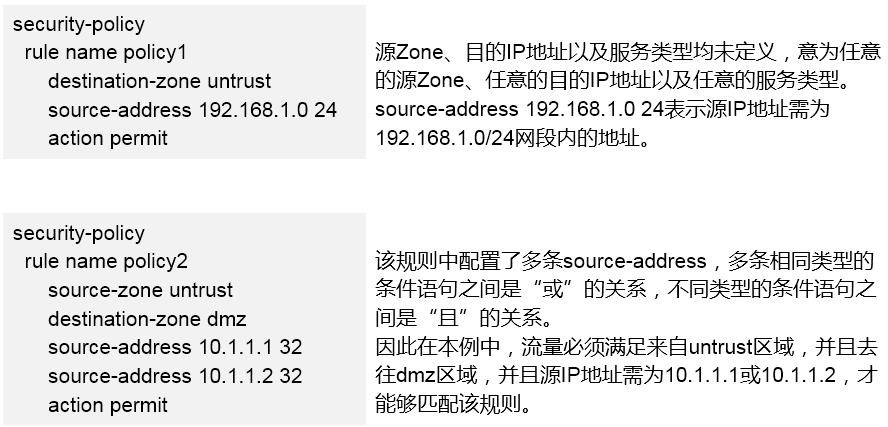
用户可以在防火墙的Security-Policy视图下,定义多个rule,来满足不同的业务需求。
系统默认存在一条缺省安全规则,如果流量没有匹配到管理员定义的安全规则,就会命中缺省安全策略(条件为any,动作默认为deny)。
在安全策略中使用对象¶
在防火墙中,对象的类型有多种,例如地址对象、服务对象、应用对象等等。在设备配置过程中,例如为防火墙配置安全策略,如果不同的安全规则中,需要频繁使用到一个相同的地址范围,这个地址范围内包含多个地址,那么重复在这些规则中书写这些地址是很繁琐的,另外,如果这个地址范围要变更,那么所有相关的规则都需要进行配置,增加了工作量。
我们可以将这些地址关联到一个地址对象中,然后直接在安全策略里调用该地址对象即可。当需要调整地址范围时,也只需对地址对象进行修改。在安全策略的配置过程中,主要使用到的对象有两种:地址对象及服务对象。在华为防火墙上,使用**ip address-set**命令可以创建地址对象,使用**ip service-set**命令可以创建服务对象。对象创建完成之后,用户可以在安全规则中引用它。以下通过一个简单的场景,以及一些简单的配置来了解对象的应用。
| 需求 | 防火墙安全策略配置 | 备注 | |
|---|---|---|---|
| Trust 区域的PC1 及PC2 都能 访 问 DMZ 中的 PC3 的 Telnet服务 | security-policy rule name test1 source-zone trust destination-zone dmz source-address 192.168.10.5 32 source-address 192.168.10.6 32 destination-address 192.168.20.11 32 service telnet action permit | 本例中,两条source-address之间是“或”的关系。 | |
| Trust 区域的PC1 及PC2 都能 访 问 DMZ 中的 PC3 的 Telnet服务,使用地址对象完成上述需求 | ip address-set add1 type object address 192.168.10.5 mask 32 address 192.168.10.6 mask 32 security-policy rule name test1 source-zone trust destination-zone dmz destination-address 192.168.20.11 32 source-address address-set add1 service telnet action permit | 创建地址对象后,可以将一个或多个地址,或地址范围添加到该对象中,并在安全策略中调用,从而简化配置 | |
| Trust区域的任意PC都能访问 DMZ 中 的 PC3 的 TCP9931端口,使用服务对象完成上述需求 | ip service-set port1 type object service protocol tcp destination-port 9931 security-policy rule name test1 source-zone trust destination-zone dmz destination-address 192.168.20.11 32 service port1 action permit | 服务代表了流量的协议类型。创建服务对象后,可以将一种或多种协议类型,或者TCP/UDP端口号添加到该对象中,并在安全策略中调用,从而简化配置 |
|---|---|---|
| Trust区域的任意PC都能访问 DMZ 中 的 PC3 的 TCP9931 、 TCP9932 、 TCP9933、UDP2281端口 | ip service-set port1 type object service protocol tcp destination-port 9931 to 9933 service protocol udp destination-port 2281 security-policy rule name test1 source-zone trust destination-zone dmz destination-address 192.168.20.11 32 service port1 action permit |
防火墙的OSPF配置¶
- ATAE3.0/E9000机框通过Fabric交换板堆叠组连接到防火墙。
- Server的缺省网关设置为FW的GE1/0/1接口。
-
完成FW 的配置, 与SW 建立OSPF 邻接关系, 交互OSPF 路由。使得SW 能够从OSPF 获知到达
192.168.10.0/24的路由。
FW的配置如下:
完成上述配置后,首先查看一下OSPF邻接关系的建立情况:
再看一下SW的路由表:
SW已经通过OSPF学习到了192.168.10.0/24的路由。此时Server即可ping通SW(10.1.1.2)。
防火墙基础配置示例¶
- 防火墙的三个接口的IP地址如图所示;
- 完成接口配置,并将防火墙的接口添加到相应的安全区域;
- 完成防火墙的安全策略配置,使得PC1能够主动访问PC2,但是PC2无法主动访问PC1;
-
完成防火墙的安全策略配置,使得PC2能够主动访问WebServer的WEB服务。防火墙的配置如下:
完成上述配置后,PC1即可主动发起访问PC2,而PC2无法主动访问PC1;另外,PC2能够访问WebServer
的HTTP服务。
报文捕获¶
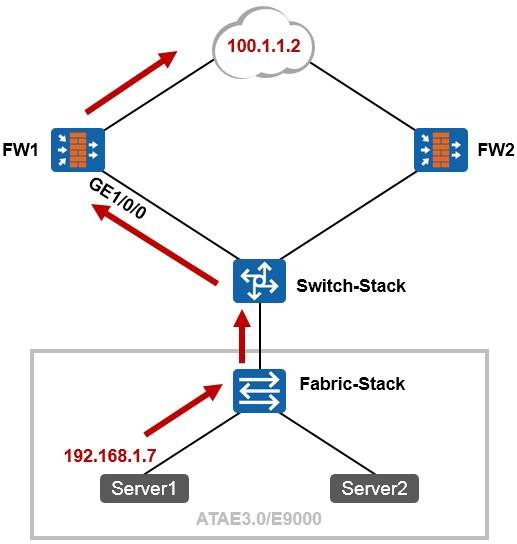
在某些情况下,我们可能需要在防火墙上进行抓包,并对捕获的报文进行分析,此时可以在防火墙上配置五元组抓包。例如在上图中,在防火墙FW1上捕获Server1发往100.1.1.2的报文。
FW1的配置如下:
完成上述配置后,可以在FW1上查看生效的配置:
HRP_A[FW1]display packet-capture configuration
| capture number: 1000 | capture mode: verbose | send mode: manual | |
|---|---|---|---|
| interface-name | packet-direction | acl-number queue-id | capt-type |
| GigabitEthernet1/0/0 | inbound | 3001 0 | IPv4 |
| GigabitEthernet1/0/0 | outbound | 3001 0 | IPv4 |
现在,FW1将会开始抓取符合条件的报文。此时如果Server1 ping 100.1.1.2,而且ping了5个报文,那么可
以在FW1上看到如下信息:
现在,这些报文已经被FW1缓存在队列0中,如果要将报文保存下来进行分析,则可以将队列0中的报文保存在FW1的磁盘空间中,形成*.cap文件,例如保存为pkt222.cap文件。
HRP_A[FW1] packet-capture queue 0 to-file pkt222.cap
此时使用dir命令,可以查看到该文件:
| HRP_A\<FW1>dir Directory of hda1:/ | |||||
|---|---|---|---|---|---|
| Idx | Attr | Size(Byte) | Date | Time | FileName |
| 0 | -rw- | 119309177 | Jan 13 2014 | 17:39:02 | suampua10v1r1c00spc100.bin |
| 1 | -rw- | 61 | Jun 26 2017 | 10:28:58 | private-data.txt |
|---|---|---|---|---|---|
| 2 …… | drw- | - | Jan 13 2014 | 17:48:10 | isp |
| 21 | -rw- | 594 | Jul 11 2017 | 11:38:34 | pkt222.cap |
通过FTP/SFTP等方式从FW1上下载该文件,即可对报文进行分析。
完成抓包后,需要进行如下操作:
注意事项:¶
- 配置五元组抓包会在一定程度上影响设备性能,因此通常只在网络问题定位时使用。在网络问题定位结束后,必须停止抓包进程,并且清空抓包队列,释放内存。
- 启动抓包需在数通工程师的指导下进行,并选择业务流量较小的时间进行,以防操作失误引起业务中断。禁止随意开启抓包。
-
命 令 packet-capture { no-ip-packet | all-packet | ipv4-packet acl-number | ipv6-packet acl6- number } [ inbound | outbound ] [ queue queue-id ] interface interface-type interface-number用于配置抓包接口、方向以及该接口用来存储抓包的队列。缺省情况下,同时抓取入方向和出方向的报文,存储抓包的队列为0。设备提供四个队列用于存储抓取的报文。设备单次单向最大抓包数目为
1000个报文。出入方向最多各存储1000个报文,每个队列最多存储共2000个,队列报文超过2000 后,新的报文将被丢弃,不再进入队列。在队列存储到2000个报文以后如需重新抓包,可以配置该接口另一个队列,或者使用reset packet-capture queue queue-id命令清空该队列。
- 在本例中,只要Server1发往100.1.1.2的报文到达FW1的GE1/0/0接口,便会被捕获,即使FW1的安全策略并未允许Server1主动访问100.1.1.2。
- NAT
- NAT 概述
-
- 启动抓包需在数通工程师的指导下进行,并选择业务流量较小的时间进行,以防操作失误引起业务中断。禁止随意开启抓包。
NAT(Network Address Translation,网络地址转换)是缓解IPv4公网地址枯竭的一个重要功臣,通过在网络设备上部署NAT,网络设备能够对特定报文的IP地址和(或)端口号进行转换。
IP地址有两种类型:公网及私网(Public and Private)。其中私网IP只能在本地网络(局域网)中使用,不能直接访问公网(Internet),这意味着局域网PC要访问公网就必须拥有公网IP,而公网IP资源本身就非常稀缺,那么,能否在局域网内统一部署私网IPv4地址空间,然后又能够让网内用户访问Internet呢?NAT技术能够对IP报文中的源或目的地址进行转换,从而当源地址为私网IP地址的数据包到达网络出口时,由NAT 设备对私网地址进行转换,转换成一个合法的公网IP并将数据包转发到公网,而当回程数据包到达时,又将目的IP修改为此前的那个私网IP地址。
NAT的优缺点:¶

- NAT 类型详解
我们简单的将NAT分为两类:
源IP地址转换(Source IP address-based NAT):¶
- No-Port地址转换(No-Port Address Translation,No-PAT)
- 网络地址及端口转换(Network Address Port Translation,NAPT)
目的IP地址转换(Destination IP address-based NAT):¶
- NAT Server
- 目的NAT
7.3.2.1 NAT类型1:源IP地址转换之No-PAT¶
No-PAT也可以称为“一对一地址转换”,在地址转换过程中,数据包的源IP地址由私网地址转换为公网地址,但端口号(TCP或UDP端口号)不做转换。设备会将转换前后的地址的所有端口进行一一对应。这种应用的优点是私网地址的所有端口不做转换,缺点是该公网地址不能被其他私网地址使用,也就是一个私网地址需独占一个公网地址。例如,若地址池中的公网IP地址只有2个,由于一台私网主机在借用其中的一个公网IP访问公网时会占用这个IP的所有端口,因此这种情况只允许最多有两台私网主机同时访问公网,其他的私网主机要等到其中一台主机不再访问公网且它占用的公网IP地址被释放后,才可再进行公网访问。

以上图为例,假设网络管理员申请到一个公网地址(200.1.1.100),并且在防火墙上部署No-PAT。现在
192.168.1.1这台PC要访问公网的8.8.8.8,始发数据包的源目的IP地址如图所示。数据包到达了防火墙后, 防火墙根据NAT映射表项,将源地址192.168.1.1修改为200.1.1.100(端口号不转换),然后将报文转发出 去,这个报文在Internet中最终被转发到8.8.8.8。现在8.8.8.8要回复报文,数据包的目的地址为200.1.1.100
(注意,公网是无论如何也不知晓192.168.1.1存在的)。这个数据包到达了防火墙后,防火墙根据NAT映射表项,将目的IP修改为192.168.1.1并转发出去,最终,这个数据包回到了192.168.1.1。这就是NAT一对一映射的工作原理。从上面的描述可以看出来,其实这种NAT类型并没有缓解公网IP地址耗尽的问题,因为你如果有10台内网PC要访问公网,相当于要有10个公网IP。
在实际的部署中,我们可能会使用基于IP地址池的No-PAT,也就是将申请到的一个或多个公网IP地址放置在一个IP地址池中,然后将该地址池应用于源地址转换。此时当某个内网设备发送的报文需要进行NAT时, 防火墙将会从地址池中选择一个空闲的地址,并创建一个NAT映射表项,然后对报文的源IP地址进行转换。而当另一个设备需要访问外网时,防火墙从地址池中选择另一个空余的公网地址。这种方式实际上还是一个私网地址对一个公网地址的映射关系。
7.3.2.2 NAT类型2:NAPT¶
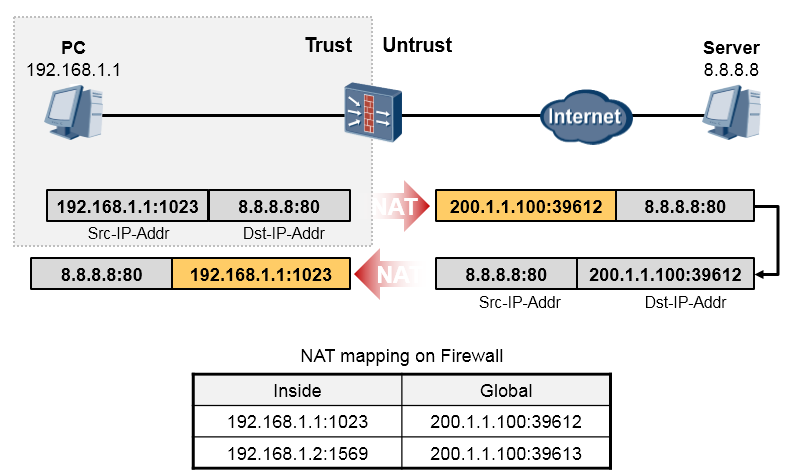
NAPT是指在进行NAT转换IP地址的同时,还对端口号进行转换,这种技术可以实现多个私网用户共用一个公网IP。NAPT也被称为“地址复用”,通过配置NAPT功能,网络设备将同时对报文的端口号和IP地址进行转换,允许多个私网IP地址同时映射到同一个公网IP地址,该公网IP地址通过不同的端口号区分不同的私网IP地址,从而实现多对一或多对多的地址转换。正是这种解决方案极大的缓解了公网IP地址紧缺的问题。我们仅需购买一个或多个公网IP地址,即可满足内网大量PC同时访问公网的需求。
在上图中,内网地址192.168.1.1及192.168.1.2在访问外部网络时,共用200.1.1.100这个公网地址。当
192.168.1.1 以TCP 源端口号1023 向外网发送报文时, 防火墙为该会话创建一个NAT 映射表项, 将
192.168.1.1:1023映射到200.1.1.100:39612,然后将报文的源IP地址及源TCP端口号进行转换,再将转换后的报文发送出去,当防火墙收到回程的报文时,也会根据NAT映射表项,将回程报文的目的地址及端口号进行转换。而当内网地址192.168.1.2使用TCP源端口号1569访问外部网络时,防火墙则将这个会话映射到
200.1.1.100的39613端口,从而通过端口号对这两个会话进行区分。
7.3.2.3 NAT类型3:NAT Server¶
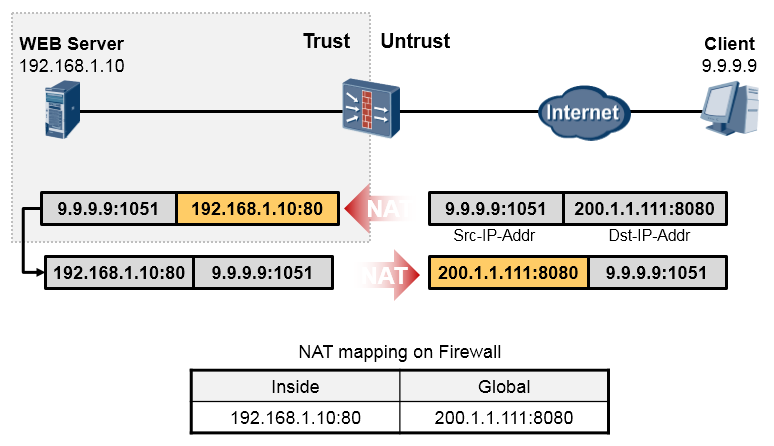
NAT Server是最常用的目的地址转换技术。我们经常能见到这样的场景:内网存在一台使用私网IP地址的服务器,例如WEB服务器,这台服务器如果需对外网提供服务,那么外网的用户显然是不可能使用该服务器的真实IP地址对其进行访问的。此时即可使用NAT Server,将该私网IP地址映射到一个特定的公网地址, 从而使得公网用户能够通过访问该公网地址从而访问内网服务器。具体示例如上图所示。
NAT Server使得内部服务器可以供外部网络访问。外部网络的用户访问内部服务器时,NAT将请求报文的目的地址转换成内部服务器的真实地址(私网地址)。对于内部服务器的回应报文,NAT还会自动将报文的源地址(私网地址)转换成公网地址。
在上图中,内网服务器192.168.1.10(的TCP80端口)需要对外提供访问,可在防火墙上部署NAT Server
将 192.168.1.10 的 TCP80 端口 映射到 200.1.1.100 的 TCP8080 端口 。 如 此 一来 ,当公网用户 访问
200.1.1.100:8080时,实际上访问的就是该内网服务器的WEB服务。
- NAT 在防火墙(NGFW)上的部署
基于地址池的源地址NAPT¶
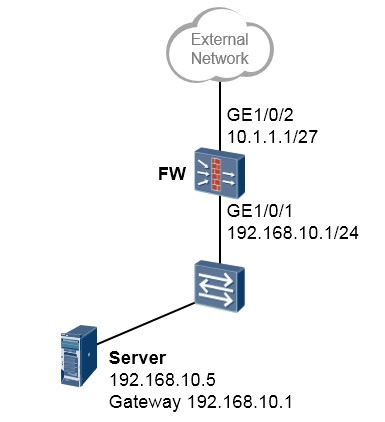
如上图所示,Server通过交换机连接到防火墙,Server的缺省网关设置为FW的GE1/0/1接口。出于安全的考虑,要求Server访问外部网络(External Network)时,源IP地址需被转换,转换成10.1.1.5至10.1.1.10这个范围内的IP地址。
FW的关键配置如下:
完成上述配置后,当Server(例如192.168.10.5)访问外部网络(例如ping 10.1.1.2)时,可以看到类似如下会话表项:
以上中括号内的IP地址,就是将源IP地址192.168.10.5被转换后所使用的IP地址。
NAT Server¶
如上图所示,Server通过交换机连接到防火墙,Server的缺省网关设置为FW的GE1/0/1接口。出于安全的考虑,我们并不希望服务器单板的真实IP地址暴露在外部网络,但是又希望某些服务器能够被外部网络访问。可在FW上部署NAT Server,以192.168.10.5这台内部服务器为例,将其映射到外部网络IP地址10.1.1.11, 使得外部网络用户能够通过访问该IP地址,从而访问192.168.10.5。
此处假设Server处于Trust安全区域,External Network处于Untrust区域。
完成上述配置后,当外部网络用户(例如10.1.1.2)访问10.1.1.11(例如ping 10.1.1.11)时,可以在FW上
看到如下会话表项:
以上中括号中的地址,就是被NAT转换后的目的IP地址。
NAT Server的几种配置场景¶
命令**nat server s1 zone untrust global 10.1.1.11 inside 192.168.10.5**用于创建一个NAT Server,名称为
s1(可自定义),该命令将内部IP地址192.168.10.5映射到外部IP地址10.1.1.11,如此一来,处于untrust区域的用户访问目的IP地址10.1.1.11时,报文的目的IP地址会被转换成192.168.10.5。
NAT Server命令存在多种配置变化,不同的配置方式适用于不同的业务场景,以下将分别进行说明:
配置方式一:¶

[FW] nat server s1 global 200.1.1.100 inside 172.16.1.1 这种NAT配置方式相当于IP一对一映射,也即当FW收到发往200.1.1.100的报文(任意目的端口号),都会 将其目的地址转换成172.16.1.1。而当防火墙收到Server(172.16.1.1)主动发出的、访问Client的报文,也会将源地址转换成200.1.1.100。所以采用这种配置方式,Internet用户能够访问Server,而Server也能够主动访问Internet。
配置方式二:¶

[FW] nat server s2 zone untrust global 200.1.1.100 inside 172.16.1.1 在“配置方式一”的基础上,增加了**zone**关键字和参数**untrust**,则该条NAT Server只向untrust区域产生作用,也就是只有在该区域的接口上收到的报文,才会进行目的地址转换。
配置方式三:¶
[FW] nat server s3 zone untrust protocol tcp global 200.1.1.200 22323 inside 172.16.1.1 8080 增加了**protocol**关键字及**tcp**参数,则当FW在其untrust接口收到发往200.1.1.200:22323的TCP报文时,FW 会将报文的目的IP地址转换成172.16.1.1、将目的TCP端口号转换成8080。
配置方式四:¶
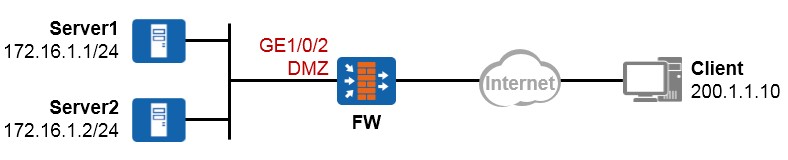
多个不同内部服务器(如上图中的Server1、Server2)使用一个公网IP地址对外发布时,可以多次使用nat
server命令对其进行配置,但是global-port(以上配置中标记红色的参数)不能相同。如此一来Client访问
200.1.1.200:21111时,实际访问的就是Server1,而访问200.1.1.200:21112时,实际访问的就是Server2。
配置方式五:¶
对于同一个内部服务器发布多个公网IP供外部网络访问的场景,如果不同公网IP所在的链路规划在不同的安全区域,可以通过配置针对不同的安全区域发布不同的公网IP的NAT Server来实现。
配置方式六:¶
对于同一个内部服务器发布多个公网IP供外部网络访问的场景,如果不同公网IP所在的链路规划在同一个安全区域,可以通过配置指定**no-reverse**参数的NAT Server来实现。指定**no-reverse**参数后,可以配置多个global地址和同一个inside地址建立映射关系。
指定**no-reverse**参数后,内部服务器主动访问外部网络时,设备无法将内部服务器的私网地址转换成公网地址,内部服务器也就无法主动向外发起连接。因此,通过指定**no-reverse**参数可以禁止内部服务器主动访问外部网络。由于配置了**no-reverse**参数,内部服务器将无法主动访问外部网络。此时,如果内部服务器想要访问外部网络,需要在内部服务器所在区域和外部网络所在区域的域间配置源NAT策略,将服务器的私网地址转换为公网地址。源NAT策略中引用的地址池可以是global地址也可以是其他的公网地址。
内网PC通过NAT server公网地址访问内部服务器¶
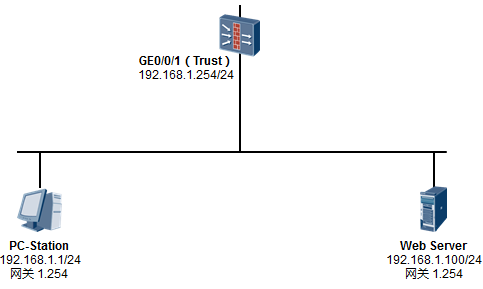
在上图所示的网络中,PC-Station及Server同属一个LAN,网关都在防火墙FW的GE0/0/1口上,都属于trust 区域。为了让Internet用户(在图中并未画出)能够访问Server,FW上部署了Nat Server,命令如下:nat server s1 global 200.1.1.100 inside 192.168.1.100,也就是将公网地址200.1.1.100映射到192.168.1.100。
完成上述配置后,Internet用户能够通过200.1.1.100这个公网IP访问Server。但是内网的PC-Station在访问
Server的时候,却存在一点问题:PC-Station通过目的私网IP地址192.168.1.100能够访问Server的Web服务,但是当PC-Station使用该服务器映射后的公网地址200.1.1.100试图访问Server的时候,却发现始终无法成功。我们来分析一下PC-Station使用公网地址访问Server的过程:
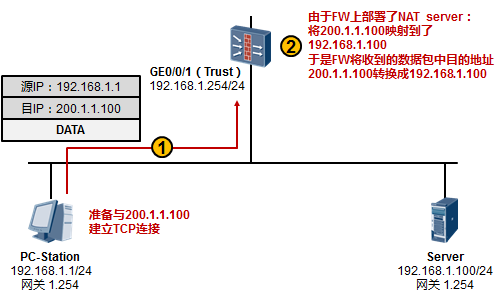
-
PC-Station去访问地址200.1.1.100, 首先要建立TCP三次握手, TCP握手报文的源IP地址为
192.168.1.1,目的地址为200.1.1.100,数据包被送到网关防火墙。
- 由于防火墙部署了NAT server,因此它将数据包的目的IP 200.1.1.100转换成192.168.1.100,然后
查找路由表,发现目的网络192.168.1.0/24就是GE0/0/1口直连。
- 防火墙将地址转换后的数据包发向Server。
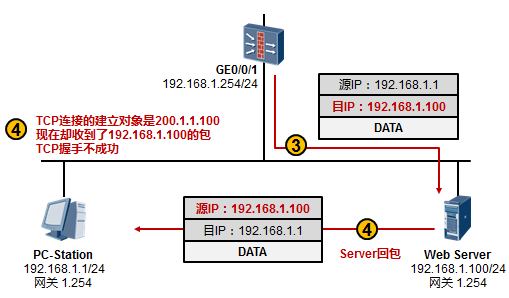
- Server收到数据包后,得回包吧,由于Web Servre收到的这个数据包源地址为192.168.1.1,因此它在产生回程数据包的时候,回程数据包的目的地址就是192.168.1.1,而192.168.1.1又是本地直连网络内的节点IP,因此Web Server直接将这个源为192.168.1.100,目的地址为192.168.1.1的数据包发送给了PC-Station,而不会再绕回FW。
-
PC在收到这个数据包的时候,发现数据包的源地址是192.168.1.100,这个地址是哪里冒出来的? 它等候的是200.1.1.100的回程报文,可是现在却收到了192.168.1.100的数据包,于是它将该报文丢弃。
这就是为什么,PC无法通过服务器的NAT server映射的公网IP来访问服务器的原因。数据包没有绕回FW, 导致PC收到的回程数据包的源地址没有被正确转换,从而导致TCP三次握手不成功。要解决这个问题,就需要让回程的流量能够回到FW,然后让FW将源地址转换成200.1.1.100再发给PC。
我们可以通过在FW上为PC创建一个NAT池,然后部署trust安全域内的源地址转换即可:
-
完成上述配置后,我们再分析一下数据包交互的过程:
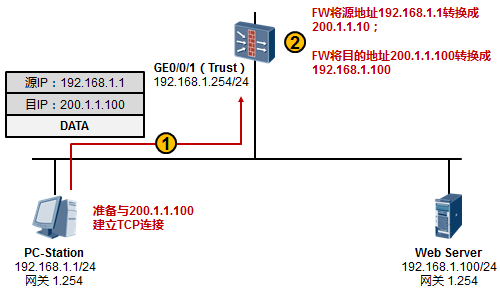
- PC试图访问200.1.1.100,首先要建立TCP三次握手,TCP握手报文的源IP地址为192.168.1.1,目的地址为200.1.1.100,数据包被送到网关防火墙。
-
由于防火墙部署了NAT Server以及源地址转换,因此它将数据包的源IP地址192.168.1.1转换成
200.1.1.10,目的IP地址200.1.1.100转换成192.168.1.100。
-
防火墙将地址转换后的数据包发向Server:
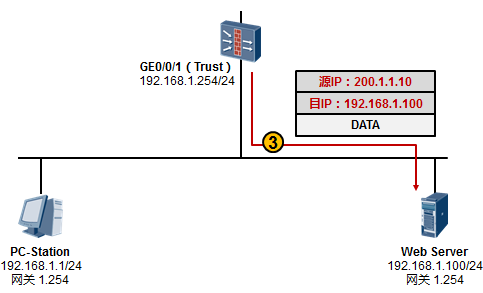
- 服务器收到数据包后要发回程报文,回程报文的源地址为192.168.1.100,目的地址为200.1.1.10, 这个数据包被发向了Server的网关192.168.1.254,也就是防火墙。
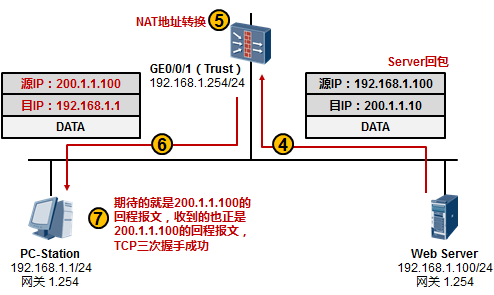
-
防火墙收到这个数据包后,由于本地已经有了NAT 的映射条目, 因此将数据包的源地址
192.168.1.100替换成200.1.1.100,将目的地址200.1.1.10替换成192.168.1.1。
-
FW将数据包转发给PC。
- PC收到这个数据包后,发现正是自己期待的200.1.1.100的回包,因此TCP三次握手成功。
7.3.4 NAT 在路由器上的部署
7.3.4.1 静态NAT映射¶
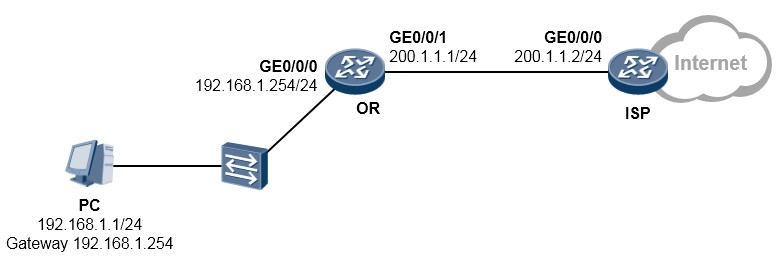
在上图中,OR是出口路由器,它连接着内网PC及Internet。现在内网的PC需要访问Internet,在OR上部署静态一对一IP映射使得PC能够访问外网,分配给内网PC 192.168.1.1 的公网地址是200.1.1.100。
OR路由器的配置如下(省略接口IP地址的配置):
上述配置中,**nat static global 200.1.1.100 inside 192.168.1.1**命令即配置静态NAT映射,将内网IP地址
192.168.1.1映射到200.1.1.100。如此一来,当源IP地址为192.168.1.1的报文准备从OR的GE0/0/1接口发送出去时,路由器将该地址转换成200.1.1.100。另外,当目的IP地址为200.1.1.100的报文到达OR路由器的
GE0/0/1接口时,报文的目的IP地址会被转换成192.168.1.1。
基于动态地址池的No-PAT¶
在上图中,OR是出口路由器,它连接着内网PC及Internet。现在内网192.168.1.0/24网段的用户需要访问
Internet,该网络从运营商申请到的公网地址区间是200.1.1.100 – 200.1.1.116,完成基于地址池的No-PAT
配置,使得内网用户能够访问Internet。
OR路由器的配置如下(省略接口IP地址的配置):
基于动态地址池的NAPT¶
在上图中,OR是出口路由器,它连接着内网PC及Internet。现在内网192.168.1.0/24网段的用户需要访问
Internet,该网络从运营商申请到的公网地址区间是200.1.1.100 – 200.1.1.105,完成基于地址池的NAPT配置,使得内网用户能够访问Internet。
OR出口路由器的配置如下(省略接口IP地址的配置):
源地址转换中,NAPT的配置与No-PAT的配置差异很小,需要格外留意。一般在项目中使用NAPT的方式较
多,毕竟这种方式可以实现多个私网IP地址共用一个公网IP地址的需求。
NAT Server¶
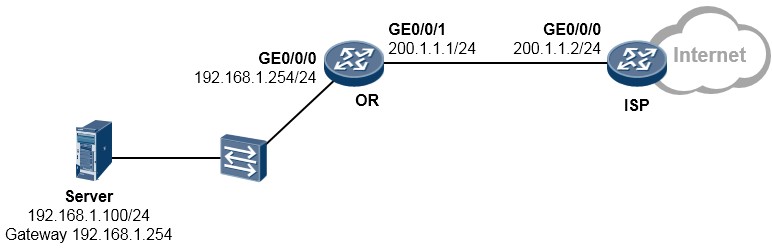
在上图中,OR是出口路由器,它连接着内网Server及Internet。内网有一台WEB服务器192.168.1.100,其
TCP80端口需要面向Internet提供服务,该网络从运营商申请到的公网地址是200.1.1.30,在路由器上完成NAT Server的配置,使得Internet用户能够通过访问200.1.1.30:8080,从而访问192.168.1.100:80。
OR路由器的配置如下(省略接口IP地址的配置):
- 防火墙双机热备
- 防火墙双机热备概述
技术背景¶
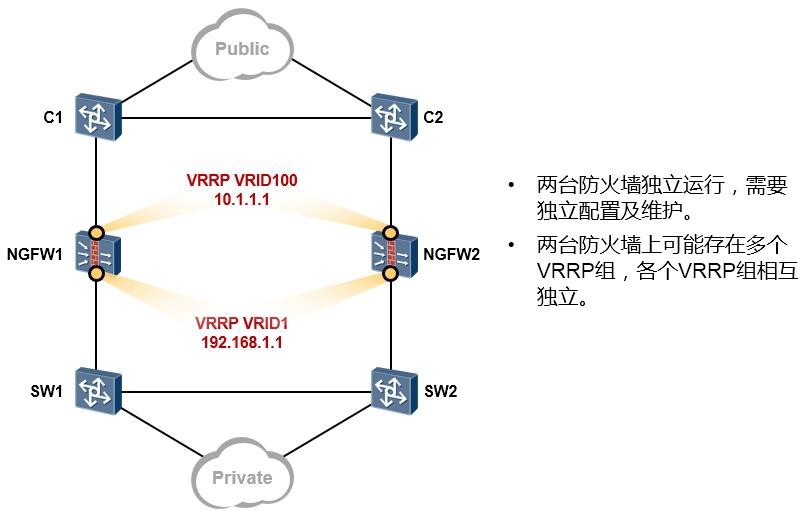
上图是一个典型的组网环境。我们来看一下如果没有双机热备技术,网络中可能会存在什么问题。
首先两台防火墙(NGFW1和NGFW2)是独立的网络设备,需要独立配置及管理,包括安全策略、对象、NAT策略、地址池等都需要分别进行配置,无法同步。此外,本场景中可能部署了VRRP,如上图所示,网络中存在2个VRRP组,分别用于上行和下行,这两个VRRP组的状态是独立的。下行的设备
(SW1/SW2)将到达Public的路由的下一跳指向VRRP VRID1的虚拟IP地址192.168.1.1,而上行的设备(C1/C2)则将到达Private的路由的下一跳指向10.1.1.1。
当这两个VRRP组的状态一致时(例如主设备都为NGFW1、备设备都为NGFW2),上、下行的数据转发是不会有问题的。在NGFW1首次收到一个上行流量的报文时,它会为这个流量创建一个会话表项, 当回程的报文发送到NGFW1的时候,由于流量命中了会话表项,因此被放行,这样,数据的通信是没有问题的。
然而如果流量的往返路径不一致的话,就会出现问题了。防火墙是基于会话表进行报文检测的,NGFW2没有收到上行流量的话,就不会建立相关会话表项,此时当它收到回程流量的时候,由于没有任何匹配的会话表项,因此这些流量最终将被丢弃,这就导致了断网,如下图所示。
造成这种现象的典型问题是VRRP组的状态不一致,例如VRRP VRID1的主设备为NGFW1,而VRRP
VRID100的主设备却为NGFW2。之所以会有这样的问题,根因是两台防火墙并非一个统一的系统,进而两组VRRP互相独立,无法协同配合。
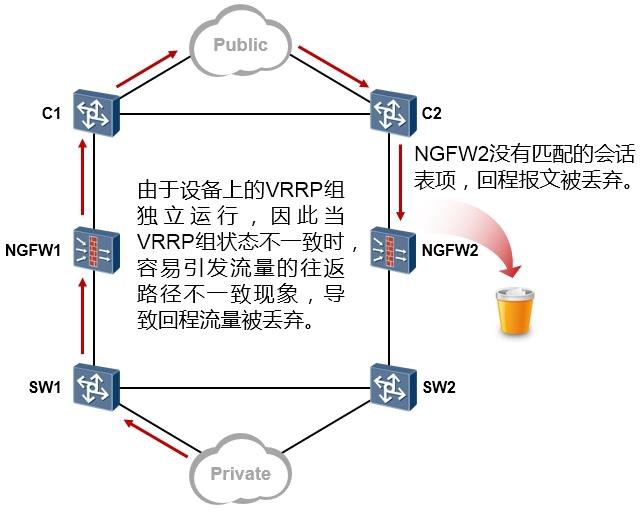
双机热备主要功能组件¶
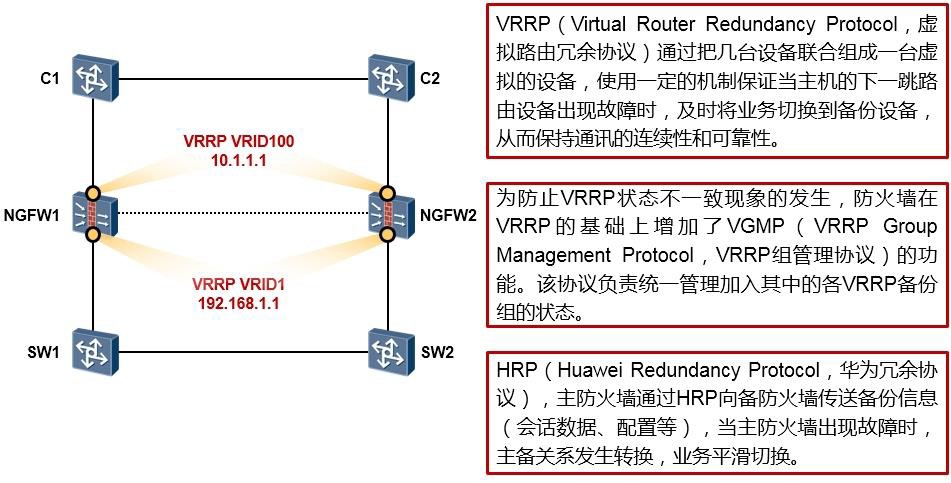
- 防火墙双机热备基础
VRRP¶
VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议)是一种应用非常广泛的网关层冗余协议,适用于支持组播或广播的局域网(如以太网等)。如需深入了解VRRP的工作原理,可查阅本手册的“VRRP”一章。下面先简单地看看,在防火墙双机组网的场景下,只部署VRRP的话,会存在什么问题:
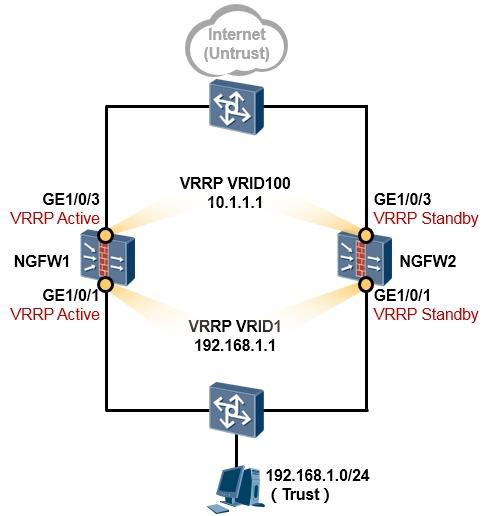
如上图所示,我们在防火墙上部署了VRRP。防火墙NGFW1的GE1/0/1口、NGFW2的GE1/0/1口组成了一个VRRP组,这个VRRP组将产生一台虚拟设备,其虚拟IP地址为192.168.1.1。在该VRRP组中,
NGFW1充当Active(主)设备,承担报文转发的任务,同时响应内网PC关于192.168.1.1的ARP请求; 在该VRRP组中,NGFW2充当Standby(备份)设备,它会侦听NGFW1的VRRP报文以便确认NGFW1 的活跃状态,并且准备随时接替它的工作成为Active。
防火墙的VRRP协议模块监视通信接口状态,并通过组播方式向Backup防火墙发送通告报文。如果
Active防火墙的接口或链路出现故障,无法正常发送VRRP通告报文,导致Backup设备在指定时间内没有收到VRRP通告报文,VRRP协议就会把Backup防火墙的VRRP状态变成active,从而将相关通信切换到新的Active防火墙NGFW2上。因此,采用VRRP技术实现了内部网络中的主机不间断地与外部网
络进行通信,可靠性得到保证。对于另一组VRRP:VRID100,原理相同,不再赘述。
我们可以在同一台设备上部署多个VRRP组,例如下图中,NGFW1的GE1/0/1口及NGFW2的GE1/0/1 口加入了一个VRRP组,虚拟IP为192.168.1.1,NGFW1的GE1/0/1口为VRRP的Active,这组VRRP用来实现内网PC的网关冗余;另外NGFW1的GE1/0/3口及NGFW2的GE1/0/3口运行了另一组VRRP,虚拟IP为10.1.1.1,NGFW1的GE1/0/3口为Active。 这组VRRP用来与Internet对接。
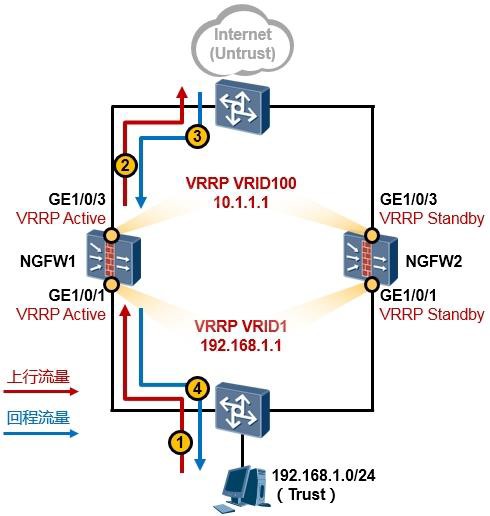
我们来分析一下数据传输的过程:
-
现在PC要访问Internet。数据包发送给自己的网关192.168.1.1。192.168.1.1是VRRP组1的虚拟IP 地址,而此刻NGFW1的GE1/0/1口是该VRRP组的Active,因此数据包由NGFW1进行处理和转发。
- 由于这是此数据流的首个报文,因此NGFW1建立会话表项,并将数据包通过上行线路送到Internet。
-
Internet回程的数据包发向10.1.1.1这个地址,这是VRRP组100的虚拟IP地址,而此刻NGFW1的
GE1/0/3口为Active,因此数据包发给了NGFW1。
-
NGFW1收到数据包后,发现数据包在会话表中有匹配的表项,因此放行这些回程报文,最终PC收到回程的数据包,数据交互完成,通信没有问题。
然而,由于这个环境中,VRRP组1及VRRP组100是相互独立的,那么就有可能出现下图所示的情况, 也即VRRP组1中NGFW1的GE1/0/1口为Active;而VRRP组100中NGFW2的GE1/0/3口为Active。这样会产生什么问题呢?
-
PC要访问Internet,数据包发送给自己的网关192.168.1.1,由NGFW1进行处理和转发。
- NGFW1建立会话表项,并将数据包通过上行线路送到Internet。
- 回程的数据包发向10.1.1.1,这是VRRP组100的虚拟IP地址,而此刻NGFW2的GE1/0/3口为Active,
因此数据包发给了NGFW2。
-
NGFW2收到数据包后,发现数据包在本地没有匹配的会话表项,因此丢弃该报文,
从这个例子我们可以看出,防火墙上VRRP组的主/备状态的统一是非常重要的,否则就可能会造成数据往返路径不一致的问题。然而传统的VRRP中,组与组之间是相互独立运作的,无法实现统一的管理, 这就需要VGMP了。
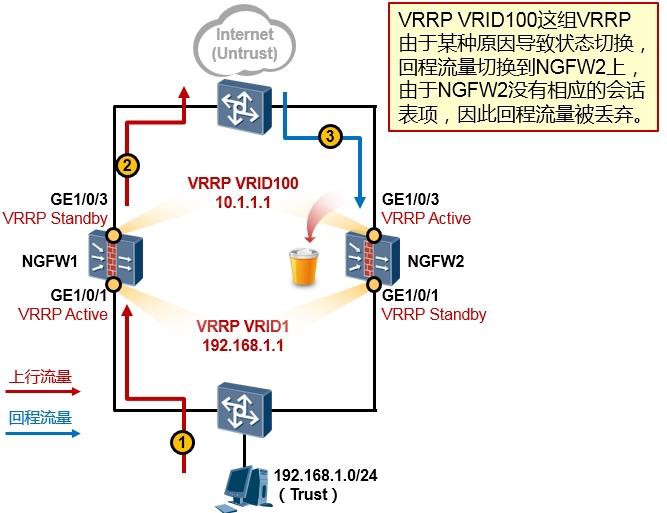
VGMP¶
一台设备可以配置多组VRRP,而且这些VRRP组之间相互独立,因此有可能出现的情况是:对于特定的组而言,本设备是Active设备,而对于其他组,本设备又是Backup设备。VGMP(VRRP Group Management Protocol,VRRP组管理协议)用于统一管理各个VRRP组,从而实现VRRP组之间的的设备状态统一。以下是VGMP的主要功能介绍:
接口集中监控:¶
- 将设备的所有VRRP组都加入到VGMP管理组中,由VGMP管理组统一监控组内所有的VRRP组状态。这样VGMP管理组就可以通过VRRP统一监控系统的接口状态。
- 将设备的业务接口加入到VGMP管理组中,由VGMP管理组统一监控组内所有接口状态(HRP Track)。
设备状态统一管理:¶
- NGFW是通过VGMP管理组来进行设备状态管理的。VGMP管理组的主备状态决定了双机热备组网中设备的主备状态,决定了VGMP管理组内的成员接口和VRRP组的状态。
- 当一台设备的VGMP管理组的状态为Active时,组内所有成员的接口状态统一为Active,该设备成
为主设备。另外一台设备的VGMP管理组状态为Standby,则该设备为备用设备。
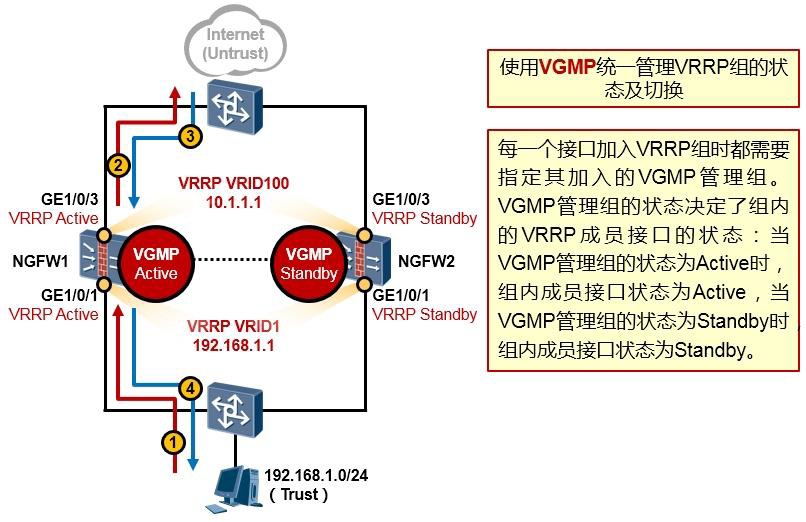
在上图中,NGFW1及NGFW2的两组VRRP都加入VGMP管理组,由VGMP管理组统一管理两组VRRP 的主备状态和切换。网络管理员将NGFW1配置为初始时的主防火墙、NGFW2为备防火墙。在正常情况下NGFW1为VGMP的Active,它是两个VRRP组(VRRP VRID1与100)的Active设备。
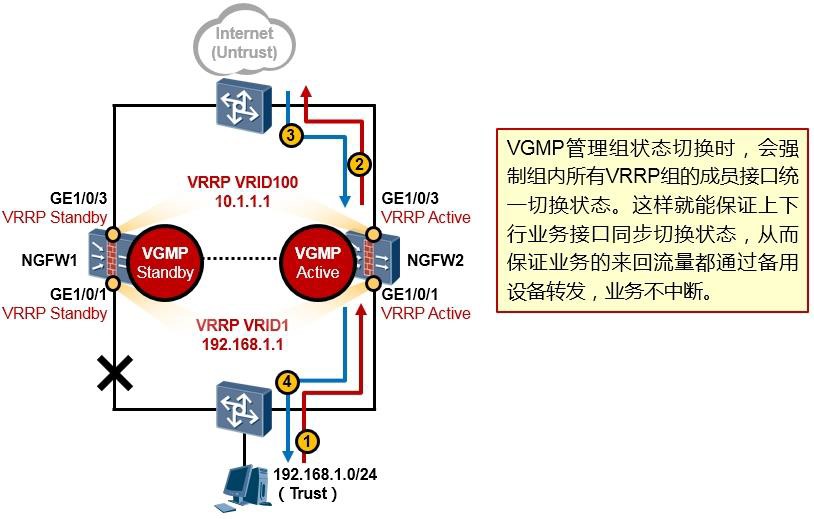
现在NGFW1的GE1/0/1口的直连链路发生故障,VGMP管理组检测到链路的变化,因此发生VGMP管理组的主备切换,NGFW2成为VGMP的Active,而NGFW1为Standby。一旦VGMP的主备发生切换,
设备上所有加入VGMP管理组的VRRP组都发生切换并保持主备状态一致。因此NGFW2成为VRRP组1 及组100的Active设备。如此一来,由VRRP组状态不一致导致的往返路径不一致问题就可以得到解决。
HRP¶
FW通过执行命令(通过Web配置实际上也是在执行命令)来实现用户所需的各种功能。如果备用设备切换为主用设备前,配置命令没有备份到备用设备,则备用设备无法实现主用设备的相关功能,从而导致业务中断。
FW属于状态检测防火墙,对于每一个动态生成的连接,都有一个会话表项与之对应。主用设备处理业务过程中创建了很多动态会话表项;而备用设备没有报文经过,因此没有创建会话表项。如果备用设备切换为主用设备前,会话表项没有备份到备用设备,则会导致后续业务报文无法匹配会话表,从而导致业务中断。
因此为了实现主用设备出现故障时备用设备能平滑地接替工作,必须在主用和备用设备之间备份关键配置命令和会话表等状态信息。为此华为防火墙引入了HRP( Huawei Redundancy Protocol)协议, 实现防火墙双机之间动态状态数据和关键配置命令的备份。
在双机热备组网中,我们往往会指定心跳线作为专门的备份通道,用于备份配置命令和状态信息。主备设备通过心跳线交互报文了解对方状态,以及实现配置命令和状态信息的备份。心跳线两端的设备上的接口称为心跳接口。
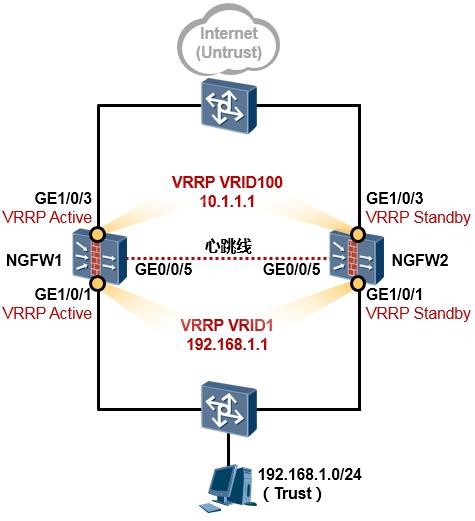
- 防火墙双机配置步骤
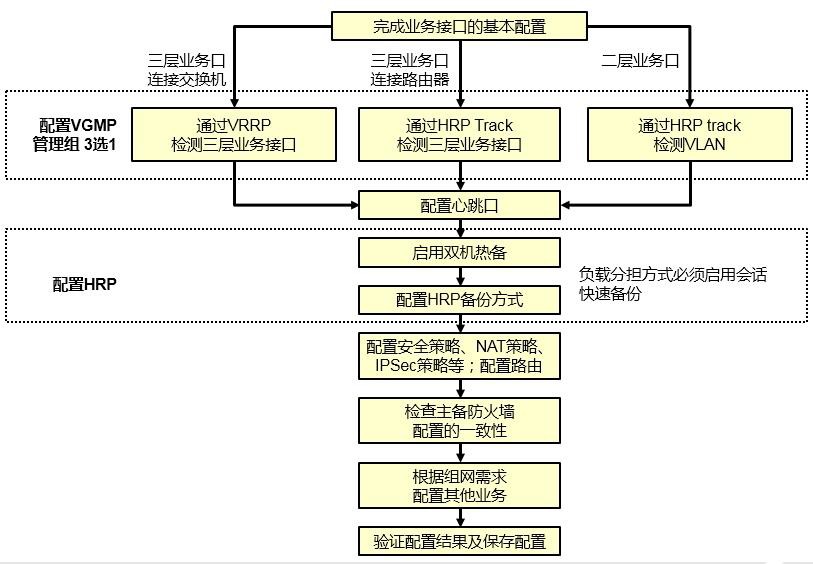
- 配置案例 1:防火墙双机主备配置(上下行连接交换机并在物理接口部署 VRRP)
场景说明:¶
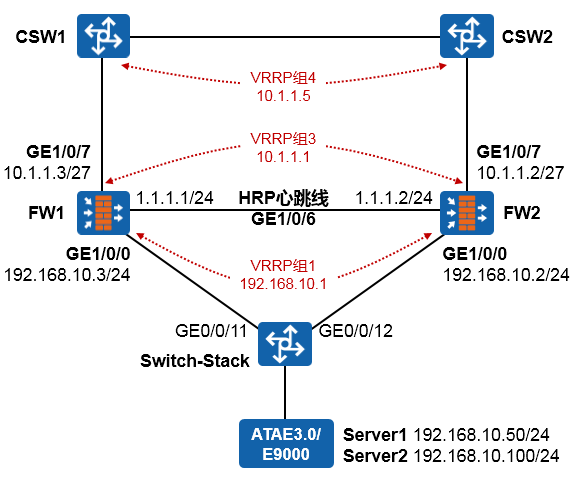
- 如图所示,ATAE3.0/E9000机框通过核心交换机堆叠组(Switch-Stack)连接到防火墙FW1及FW2。
- ATAE3.0/E9000目前只规划了1个VLAN,服务器单板(Server1及Server2)使用192.168.10.0/24网段,且缺省网关设置为FW1/FW2。
- 防火墙FW1及FW2部署双机热备,工作方式为主备,正常情况下FW1为主,FW2为备。
-
防火墙FW1及FW2上下行均连接着交换机,其中CSW1及CSW2为外网(或客户)交换机,按图示运行
VRRP。
-
两台防火墙的GE1/0/0接口用于连接内网(Trust安全区域),运行一组VRRP,使用的VRID为1,且虚拟IP地址为192.168.10.1,该地址将作为服务器单板的缺省网关;两台防火墙的GE1/0/7接口用于连接外网(Untrust安全区域),运行另一组VRRP,使用的VRID为3,且虚拟IP地址为10.1.1.1,该地址将作为外部交换机CSW1及CSW2的、到达内部网段的静态路由的下一跳。
- 要求Server1及Server2能够访问外部网络。
配置指导:¶
完成FW1和FW2的接口基本配置、接口加域¶
FW1的配置如下:
FW2的配置如下:
完成FW1和FW2的VRRP配置¶
FW1的配置如下:
FW2的配置如下:
注意:在配置防火墙VRRP时,主防火墙的所有VRRP都需加入Active管理组,而备份防火墙的所有
VRRP都需加入Standby管理组。
完成FW1和FW2的HRP配置¶
FW1的配置如下:
FW2的配置如下:
完成上述配置后,FW1与FW2便会开始以双机的方式工作。由于FW1是缺省的主防火墙,因此其设备
名称将变成HRP_A[FW1] , 其中A表示Active;而FW2由于是备防火墙, 因此其设备名称将变成
HRP_S[FW2],其中S表示Standby。
在FW1上使用display hrp group命令,可以看到如下输出:
而在FW2上使用该命令,输出如下:
HRP_S[FW2] display hrp group
另外,使用**display hrp state**命令(显示当前HRP的状态,包括管理组的接口和track接口等),在FW1
上可以看到如下输出:
| HRP_A[FW1] display hrp state The firewall's config state is: ACTIVE Backup channel usage: 0.01% Time elapsed after the last switchover: 0 days, 0 hours, 2 minutes Current state of virtual routers configured as active: | ||
|---|---|---|
| GigabitEthernet1/0/7 | vrid | 3 : active |
| GigabitEthernet1/0/0 | vrid | 1 : active |
完成静态路由的配置¶
FW1及FW2作为服务器单板的缺省网关,要负责将服务器访问外部网络的流量转发出去,因此需具备相应的路由信息。在本场景中,很明显,与外部网络对接采用的是“静态路由+VRRP”的方案。因此, 需在FW1及FW2上完成静态路由的配置,此处我们将为它们各配置一条默认路由,下一跳为客户交换机的VRRP虚拟IP地址10.1.1.5。
FW1的配置如下:
HRP_A[FW1] ip route-static 0.0.0.0 0.0.0.0 10.1.1.5
FW2的配置如下:
HRP_S[FW2] ip route-static 0.0.0.0 0.0.0.0 10.1.1.5 注意:当FW1及FW2形成双机主备后,缺省时,静态路由的配置不会自动从主墙同步到备份防火墙, 因此静态路由需分别在FW1及FW2上进行配置。
注意:为了让Server访问外部网络的回程流量能够从客户交换机CSW顺利地返回FW1/FW2并到达
Server,在本步骤中,需确保客户交换机CSW1及CSW2拥有到达192.168.10.0/24网段的回程路由,该路由的下一跳应为10.1.1.1。
在主防火墙FW1上完成安全策略的配置¶
注意:当FW1及FW2形成双机主备后,在配置安全策略(Security-Policy)时,需在主防火墙上完成相
应的配置,所做的安全策略的相关配置会自动同步到备份防火墙。因此上述test1安全规则会自动同步到FW2。
到目前为止,Server1及Server2已经能够访问外部网络了。
(增加需求)源地址NAT配置¶
现在网络中出现了新增的需求,要求内部网段192.168.10.0/24访问外部网络时,将源IP地址进行转换, 转换成地址池10.1.1.10~10.1.1.20中的客户大网IP地址(10.1.1.10~10.1.1.20地址段需向客户申请)。
在主防火墙FW1上完成NAT策略的配置:
注意:在主防火墙FW1上执行的上述NAT地址池及NAT策略配置,会自动同步到备份防火墙FW2。 以上的配置中,NAT策略规则policy1用于使防火墙在收到Trust区域访问Untrust区域的、源IP地址为
192.168.10.0/24网段的报文时,将这些报文的源IP地址进行转换,转换成地址池pool1中的某个IP地址。
完成上述配置后,Server1即可访问外部网络。当Server1 ping外部网络IP地址10.1.1.30时,我们能在
FW1上看到如下会话:
以上输出中,中括号内的IP地址为转换后的IP地址。
(增加需求)NAT Server配置¶
现在网络中出现了新增的需求,要求外部网络能够访问Server2的FTP服务,并且在访问时,使用的目的IP地址及目的TCP端口号为10.1.1.29:2121。要实现这个需求,至少有两个配置需要完成,其一是配置安全策略,使得外部网络用户能够访问Trust区域中的Server2(192.168.10.100)的FTP服务;其二是配置NAT Server,将该内部业务192.168.10.100:21映射到10.1.1.29:2121。
另外,FW还需增加NAT server的配置,使得外部用户能够使用目的IP地址10.1.1.29:2121来访问
Server2的FTP服务:
HRP_A[FW1] nat server s2 zone untrust protocol tcp global 10.1.1.29 2121 inside 192.168.10.100 21
完成上述配置后,外部网络用户即可访问Server2的FTP服务。在FW1上能看到如下会话:
最后,在本例中,ATAE3.0/E9000内只规划了一个VLAN。而防火墙FW1及FW2的GE1/0/0接口只需为该VLAN提供网关服务,因此我们直接在FW1及FW2的GE1/0/0接口上进行IP地址及VRRP功能的配置, 在这个场景中,核心交换机堆叠组Switch-Stack的GE0/0/11及GE0/0/12接口需配置为Access类型,并且加入相应的VLAN。
- 与防火墙双机热备相关的其他命令
hrp standby config enable¶
该命令用于允许配置备用设备。缺省情况下,未启用允许配置备用设备的功能。所有可以备份的信息都只能在主防火墙上配置,不能在备防火墙上配置。启用允许配置备用设备的功能后,所有可以备份的信息都可以直接在备防火墙上进行配置。且备防火墙上的配置可以同步到主防火墙。
hrp mirror session enable¶
该命令用于启用会话快速备份。配置会话快速备份功能后,主防火墙的会话信息会立即同步至备防火墙。当主防火墙出现故障时,报文能够平滑地被备防火墙转发出去,从而保证内外部用户的会话不中断。开启该功能时,如果网络中存在大量的会话,那么两台防火墙之间的心跳线可能需规划较大的可用带宽,例如可使用聚合接口(Eth-trunk)作为心跳接口。
undo hrp preempt¶
缺省情况下,VGMP管理组的抢占功能为开启状态,抢占延迟时间为60s(该时间使用**hrp preempt**
**delay**命令修改)。如果配置**undo hrp preempt**则抢占功能被关闭。
-
配置案例 2:防火墙双机主备配置(上下行连接交换机并在下行
子接口部署 VRRP)
场景说明:¶
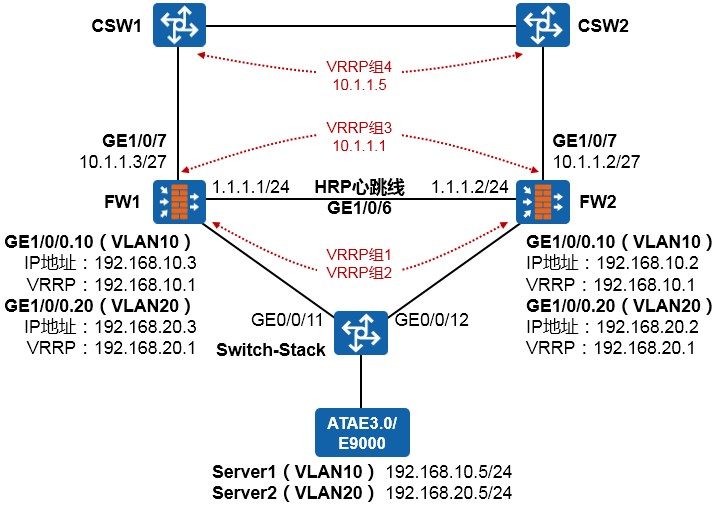
1) 如图所示,ATAE3.0/E9000机框通过核心交换机堆叠组(Switch-Stack)连接到防火墙FW1及FW2。
2) ATAE3.0/E9000 目 前 规 划 了 2 个 VLAN , VLAN10 使用 192.168.10.0/24 网段, VLAN20 使用
192.168.20.0/24网段。其中VLAN10被规划在了防火墙的Trust区域,而VLAN20被规划在了DMZ区域。
- 防火墙FW1及FW2部署双机热备,工作方式为主备,正常情况下FW1为主,FW2为备。
-
防火墙FW1及FW2上下行均连接着交换机,其中CSW1及CSW2为外网(或客户)交换机,按图示运行
VRRP。
-
两台防火墙的GE1/0/0接口用于连接内网,由于该物理接口需对接两个VLAN,因此需创建两个子接口。为了提供冗余的网关,FW1及FW2都需在自己GE1/0/0的两个子接口上各运行一组VRRP,其中VLAN10的子接口使用的VRID为1,且虚拟IP地址为192.168.10.1,该地址将作为VLAN10业务的网关;VLAN20 的子接口使用的VRID为2,且虚拟IP地址为192.168.20.1,该地址将作为VLAN20业务的网关。
- 两台防火墙的GE1/0/7接口用于连接外网(Untrust区域),运行另一组VRRP,使用的VRID为3,且虚拟IP地址为10.1.1.1。
- 要求内部网段192.168.10.0/24能主动访问外部网络,而且当其访问外部网络时,防火墙将源IP地址进行转换,转换成地址池10.1.1.10~10.1.1.20中的IP地址。要求外部网络能够访问Server2的FTP服务, 并且在访问时,使用的目的IP地址及目的TCP端口号为10.1.1.29:2121。
配置指导:¶
完成FW1和FW2的接口基本配置、接口加域¶
FW1的配置如下:
FW2的配置如下:
完成FW1和FW2的VRRP配置¶
FW1的配置如下:
FW2的配置如下:
完成FW1和FW2的HRP配置¶
FW1的配置如下:
FW2的配置如下:
完成上述配置后,FW1与FW2便会开始以双机的方式工作。FW1由于是缺省的主防火墙,因此其设备
名称将变成HRP_A[FW1] , 其中A表示Active;而FW2由于是备防火墙, 因此其设备名称将变成
HRP_S[FW2],其中S表示Standby。
完成静态路由的配置¶
FW1及FW2作为服务器单板的缺省网关,要负责将服务器访问外部网络的流量转发出去,因此需具备相应的路由信息。在本场景中,很明显,与外部网络对接采用的是“静态路由+VRRP”的方案。因此, 需在FW1及FW2上完成静态路由的配置,此处我们将为它们各配置一条默认路由,下一跳为客户交换机的VRRP的虚拟IP地址10.1.1.5。
FW1的配置如下:
HRP_A[FW1] ip route-static 0.0.0.0 0.0.0.0 10.1.1.5
FW2的配置如下:
HRP_S[FW2] ip route-static 0.0.0.0 0.0.0.0 10.1.1.5
注意:当FW1及FW2形成双机主备后,缺省时,静态路由的配置不会自动从主墙同步到备份防火墙, 因此静态路由需分别在FW1及FW2上进行配置。
完成安全策略及源IP地址NAT配置,使得Server1能够访问外部网络¶
在主防火墙FW1上配置安全策略:
注意:当FW1及FW2形成双机主备后,在配置安全策略(Security-Policy)时,需在主防火墙上完成相
应的配置,所做的安全策略的相关配置会自动同步到备份防火墙。因此上述test1安全规则会自动同步到FW2。
在FW1上进行源地址NAT配置。要求内部网段192.168.10.0/24访问外部网络时,将源IP地址进行转换, 转换成地址池10.1.1.10至10.1.1.20中的公网IP地址。
注意:在主防火墙FW1上运行的上述配置,会自动同步到备份防火墙FW2。完成上述配置后,Server1即可访问外部网络。
完成安全策略及NAT Server配置,使得外部网络能够主动访问Server2的FTP服务¶
要求外部网络能够访问Server2的FTP服务,并且在访问时,使用的目的IP地址及目的TCP端口号为
10.1.1.29:2121。在主防火墙FW1上添加如下配置:
上述配置会自动同步到备份防火墙。
另外,FW还需增加NAT server的配置,使得外部网络用户能够使用目的IP地址10.1.1.29:2121来访问
Server2的FTP服务:
HRP_A[FW1] nat server s2 zone untrust protocol tcp global 10.1.1.29 2121 inside 192.168.20.5 21 最后,在本例中,核心交换机Switch-Stack的GE0/0/11及GE0/0/12接口必须配置为Trunk类型,并且放 通VLAN10及20。
- 配置案例 3:防火墙双机主备配置(上下行连接交换机并在下行Eth-trunk 子接口部署 VRRP)
场景说明:¶

1) 如图所示,ATAE3.0/E9000机框通过核心交换机堆叠组(Switch-Stack)连接到防火墙FW1及FW2。
2) ATAE3.0/E9000 目 前 规 划 了 2 个 VLAN , VLAN10 使用 192.168.10.0/24 网段, VLAN20 使用
192.168.20.0/24网段。其中VLAN10被规划在了防火墙的Trust安全区域,VLAN20被规划在了DMZ安全区域。
- 防火墙FW1及FW2部署双机热备,工作方式为主备,正常情况下FW1为主,FW2为备。
-
防火墙FW1及FW2上下行均连接着交换机,其中CSW1及CSW2为外网(或客户)交换机,按图示运行
VRRP。
-
为了增加防火墙与交换机Switch-Stack之间互联链路的可靠性,FW1、FW2与Switch-Stack之间部署链路聚合。为了增加FW1与FW2之间的心跳链路的可靠性和带宽,两台防火墙之间采用聚合接口互联, 将该聚合接口用于HRP心跳。
-
两台防火墙的聚合接口Eth-trunk1用于连接内网,由于该聚合接口需对接两个VLAN,因此需创建两个子接口。为了提供冗余的网关,FW1及FW2需在Eth-trunk1的两个子接口上各运行一组VRRP,其中
VLAN10的子接口使用的VRID为1,且虚拟IP地址为192.168.10.1,该地址将作为VLAN10业务的网关;
VLAN20的子接口使用的VRID为2,且虚拟IP地址为192.168.20.1,该地址将作为VLAN20业务的网关;
-
两台防火墙的GE1/0/7接口用于连接外网,运行另一组VRRP,使用的VRID为3,且虚拟IP地址为
10.1.1.1。
-
要 求 内 部 网 段 192.168.10.0/24 访 问 外 部 网 络 时 , 将 源 IP 地 址 进 行 转 换 , 转 换 成 地 址 池
10.1.1.10~10.1.1.20中的IP地址。要求外部网络能够访问Server2的FTP服务,并且在访问时,使用的目的IP地址及目的TCP端口号为10.1.1.29:2121。
配置指导:¶
完成FW1和FW2的接口基本配置、接口加域¶
FW1的配置如下:
FW2的配置如下:
完成FW1和FW2的VRRP配置¶
FW1的配置如下:
FW2的配置如下:
完成FW1和FW2的HRP配置¶
FW1的配置如下:
FW2的配置如下:
完成静态路由的配置¶
FW1及FW2作为服务器单板的缺省网关,要负责将服务器访问外部网络的流量转发出去,因此需具备相应的路由信息。在本场景中,很明显,与外部网络对接采用的是“静态路由+VRRP”的方案。因此, 需在FW1及FW2上完成静态路由的配置,此处我们将为它们各配置一条默认路由,下一跳为客户交换机的VRRP的虚拟IP地址10.1.1.5。
FW1的配置如下:
HRP_A[FW1] ip route-static 0.0.0.0 0.0.0.0 10.1.1.5
FW2的配置如下:
HRP_S[FW2] ip route-static 0.0.0.0 0.0.0.0 10.1.1.5 注意:当FW1及FW2形成双机主备后,缺省时,静态路由的配置不会自动从主墙同步到备份防火墙, 因此静态路由需分别在FW1及FW2上进行配置。
完成安全策略及源IP地址NAT配置,使得Server1能够访问外部网络¶
在FW1上完成安全策略配置:
注意:当FW1及FW2形成双机主备后,在配置安全策略(Security-Policy)时,需在主防火墙上完成相应的配置,所做的安全策略的相关配置会自动同步到备份防火墙。因此上述test1安全规则会自动同步到FW2。
要求内部网段192.168.10.0/24访问外部网络时,将源IP地址进行转换,转换成地址池10.1.1.10至
10.1.1.20中的公网IP地址。在主防火墙FW1上完成NAT策略的配置:
注意:在主防火墙FW1上运行的上述配置,会自动同步到备份防火墙FW2。
完成上述配置后,Server1即可访问外部网络。
完成安全策略及NAT Server的配置,使得外部网络能够主动访问Server2的FTP服务¶
要求外部网络能够访问Server2的FTP服务,并且在访问时,使用的目的IP地址及目的TCP端口号为
10.1.1.29:2121。在主防火墙FW1上添加如下配置:
另外,FW还需增加NAT server的配置,使得外部网络用户能够使用目的IP地址10.1.1.29:2121来访问
Server2的FTP服务:
HRP_A[FW1] nat server s2 zone untrust protocol tcp global 10.1.1.29 2121 inside 192.168.20.5 21 最后,在本例中,核心交换机Switch-Stack的Eth-trunk1及Eth-trunk2接口必须配置为Trunk类型,并且 放通VLAN10及20。
-
配置案例4:防火墙双机主备配置(下行连接内部交换机并在Eth-
trunk 子接口部署 VRRP、上行连接外部交换机并运行 OSPF)
场景说明:¶
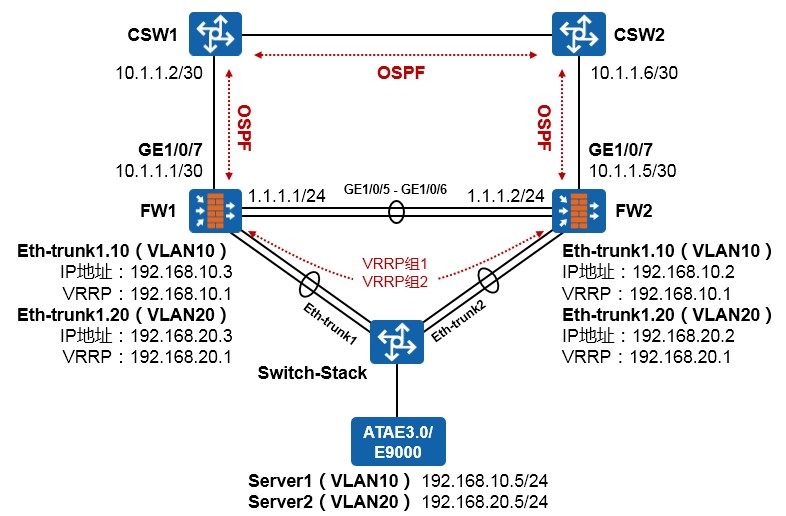
1) 如图所示,ATAE3.0/E9000机框通过核心交换机堆叠组(Switch-Stack)连接到防火墙FW1及FW2。
2) ATAE3.0/E9000 目 前 规 划 了 2 个 VLAN , VLAN10 使用 192.168.10.0/24 网段, VLAN20 使用
192.168.20.0/24网段。其中VLAN10被规划在了防火墙的Trust安全区域,VLAN20被规划在了DMZ安全区域。
- 防火墙FW1及FW2部署双机热备,工作方式为主备,正常情况下FW1为主,FW2为备。
-
防火墙FW1及FW2上下行均连接着交换机,其中CSW1及CSW2为外网(或客户)交换机,按图示运行
OSPF。也即FW1与CSW1、FW2与CSW2建立OSPF邻接关系。
-
为了增加防火墙与交换机Switch-Stack之间互联链路的可靠性,FW1、FW2与Switch-Stack之间部署链路聚合。为了增加FW1与FW2之间的心跳链路的可靠性和带宽,两台防火墙之间采用聚合接口互联, 将该聚合接口用于HRP心跳。
-
两台防火墙的聚合接口Eth-trunk1用于连接内网,由于该聚合接口需对接两个VLAN,因此需创建两个子接口。为了提供冗余的网关,FW1及FW2需在Eth-trunk1的两个子接口上各运行一组VRRP,其中
VLAN10的子接口使用的VRID为1,且虚拟IP地址为192.168.10.1,该地址将作为VLAN10业务的网关;
VLAN20的子接口使用的VRID为2,且虚拟IP地址为192.168.20.1,该地址将作为VLAN20业务的网关;
-
要求内部网段192.168.10.0/24能够访问外部网络(不做源地址NAT)。
-
要求外部网络能够访问Server2的FTP服务,并且在访问时,使用的目的IP地址及目的TCP端口号为
10.10.10.10:2121。
配置指导:¶
完成FW1和FW2的接口基本配置、接口加域¶
FW1的配置如下:
FW2的配置如下:
完成FW1和FW2的VRRP配置,以及HRP Track配置¶
FW1的配置如下:
FW2的配置如下:
说明:在部署了VRRP的接口上,防火墙可以通过VRRP的状态来监控接口的状态,从而在接口故障时感知到问题的发生,并触发防火墙主备切换。然而FW1及FW2的GE1/0/7口在本场景中并未运行VRRP, 因此无法通过VRRP监控该接口,所以需要配置**hrp track**命令,使得防火墙的VGMP能够监控这个接口的状态。在主防火墙的接口上需使用**hrp track active**命令,而备墙使用**hrp track standby**。
完成FW1和FW2的HRP配置¶
FW1的配置如下:
FW2的配置如下:
完成OSPF的配置¶
FW1及FW2作为服务器单板的缺省网关,要负责将服务器访问外部网络的流量转发出去,因此需具备相应的路由信息。在本场景中,FW1及FW2与外部交换机采用OSPF的方式对接,进行路由交互。典型的对接场景如下。
- FW1与CSW1采用10.1.1.0/30的网段互联;基于该直连接口建立OSPF邻接关系。
- FW2与CSW2采用10.1.1.4/30的网段互联,基于该直连接口建立OSPF邻接关系。
- CSW1与CSW2采用另一个互联网段,并且也建立OSPF邻接关系。
-
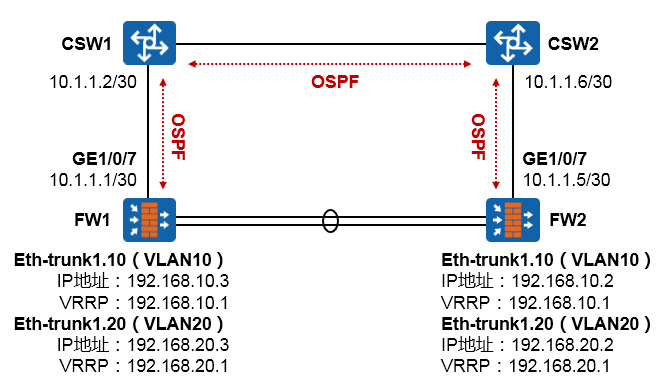 上述建立邻接关系的接口必须规划在相同的OSPF区域(Area-ID必须相同,例如都是Area0)。
上述建立邻接关系的接口必须规划在相同的OSPF区域(Area-ID必须相同,例如都是Area0)。FW1的配置如下:
FW2的配置如下:
注意:当FW1及FW2形成双机主备后,缺省时,OSPF的配置不会自动从主墙同步到备份防火墙,因此
OSPF需分别在FW1及FW2上进行配置。在主防火墙FW1上完成安全策略的配置:
注意:在上述安全策略的配置中,“OSPF1”至“OSPF4”规则用于允许FW与CSW交互的OSPF报文,
使得两者能够正确地建立OSPF邻接关系并交互路由。如果不配置相关安全规则,则FW与CSW可能将无法正确建立OSPF邻接。
完成上述配置后,需在防火墙上检查OSPF邻接关系状态及路由,确保防火墙学习到了客户所通告的路由。
以FW1为例,查看其OSPF邻居表:
它已经与CSW1建立了全毗邻(Full)的邻接关系。
完成安全策略配置,使得Server1能够访问外部网络¶
在FW1上完成安全策略配置:
注意:当FW1及FW2形成双机主备后,在配置安全策略(Security-Policy)时,需在主防火墙上完成相
应的配置,所做的安全策略的相关配置会自动同步到备份防火墙。因此上述test1安全规则会自动同步到FW2。
完成上述配置后,Server1即可访问外部网络。
完成安全策略及NAT Server的配置,使得外部网络能够主动访问Server2的FTP服务¶
要求外部网络能够访问Server2的FTP服务,并且在访问时,使用的目的IP地址及目的TCP端口号为
10.1.1.29:2121。在主防火墙添加如下配置:
另外,FW还需增加NAT server的配置,使得外部网络用户能够使用目的IP地址10.1.1.29:2121来访问
Server2的FTP服务:
HRP_A[FW1]nat server s2 zone untrust protocol tcp global 10.1.1.29 2121 inside 192.168.20.5 21 需要注意的是,在本场景中,FW1与CSW1采用10.1.1.0/30网段直连,FW2与CSW2采用10.1.1.4/30网 段直连,而分配给Server2的外网IP地址是10.1.1.29,这个地址当然是需要外部网络(例如客户)分配的。目前这个地址并不属于任何设备,仅仅用于目的地址NAT,为了让外部网络访问10.1.1.29的流量能够顺利到达FW1或FW2,防火墙就需要通过OSPF向外部通告10.1.1.29/32路由。
FW1的配置如下:
FW2的配置如下:
完成上述配置后,FW1及FW2便会将其路由表中的10.1.1.29/32路由注入OSPF,并向CSW1及CSW2
进行通告,而后者即可通过OSPF学习到相应的路由。
- 防火墙双机配置注意事项
7.4.9.1 双机热备中的OSPF及NAT¶
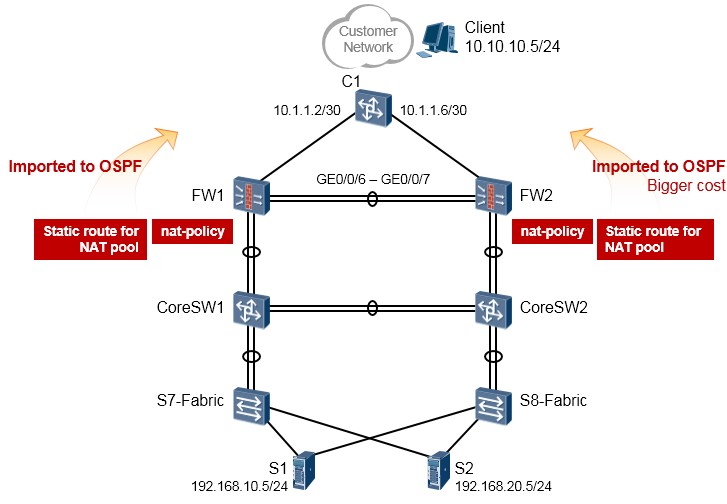
在上图中,FW1/FW2与C1运行OSPF。现在客户为防火墙分配了一个地址段10.1.1.16/30作为NAT使用。防火墙使用这个公网地址段作为NAT地址池,然后部署了nat-policy,当S1/S2访问客户网络时,将源地址进行转换。为了让访问客户网络的业务流量能够正常往返, 需要通过OSPF 向客户设备C1通告这条路由
10.1.1.16/30。在FW1/FW2配置10.1.1.16/30的黑洞路由,然后重发布到OSPF即可。
另外,10.1.1.16到10.1.1.19这四个地址都是可用的,也就是网络地址10.1.1.16及广播地址10.1.1.19都可用于NAT,回程的流量不会有问题,实测可行。
7.5 防火墙常见问题
防火墙双机部署VRRP时发送数据的源地址¶
在上图所示的场景中,FW1及FW2运行双机热备。在双方的外网接口GE0/0/3上部署了一组VRRP,虚拟IP 地址为192.168.30.1,当我们在主防火墙FW1上ping 192.168.30.100时,由于防火墙的外网接口与目标IP地址192.168.30.100直连可达,因此源地址为FW1的GE0/0/3接口IP地址,同理在FW2上ping目标IP地址的话, 数据包源地址为FW2的GE0/0/2接口地址。当我们要测试防火墙VRRP虚拟IP地址到目标IP的可达性时,则使用ping -a 192.168.30.1 192.168.30.100。这里有一个细节,那就是当我们在FW1及FW2上配置VRRP后, 在两台防火墙的路由表中,会出现一条192.168.30.1/32的主机路由,也就是描述这个虚拟IP地址的主机路由。
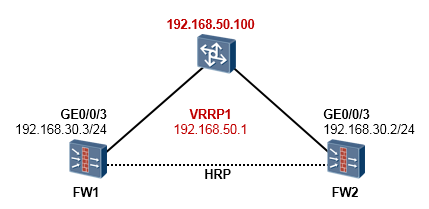
考虑另外一种情况,那就是如果FW1及FW2的GE0/0/3接口的VRRP虚拟IP地址与接口的实际IP并不在同一个网段的情况,例如虚拟IP地址为192.168.50.1/24,这在防火墙上是允许的。完成VRRP的配置后,FW1及
FW2在本地路由表中会产生192.168.50.0/24网段路由(与GE0/0/3接口关联)以及192.168.50.1/32主机路由。此时,当FW1直接ping 192.168.50.100时,数据包的源地址就是192.168.50.1(因为它在该网段中仅拥有这个IP地址)。当然,此时FW去访问192.168.50.100的数据包,是受控于Local到untrust的域间包过滤规则的。以上现象均在E1000E-X V300R001C00SPC700版本上验证过。
防火墙对回程流量的处理细节与相关案例¶
在上图所示的网络中,SW将默认路由的下一跳设置为12.1.1.2。当PC访问11.1.1.1时,例如PC ping 11.1.1.1, 流量的转发路径如图所示。一个关键的细节是,FW将PC ping 11.1.1.1的去程流量从GE0/0/4发出,并创建
Session,而在其GE0/0/7接口上接收回程流量,由于这些回程流量能够命中已存在的Session(五元组), 因此FW将GE0/0/7接口上接收的回程流量放行。当然,这个例子只是想讨论防火墙对这种流量的处理方式
(是转发,而不是丢弃),不过这种流量的传输路径并不被认为是合理的。
再看另一个例子,在上图中,SW依然将默认路由的下一跳设置为12.1.1.2,而防火墙则配置去往2.2.2.2/32
(SW的Loopback管理地址)的路由,下一跳则为11.1.1.1。如此一来,当SW以2.2.2.2为源去ping PC时, 流量的转发路径如图所示。一个有趣的细节是,虽然流量是从防火墙的DMZ接口进入,从Untrust接口出去, 但是这个流量在FW上留下的Session如下:
在处理回程流量时,FW经过路由查询,发现去往2.2.2.2的数据需从GE0/0/4转发,而该接口属于Trust区域,
因此它修改Session,将入站区域修改为Trust。下面来看一个实际的例子:
FW1/FW2部署双机主备。两台防火墙的GE0/0/3接口都加入untrust区域,GE0/0/1接口加入Trust区域。
FW1/FW2与客户采用VRRP+静态路由的方式进行对接。
现在客户网络中的10.10.10.1客户端可以访问主防火墙的管理地址——Loopback0 11.1.1.1/32,但是无法访问备份防火墙FW2的Loopback0。当10.10.10.1在ping 11.1.1.2时,可以在FW2上查看到如下Session:
留意到,inbound方向的流量正好是5个报文(实际ping了5个报文),而outbound却是0,因此怀疑报文是
已经到达了FW2,而FW2并没有回复这些ICMP报文,检查FW2的路由后发现,其并没有去往10.10.10.0/24 网段的路由。增加路由后,问题解决。另外,在上述session中,可以看到报文是从trust区域进来的,因此可以判断10.10.10.1访问11.1.1.2的报文是从FW1进来,然后由FW1转发给FW2,最终FW2在自己的
GE0/0/1口上收到这个报文,因此形成这样的表项。
在FW2增加去往10.10.10.1的路由(路由的下一跳直接指向客户地址)后,10.10.10.1即可访问11.1.1.2,而流量如下所示:
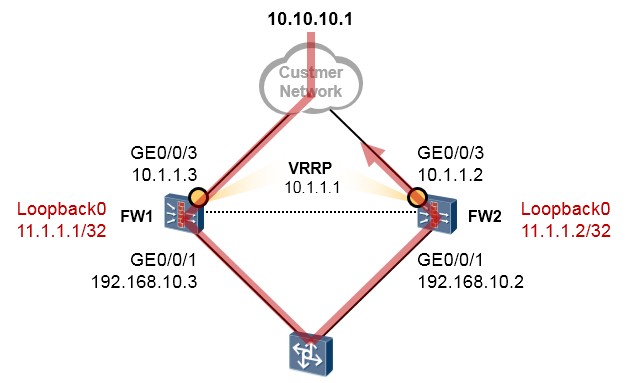
当FW2增加去往10.10.10.1的路由后,当后者访问11.1.1.2时,FW2的session如下:
报文明明是从FW2的GE0/0/1接口(trust区域)进来,而实际session显示的却是从untrust区域进来(实际上
这是符合事实的),因此,显然是防火墙在顺利地将回程报文转发出去后(从untrust区域送出),修正了
session里的域间信息。
注:这里所讨论的防火墙,均是Eudemon1000E-X(V300R001C00SPC700)。
- VPN
VPN 基础知识¶
VPN概述¶
假设我有一个公司,在全国各地有着许多分支机构和网点,同时又有外出公干的职员,如果这些网络之间需要进行互访,一种最经济的方式是购买Internet接入线路,例如ADSL的线路,廉价且使用方便,但是如果直接在Internet这个公网上传输企业内部数据,将面临着很高的安全风险,因为Internet作为一个全球性质的公有网络,安全性是非常低的。基于这个问题,我们可能会考虑在通信网络之间架设专用线路,也就是专线,专线虽然能提高安全性并提供线路的专用性,但是价格较为昂贵,那么有没有一种比较廉价、安全、可靠、可信赖、灵活的方式实现我们跨公网的私有通信需求呢?

Virtual Private Network,简称VPN。就是一种非常理想的解决方案。IETF草案理解基于IP的VPN为:
"使用IP机制仿真出一个私有的广域网",是通过私有的隧道技术在公共数据网络上仿真一条点到点的专线技术。说白点就是,我们运用VPN技术,可以实现利用公有网络实现私有的数据通信,相当于我们在通信节点之间,跨公有网络建立一个私有的、专用的虚拟通信隧道,而且基于不同的VPN技术,我们还能让这个通信隧道具有安全性、可信任、可靠性、完整性检验等特点。
VPN有两个显著的特点:专用型、虚拟性。
VPN的分类¶
按业务用途分类¶
Access VPN¶
远程拨入VPN,这种VPN类型可以提供内部员工在出差时的远程VPN拨入服务。通过在企业的安全设备上部署该种VPN技术,员工可以在任何能够接入公网的角落,通过远程拨入VPN 拨入到企业内网,从而访问内网资源。
Intranet VPN¶
这种VPN是利用VPN技术,实现在公网上属于该企业的不同站点或办事处之间的私有通信。
Extranet VPN¶
实现企业内部网络与合作伙伴或授权机构之间的虚拟专用网络。
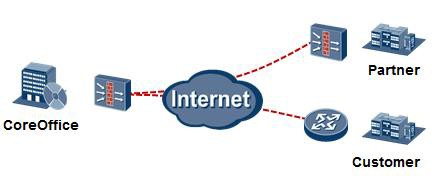
按实现的层次分类¶
Lay3隧道VPN¶
VPN的工作层在网络层。例如:GRE、IPSec等。
Lay2隧道VPN¶
VPN的工作层在数据链路层。例如L2TP、PPTP等。
VPN的常见技术¶

隧道技术:¶
利用封装及解封装技术,能够在通信站点之间建立一个点到点的虚拟通信隧道。例如在上图中,为了实现192.168.1.0/24及192.168.2.0/24两个信息岛屿的互通,我们可能要让中间的传输网络都有关于这两个网络的路由,但这就相当于暴露了这两个网络;又或者我们并不希望中间的传输网络知道这两个网络的存在,那么可以采用隧道技术,在两个边界路由器之间建立一条隧道(Tunnel),这条tunnel一旦建立好之后,相当于在两个网络间建立起一条直连的通道,当192.168.1.1用户要访问192.168.2.1时,报文在被边界路由器送到公网网络前会封装上一层新的IP头部,而这层IP头部中源IP地址为隧道的本地源地址,目的IP地址为隧道的目的端IP,数据包随后被送入公有网络,而公有网络中的路由器只会针对报文的外层IP头部也就是隧道IP头进行路由,最终将数据包转发到另一端的边界路由器上,由其解封装, 并还原成原始的IP报文转发到目的地。隧道机制是一种非常重要的思想,被广泛应用在各种VPN技术中。
身份认证技术:¶
使用身份认证技术,可以对建立通信隧道的两端设备进行相互认证,也可以对远程接入网络的用户进行认证,确保数据交互和网络接入的安全性。
数据加密技术:¶
数据加密技术用于实现VPN的安全性。通过数据加密技术,明文的、受保护的数据会被数据发送方使用加密算法加密从而形成密文,密文在传输到数据接收方后再由接收方解密,这样一来我们的数据在公网中传输时安全性就得到了提高。
目前加密算法主要分为对称性加密算法及非对称性加密算法。在讲解这两个算法之前我们先了解加密算法和秘钥的概念。举个非常简单的例子:假设数字2是我们的明文,现在要把明文加密,我采用一个
“乘方”的加密算法,把这个明文加密,加密后的密文是在明文的基础上的3次方,所以密文就是8,因此在这个例子中我用的加密算法是“乘方”,而秘钥是“3”,明文是“2”,加密后的密文是“8”。
在安全领域,加密算法都是公开的,例如上面举的这例子,乘方这个数学算法大家都知道,但是我们使用的这个秘钥,也就“乘几次方”,却是由加、解密双方约定的,这才是关键。
目前有两种加密算法:对称性加密算法、非对称性加密算法。对称性加密算法指的是加密和解密过程使用相同的秘钥。而非对称性加密算法则不同,它使用两把秘钥,加密过程使用的是公钥,解密过程使用私钥,公钥和私钥是成对的。目前业内有多种加密算法,这些算法可以被VPN技术整合使用,以提高安全性。详细的内容请见IPSecVPN章节。
秘钥管理技术:¶
上面已经说了,无论是对称性加密算法,或者是非对称性加密算法,算法是公开的,但是秘钥是必须要妥善保存的,如果秘钥泄露,那么数据传输就没有任何安全性可言,加密算法也就失去了意义。因此秘钥的产生、分发和管理就异常重要。
数据验证技术:¶
数据验证技术,也称为哈希算法,用于检验数据在传输过程中是否被篡改。
在上图中,我们有一个原始数据123456,这个数据如果直接就这么传输到接收方,接收方如何确定数据在传输过程中没有被篡改呢?使用哈希算法可以搞定这个问题。在发送方,使用哈希算法(如MD5) 对原始数据做哈希可得到一个哈希结果。哈希算法有这么几个特点:理论上的不可逆、定长的输出、雪崩效应等。原始数据经过哈希算法计算得到的哈希结果是固定长度的数据,这个数据看上去就是一堆乱码,而且理论上是无法通过哈希结果推导到原始数据的,另外,原始数据即使只有一个极其细微的变化,得到的哈希结果是截然不同的,这就是所谓的雪崩效应。
发送方将原始数据和自己针对原始数据做了哈希之后得到的结果一并发送给接收方,那么接收方在其本地,也对接收到的数据使用相同的算法做哈希,然后将自己计算得到的哈希结果与对方发送过来的哈希结果做比对,如果比对相同,则说明数据在传输过程中没有被篡改,因此,使用哈希算法,可以确保数据在传输过程中的完整性。
GRE¶
GRE的基本概念¶
GRE概述¶
- Generic Routing Encapsulation,简称GRE,是一种VPN技术,通过GRE技术,我们能够对网络层数据进行封装,封装后的数据能够在公共网络中传输。
- GRE提供了一种隧道机制。
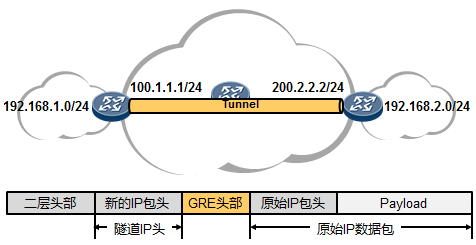
我们看上图,两个信息岛屿192.168.1.0/24及192.168.2.0/24要互相通信,一种最直接的办法就是打通全网的路由,让中间的公有传输网络中的所有路由器都有到达这两个网段的路由。但是可能有这样的需求:不希望中间的公有网络知道这两个网段的存在,但是仍然希望他们能够互访。
这里就可以使用GRE这种VPN技术。GRE的工作机制非常简单,就是在原始的IP报文的基础上,加上一个新的GRE的头部,然后再套上一个新的隧道IP头。这个新的隧道IP头部用于在中间的公有网络中传输被封装的原始IP数据包。这样一来,即使中间公有网络没有192.168.1.0/24及2.0/24的路由,两个信息岛屿也能通过我们预先建立好的隧道进行数据互通,互访数据被隧道边界设备封装上GRE头部以及新的隧道头部,然后送入公有网络,数据包在公有网络中传输时,转发数据包的中间设备只会查看隧道IP头并进行路由,最终数据包被转发到隧道对端的边界路由器上,它将数据包的隧道IP头及GRE头部解除封装,然后将里头承载的原始IP报文转发到目的地。
GRE的特点¶
- 可用于在站点之间建立点到点的专用通信隧道;
- GRE头部的通用性非常高,能承载各种类型的上层协议,例如IPv4、IPv6等报文;
- GRE的实现机制及配置非常简单,采用手工方式建立隧道;
- 不提供数据加密功能,可配合IPSec来增强安全性;
- 不提供QoS能力;
- 建立好的GRE隧道支持动态路由协议。
GRE的配置及实现¶
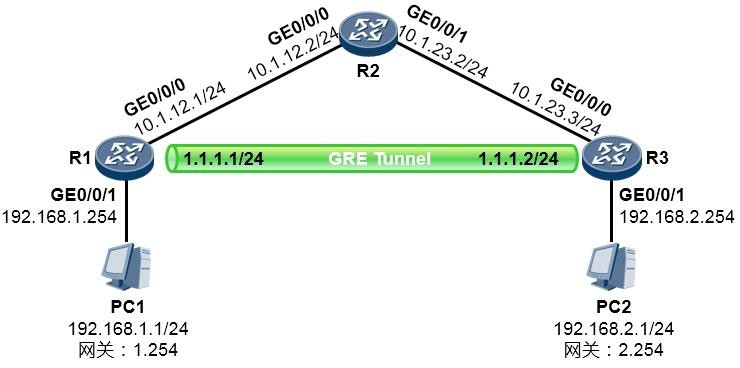
网络拓扑如上图所示。其中,R2只配置接口IP地址,并不配置任何静态路由,也不运行动态路由协议。在
R1及R2之间建立GRE隧道,使得192.168.1.0/24与192.168.2.0/24网段能够互通。
R1的配置如下:¶
在以上配置中,**source gigabitEthernet0/0/0**命令用于指定隧道在本设备的源接口,这条命令同时会将隧
道的源地址指定为该接口的地址,也即10.1.12.1。在本例中,使用**source 10.1.12.1**命令可以实现类似的效果。
R2的配置如下:¶
R3的配置如下:¶
完成配置后,PC1即可与PC2相互通信。实际的报文交互过程如下:
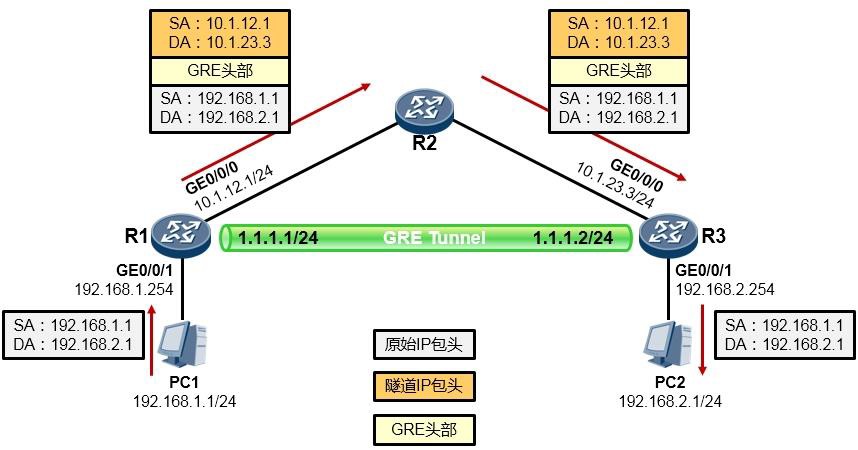
IPSecVPN¶
技术背景¶
上图所示是一家规模不小的公司,它除了中心站点外还有分布在全国各地的多个分支机构或办事处,以及出差在外的移动办公人员,这些节点之间要想互相通信,一种最简单最经济的方法就是利用Internet线路来实现数据互访,但是Internet毕竟是一个共享的网络环境,存在太多的安全威胁,直接在Internet上传输公司的机密数据是极为危险的。如果租用专线呢?专线是一种专有线路,固然更加安全,但是却也更为昂贵,而且专线又无法提供对移动性的支持。IPSecVPN可以完美的解决上述问题。
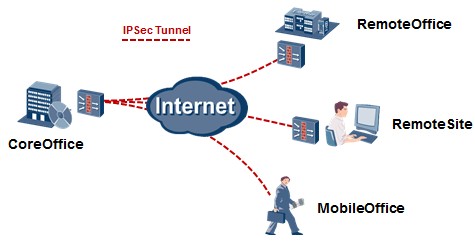
IPSecVPN是一种应用非常广泛、非常成熟的VPN技术。利用IPSecVPN我们可以放心的在公网上传输机密数据,因为IPSec可以提供安全性、完整性、身份认证、防重放攻击等等多种特性。IPSecVPN的组网也是很灵活,除了典型的站点到站点的IPSecVPN组网,还支持远程拨入式的组网。
IPSecVPN初相识¶
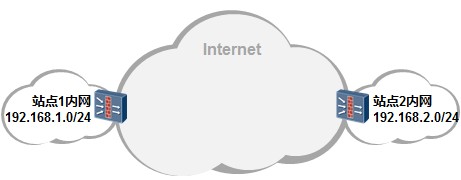
上图所示的两个站点,如果直接在Internet上进行数据传输,是存在诸多安全隐患的。使用IPSecVPN技术能够为数据传输保驾护航,这是一个典型的站点到站点(Site to Site或者LAN to LAN)的IPSecVPN应用场景, 两个站点之间跨Internet通信,在站点的防火墙上部署IPSecVPN从而保护两地内网的互访流量。在完成
IPSecVPN的部署后,两个站点的防火墙之间将会进行IPSecVPN隧道的建立:

在这个过程中,两端首先会协商用于保护隧道的加密算法、哈希算法等,在对齐所用的各种算法或策略后, 进行公共值的交换以便两者能够生成相匹配的秘钥用于后续的加密及哈希,然后进行对等体身份认证,也就是验证两台防火墙的身份。两端用于身份认证所交互的报文就是使用上文所提及的加密算法和哈希算法进行保护的。
上面的工作完成后,双方还会进一步协商用于保护两地站点内网之间通信流量的各种安全策略(IPSec
Proposal):安全协议类型、加密算法、哈希算法等等。上述工作都完成之后,一条IPSecVPN的隧道就建立起来了。
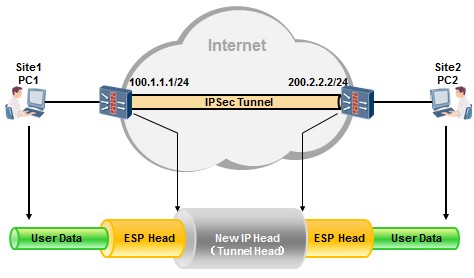
这相当于在Internet上拉起了一条隐形的、受保护的通信通道,站点1、2之间的受保护流量(也称为IPSecVPN 感兴趣流量)在传输时会“进入”该隧道内进行传输,传输的过程中数据是被加密的,因此可以保证通信的 机密性,同时数据还会被进行完整性校验,以便检测数据在传输过程中是否被篡改。就拿上面的这张图来 说,受保护的数据是绿色的管道,这部分数据在送到站点防火墙后会被识别为IPSecVPN感兴趣的流量,于 是被加密以及哈希,并套上一个安全协议的头部(例如ESP头部),之后为了让这个数据包能够在Internet 上传输到另一个站点的防火墙,我们还会在上述基础上,再为数据套上一个新的IP头,或称为新的隧道头部。
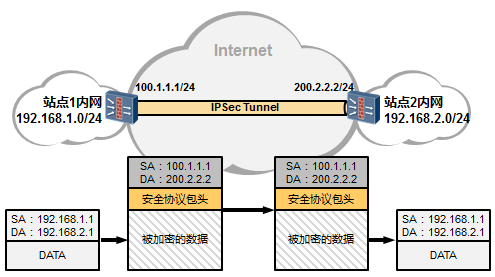
上图就是一个在IPSecVPN环境下数据传输的示例,站点1的192.168.1.0/24网络有一个节点要想访问站点2, 此刻它可直接使用192.168.2.x形式的目标IP地址来访问站点2,这是得益于IPSecVPN的隧道化技术,使得 两个站点之间可以使用对端的真实IP地址来进行互访。
明文的数据包到达站点1的出口防火墙后,防火墙发现这是一个IPSecVPN感兴趣的流量,因此将该报文使用预先协商好的加密策略和秘钥进行加密,同时对加密后的数据进行哈希计算,最后将这些处理后的数据
包在一个安全协议的头部后面,然后再套上一层新的IP头部,这层新的IP头部称为隧道头,其源地址为
100.1.1.1,目的地址为200.2.2.2。注意,这个源、目的地址都是公网IP地址,也就是在防火墙外网接口上的IP地址,最后这个数据包就被送上了Internet传输到对端站点的防火墙上。
由于数据包已经被安全处理过,因此我们并不担心数据在传输过程中被窃听,或者被篡改。数据包在到达站点2的防火墙后,它将数据包的隧道头剥去,利用安全协议包头中的相关信息查询到存储在本地的、相应的安全策略、秘钥等信息,然后对数据包进行完整性校验、解密,最终将解密后的明文数据发到目的地
192.168.2.0/24网络。
IPSec协议框架¶
概述¶
IPSec是一种开放的标准框架结构,是由IETF指定的标准,是特定的通信方之间在IP层通过加密和数据摘要(hash)等手段,来保证数据包在公网上传输时的机密性(confidentiality) 、完整性(data integrity) 和真实性(origin authentication)等。IPSec只能工作在IP层,要求乘客协议和承载协议都是IP协议。
IPSec并不是一个单一的协议,而是一个框架。
协议框架¶

IPSec的框架包含若干个协议。最重要的就是IKE和两个安全协议(AH、ESP)。其中IKE(Internet秘钥交换协议)是核心和根本,这是个混合协议,它包含三个协议:

其实我们只要关注其中最重要的协议,ISAKMP就好了,它是整个IKE的核心,因此经常在各种场合下的技术交流中,我们会将ISAKMP和IKE笼统的等同起来说。
ISAKMP负责IPSecVPN中非常重要的几项工作:负责建立和维护SA(IKE SA及IPsecSA)、协商协议参数(如加密、验证协议等)、对等体身份验证、协商密钥、以及对密钥的管理。ISAKMP还定义了消息交换的体系结构,包含对等体之间用于IPSec协商的报文格式、状态机等。
IPSec协议框架的另一个重要的协议类型:安全协议,它是真正负责保护用户数据的协议,包括两个:
AH及ESP:

其中AH协议能够提供数据完整性校验、源认证、防重放攻击等,但短板是不支持数据加密。ESP则支持数据源认证、完整性校验、防重放攻击及数据加密。
IKE的两个阶段¶

当我们在两个站点之间部署IPSecVPN时,IPSecVPN的一个感兴趣报文到达后,将触发IKE的工作。IKE通过两个阶段建立一条安全的IPSecVPN隧道,使得受保护的流量能够在公网中安全的传输,这两个阶段就是安全领域经典的IKE阶段一,及阶段二。
IKE阶段一¶
阶段一的主要工作内容是协商安全策略、进行DH交换、对等体认证。
- 与安全策略协商相关的内容,在华为的设备上的配置就是IKE Proposal,包括用于IKE隧道的加密算法、哈希算法、DH算法组等策略,两个站点的策略要一致。
- DH交换就是交换公共值,DH算法是一个神奇的算法,两个站点的防火墙之间通过交换几个公共值,再经过一系列的数学运算,最终得到三把秘钥。而即使有人侦听了DH公共值交换的报文,也无法推导出这三把秘钥。
- 接下去就是对等体的身份认证,最简单的方式就是预共享秘钥的方式,两个站点在防火墙上配置一个统一的密码,如果密码一致则说明两个对等体是可信赖的。
阶段一完成的标志是IKE SA的建立,SA(Security Associations,安全关联)可以简单理解为IPSec对等体双方的一共安全共识。SA一共有两种,一种是这里提到的IKE SA,IKE对等体双方有一个共同的IKE SA。另一种SA是IPSec SAs,一个IPSec会话有两个IPSec SAs,在下文会介绍。 阶段一有两个模式,我们上文中描述的是主模式,也是应用的较为广泛的模式,另一种模式是野蛮模式,这里不做介绍。
阶段一的工作可以理解为是在为阶段二做铺垫,阶段一协商妥当的相关安全策略如加密算法、哈希算法等,都是为了保护第二阶段的相关ISAKMP数据。
IKE阶段二¶
IKE第一阶段完成后,就会进入IKE第二阶段,在阶段二最主要的任务是明确第二阶段的策略(在华为设备的配置中就是IPSec Proposal),这些策略包括加密算法、哈希算法等等,注意,这里的这些策略, 要和阶段一的策略区分开来,这里所协商的策略是最终用于保护实际业务流量的策略,而阶段一的那些策略是用于保护IPSec协商的数据(主要是为了保护IKE阶段二的协商过程)。
阶段二完成的标志是双方都明确了IPSec SAs,这里的IPSec SAs实际上是包含两个SA:入站及出站。
FW1上的出站SA用于保护从FW1发往FW2的数据,这个SA对应FW2上的入站SA,而FW1的入站SA对应FW2的出站SA。
IKE两个阶段完成后:¶
IKE两个阶段完成后,IPSecVPN的隧道就算是建立起来了,上面说了标志性的里程碑就是IPSec SAs 的建立,如果IPSecVPN隧道正确建立,站点的IPSecVPN安全设备上应该有两个IPSec SAs,一个是出站的outbound SA,一个是入站的Inbound SA。站点1的出站SA对应站点2的入站SA,站点1的入站
SA对应站点2的出站SA,如下图所示。
IPSec SAs中保存着双方协商好的加密算法、哈希算法、秘钥信息等等。当站点1的FW收到来自本地内网的流量,如果该流量匹配了IPSecVPN的感兴趣数据流,它就会根据出站SA中指示的加密算法,以及
秘钥对数据进行加密,并做加密后的数据做哈希,将处理好的数据封装在ESP(安全协议,此处以ESP 为例)后,并在ESP头部中写入明确SA的SPI(索引值,这个索引值对应Site2-FW的入站SA),然后再封装上新的IP头以便数据能够在公网中传输。
Site2-FW收到数据后,将隧道IP头部去除,发现里头是个ESP封装的报文,于是从ESP头部中的SPI在本地查找,找到SPI值对应的SA,也就是匹配的入站SA,将数据做完整性校验,校验通过后对数据进行解密,最后得到明文的原始报文,然后将报文传递到本地内网目标节点。
路由器上的LAN-to-LAN IPSec VPN(IKE协商)¶
实验拓扑及需求:¶
- 在R1及R3上配置高级ACL用于匹配IPSecVPN感兴趣流量。
- 在R1及R3上创建IKE Proposal,用于指定IKE阶段一的策略。
- 在R1及R3上配置IKE peer,用于指示对等体(地址等信息)。在本例中,使用的是域共享秘钥的方式进行对等体身份验证。
- 在R1及R3上创建IPSec Proposal,用于指定IKE阶段二的策略,以便协商IPSec SA。
- 在R1及R3上创建IPSec Policy,用于将ACL、IKE Proposal、IPSec Proposal、IKE Peer等信息进行关联。
- 在R1及R3上将IPSec Policy应用在接口上。
- 在R1及R3上创建IPSec Proposal,用于指定IKE阶段二的策略,以便协商IPSec SA。
- 在R1及R3上配置IKE peer,用于指示对等体(地址等信息)。在本例中,使用的是域共享秘钥的方式进行对等体身份验证。
- 在R1及R3上创建IKE Proposal,用于指定IKE阶段一的策略。
实验步骤及配置:¶
R1的配置如下:
R3的配置如下:¶
R2的配置如下:¶
完成配置后,可在PC1上去ping PC2的地址,这样一来将在R1上触发IPsec VPN的感兴趣流量,R1-R3
之间就会开始进行IKE的协商。协商成功的标志是,在R1及R3上生成安全关联SA:
IPSecVPN的NAT穿越问题¶
IPSecVPN的NAT穿越问题(NAT Server场景)¶
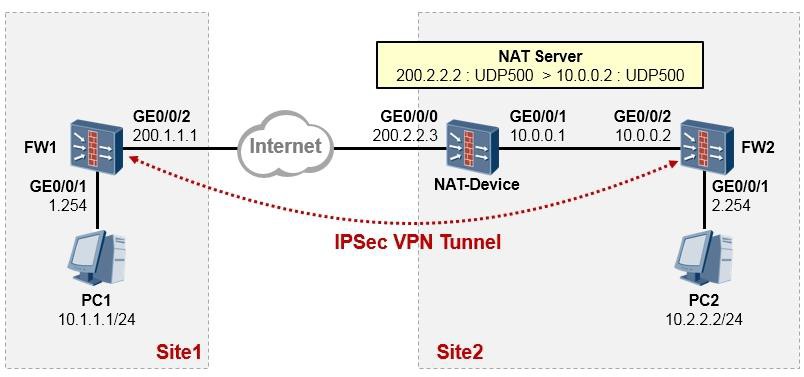
在上图所示的环境中,PC1、FW1为站点1的设备,NAT-Device、FW2及PC2为站点2的设备,其中FW1、
FW2为IPSecVPN网关,欲在二者之间建立站点到站点的IPSecVPN隧道。由于站点2的IPSecVPN网关躲在该站点的NAT设备之后并且使用私有IP地址空间,为了保证FW1能够与FW2对话,在NAT-Device 上部署了NAT Server,将公网地址200.2.2.2的UDP500端口映射到了10.0.0.2的UDP500端口。FW1使用200.2.2.2来访问FW2。
先考虑一下当FW1及FW2关闭NAT Traversal(或者FW1、FW2不支持NAT Traversal)时IPSecVPN隧道的建立问题。由于IPSecVPN的协商工作由ISAKMP完成,而ISAKMP是基于UDP的,且使用的源、目的端口均为UDP500,因此ISAKMP报文能够顺利被NAT-Device完成地址转换,最终IPSecVPN是能够建立起来的,在FW1及FW2上查看IPSec SAs是能够看到已经协商建立好的SAs。但是两个站点之间
PC的互访却出现了问题。我们考虑PC1去访问PC2的情况:
PC1发出的数据包如图所示。数据包到达FW1后,匹配上了IPSecVPN的感兴趣流量,因此报文被加密、哈希,然后套上ESP的头部,又封装上新的IP头。这个被处理后的数据包就被送上了公网,传输到了NAT-Device上,虽然NAT-Device上部署了NAT Server端口映射,但是接收到的这个包是一个IP包,IP 包头的后面就是ESP的头部了,没有UDP头部,NAT设备就不可能将报文做地址转换并丢给FW2,因此该报文就会被NAT-Device丢弃。这就导致虽然IPSecVPN隧道已经建立起来了,但是站点间的受保护流量无法互访的问题。
解决的办法就是在FW1及FW2上打开NAT trasversal功能,该功能激活后,在FW1及FW2的IKE第一阶段中就会进行NAT trasversal的协商,同时还能够通过ISAKMP报文的交互判断两台防火墙之间是否有
NAT设备。如果存在NAT设备,则从IKE阶段一的第5,6个报文和后续的快速模式的三个ISAKMP包,以及用于承载用户数据的ESP报文,都会使用UDP源、目的端口4500进行传输。这样,报文穿越NAT-
Device时就能够被正确的地址转换。这里有一点必须注意的是在NAT-Device上要增加4500的端口映射。
如此一来当PC1发出的数据到达FW1时,FW1将报文处理后封装上ESP头部,然后再封装上一个UDP 头部,源、目的端口号都使用4500(这个端口号专用于IPSec-NAT),最后再封装上隧道的IP头部。完成后报文被送达NAT-Device。NAT-Device发现这是一个UDP包,目的端口为4500,而本地配置了端口映射,将200.2.2.2:4500映射到了10.0.0.2:4500,因此将目的IP转换成10.0.0.2并将数据包转发给FW2, 接下来的过程就不再赘述了。
IPSecVPN的NAT穿越配置示例(NAT Server场景)¶
实验拓扑及IP编址如上图所示。FW1及PC1为站点1的设备;NAT-Device、FW2及PC2为站点2的设备;
FW1及FW2为IPSecVPN网关,两者之间部署LAN to LAN IPSecVPN;站点2申请到的、用于IPSecVPN 的地址是200.2.2.2;在NAT设备上配置NAT Server,将200.2.2.2的UDP500和UDP4500映射到10.0.0.2的UDP500和UDP4500。Internet可使用一台路由器模拟,只配置接口IP,不配置任何路由信息。
请注意,本案例采用Eudemon1000E-X防火墙举例讲解,不同的防火墙型号,在配置上存在差异。
FW1的配置如下(省略接口IP地址、安全区域等配置):¶
#配置默认路由
[FW1] ip route-static 0.0.0.0 0.0.0.0 200.1.1.2
#定义IPSecVPN感兴趣数据流,使用ACL3000来匹配感兴趣流量: [FW1] acl number 3000
[FW1-acl-adv-3000] rule permit ip source 10.1.1.0 0.0.0.255 destination 10.2.2.0 0.0.0.255
#配置IKE Proposal,这是IKE阶段一的策略: [FW1] ike proposal 1
[FW1-ike-proposal-1] authentication-method pre-share [FW1-ike-proposal-1] authentication-algorithm sha1 [FW1-ike-proposal-1] encryption-algorithm 3des-cbc
#配置IPsec proposal,这是IKE阶段二的策略: [FW1] ipsec proposal myset
[FW1-ipsec-proposal-myset] transform esp
[FW1-ipsec-proposal-myset] esp authentication-algorithm sha1 [FW1-ipsec-proposal-myset] esp encryption-algorithm 3des
#配置IKE peer,定义预共享秘钥、关联IKE proposal并指定隧道对端节点IP: [FW1] ike peer fw2
[FW1-ike-peer-fw2] pre-shared-key Huawei123 [FW1-ike-peer-fw2] ike-proposal 1
[FW1-ike-peer-fw2] remote-address 200.2.2.2
[FW1-ike-peer-fw2] remote-address authentication-address 10.0.0.2
[FW1-ike-peer-fw2] nat traversal
#配置IPsec Policy:
[FW1] ipsec policy mymap 1 isakmp
[FW1-ipsec-policy-isakmp-mymap-1] security acl 3000 [FW1-ipsec-policy-isakmp-mymap-1] ike-peer fw2 [FW1-ipsec-policy-isakmp-mymap-1] proposal myset
#应用IPsec Policy到接口:
[FW1] interface GigabitEthernet0/0/2
[FW1-GigabitEthernet0/0/2] ipsec policy mymap
#放开防火墙自身到Untrust区域的流量,使得防火墙FW1能够主动发送ISAKMP、及隧道建立后的加密流量到FW2: [FW1] policy interzone local untrust outbound
[FW1-policy-interzone-local-untrust-outbound] policy 0
[FW1-policy-interzone-local-untrust-outbound-0] policy destination 200.2.2.2 0 [FW1-policy-interzone-local-untrust-outbound-0] action permit
#放开IPSecVPN隧道对端防火墙发送过来的流量:
[FW1] policy interzone local untrust inbound
[FW1-policy-interzone-local-untrust-inbound] policy 0
[FW1-policy-interzone-local-untrust-inbound-0] policy source 200.2.2.2 0 [FW1-policy-interzone-local-untrust-inbound-0] action permit
#放开对端站点内网过来的流量:
[FW1] policy interzone trust untrust inbound
[FW1-policy-interzone-trust-untrust-inbound] policy 0
[FW1-policy-interzone-trust-untrust-inbound-0] policy source 10.2.2.0 0.0.0.255
[FW1-policy-interzone-trust-untrust-inbound-0] policy destination 10.1.1.0 0.0.0.255 [FW1-policy-interzone-trust-untrust-inbound-0] action permit
#放开本地站点内网到对端站点内网的流量:
[FW1] policy interzone trust untrust outbound
[FW1-policy-interzone-trust-untrust-outbound] policy 0
[FW1-policy-interzone-trust-untrust-outbound-0] policy source 10.1.1.0 0.0.0.255
[FW1-policy-interzone-trust-untrust-outbound-0] policy destination 10.2.2.0 0.0.0.255 [FW1-policy-interzone-trust-untrust-outbound-0] action permit
FW2的配置如下(省略接口IP地址、安全区域配置等):
注意事项:由于这个环境中,FW1采用的配置不是基于模板的IPSec,FW1使用200.2.2.2作为远端对等体地址对FW2进行身份验证,然而实际上FW2的真实IP地址是10.0.0.2,而并非200.2.2.2,这么一来,
FW1对FW2进行IPSec对等体认证的时候就会失败,因为FW2使用10.0.0.2与FW1进行认证(这个地址被封装在ISAKMP报文之中)。
解决上述问题方法之一是在FW1上手工指定远端对等体FW2用于身份认证的地址,在FW1的peer视图下使用命令**authentication-address**来指定对端用于身份认证的地址(也就是FW2的真实IP 10.0.0.2)。这就是本例所用的方法。
另一种方法是不使用IP地址作为身份认证的依据(默认就是使用IP地址),而是使用name来进行身份验证,FW1上的关键性配置修改如下:
FW2上的关键性配置可修改如下:
配置完成后,PC之间即可互通。
IPSecVPN的NAT穿越(NAT address-group场景)¶
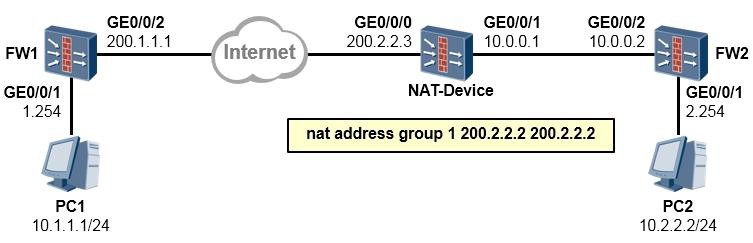
我们再来看另一种情况,如上图所示,FW1及PC1为站点1的设备;NAT-Device、FW2、PC2为站点2 的设备。在NAT-Device上部署了基于地址池的源地址转换(NAPT),站点2的内网设备(包括FW2) 使用公网地址200.2.2.2访问外网。
首先考虑FW1及FW2没有开启NAT Trasversal的情况,由于IPSecVPN隧道的协商是ISAKMP实现的, 而ISAKMP报文使用UDP源、目的端口500,因此报文会被NAT-Device顺利完成地址转换(必须由FW2 主动发起IPSecVPN隧道协商),从而IPSecVPN隧道的建立是没有问题的。
但是在IPSecVPN隧道建立起来之后:
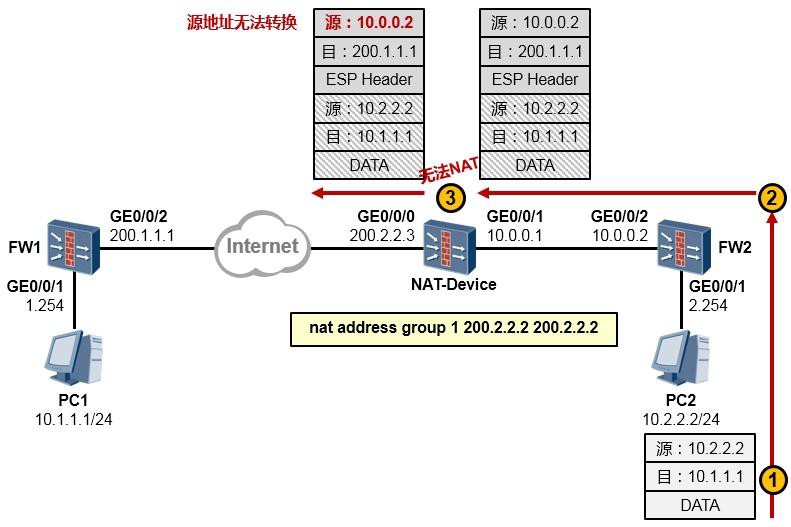
PC2访问PC1的数据在FW2被处理后,封装ESP头部、封装新的IP头,然后送到了NAT-Device,注意, NAT-Device部署的是NAPT,也就是多个内网地址共用一个公网地址访问外网、并使用端口号区分内网IP地址的NAT方式。而此刻NAT-Device收到的报文是一个IP包,在IP包头后面就是ESP的报文头部, 再往后就是被加密的数据了,NAT-Device无法根据现有的数据形成NAT表项并完成地址转换。NAT会话表项一般包括协议类型、源地址、源端口、目的地址、目的端口等五元组,而此刻数据元素不足, NAT-Device无法创建NAT表项、无法对该报文进行地址转换,因此它直接把这个报文转发出去,显然,
这个报文是无法在公网上传输的,因为它的源IP地址是10.0.0.2,这是一个私有IP。
现在,FW1及FW2启用NAT Trasversal,双方经过协商之后,会在受保护报文的ESP头部前增加一个
UDP头部,源、目的端口号为4500,有了这个头部,报文在经过NAT-Device的时候就能够被正确的进行地址转换:
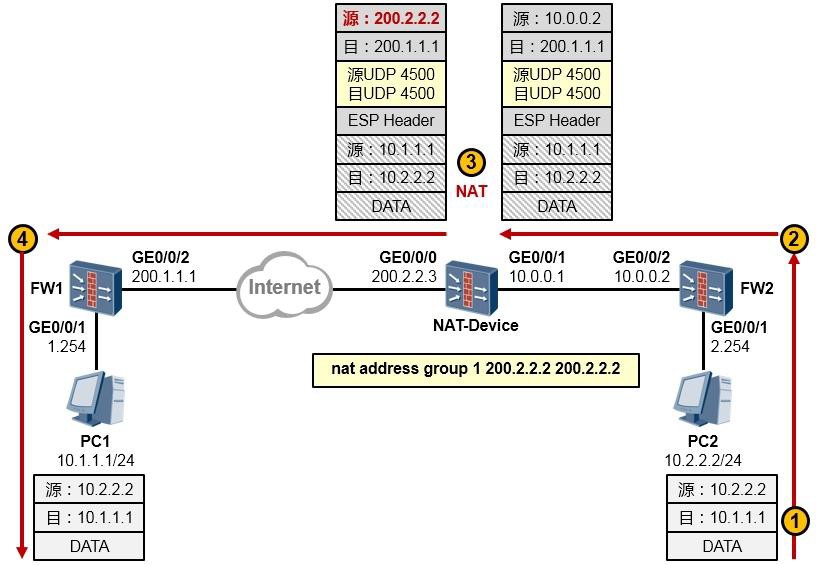
IPSecVPN的NAT穿越配置示例(NAT address-group场景)¶
实验拓扑及IP编址如上图所示。FW1及PC1为站点1的设备;NAT-Device、FW2及PC2为站点2的设备;
FW1及FW2为IPSecVPN网关,两者之间部署LAN to LAN IPSecVPN;NAT-Device上部署了NAPT源地址转换,申请到的、用于地址转换的公网IP是200.2.2.2。Internet可使用一台路由器模拟,只配置接口IP,不配置任何路由信息。
注意在本场景中,FW1上部署基于模板的IPSecVPN(因为FW2侧部署了源NAT,因此FW1可能事先无法知道FW2的公网地址),FW2作为IPSecVPN隧道协商的发起端。
请注意,本案例采用Eudemon1000E-X防火墙举例讲解,不同的防火墙型号,在配置上存在差异。
FW1的配置如下(省略接口IP、安全区域配置等):¶
#配置默认路由:
[FW1] ip route-static 0.0.0.0 0.0.0.0 200.1.1.2
#定义IPSecVPN感兴趣数据流,使用ACL3000来匹配感兴趣流量: [FW1] acl number 3000
[FW1-acl-adv-3000] rule permit ip source 10.1.1.0 0.0.0.255 destination 10.2.2.0 0.0.0.255
#配置IKE Proposal,这是IKE阶段一的策略: [FW1] ike proposal 1
[FW1-ike-proposal-1] authentication-method pre-share [FW1-ike-proposal-1] authentication-algorithm sha1 [FW1-ike-proposal-1] encryption-algorithm 3des-cbc
#配置IKE peer,定义预共享秘钥、关联IKE proposal并指定隧道对端节点IP地址: [FW1] ike peer fw2
[FW1-ike-peer-fw2] pre-shared-key Huawei123 [FW1-ike-peer-fw2] ike-proposal 1
[FW1-ike-peer-fw2] nat traversal
#配置IPsec proposal,这是IKE阶段二的策略: [FW1] ipsec proposal myset
[FW1-ipsec-proposal-myset] transform esp
[FW1-ipsec-proposal-myset] esp authentication-algorithm sha1 [FW1-ipsec-proposal-myset] esp encryption-algorithm 3des
#配置IPsec policy模板:
[FW1] ipsec policy-template policy_temp 1
[FW1-ipsec-policy-template-policy_temp-1] security acl 3000 [FW1-ipsec-policy-template-policy_temp-1] ike-peer fw2 [FW1-ipsec-policy-template-policy_temp-1] proposal myset
#配置IPsec Policy:
[FW1] ipsec policy mymap 1 isakmp template policy_temp
#应用IPsec Policy到接口:
[FW1] interface GigabitEthernet0/0/2
[FW1-GigabitEthernet0/0/2] ipsec policy mymap
#放开防火墙自身到Untrust区域的流量,使得防火墙FW1能够主动发送ISAKMP、及隧道建立后的加密流量到FW2: [FW1] policy interzone local untrust outbound
[FW1-policy-interzone-local-untrust-outbound] policy 0
[FW1-policy-interzone-local-untrust-outbound-0] policy destination 200.2.2.2 0 [FW1-policy-interzone-local-untrust-outbound-0] action permit
#放开IPSecVPN隧道对端防火墙发送过来的流量:
[FW1] policy interzone local untrust inbound
[FW1-policy-interzone-local-untrust-inbound] policy 0
[FW1-policy-interzone-local-untrust-inbound-0] policy source 200.2.2.2 0 [FW1-policy-interzone-local-untrust-inbound-0] action permit
#放开对端站点内网过来的流量:
[FW1] policy interzone trust untrust inbound
[FW1-policy-interzone-trust-untrust-inbound] policy 0
[FW1-policy-interzone-trust-untrust-inbound-0] policy source 10.2.2.0 0.0.0.255
[FW1-policy-interzone-trust-untrust-inbound-0] policy destination 10.1.1.0 0.0.0.255 [FW1-policy-interzone-trust-untrust-inbound-0] action permit
#放开本地站点内网到对端站点内网的流量:
[FW1] policy interzone trust untrust outbound
[FW1-policy-interzone-trust-untrust-outbound] policy 0
[FW1-policy-interzone-trust-untrust-outbound-0] policy source 10.1.1.0 0.0.0.255
[FW1-policy-interzone-trust-untrust-outbound-0] policy destination 10.2.2.0 0.0.0.255 [FW1-policy-interzone-trust-untrust-outbound-0] action permit
FW2的配置如下(省略接口IP、安全区域配置等):
当PC2访问PC1时,流量将触发FW2与FW1进行IPSecVPN隧道的协商。
IKE阶段一的第1,2两个报文使用源、目的UDP端口500,流量在经过NAT设备时地址被转换,出现如下
NAT表项:
[NAT] display firewall session table
这些报文还会进行NAT Traversal的协商,及NAT设备的发现。经过协商后双方决定使用UDP端口4500
来进行报文交互,随后用于对等体验证的ISAKMP包使用UDP源、目的端口4500,流量在经过NAT设备时被地址转换,出现如下NAT表项:
udp VPN:public --> public 10.0.0.2:4500[200.2.2.2:2048]-->200.1.1.1:4500
在IPSecVPN隧道建立起来后,受保护的流量依然会使用UDP4500端口进行通信,由于NAT设备已经有了上述表项,因此报文同行畅通(当然,在IPSecVPN隧道建立起来之后,由于NAT设备已经有了相关的表项,因此PC1也可以主动发起流量访问PC2)。
VPN Client客户端通过L2TP over IPSec拨入防火墙¶
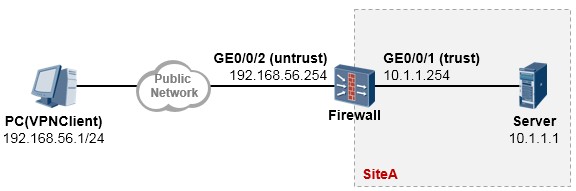
所谓“IPSecVPN远程拨入场景”,也就是用户从公网通过VPN拨入防火墙,从而对防火墙所保护的内网资源进行访问。在上图所示的场景中,PC及Firewall都接入一个公共网络(Public network),Firewall的GE0/0/1接口连接着SiteA的内网(Trust安全域),内网中有服务器Server。现在PC能够通过Public network访问到
Firewall的外网接口GE0/0/2。我们要在Firewall上部署IPSecVPN远程拨入,将Firewall配置为一台VPN服务器,使得客户端能够通过Public network,使用VPN客户端软件拨入Firewall,从而访问SiteA的内网资源。在本方案中,PC需使用VPN客户端软件进行拨号,拨号成功后,PC与防火墙之间会建立一条加密的隧道, 同时PC会获得一个SiteA所分配的内网地址,它可使用该地址直接对开放的内网资源进行访问。
注意:本例中所使用的防火墙是Eudemon1000E-X。不同的防火墙型号,在配置上存在差异。
IP地址资源的规划如下:
| 使用方 | 地址 | 备注 |
|---|---|---|
| PC(VPN客户端) | 192.168.56.1/24 | 网关192.168.56.254。 |
| Interface virtual- template 1 | 192.168.255.1/24 | 这个地址是VPN客户端拨号成功后,虚拟 |
| 网卡的网关地址。可自定义。 | ||
|---|---|---|
| PC的地址池 | 1.1.1.1至1.1.1.100 | VPN客户端成功拨入后,防火墙所分配的 动态地址池。这个地址池最好与内网业务的网段区分开,可单独规划一个地址段。 |
Firewall的基础配置如下:
Firewall的VPN服务配置如下:
authentication-algorithm sha1 encryption-algorithm des-cbc dh group2
#配置IKE对等体: ike peer peer1
exchange-mode aggressive local-id-type fqdn lns
ike-proposal 1
pre-shared-key abcde remote-id-type fqdn client1
注:如果是在*eNSP*模拟器中完成该实验,则上述配置(*IKE*对等体的配置)改为:
ike peer peer1
exchange-mode aggressive local-id-type fqdn
ike-proposal 1
pre-shared-key abcde remote-id client1
quit
ike local-name lns
#配置VPN感兴趣数据流,1701端口为防火墙作为隧道响应端处理L2TP报文的端口: acl number 3001
rule permit udp source-port eq 1701
#配置IKE第二阶段的策略:
ipsec proposal p1
esp encryption-algorithm des
esp authentication-algorithm md5
# 配置IPSec安全策略,本端使用模板方式建立IPSec安全策略,用来接收不同PC发起连接:
ipsec policy-template template1 1 ike-peer peer1
proposal p1 security acl 3001
ipsec policy mypolicy 1 isakmp template template1
#在Firewall的外网接口上应用IPSec Policy: interface GigabitEthernet 0/0/2
ipsec policy mypolicy 假设目前防火墙的缺省域间包过滤规则是deny any,那么我们还需要在防火墙上配置untrust到local的域间安全策略,使得Public network的用户发起的VPN流量能够顺利被防火墙处理:
完成上述配置后,在PC上安装VPN Client(此处以Huawei VPN Client V100R001C02SPC701为例)。
安装完成后,进入主界面,在下图所示的主界面中,点击新建按钮:

进入新建连接向导:
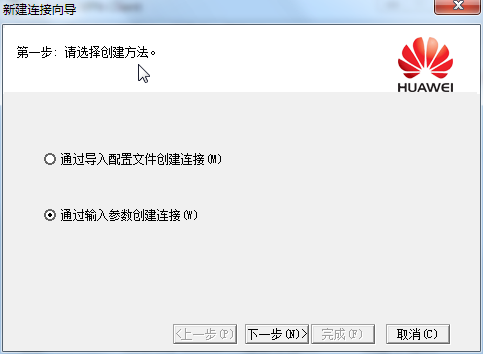
在上述界面中,选择通过输入参数创建连接,然后点击下一步:
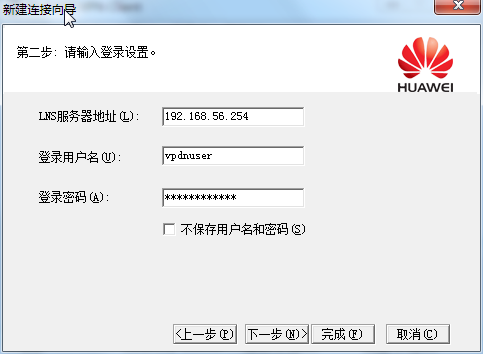
在上述界面中输入LNS服务器的地址192.168.56.254,也就是防火墙的外网接口地址,以及VPN账号及密码, 该账号及密码是使用local-user vpdnuser password cipher userpassw123命令在防火墙上定义的,所输入的内容需与防火墙的配置一致。完成后点击下一步:

在 上 述 界 面 中 输 入 L2TP 参数 , 其中 隧 道 验 证 密 码 字 段 对 应 防 火 墙 上 tunnel password cipher
TunnelPassw123命令所定义的密码,也就是TunnelPassw123。而预共享秘钥则对应pre-shared-key abcde
命令所定义的密码,也就是abcde。完成后点击下一步:
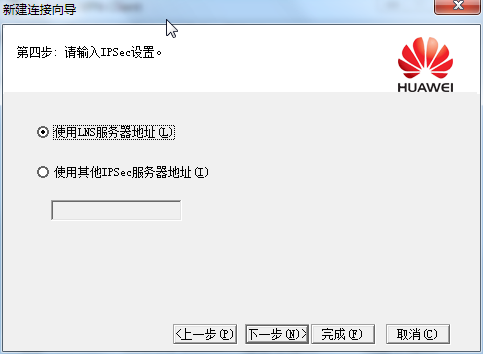
在上述界面中,选择使用LNS服务器地址。然后点击下一步:
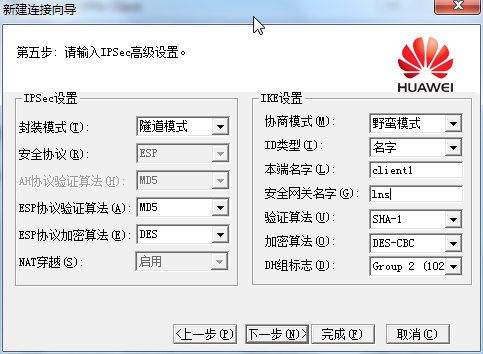
按照上述界面所示填写相关参数。点击下一步,然后完成配置。

右键刚创建好的连接,点击连接按钮,开始VPN拨入:
连接成功后,客户在PC上查看到获取的IP地址:
在防火墙上也能查看到相关信息:
在防火墙上查看IKE SA:
在防火墙上查看IPSec SA:
完成上述配置后,客户端已经能够正常拨入Firewall,在PC拨号的过程中,应该能在Firewall上查看到如下
会话:
注意,此时虽然PC已经成功拨入了Firewall,但是还不能够访问内网资源(假设当前防火墙的缺省域间包过
滤规则是deny any)的。实际上,拨号成功后,PC与Firewall之间就建立起一条加密的隧道,从这个层面上看,我们可以形象地将PC理解为逻辑上是直接连接在Firewall上的,而且属于interface Virtual-Template 1 这个接口所加入的安全域。因此,为了让PC能够正常访问站内资源,我们还要将Virtual-Template放置到安全域,并且配置Virtual-Template所在安全域到trust域的策略,使得VPN客户端在拨入成功后,能够使用所分配的IP地址访问内网资源:
如此一来,PC即可访问10.1.1.1。
站点内私网地址冲突时的LAN-to-LAN IPSecVPN部署¶
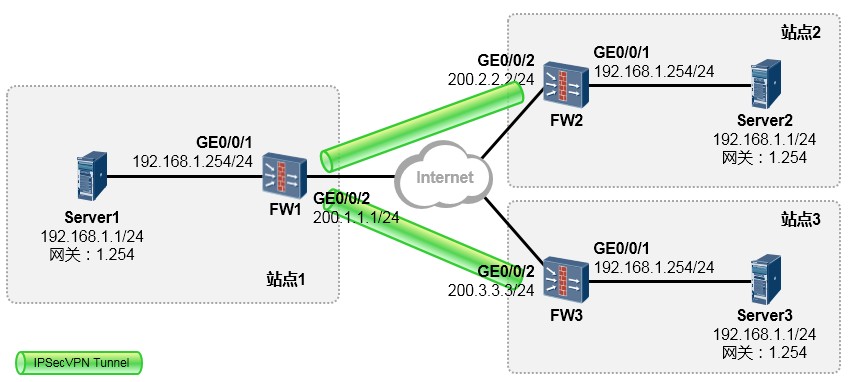
在上图所示的场景中,X公司存在三个站点,其中站点1是主站点,站点2及3是分支站点。3个站点的防火墙都通过广域网链路接入Internet。现在,客户要求在站点1与站点2、站点1与站点3之间部署LAN-to-LAN
IPSecVPN(如图所示),最终使得Server1与Server2、Server1与Server3能够安全地互通。有趣的是,每个站点的Server都使用了重叠的私网IP地址,以图中的服务器为例,3个站点的Server,都使用192.168.1.1 这个IP地址。显然,客户并不希望调整网络的IP编址以便适应新的需求,因此我们只能从方案的角度思考是否可以解决这个问题。
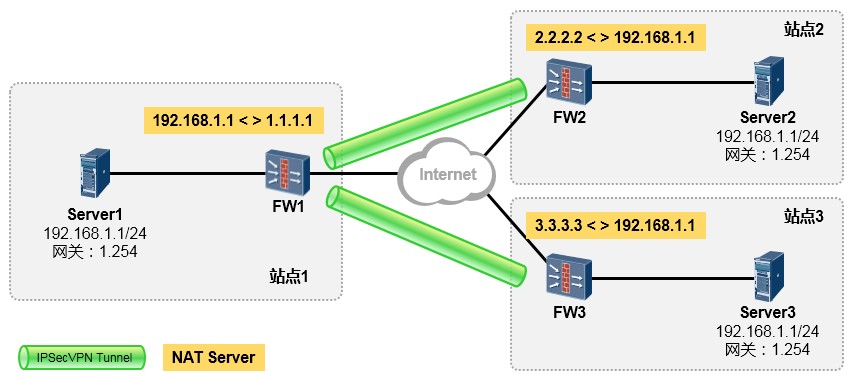
简单地说一下实现思路:首先在每个站点的防火墙上部署NAT Server,将本站点Server(192.168.1.1)映射到一个公网地址,例如在FW1上,将192.168.1.1映射到1.1.1.1;在FW2上将192.168.1.1映射到2.2.2.2; 在FW3上将192.168.1.1映射到3.3.3.3,如上图所示。接下来,在FW1与FW2之间、FW1与FW3之间部署
IPSecVPN隧道。以FW1为例,其与FW2之间的IPSecVPN隧道的感兴趣流量是从1.1.1.1访问2.2.2.2的流量; 而FW2与FW1之间的IPSecVPN隧道的感兴趣流量是从2.2.2.2访问1.1.1.1的流量;同理,FW3与FW1之间的IPSecVPN隧道的感兴趣流量是从3.3.3.3访问1.1.1.1的流量。
完成IPSecVPN及NAT的部署后,我们来分析一下数据包交互的过程(如下图所示)。以Server1访问Server2 为例,访问时需使用目的地址2.2.2.2,流量到达FW1后,先执行NAT,源IP地址被转换成1.1.1.1,随后报文被路由到出接口GE0/0/2,碰撞到部署在出接口上的IPSec Policy,因为流量匹配IPSecVPN感兴趣流量,从而数据被加密、哈希,然后封装一层隧道头部。处理后的报文被发往FW2。FW2将报文的隧道头部剥除, 进行完整性校验、解密,得到明文,随后将报文的目的IP地址2.2.2.2转换成192.168.1.1,最后发往本站点
Server1。Server间的其他互访流量同理。
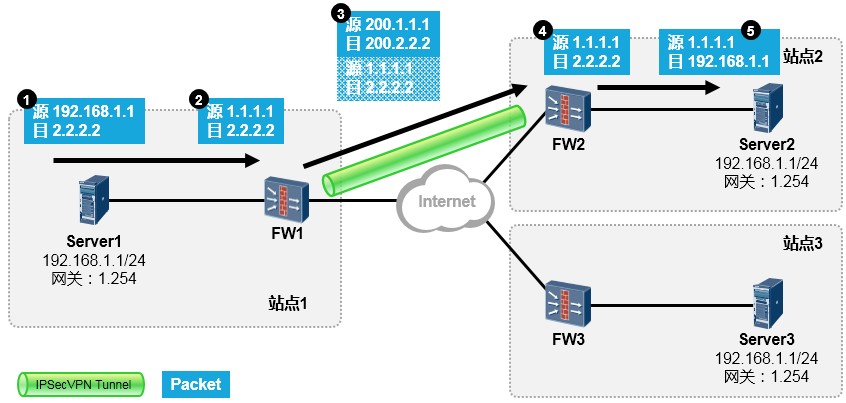
本文重点关注IPSecVPN的配置,防火墙的接口配置、接口加Zone、安全策略等姑且忽略。
FW1的关键配置如下:
FW2的关键配置如下:
FW3的关键配置如下:
完成配置后,从Server1 ping Server2时,可以在FW1上看到如下Session:
可以在FW2上看到如下Session:
其中esp是加密后的报文。
NGFW:接入用户采用VPN Client软件通过L2TP over IPSec方式接入总部VPN¶
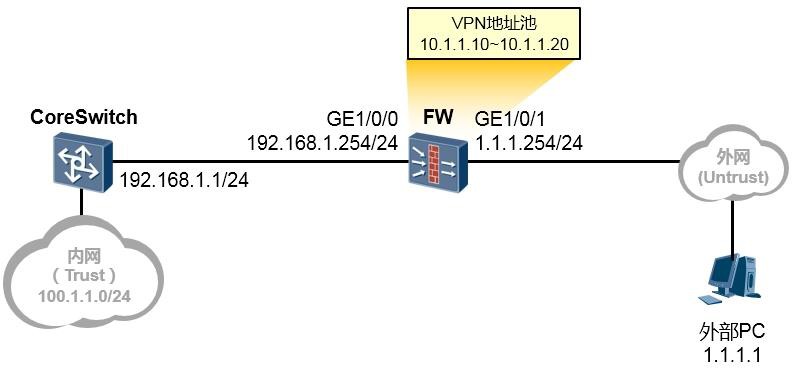
远程用户采用VPN Client软件通过L2TP over IPSec方式接入总部VPN,是一种常见的拨入式VPN应用。本例中的防火墙为E1000E-N(NGFW),并且软件版本为V5R1C10。网络拓扑如上图所示,其中外部PC安
装了HUAWEI VPN Client软件,该PC连接到了外部网络,而且它可以通过外部网络到达防火墙FW。现在的需求是:外部PC通过拨号的方式,连接到FW所保护的内部网络,并且可以访问100.1.1.0/24。
本例在FW上部署L2TP over IPSec,使得外部PC能够使用指定的账号拨入,拨入成功后,外部PC将获得
10.1.1.0~10.1.1.20范围内的IP地址,并且直接访问目标网段100.1.1.0/24。
防火墙FW(注意,本例以软件版本V5R1C10为例,不同的软件版本,配置方式有所不同)的配置如下:
以上是一些基本配置,接下来开始L2TP Over IPSec的配置:
l2tp enable l2tp-group 1
allow l2tp virtual-template 1 remote remoteTunnelName tunnel name lns
tunnel authentication
tunnel password cipher TunnelPwd123
-
接下来开始IPSec的相关配置:
#创建ACL3000,用于匹配L2TP流量,这些流量需要受IPSec保护(加密、验证):
acl 3000
rule permit udp source-port eq 1701 rule permit udp destination-port eq 1701
#配置IPSec安全提议: ipsec proposal tran1
transform esp
esp authentication-algorithm sha1 esp encryption-algorithm aes-256
#配置IKE安全提议:
ike proposal 10
authentication-method pre-share authentication-algorithm sha1 encryption-algorithm 3des
dh group5
#配置IKE对等体: ike peer a
ike-proposal 10
pre-shared-key IPSecPreSKey123
#配置IPSec策略模板,名称可自定义,此处为policy_temp,在其中关联ACL3000、IPSec安全提议以及对等体:
ipsec policy-template policy_temp 1 security acl 3000
proposal tran1 ike-peer a
#创建IPSec策略mypolicy,在序号10(序号可自定义)中指定IPSec策略模板: ipsec policy mypolicy 10 isakmp template policy_temp
完成上述配置后,外部PC安装VPN客户端软件,此处以Secoway VPN Client软件为例。在VPN Client软件的主界面中,点击“新建”按钮:
弹出如下界面:
在以上弹出的界面中,选择“通过输入参数创建连接”,弹出如下界面:

在以上界面中,LNS服务器地址为防火墙外网接口的IP地址,用户名及密码则按照所配置的输入。完成后点击“下一步”:
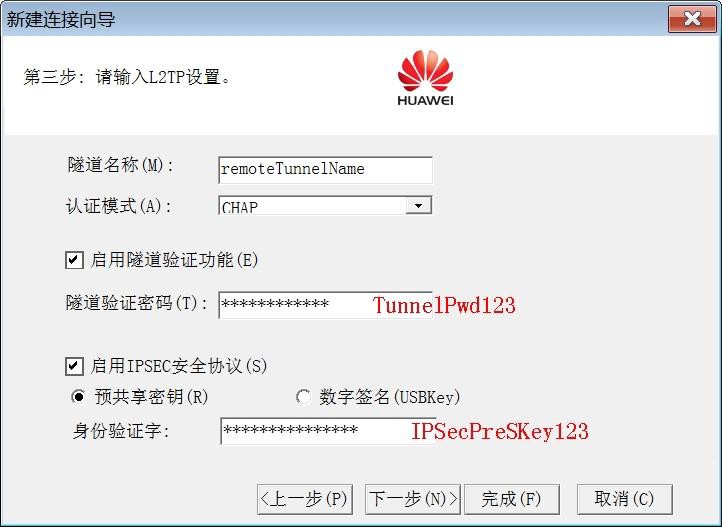
在以上界面中,按图示输入隧道名称、隧道验证密码以及IPSec预共享密码,在本例中,这些密码我都特意设置成与其功能有一定关联性的字符串,以便帮助读者理清密码的对应关系。完成后点击“下一步”:

在以上界面中,选择“使用LNS服务器地址”, 完成后点击“下一步”:
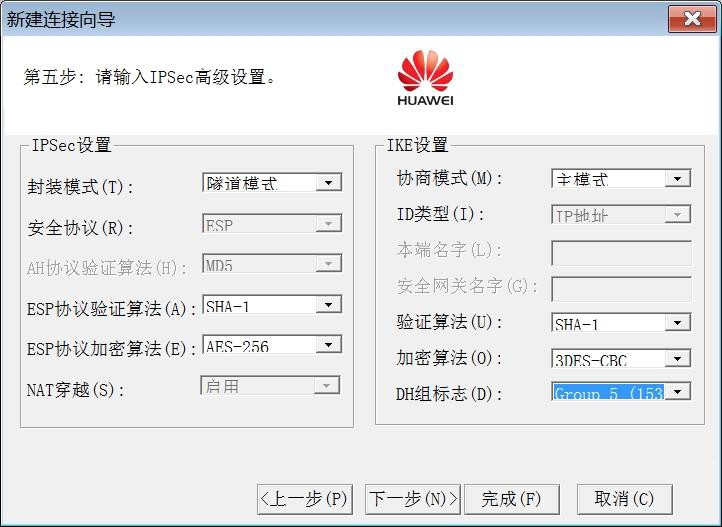
在以上界面中,选择与防火墙FW所匹配的IKE安全提议、IPSec安全提议。需注意的是,VPN Client软件所支持的加密、验证算法可能会比防火墙所支持的更少,为了确保VPN拨号成功,防火墙要对应地迁就一下VPN Client,选择对方支持的算法。完成后点击“下一步”:

 在以上界面中,点击“完成”,VPN连接就创建好。我们可以在主界面中看到创建好的VPN连接,此时双击该连接即可触发VPN拨号。缺省时,用户VPN拨号成功后,在逻辑上便会被认为与防火墙直连,并且只能访问防火墙所保护的内部网络。
在以上界面中,点击“完成”,VPN连接就创建好。我们可以在主界面中看到创建好的VPN连接,此时双击该连接即可触发VPN拨号。缺省时,用户VPN拨号成功后,在逻辑上便会被认为与防火墙直连,并且只能访问防火墙所保护的内部网络。
‘
如果希望客户端在拨入VPN之后,除了可以访问内网100.1.1.0/24网段,同时还可以访问外部网络(例如
Internet),那么可以在VPN Client软件的界面上右击本次创建的“我的连接”图标,选择“属性”,弹出如下窗口:
在上述窗口中,勾选“连接成功后允许访问Internet”,出现“路由设置”选项卡,点击该选项卡,在该选项卡的界面中点击“添加”按钮,按如下输入:
完成上述操作后,重新拨号即可。上述操作的目的是让VPN Client软件拨号成功后,不在VPN虚拟网卡上设置默认网关,而是在客户端PC的路由表中写入一条到达100.1.1.0/24的路由,并将该路由的下一跳指定为10.1.1.1(防火墙Virtual-Template 1接口的IP地址)、出接口为VPN虚拟网卡。
如此一来,当VPN客户端访问Internet时,流量可以从物理网卡出去,而当客户端访问100.1.1.0/24时,流量会从VPN虚拟网卡出去,并进入L2TP隧道、被加密后送往防火墙。
拨号成功后,客户端显示如下:
在防火墙上查看L2TP隧道:
1)本案例可在eNSP中完成,需在eNSP中配置Cloud,并与电脑的网卡进行桥接。
2)在本例中,CoreSwitch必须拥有到达10.1.1.10~10.1.1.20这些IP地址所在网段的路由,并且路由的下一跳需为防火墙。最简单的方式,即在CoreSwitch上配置到达10.1.1.0/24的静态路由,下一跳为FW。
配置案例1:NGFW双机主备场景下采用OSPF连接外部网络时部署¶
IPSecVPN¶
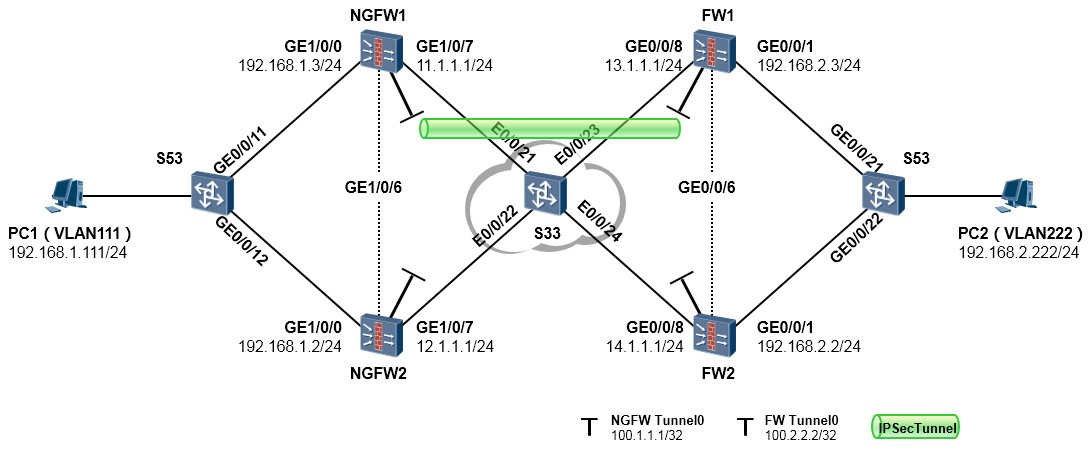
在上图所示的场景中,两个站点的网络设备通过中间的外部网络进行对接。NGFW1及NGFW2(E1000E-
N,软件版本为V1R1C30)是站点1的设备,而FW1及FW2(E1000E-X)是站点2的设备。两个站点的防火墙通过点对点链路、采用OSPF路由协议与外部对接。
现在,我们要在两个站点的防火墙之间部署Site-to-Site IPSecVPN,使得两地内网的用户(图中的PC1与
PC2)能够安全地通信、能够采用实际内网IP地址进行互通。网络正常时,NGFW1是站点1的主用墙,而
FW1则是站点2的主用墙,两地内网的互通流量通过两台主用墙之间建立的IPSecVPN隧道进行交互。当
NGFW1或FW1(或其外网线路)发生故障时,两地内网互访的流量可以平滑地切换。
这个方案的特点在于,以双机主备方式工作的防火墙对外与路由设备对接,而且运行了动态路由协议
(OSPF),我们要在这个场景中部署IPSecVPN,要求VPN隧道在主备墙之间能够实现高可靠性。实际上要实现这个需求,方案存在几种,本文将介绍基于Tunnel接口建立IPSecVPN隧道的方案。
在NGFW1及NGFW2上各创建一个Tunnel0接口,为该接口分配相同的IP地址(100.1.1.1/32),这样一来,两个防火墙对外可呈现出一个IP地址。当然这个IP地址需是外部网络中路由可达的,NGFW1及
NGFW2将该地址通过OSPF通告到外部网络(NGFW会自动将备墙通告的路由的Cost调大,使得访问
100.1.1.1/32的流量到达主墙)。同理站点2的FW1及FW2各自创建一个Tunnel0接口,且分配相同的IP地址(100.2.2.2/32),然后都将该地址通告到OSPF网络。随后两对防火墙部署基于Tunnel0接口的
IPSecVPN隧道。
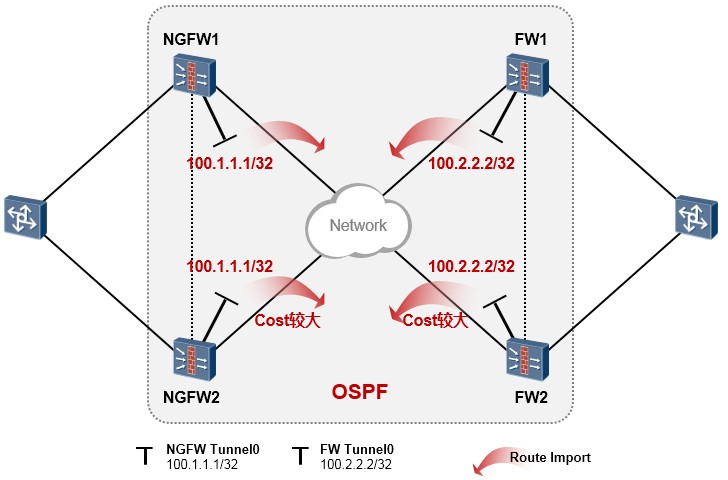
NGFW1的配置如下:
firewall zone untrust
add interface GigabitEthernet 1/0/7 firewall zone name ha
set priority 99
add interface GigabitEthernet 1/0/6
hrp interface GigabitEthernet 1/0/6 hrp mirror session enable
hrp ospf-cost adjust-enable hrp enable
ospf 1 router-id 1.1.1.1
area 0
network 11.1.1.1 0.0.0.0
quit
quit
# 将直连路由100.1.1.1/32通告到OSPF:
ip ip-prefix 1 permit 100.1.1.1 32
route-policy Direct_to_OSPF permit node 10 if-match ip-prefix 1
quit
ospf 1
import-route direct route-policy Direct_to_OSPF quit
# IPSecVPN部署:
acl number 3000
rule permit ip source 192.168.1.0 0.0.0.255 destination 192.168.2.0 0.0.0.255 quit
ike proposal 1
authentication-method pre-share encryption-algorithm 3des-cbc authentication-algorithm sha2-256 integrity-algorithm hmac-sha1-96 dh group2
quit
ike peer e1000ex ike-proposal 1
pre-shared-key Huawei123
remote-address 100.2.2.2 //100.2.2.2是对端站点防火墙的Tunnel0接口地址
undo version 1 //使用IKE v2对接
quit
ipsec proposal myset transform esp
esp authentication-algorithm sha1 esp encryption-algorithm 3des quit
ipsec policy mypolicy 1 isakmp security acl 3000
ike-peer e1000ex proposal myset
local-address 100.1.1.1 //100.1.1.1是本防火墙的Tunnel0接口地址
quit
int tunnel 0
ip address 100.1.1.1 32 //为Tunnel0接口配置IP地址
tunnel-protocol ipsec //Tunnel接口的封装模式为IPSec
ipsec policy mypolicy //将IPSec策略应用在Tunnel接口上
firewall zone untrust
add interface Tunnel 0 //注意,必须将Tunnel0接口加入安全区域 quit
ip route-static 192.168.2.0 24 tunnel 0 //这条路由非常关键,它用于将本地用户访问对端站点内网用户的 流量牵引到Tunne0接口,而Tunnel0接口则是IPSecVPN隧道的端点
# 配置安全策略,此处有两种安全策略需要关注,1是允许本防火墙与对端站点防火墙交互用于协商IPSecVPN隧道的相关报文的策略,2是允许本地内网用户与对端内网用户互访的策略:
security-policy
rule name IPsecVPN_From_Local source-zone local
destination-zone untrust
NGFW2的配置如下:
站点2的防火墙FW1的配置如下:
firewall zone trust
add interface GigabitEthernet 0/0/1 firewall zone untrust
add interface GigabitEthernet 0/0/8 firewall zone name ha
set priority 99
add interface GigabitEthernet 0/0/6
hrp interface GigabitEthernet 0/0/6 hrp mirror session enable
hrp ospf-cost adjust-enable hrp enable
ospf 1 router-id 3.3.3.3
area 0
network 13.1.1.1 0.0.0.0
quit
quit
#
ip ip-prefix 1 permit 100.2.2.2 32
route-policy Direct_to_OSPF permit node 10 if-match ip-prefix 1
quit
ospf 1
import-route direct route-policy Direct_to_OSPF
quit
# IPSecVPN部署:
acl number 3000
rule permit ip source 192.168.2.0 0.0.0.255 destination 192.168.1.0 0.0.0.255 quit
ike proposal 1
authentication-method pre-share encryption-algorithm 3des-cbc integrity-algorithm hmac-sha1-96 dh group2
quit
ike peer ngfw
ike-proposal 1
pre-shared-key Huawei123 remote-address 100.1.1.1
undo version 1 quit
ipsec proposal myset transform esp
esp authentication-algorithm sha1 esp encryption-algorithm 3des quit
ipsec policy mypolicy 1 isakmp security acl 3000
ike-peer ngfw proposal myset
local-address 100.2.2.2 quit
int tunnel 0
ip address 100.2.2.2 32 tunnel-protocol ipsec ipsec policy mypolicy
firewall zone untrust
add interface Tunnel 0 quit
ip route-static 192.168.1.0 24 tunnel 0
# 部署安全策略:
policy interzone local untrust inbound policy 10
action permit
policy source 100.1.1.1 0
policy destination 100.2.2.2 0 policy interzone local untrust outbound
policy 10
FW2的配置如下:
完成配置后,当PC1与PC2开始首次互访时,流量将触发防火墙进行IPSecVPN隧道协商,隧道建立后,PC1
与PC2即可实现相互通信。此时以NGFW1为例,查看IKE SA:
关键是查看IPSec SA:
当网络正常时,站点间互访流量的交互过程,以PC1访问PC2为例,报文被PC1送到网关,也就是NGFW1, 因为它是此时的主墙,报文的目的IP地址是192.168.2.222,也就是PC2的地址。NGFW1查询自己的路由表,发现需要将报文送至Tunnel0接口,因此判断报文从Trust区域进、Untrust区域出,然后检查安全策略,发现报文被允许通行。由于Tunnel0接口的封装类型为IPSec,加上该流量满足ACL3000(IPSecVPN感兴趣的数据流量)的规则,因此NGFW1在本地查询IPSec SA,然后将流量进行加密等操作,再封装一个新的IP头部,该IP头部的源地址为100.1.1.1,目的地址为100.2.2.2。NGFW1将处理过的报文转发到外部网络。外部网络将报文路由到FW1,由后者做完整性校验、解密等操作,最终将原始报文转发给PC2。如下图所示:
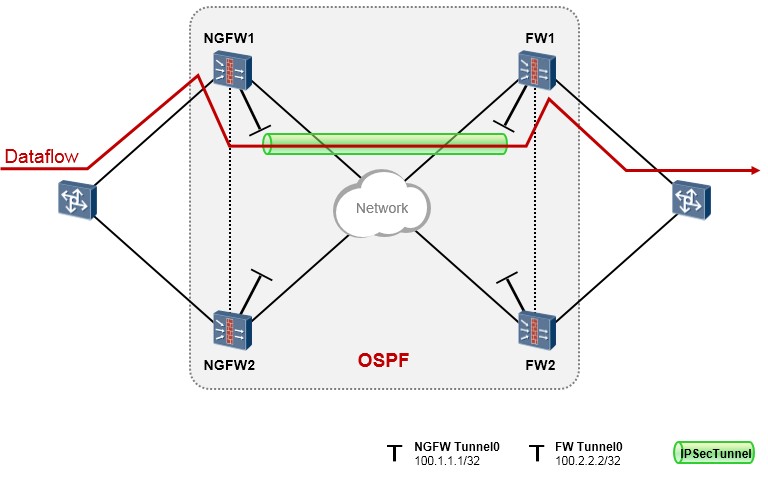
当NGFW1连接外网的连接发生故障时,立即发生主备切换,流量被吸引到NGFW2,此时由NGFW2已经拥有了主墙此前协商好的IPSec SA,因此可以立即将流量进行加密等处理,然后从隧道转发出去:
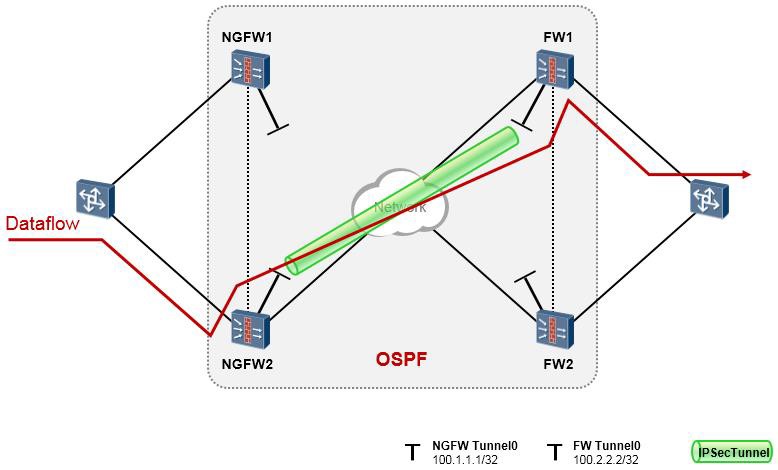
从实地测试的结果看,在PC1持续ping PC2的过程中,发生上述故障时,仅仅会丢失2个ICMP包,随后通信即可恢复正常。
网络管理¶
- SNMP
技术背景¶
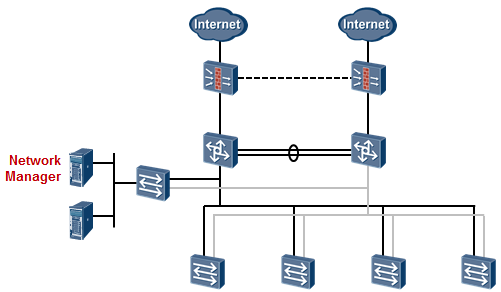
假设你作为一个网络的管理员,要实现对网络的管理,要知道每台网络设备的运行状况,并且在网络设备发生一些关键性事件的时候第一时间捕捉到,该如何实现呢?这里就要用到SNMP(Simple Network Management Protocol)了。
随着网络业务的日益发展,现有的网络中,设备数量日益庞大,且这些设备与网络管理员所在的中心机房距离较远。当这些设备发生故障时,如果设备无法主动上报故障,导致网络管理员无法及时感知、及时定位和排除故障,那么将导致网络的维护效率降低,维护工作量大大增加。
利用SNMP简单网络管理协议,网管服务器可以远程询问设备的状态,同样设备也能够在特定类型的事件发生时向网络管理工作站发出警告。SNMP是规定网管站和设备之间如何传递管理信息的应用层协议。SNMP定义了网管管理设备的几种操作,以及设备故障时能向网管主动发送告警。
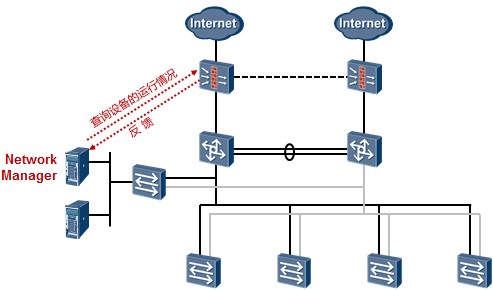
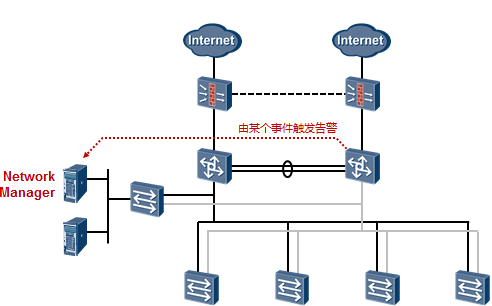
网管使用SNMP协议管理设备时,存在网管站、Agent和被管理设备三个角色。关于角色、MIB和操作的定义和作用请参考下面的具体内容。
SNMP概述¶
SNMP(Simple Network Management Protocol,简单网络管理协议)是广泛用于TCP/IP网络的网络管理标准协议,是一个公有的标准。SNMP提供了一种通过运行网络管理软件的中心计算机(即网络管理工作站NMS)来管理网元的方法。共有三个版本SNMPv1、SNMPv2c和SNMPv3,用户可以根据情况选择同时配置一个或多个版本。
SNMP的角色认知¶
- **网管站(Network Management Station):**向被管理设备发送各种查询报文,以及接收被管理设备发送的告警。在实际的网络环境中就是安装了网管软件的服务器。
- **被管理设备(Devices):**也就是网络中的各种接受网管的设备,常见的如路由器、交换机、防火墙以及其他支持SNMP管理的设备。
- **代理(Agent):**驻留在被管理设备上的一个进程。Agent的作用如下。
- 接收、解析来自网管站的查询报文。
- 根据报文类型对管理变量进行Read或Write操作,并生成响应报文,返回给网管站。
-
根据各协议模块对告警触发条件的定义,当发生某个事件(如端口UP/DOWN,STP拓扑变更、
OSPF邻居关系DOWN掉等)的时候,主动触发一个告警,向网管站报告该事件。
SNMP的基本工作原理¶
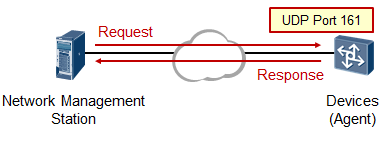
上面是一个最简化的呈现方式,我们只需要保证被网管设备与网关站之间是IP可达的,就可以利用
SNMP实现网管。一种典型的网管方式是NM Station发送相关的报文去查询被网管设备的相关运行信息
(例如查看设备的CPU利用率),被网管设备针对这个查询进行响应,此时,NM Station访问的是被网管设备的UDP161端口。
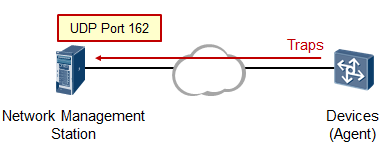
另一种典型的网管方式是,被网管设备在某个事件发生后,触发了一个告警,它将该告警通过Trap报文发往NM Station的UDP 162端口。从而网管站能够在第一时间了解到网络中的各种突发事件。
MIB¶

想象一下每一个被网管的设备都有一棵“树”,这棵树有许多分支和节点,在节点上挂着果实,要了解该设备的某个信息,就去摘取一个特定的果实,这棵树就是MIB。
每一个被网管设备的Agent都维护一个MIB库,MIB(Management Information Base,管理信息库)是一个类似于树形结构的数据库,其中含有大量对象(Objects),这些对象中存储着该设备的各种信息, 而MIB就是所有对象的集合。可以通过对MIB的读取或写入来实现对设备的管理,下图就是MIB的一个简单呈现:

MIB是以树状结构进行存储的,树的节点表示管理对象Object,在对象中就存储着可用于网管的信息, 对象可以用从根Root开始的一条路径来唯一的识别,这就是OID(Object Identifier,即对象标示符),
通过OID就可以准确的定位到某个对象,例如下图中,要找internet节点,就使用{1.3.6.1}:

通过OID树,可以高效且方便地管理其中所存储的管理信息,同时也方便了对其中的信息进行批量查询。
特别地,当用户在配置Agent时,可以通过MIB视图来限制NMS能够访问的MIB对象。MIB视图实际上是MIB的子集合。
目前SNMPv1 在现网中已经几乎不再使用, SNMPv2c 也不建议使用, SNMPv3 的实现原理和
SNMPv1/SNMPv2c基本一致,唯一的区别是SNMPv3增加了身份验证和加密处理。出于安全考虑,建议使用SNMPv3。
- SNMPv3 的基础配置
SW为以太网交换机(以S5300交换机的V2R3系统软件版本为例),按图中所示连接着网络管理系统(NMS),典型的NMS如I2000。完成SW的配置,使得NMS能够通过SNMP管理SW,而且SW也能够将告警通过SNMP
Trap上报给NMS。
SW的关键配置如下:
注意:上述配置仅呈现交换机SNMP及告警相关的配置,其他的诸如交换机VLAN、Vlanif及接口类型等配置不再赘述。
注意事项:¶
-
在部署网络设备与NMS(例如I2000网管系统)对接时,务必确保两者之间各项参数的绝对匹配,例如
SNMP版本、SNMP加密或鉴权方式及密码等等。
-
要求采用SNMPv3版本进行部署,而不是安全性较低的SNMPv2c或SNMPv1。
- 在实际部署网络设备与NMS的对接时,建议首先确保两者之间通信的正常,以交换机为例,可在设备上ping网管系统。在测试设备告警时,需在设备上执行带源IP地址的ping测试,其中源IP地址为设备告警报文的源IP地址,也就是snmp-agent trap source命令所指定的接口IP地址,缺省时,该IP地址为告警报文出接口的IP地址。
- NTP 的基础配置
- 网络中部署了NTP服务器(NTPServer),为主机及网络设备提供时钟源。
-
完成SW的配置,使得SW能够与NTPServer同步时钟。
SW的配置如下:
说明:其中192.168.1.1是NTP服务端设备,服务端设备可以是Linux平台的服务器,也可以是网络设备。华
为S系列交换机支持的NTP版本是1-3,缺省使用的是版本3。如果NTP服务器是Linux操作系统,并且使用
NTPv4,是可以与交换机的NTPv3兼容的。如果双方激活了authentication,那么要确保两端authentication-
keyid和Key都是分别一致的。
组播技术¶
- 组播基础
- 组播概述
什么是单播(Unicast)¶
- 单播通信应该是我们现实中见得最多的通信方式,几乎随处可见。
- 所谓的单播,就是一对一的数据通信过程,一个单播数据包只发给一个特定的目标设备,这个目标设备是数据包的目的IP地址的拥有者。
- 当源需要将一份相同的数据同时发送给多个接收者时,源需发送与接收者数目相同的单播数据包。这种需求常见于多媒体直播等业务。
- 当接受者增加到成百上千时,将极大加重服务器为相同数据创建和发送多份拷贝的负担,网络设备也将承受更大的性能损耗。例如视频类的服务,如果采用单播的方式实现,恐怕就有比较大的短板。
- 当源需要将一份相同的数据同时发送给多个接收者时,源需发送与接收者数目相同的单播数据包。这种需求常见于多媒体直播等业务。
- 所谓的单播,就是一对一的数据通信过程,一个单播数据包只发给一个特定的目标设备,这个目标设备是数据包的目的IP地址的拥有者。
什么是广播(Broadcast)¶
- 广播数据包被限制在广播域中;广播域的一个典型的例子是VLAN,一个VLAN就是一个广播域。路由器能够隔离广播域,广播数据包到达路由器的三层接口后,即到达了传播的边界。
- 在一个广播域中,一旦有节点发送广播数据,那么广播域内的所有设备都会收到这个数据包并且不得不耗费资源去处理,大量的广播数据包将消耗网络的带宽及设备资源;
- 在IPv6中,广播的报文传输方式被取消;
- 因此在同一份数据存在多个接收者的场景下,广播依然不太合适。
- 在IPv6中,广播的报文传输方式被取消;
- 在一个广播域中,一旦有节点发送广播数据,那么广播域内的所有设备都会收到这个数据包并且不得不耗费资源去处理,大量的广播数据包将消耗网络的带宽及设备资源;
什么是组播(Multicast)¶
- 组播的数据传输方式是一对多的模型,只有加入到特定组播组的成员,才会收到发往该组的组播数据。以组播地址为目的地址的数据发往多个接收者。
- 当一个组内存在多个成员时,数据发送源无需每次发送多个数据拷贝,而是每次仅需发送一份即可,组播路由器(运行组播路由协议的路由器,此处也指其他类型的设备,例如交换机等)会根据需要转发或拷贝组播数据。
- 组播数据流只发送给加入该组播组的用户,而不需要该数据的设备则不会收到该组播流量。
- 相同的组播业务流量,在一段链路上仅有一份数据,大大提高了网络资源的利用率。
- 组播数据流只发送给加入该组播组的用户,而不需要该数据的设备则不会收到该组播流量。
- 当一个组内存在多个成员时,数据发送源无需每次发送多个数据拷贝,而是每次仅需发送一份即可,组播路由器(运行组播路由协议的路由器,此处也指其他类型的设备,例如交换机等)会根据需要转发或拷贝组播数据。
组播的特点和应用¶
组播的特点:
- 提高效率:在一对多的通信场景下,降低网络流量、减轻硬件负荷;
- 优化性能:在一对多的通信场景下,减少冗余流量、节约网络带宽、降低网络负载; 组播的应用:
- 组播适用于多接收者期望收取相同流量的场景;
- 组播适用于接收者地址(或位置)未知的场景;
- 多媒体直播;
- 培训、多媒体会议、联合作业场合的通信;
- 数据仓库、金融应用(股票)。
- 组播适用于多接收者期望收取相同流量的场景;
- 优化性能:在一对多的通信场景下,减少冗余流量、节约网络带宽、降低网络负载; 组播的应用:
- 组播模型
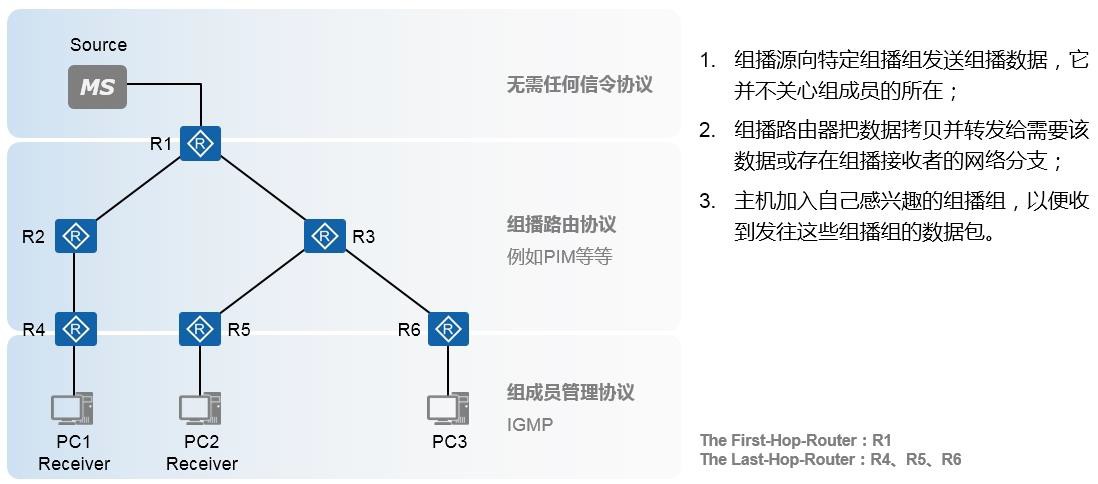
上图就是一个典型的组播模型。通常我们将组播模型分为三个模块。
组播源,与跟其直连的组播路由器(第一跳路由器)构成了第一个模块,这个模块中并没有特殊的信令或控制协议,组播源直接发送组播数据,第一跳路由器会收到这些组播数据。
网络中的组播路由器,也就是运行组播路由协议的路由器构成了第二个模块。网络中的这些组播路由器都将运行组播路由协议,组播路由协议工作的目的就是在网络中构建出一棵无环的组播分发“树”,使得组播流量从第一跳路由器沿着构建好的组播分发树转发到每一个组播用户所在的网段,而对于不需要这些组播数据的用户或网络分支则不会收到组播流量。
组播接收者与其直连的路由器(最后一跳路由器)构成了第三个模块。在这个模块中,有一个协议非常需要关注,那就是IGMP(因特网组管理协议),这个协议帮助最后一跳路由器了解其接口所连接的网段中是否存在组播组的成员,同时协助维护组成员关系。组播用户(终端设备)如果要加入组播组,则使用IGMP协议报文进行申请,而最后一跳路由器也使用IGMP协议报文去查询直连的网段中是否存在组成员。
组播网络的正常工作正是由上面我们所描述的各个组件协同工作而实现的。
- 组播分发树
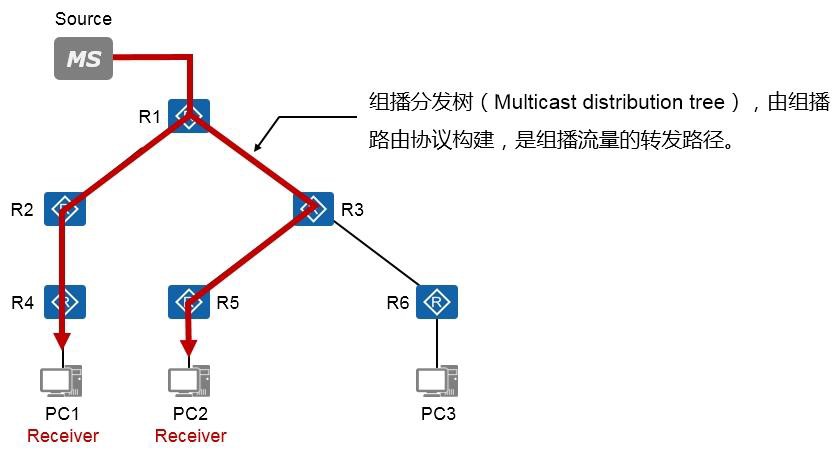
- 组播地址
组播IP地址空间¶
在IPv4地址空间中,D类地址(224.0.0.0/4)被用于组播。组播IP地址代表一个接收者的集合。IANA对
D类地址做了进一步的定义,几种主要的组播地址如下表所示:
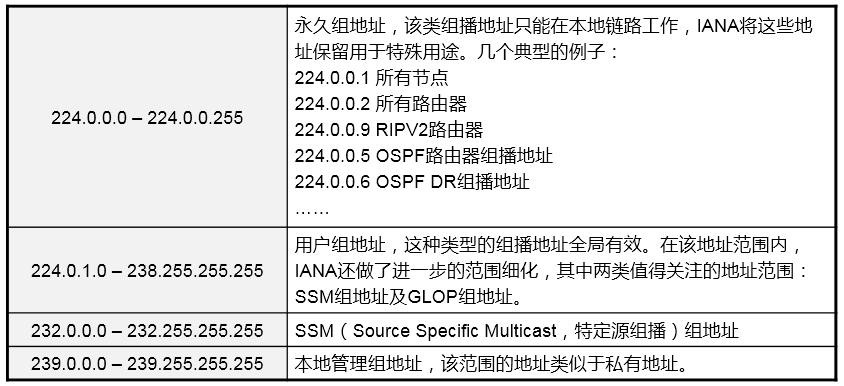
组播IP地址是组播组的标识符。一个典型的组播应用场景是视频直播。例如某个视频直播频道使用组播
IP地址239.1.1.1作为业务地址,那么该视频直播的发送源(可能是一台多媒体服务器)会持续以该组播地址为目的IP地址发送组播数据,这些组播数据会被送入组播网络,组播网络中的组播设备(例如组播路由器或者组播交换机)会根据需要复制及转发这些组播报文,最终组播报文沿着一条无环的路径到达组播接收者所在的网段。在该场景中,组播接收者可能是一些需要观看该视频直播的PC,它们必须通过IGMP协议报文宣告自己加入了239.1.1.1这个组播组,随后,开始侦听发往239.1.1.1的组播数据。
组播IP地址与MAC地址的映射¶

在以太网中,IP数据包必须增加以太网封装,才能在以太网链路上传输。在以太网封装的帧头中,需写入该数据帧的源和目的MAC地址。对于单播数据而言,其IP包头中的目的IP地址是单播地址,而以太
网帧头中的目的MAC地址则是链路层面上的下一跳设备的MAC地址,该MAC地址也是单播地址。对于一个组播数据而言,其目的IP地址当然是组播IP地址,那么它的目的MAC地址呢?当然,不可能是一个单播MAC地址,因为该数据发往一组接收者,而不是单一的接收者。实际上,此处使用的MAC地址必须是组播MAC地址。那么,我们就需要明确组播IP地址与组播MAC地址的映射关系。当一个组播IP 报文被封装以太网帧头时,设备会根据报文的组播IP地址进行映射,从而得到对应的组播MAC地址, 将其写入帧头的目的MAC地址字段中。下图描述了一个组播IP地址到对应的组播MAC地址的映射关系:
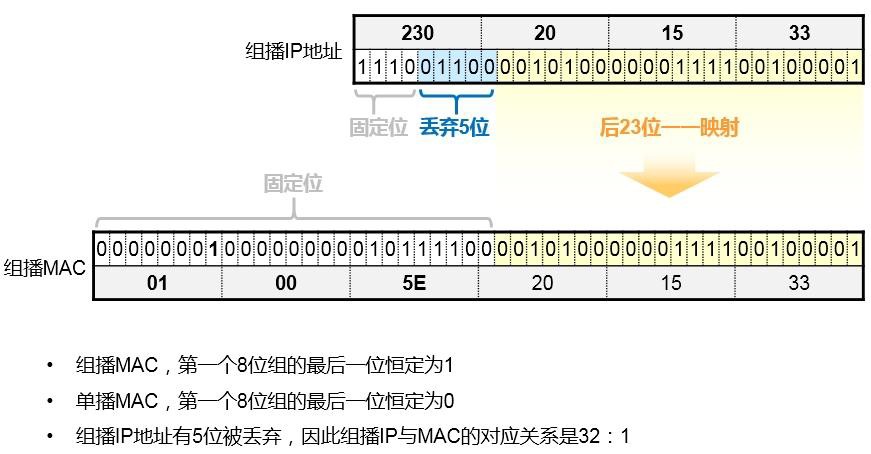
- IGMP
- IGMP 概述
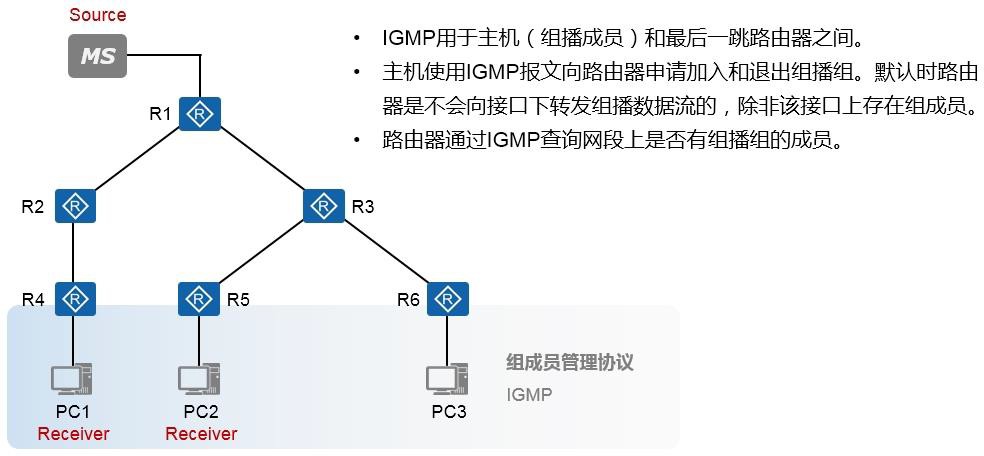
IGMP(Internet Group Manage Protoco,因特网组管理协议l)用于主机和最后一跳路由器之间。最后一跳路由器是直连组播组成员的路由器,它需要一种协议来解决组成员管理的问题,IGMP就是用来解决这类问题的。
主机使用IGMP协议报文向路由器申请加入和退出组播组。当路由器从接口上收到直连网段中的主机发送出来的IGMP协议报文且该报文用于宣告其加入组播组时,路由器也就知道了在该直连网段中存在特定组播组的成员,从而当路由器收到发往该组播组的流量的时候,就会向该接口转发。另一方面,路由器通过IGMP 协议报文查询网段上是否有组播组的成员。
IGMP是3层协议,直接被封装在IP中,协议号为2,IGMP数据包只在本网段内有效,报文的TTL参数为1。到目前为止,IGMP有三个版本:
- IGMPv1版本(由RFC 1112定义),已经基本不再使用。
- IGMPv2版本(由RFC 2236定义)
- IGMPv3版本(由RFC 3376定义)
IGMPv1(RFC1112)¶
报文格式¶

IGMPv2的报文格式如上,一共有两种报文:
- 当TYPE字段为1时,报文为成员关系查询(Host membership query)
-
当TYPE字段为2时,报文为成员关系报告(host membership report)
Version字段的值恒定为1,因为这是IGMPv1的报文。
对于Group address字段,当报文为成员关系报告时一般该字段填充为特定组播组的IP地址,当报文为成员关系查询时,本字段为全0。
-
报文发送时各项字段的内容¶
| 成员关系查询 | 成员关系报告 | |
|---|---|---|
| 源IP地址 | 路由器接口IP | 主机接口IP |
| 目IP地址 | 224.0.0.1 | 组播组IP |
| TTL | 1 | 1 |
| 报文中的Group Address | 0.0.0.0 | 组播组IP |
IGMPv1查询及响应过程¶
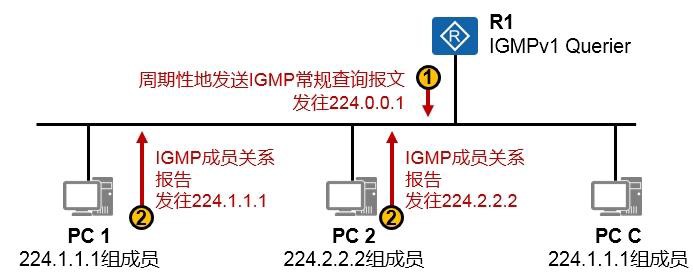
R1作为这个子网中的IGMPv1查询器,会周期性地(默认60s一次)下发IGMPv1成员关系查询报文来询
问这个子网中是否存在组播组的成员。注意,IGMPv1的成员关系查询不能针对特定的组播组,只能进行普遍组(也就是所有组)查询,该查询包的目的地址是224.0.0.1(所有主机),且报文中group address 字段为0.0.0.0。
主机们收到了查询包,纷纷发送IGMPv1成员关系报告,如PC1向224.1.1.1发送,PC2向224.2.2.2发送成员关系报告。PC3比较特殊,它可能动作慢一点,还没发呢就收到了PC1的成员关系报告(这里其实有个report delay的随机计时器,当终端收到一个查询后,会产生一个随机时间,这个时间倒计时为0后才发送成员关系报告,而当终端收到同一个组播组的其他成员发出的成员关系报告后,自己就不再发了,因为只需要让查询器知道这个子网中有该组播组的成员即可,至于存在多少个,其实没必要知道。这样可以避免同组内的成员重复发送成员关系报告,起到优化网络流量的目的),发现是自己同一组播组的接收者,因此为了避免重复发送,就抑制了自己报告。
IGMPv1查询器¶
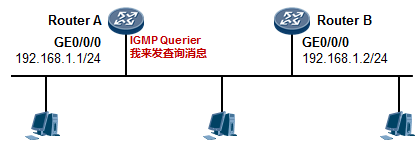
如果在同一网段中,存在多个IGMP路由器,就像上图,这种情况如果A和B都发IGMP查询,就显得有点多余了,因此在它们之间选出一个查询器(Querier),由这个查询器来发查询。但是RFC1112没有指定如何选择IGMPv1查询器,没办法,IGMPv1只能借助组播协议如PIM、DVMRP等。
IGMPv1加入机制¶
当子网中,有主机想加入某个组播组时,它可以无需等待查询器的下一个成员关系查询包的到来,而是直接向自己感兴趣的组播组的IP地址发送IGMPv1成员关系报告,来宣告自己加入组播组。
IGMPv1离开机制¶
IGMPv1没有定义主机退出组播组的机制,因此主机会“默默”离开。在子网中最后一个组播组成员离开后,IGMPv1会在一定的超时时间后就知道该组内没有成员了,于是便不会再向该子网转发组播流量。从这里可以看出,IGMPv1的离开机制实际上是不合理的,因为有可能子网中已经没有组播组的成员了, 组播路由器依然向该子网发送组播数据,直到一段时间后计时器超时发现确实没有组播用户了,才会停止转发组播数据。
IGMPv2(RFC2236)¶
报文格式¶
| 字段 | 描述 |
|---|---|
| Type | 不同Type字段对应不同的IGMPv2报文类型,请看报文类型小节 |
| Max Response Time | 最大响应时间(只在查询报文中设置,其他报文中为0x00)是主机 用成员关系报告来响应查询报文的最长等待时间,默认10s |
| Group address | 当报文为常规查询包时,该字段为全0;当报文为特定组查询报文时 该字段设置为所查询的组播组的地址。 当报文为成员关系报告或离组报文时,该字段的值设置为目标组播组地址。 |
报文类型¶
成员关系查询Membership Query(TYPE字段:0x11)¶
IGMPv2的成员关系查询包括两种报文:
常规查询General Query¶
常规查询报文又叫做普遍组查询,用于IGMP查询器的常规性的、针对所有组播组的查询。该报文的目的IP是224.0.0.1,报文中的组地址字段设置为0.0.0.0。
常规查询报文默认60s发送一次。
这个查询中同时包含Max Response Time,这个值告诉主机用成员关系报告报文回应这个查询的最长等待时间,该时间默认10s。
特定组查询Group-Specific Query¶
路由器的特定组查询报文是当子网中的主机发出离组报文而触发的,当路由器收到离组报文时,路由器知道有特定的组播组的成员要离开该组,它必须判断是否仍有该组播组的其他组员存在,因此使用该报文。报文的目的地址为发出离组报文的主机所在组的组地址。
为了避免特定组查询报文被意外丢弃或被破坏导致路由器误以为组内没有成员了,查询路由器以1s的时间间隔连续发送两个特定组查询报文,如果依然没有成员响应,路由器删除该组。
成员关系报告Membership Report(Type字段:0x16)¶
主机使用该报文宣告自己加入某个组播组。这个报文在一台主机第一次加入组播组时发送。另外, 也用来响应IGMP路由器发出的查询报文。该报文的目的地址是该主机期望加入的组播组地址。
Version1 Membership Report(Type字段:0x12)¶
作用同上,不过该报文是为兼容IGMPv1而设定的报文。
离组报告Leave Group(Type字段:0x17)¶
当主机要离开组播组时发送,该报文的目的地址为224.0.0.2。
这个报文包含主机期望退出的组播组的地址。当IGMP路由器收到一个离开报文的时候,会向这个特定组发送特定组查询报文,这样,如果这个组内还有其他PC,则有人会回应,如果没有人回应, 则路由器将不向该组发送组播报文。
查询及响应机制¶
IGMP路由器会周期性地向直连网段中发送IGMPv2常规查询报文。
PC1及PC3会收到这个查询包,随后会各自启动一个“报告延迟计时器”,这个计时器是由主机自己随机产生的,时间范围是0-10s(10s取自A发送的查询报文中的Max Response Time)之间的一个值,该计时器启动后开始倒计时,计数到0后主机就会发送IGMPv2成员关系报告。
假设在上图中,PC1的报告延迟计时器先计时到0,那么它会响应一个成员关系报告以便通知A路由器组播组224.1.1.1内有自己这么一个成员在。而此时PC3的报告延迟计时器还未超时,因此当它收到同一个组播组的PC1发送的成员关系报告后,将抑制自己的成员关系报告(因为没有必要重复发送),这样可以避免网络中出现大量的成员关系报告。
离开机制¶
- PC1要离开组224.1.1.1,它主动向网络中发送IGMPv2离组报文用于宣告自己离开组播组224.1.1.1,该报文的目的地址是224.0.0.2。
- R1收到该报文后,以1s为间隔连续发送IGMP特定组查询报文(共计发送2个),以便确认该网段中是否还有224.1.1.1组的其他成员。
- PC3仍然是组224.1.1.1的成员,因此它将立即响应该特定组查询。如此一来R1便知道该子网中仍然存在该组播组的成员。
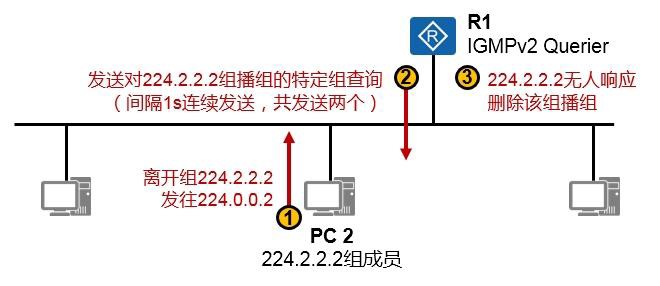
- 现在,PC2要离开组播组224.2.2.2,它主动向网络中发送IGMPv2离组报文。
- R1收到该报文后,以1s为间隔连续发送IGMP特定组查询报文(共计发送2个),以便确认该网段中是否还有224.2.2.2的其他成员。
-
现在组224.2.2.2已经没有成员了,因此没有主机响应这个查询。R1便认为该LAN中已经没有
224.2.2.2组播组的成员了,将不会再向这个LAN中转发该组的组播流量。
IGMPv2查询器¶
如果一个网段中有多台IGMP路由器,这些路由器都发送IGMP查询的话那就显得非常多余且低效。
IGMP会在这些路由器(的接口)中选举出一个IGMP查询器。IGMPv2定义了查询器的选举办法:IP地址最小的路由器充当该网段的IGMP查询器,由它来发送查询报文。在上图中,R1的GE0/0/0接口地址比R2的GE0/0/0接口地址更小,因此它(的接口)成为该网段的IGMP查询器。
若非查询器(例如本例中的R2的GE0/0/0接口)在“Other Querier Present Timer”计时器(默认125s) 超时后依然没有收到查询器发送的IGMP查询报文,那么它会认为查询器已经故障,新一轮的查询器选举将会被触发。
几个计时器¶
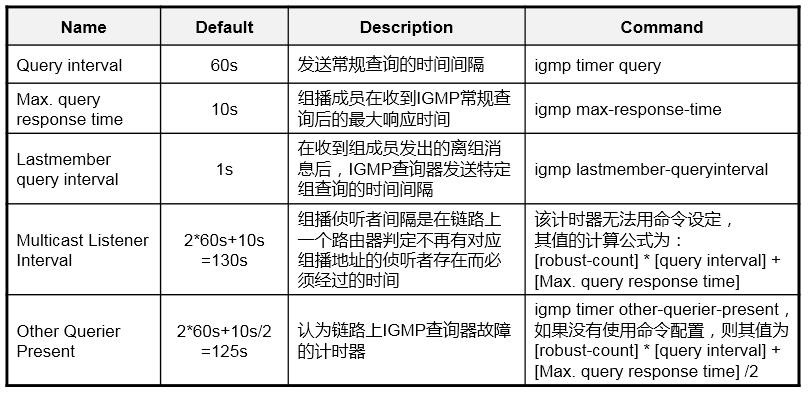
Robustness Variable¶
Robustness Variable(或者robust-count),健壮性变量,默认值为2。这个系数或者说变量会影响IGMP 的某些操作,例如作为计算某个计时器时使用的一个参数等。健壮系数越大,IGMP路由器就越健壮, 但是组超时的时间也就越长。
执行命令**robust-count robust-value**配置IGMP健壮系数。健壮系数主要用于:
- 当路由器启动时,发送“健壮系数”次的“普遍组查询报文”,发送间隔为“IGMP常规查询报文的发送间隔Query interval”的¼。
- 当路由器收到离开报文后,
- 对于IGMPv2,路由器发送“健壮系数”次的“特定组查询报文”,发送间隔为“IGMP特定组查询报文的发送间隔Lastmember-queryinterval”。
- 对于IGMPv3,路由器发送“健壮系数”次的“特定组/源查询报文”,发送间隔为“IGMP特定组/源查询报文的发送间隔”。
- 对于IGMPv2,路由器发送“健壮系数”次的“特定组查询报文”,发送间隔为“IGMP特定组查询报文的发送间隔Lastmember-queryinterval”。
IGMPv1与v2的区别¶
- IGMPv2定义了查询器的选举机制,IGMPv1没有,后者需依赖组播路由协议。
- IGMPv2在查询报文中增加“最大响应时间”字段,IGMPv1没有定义该字段。
- IGMPv2增加特定组查询报文,IGMPv1没有定义该报文。
- IGMPv2定义了离组机制,而IGMPv1中组播组成员是默默的离开。
IGMP 配置及实现¶
配置命令¶
激活路由器的组播路由功能¶
[Huawei] multicast routing-enable
在接口上激活IGMP并选择IGMP的版本¶
配置IGMP查询¶
IGMPv2配置示例¶
完成配置后,可在路由器上查看IGMP的相关参数:
也可以进一步查看详细信息:
现在PC1加入组播组224.1.1.1,然后我们在A上做查看:
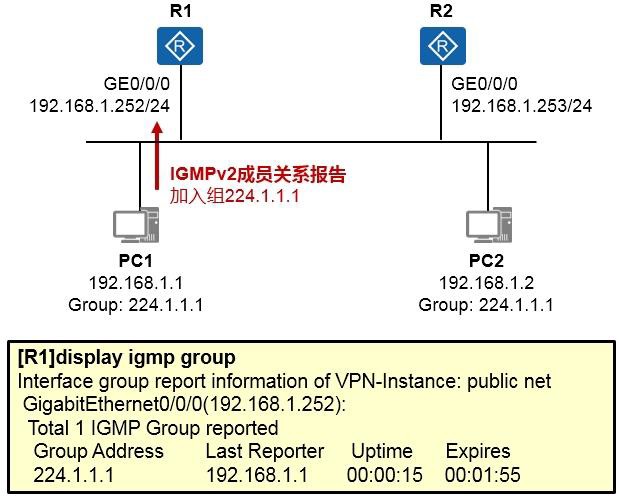
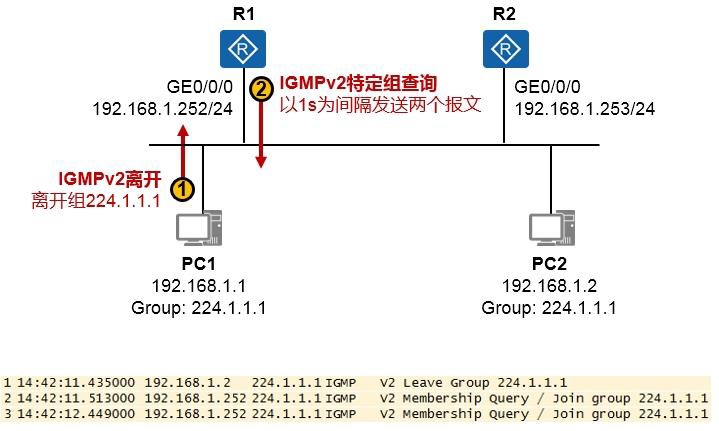 可使用**display igmp group verbose**再进一步查看详细信息。接着PC1离开组播组224.1.1.1:
可使用**display igmp group verbose**再进一步查看详细信息。接着PC1离开组播组224.1.1.1:
A会以1s为间隔连续发送两个特定组查询报文。在确定该组网中不再有224.1.1.1组播组的成员后,A将该组播组删除。
- 组播路由协议概述
- 关于组播路由协议
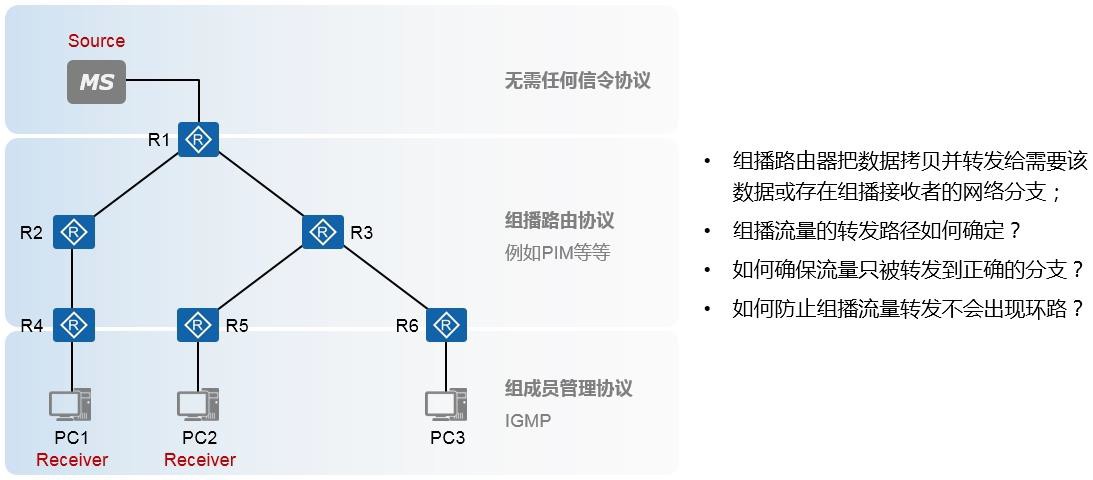
- 单播数据包的转发,是一个一对一的过程,路由器将IP数据包送到它的目的地,单播路由器并不关心数据包的源地址。而组播数据是由组播源产生、发向一组接收者的,组播路由器将数据包从源分发下去, 一直到组播的接收者。那么组播路由器如何知道,该将组播数据向哪里去转发,哪些接口需要组播流量?组播流量要走什么路径?这就要用到组播路由协议了。
- 另外一点值得注意的是,组播流量与单播流量不同,组播流量发往一组接收者,如果网络中有环路存在,那么情况比单播环路严重得多,因此所有的组播路由器必须知道组播的源,也必须把组播数据包从源(来的方向)向目标转发。为了保证数据从上游转发到下游,每一个组播路由器都维护一个组播前传表(组播路由表)。
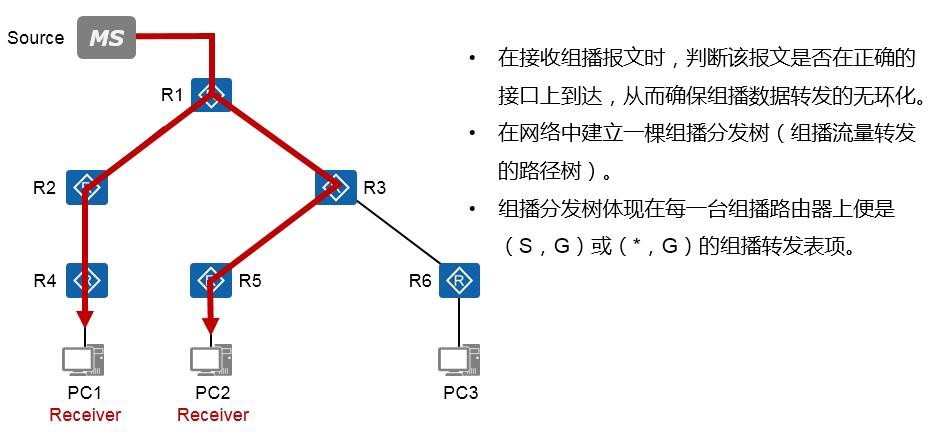
- 组播路由表项
在一个组播网络中,组播路由协议需要运行在网络设备(例如路由器、交换机等)上,组播路由协议在网络中工作后的最主要的成果之一便是构建一棵无环的组播分发树,这棵树描绘了组播流量在组播网络中的转发路径。而这个所谓的树当然是实际中并不存在的,只是人为抽象出来的。这个树在每一台组播网络设备上的体现,便是组播路由表项。组播路由表项类似单播路由中的路由表。
本手册只介绍PIM这一个组播路由协议,因此此处以PIM为例进行讲解。
PIM路由表项即通过PIM协议建立的组播路由表项。PIM网络中存在两种路由表项:(S,G)路由表项或(*,
G)路由表项。S表示组播源,G表示组播组,*表示任意。
-
(S,G)路由表项知道组播源S的位置,主要用于在PIM路由器上建立SPT。对于PIM-DM网络和PIM-
SM网络适用。
-
(*,G)路由表项由于只知道组播组G的存在,主要用于在PIM路由器上建立RPT。对于PIM-SM网络和双向PIM网络适用。
PIM路由器上可能同时存在两种路由表项。当收到源地址为S,组地址为G的组播报文,且通过RPF检查的情况下,按照如下的规则转发:
-
如果存在(S,G)路由表项,则由(S,G)路由表项指导报文转发。
- 如果不存在(S,G)路由表项,只存在(*,G)路由表项,则先依照(*,G)路由表项创建(S,G) 路由表项,再由(S,G)路由表项指导报文转发。
- 组播分发树
组播分发树(Multicast Distribution Trees),是用于IP组播数据包在网络中传输的路径。组播分树由组播路由协议构建及维护,有了这棵树,组播流量也就明确了转发路径。
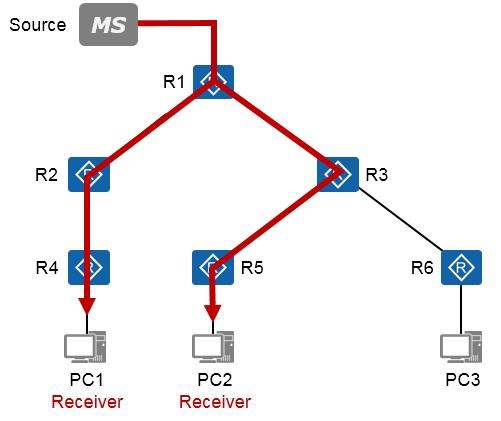
有两种组播分发树:源树(或者称为最短路径树)及共享树:
- 源树(Source Distribution tree):或叫最短路径树(Shortest-path trees,SPT),树根是组播源,源树的分支形成了通过网络到达组播接收者的分布树。因为源树以最短的路径贯穿网络,所以又叫最短路径树SPT。源树使用(S,G)的组播表项标记,此标记暗示每个组单独的源都有一个SPT。
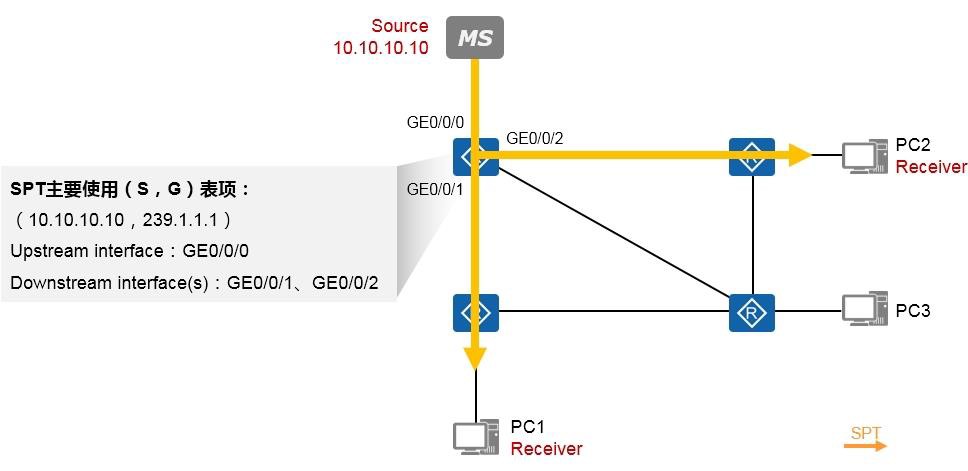
源树的根是组播源,可以很直观的看到源树的弊端:假设在一个组播域中有200个组播组,平均每个组
30个源,那么每个路由必须为一个组记录30个(S,G)对(交互式的组播应用中,许多组员,也即接受者同时也是一个源,也即发起者),那么就是30*200个。如此一来每台组播路由器需要维护的组播表项就非常多,所消耗的资源自然也就上去了。
-
共享树(Shared Tree):与源树使用组播源作为根不同,共享树使用RP作为汇聚点。共享树的通用名:
RPT。共享树使用(*,G)的组播路由表项标记。多个组播组可以共用一个RP,期望接收组播流量的路由器通过组播协议在自己与RP之间建立一条RPT的分支,组播流量首先需要从源发送到RP,然后再由RP将组播流量转发下来,组播流量顺着RPT最终到达各个接收者所在的终端网络。
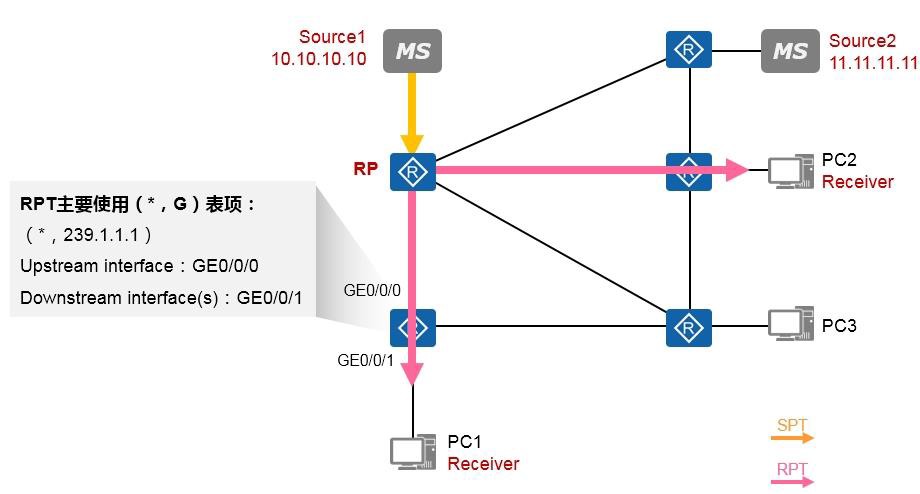
RPF¶
前面已经说了,在组播的环境下,如果数据出现环路影响是非常大的。路由器如何确保组播流量转发的无环呢?组播路由器收到组播数据报文后,只有确认这个数据报是从自己朝向组播源的接口上收到的,该报文才会被转发,否则被丢弃,这就是RPF(Reverse Path Forwarding)检查。
话又说回来了,路由器如何知道,该接口是否是“朝向”组播源的接口呢?最常见的做法是路由器通过单播路由表来协助做RPF,也就是看单播路由表中,到达源的单播路由,该路由的出接口即为朝向源的接口。
- 在单播路由表中查询到组播报文源地址的单播路由。
- 如果该路由的出接口就是组播报文的入接口,则报文通过RPF检查,组播报文将从下游接口转发出去。
- 否则,报文被丢弃。
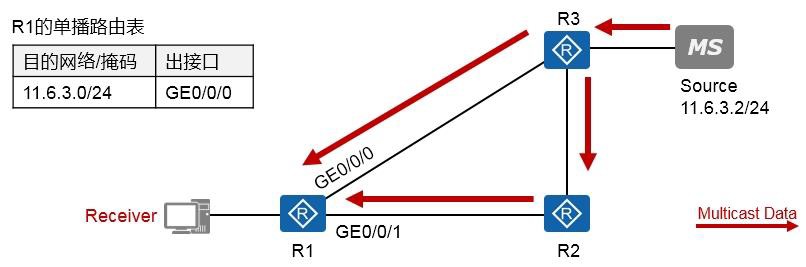
在上图中,假设在R1的单播路由表中,到达组播源11.6.3.2的单播路由的出接口为GE0/0/0,那么如果在
GE0/0/1上收到Source发来的组播数据包,则这些数据包无法通过RPF检查,数据包会被丢弃。注意,组播数据是绝对不会从RPF接口往回发的。
- PIM 概述
最常见、也是使用最为广泛的组播路由协议之一就是PIM((Protocol Independent Multicast,协议无关组播协议无关组播)。PIM独立于单播路由选择协议,它的工作依赖单播路由选择协议提供的信息(单播路由表),而又与具体的单播路由协议无关。PIM使用单播路由表去实现RPF检验功能。
PIM的报文使用IP头协议号:103,使用保留的组播地址:224.0.0.13。
PIM有两种工作模式:
PIM-DM密集模式¶
- 使用“推”(Push)模型(PIM-DM假设网络中每一个分支都有组播组成员,因此想不管三七二十一把组播流量扩散到每一个角落)。
- 下游不想接收组播数据的话则将自己所在的分支剪枝(Prune)掉。
- 完成剪枝后,组播路径树(源树)也就最终成型了,组播流量源源不断的顺着构建好的源树进行转发。
PIM-SM 稀疏模式¶
-
使用“拉”(Pull) 的模型,除非显式加入组播树,否则不给你发组播流量。
- 使用汇聚点RP,支持共享树和源树。
- 发送方向RP注册,把组播数据发给RP,RP将组播数据拷贝发送给注册的接收方。
-
直连着组播接收者的最后一跳的路由器知道去RP的最短路径,它朝着RP的方向发出Join报文,
Join报文逐跳到达RP的过程中,便创建了共享树的一个分支。
-
PIM-DM
- 协议概述
- PIM-DM(PIM-DenseMode)使用于网络规模较小、组播接收者较为密集的组网中。PIM-DM假设网络中的每一个分支都有组播接收者,因此在组播源开始发送组播流量时,PIM-DM将组播流量扩散网络的每一个角落,这种方式我们称之为“推”(Push)。
- 如果网络中的一个分支没有该组播组的成员,则PIM-DM将这个分支剪枝Prune掉(我这里不需要,把我剪掉吧,别给我发组播数据了)。
- 被剪枝的分支,其剪枝状态是有时间限制的,如果某个分支一直不需要组播组的流量,则需要周期性的发送剪枝报文,除非该分支下有了组播组的成员。
- 如果此前不需要组播流量的分支(已被剪枝的分支)现在有了组播成员,那么可以使用Graft嫁接机制来恢复组播流量的转发。
- PIM-DM使用源树,或称为最短路径树SPT。
- 协议报文
PIM协议的报文封装在IP报文中,IP报头的协议号为103。PIM协议的报头如下:

其中Type字段对应不同的PIM协议报文:

红色字体标识的报文为PIM-DM中使用的协议报文
- 邻居关系
上面的环境中,R1与R2都在各自的接口上激活了PIM,随后接口开始发送PIM Hello包去发现链路上的其他
PIM路由器。
| [R1] display pim neighbor VPN-Instance: public net Total Number of Neighbors = 1 | |||||
|---|---|---|---|---|---|
| Neighbor | Interface | Uptime | Expires | Dr-Priority | BFD-Session |
| 10.1.12.2 | GE0/0/0 | 00:02:47 | 00:01:27 | 1 | N |
Hello报文如下:
报文中的PIM Parameters都是TLV的格式,其中Holdtime就是PIM邻居的保活时间,默认105s。
Hello报文默认每隔30s发送一次,当PIM路由器收到邻居发来的Hello报,则邻居的保活计时器回到105s重新开始倒计时。
- 扩散(Flood)、剪枝(Prune)及嫁接(Graft)
初始化时的扩散¶
在上面的场景中,ABCDEF路由器都激活了组播路由功能,同时运行PIM-DM。现在组播源Source
10.10.10.10开始向组播组224.1.1.1发送组播数据,这些数据的目的地址都是224.1.1.1。数据包到达第一跳路由器A后,A将组播数据从所有接口(除了数据包进入的接口)扩散出去,BE也就收到了组播数据,他们同样将组播数据扩散。如此一来,组播数据就被扩散到了整个网络。
值得注意的是,组播路由也是有路由表项的,组播路由表项类似这样(下图与本节的示例无关):

一个组播路由表项首先有一个标识,形式可以是(S,G),或者是(*,G),(S,G)用于源树,而(*,
G)用于共享树。PIM-DM使用的是源树,所以当路由器收到组播数据时创建的是(S,G)表项,S标识组播源,G标识组播组,所以,在本节开始时展示的例子中,组播表项是(10.10.10.10,224.1.1.1)。
一个组播路由表项含有两个非常重要的内容,一是Upstream Interface或者Incoming Interface,这是
RPF接口,也就是“朝向”组播源的接口(或称为上行接口),PIM通过单播路由表来做RPF检查,在单播路由表中查找到组播源10.10.10.10的路由并找到出接口,该接口就是这里的上行接口。组播数据只有从正确的上行接口(RPF接口)收到才会进行处理,如果组播数据不是在RPF接口被收到,则被丢弃。这样可以确保组播流量转发的无环。
另一个重要的内容是Downstream Interface List(下行接口列表)或者Outgoing Interface List,这是一个接口列表,当PIM-DM组播路由器从上行接口收到一个组播数据包,初始情况下会从所有接口(当然除了上行接口)转发出去,因此此时下行接口列表里头罗列的就是那些接口。 当网络中的分支开始剪枝的时候,被剪枝掉的接口将从下行接口列表中去除。
剪枝¶
继续上面的场景,现在组播流量已经被扩散到全网。F有一个直连的网段连接着用户终端,它通过IGMP
了解到这个子网中存在组播组224.1.1.1的接收者,此刻F是一台“最后一跳路由器”,因为它直连着组播组224.1.1.1的成员,因此F是需要这些组播流量的。但是F从两个接口都收到了组播流量,我们假设
F的单播路由表中,到达10.10.10.0/24网络的路由下一跳是E,所以RPF接口就是连接E的那个接口,那从B收到的组播流量就不能通过RPF检查了,因此F向B发送一个PIM剪枝(Prune)报文,让B别再给自己发组播流量。
B路由器收到F发送过来的剪枝报文,它将自己收到该报文的接口从组播表项的下行接口列表中删除, 以后就不再向该接口发送组播流量了。
D路由器是一台叶路由器,没有任何组播组成员直连,因此它不需要这些组播流量,于是向上游发送PIM
Prune报文请求将自己从组播树上剪除,C会收到这个剪枝报文,它将收到该报文的接口从组播表项的下行接口列表中删除,随后发现此刻组播表项的下行接口列表为空,于是认为自己不需要组播流量,所以向上游路由器也就是B路由器发送了剪枝报文,而此刻B路由器同样发现自己的下行接口列表空了, 于是向上游路由器A发送剪枝报文。
最后,经过一系列剪枝活动之后的源树如下:
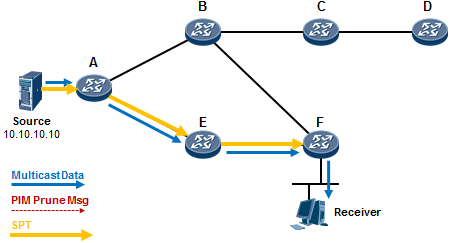
至此组播流量将沿着PIM-DM构建好的源树进行转发,不需要组播流量的节点是不会收到组播流量的。
嫁接¶
在上文场景的基础上,D路由器直连的网络中出现了一个新增的组播组用户,这个用户通过IGMP成员关系报告宣称自己要加入组播组224.1.1.1,D将会收到这个IGMP报文并且知道了该子网中有了组播组
224.1.1.1的成员,于是它将连接这个子网的接口添加到组播表项(10.10.10.10,224.1.1.1)的下行接口列表中,并向上游路由器C发送一个PIM Graft嫁接报文,试图将组播流量拉过来。C收到这个PIM Graft 报文,将收到这个报文的接口添加到组播表项(10.10.10.10,224.1.1.1)的下行接口列表中,然后以一个Graft-ACK报文回复给D,并向自己的上游路由器B发送Graft嫁接报文,B做的操作类似,就不再赘述了,嫁接报文会逐渐传递到A。
最终组播流量的传输路径如下:
- Assert 断言机制
上图所示的网络中,R1、R3都从其RPF接口收到Source发往224.1.1.1的组播数据,他们都会进行组播数据转发,这么一来R4将收到两份重复的组播数据,一方面造成链路带宽资源浪费,也加重了设备负担。
这时候就要选出转发路由器(在R1、R3与R4所接入的这个LAN中,究竟由谁来转发10.10.10.10发往组播组
224.1.1.1的流量),这是通过Assert报文实现的,这个机制也被称为“断言机制”,Assert报文内包括源和组的地址、到源的单播路由的度量值,以及发现这条路由的路由协议的优先级等关键信息。
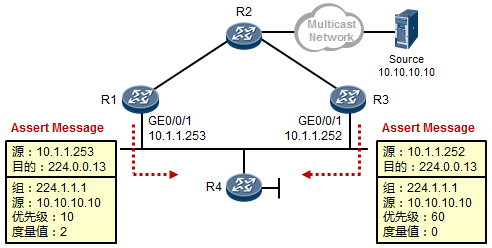
当R1或者R3从自己的GE0/0/1口,也就是(10.10.10.10 , 224.1.1.1)组播组的下行接口上收到(10.10.10.10 ,
224.1.1.1)组播组的数据,它们就意识到在这个接口上还有其他的组播路由器在转发相同的组播流量,这将触发R1及R3发送PIM Assert 报文, 报文的大致内容如上图所示。上图假设R1通过OSPF 学习到
-
/24路由,度量值Cost=2;R3通过静态路由获知10.10.10.0/24路由,Cost=0。在收到对方的Assert
报文后,双方开始PK:
- 首先PK双方到组播源的单播路由的优先级,优选值小的;
- 如果上面这项相等,则再PK到组播源的度量值,优选值小的;
-
如果上面这项还相等,则进一步比较本地接口IP地址,优选IP大的。
所以在上面的例子中,由于R1到达10.10.10.0/24路由的优先级为10,优于R3,因此R1的GE0/0/1口开始转发组播数据,而R3则不转发,此刻由于R3下行接口列表为空,因此R3通过其上行接口向R2发送一个Prune 剪枝报文,将自己从组播树上剪除。
9.5.6 配置示例
实验拓扑¶
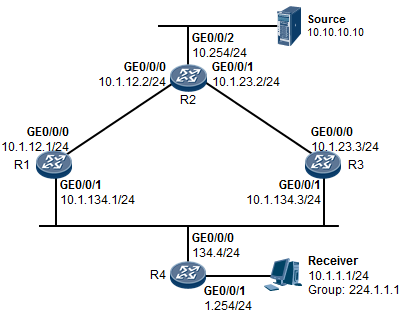
实验需求¶
- 网络拓扑、IP地址规划如上图所示;
- R1、R2、R3、R4运行OSPF协议,打通网络的单播路由;
- R1、R2、R3、R4同时也是组播路由器,运行PIM-DM;
- Receiver加入组播组224.1.1.1,在R4上观察IGMP信息;
- Source开始向组播组224.1.1.1发送组播数据,观察Assert现象、Prune现象。
配置实现¶
R1的配置如下:
R2的配置如下:
R3的配置如下:
R4的配置如下:
完成配置后,首先做个查看:
| Total Number of Neighbors = 2 | |||||
|---|---|---|---|---|---|
| Neighbor | Interface | Uptime | Expires | Dr-Priority | BFD-Session |
| 10.1.12.1 | GE0/0/0 | 00:02:08 | 00:01:37 | 1 | N |
| 10.1.23.3 | GE0/0/1 | 00:01:20 | 00:01:25 | 1 | N |
上面输出的是R2的PIM邻居,可以看到R2有两个PIM邻居,分别是R1及R3。
现在,各台路由器都已经就绪了,我们主要分析以下几个内容:
组成员加入组播组224.1.1.1¶
现在让Reciver加入组播组224.1.1.1,一般组播接收者就是我们的电脑或者其他便携设备,例如视频的业务,在电脑上安装一个视频客户端,打开客户端进行简单的操作就会触发电脑发送IGMP成员关系报告,宣称自己所要加入的组播组(可以华为自研的模拟器eNSP来模拟本实验)。
现在在最后一跳路由器R4上查看:
R4已经发现了组播组224.1.1.1内有一个组播成员10.1.1.1,但是由于现在R4还没有收到组播数据,所
以自然没有组播数据转发给接收者。
组播源开始发送组播数据观察扩散过程、Assert机制¶
现在组播源Source开始向组播组224.1.1.1发送组播数据,组播数据到达第一跳路由器R2,则R2创建组播路由表项(10.10.10.10,224.1.1.1):
在该表项中,上行接口朝向源,所以就是GE0/0/2口,而由于运行的是PIM-DM模式,因此R2将GE0/0/1
及GE0/0/0接口都添加到下行接口列表中,然后将组播数据从GE0/0/0口和GE0/0/1口都转发下去。
随后R1及R3都会收到R2转发下来的组播数据,他们也是创建一个组播路由表项,然后将所有接口(除
了RPF接口)都添加到下行接口列表中,并开始向下行接口发送数据数据。
在这个过程中,R1及R3都会向自己的GE0/0/1口转发组播流量,一旦双方在自己的GE0/0/1口上收到
(10.10.10.10,224.1.1.1)组播组的数据时,它们就知道在这个LAN中有两台组播路由器在转发数据, 这将触发Assert机制,R1及R3会发送Assert报文,在R1或R2的GE0/0/1口上抓包可以看到:

看一下R1发送的Assert报文:
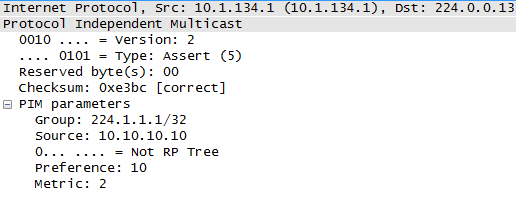
可以看到报文里包含组播组地址、源地址、优先级和度量值。R3发出的Assert报文类似,由于此时R1 及R3都是通过OSPF学习到10.10.10.0/24路由的,并且路由的度量值相等,都是2,因此接口IP地址大的路由器,也就是R3会从断言机制中胜出,它继续向10.1.134.0/24网络来转发组播组224.1.1.1的数据。
如此一来R1就不需要组播数据了,因此它会向上行接口发送一个Prune剪枝报文,将自己从组播树上剪除,R1的组播路由表就变成:
从上面的输出可以看到,R1的(10.10.10.10,224.1.1.1)组播表项没有下行接口。
R2的组播表项就变成:
(10.10.10.10,224.1.1.1)表项中,下行接口列表只有一个接口了,也就是GE0/0/1口。
R4在收到组播数据后,也是创建一个组播表项:
然后将组播数据从GE0/0/1口转发出去,如此一来接收者也就收到组播数据了。
因此,最终网络稳定下来之后,组播流量的传输路径是这样的:
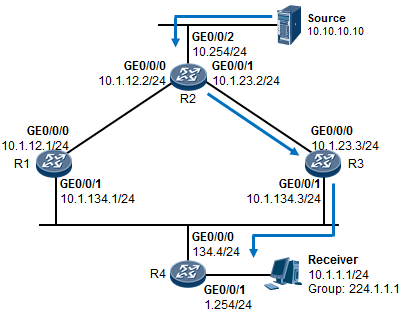
组播成员离组、观察Prune剪枝过程¶
现在,组播源仍然在不断的发送组播流量,我们让接收者Receiver离开组播组224.1.1.1。
由于Receiver一旦离开组播组,R4的GE0/0/1口上关于224.1.1.1的组播组就没有成员了,因此它将接
口GE0/0/1从自己的(10.10.10.10,224.1.1.1)组播表项的下行接口列表中去除,如此一来下行接口列表也就空了,R4知道自己不再需要224.1.1.1的组播数据,于是它从上行接口GE0/0/0发一个Prune剪枝报文,请求将自己从组播树上剪除。
R3收到这个剪枝报文后,将自己的GE0/0/1口从(10.10.10.10,224.1.1.1)组播表项的下行接口列表中去除,然后它发现接口列表空了,于是也发现自己不再需要组播数据了,因此向上行接口发送Prune报文,此刻R3的组播路由表如下:
R2收到R3发出的Prune报文后,其组播表如下:
下行接口列表为空,因此直接将源发送过来的组播数据丢弃,不从任何接口转发。
组播成员再次加组,观察Graft嫁接过程¶
经过前面的步骤,虽然组播源仍然在不断的向224.1.1.1发送组播数据,但是由于网络中不存在任何的组成员,因此组播流量被R2直接丢弃。
现在我们再次让Receiver加入组播组224.1.1.1。PC发送IGMP成员关系报文,R4在收到这个报告之后意 识 到 接 口 GE0/0/1 下 出 现 了 组 播 组 224.1.1.1 的 成 员 , 于 是 将 GE0/0/1 接 口 添 加 到
(10.10.10.10,224.1.1.1)表项的下行接口列表中,并向R3发送一个嫁接Graft报文:
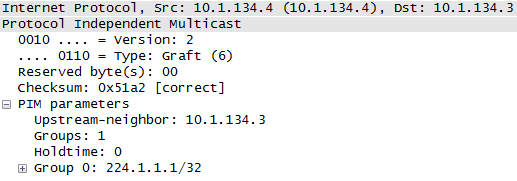
这个报文是一个单播包,R3收到之后将接口GE0/0/1添加到组播表项的下行接口列表,并向R4回送一个Graft-ACK报文以作确认。同时R3向自己的上行PIM邻居R2发送一个Graft报文。R2在收到这个报文的时候,也是将收到该报文的接口GE0/0/2添加到(10.10.10.10,224.1.1.1)表项的下行接口列表,随后开始向该接口转发224.1.1.1的组播流量。自此,组播树又重新构建完成。
- PIM-SM
- 基础知识
协议概述¶
- PIM-DM适用于网络规模较小、组播接收者较为密集的场景,而PIM-SM则适用于网络规模较大、组播接收者较为分散的场景。PIM-SM采用Pull(拉)的方式工作,初始情况下不会向网络分支的任何角落扩散组播流量,除非某个分支显式的申请。
- PIM-SM支持源树及共享树。
- 引入汇聚点RP的概念,RP作为共享树的树根。
- 共享树到源树的切换机制使得组播流量的转发更加科学和高效。
汇聚点RP(Rendezvous Point)¶
汇聚点RP,是共享树RPT的树根,负责将来自于源(Source)的组播流量转发到接收者。在PIM稀疏模式中,源发向组播组的流量先是送到RP,再由RP将组播流量沿着RPT往下游转发。网络中的分支如果需要组播流量,则由组播路由器朝着RP的方向发送PIM Join报文,将自己拉到RPT上。
一个RP,可以负责一个或多个组播组的组播流量转发,一个组播组同一时间只能有一个RP(可以使用动态发现机制进行主备切换)。
RP的发现机制:
- 静态手工指定(需在所有组播路由器上配置)。
- 动态发现:BSR。
PIM-SM RPF检查¶
PIM-SM支持RPT(共享树)及SPT(源树),RPF 的检查:
- 对于源树,使用组播源的地址进行RPF检查。
- 对于共享树,使用RP的地址进行RPF检查。
- 工作机制 1:共享树加入
PIM-SM与PIM-DM的工作方式不同,PIM-SM需要显式的PIM Join报文构建共享树的分支。
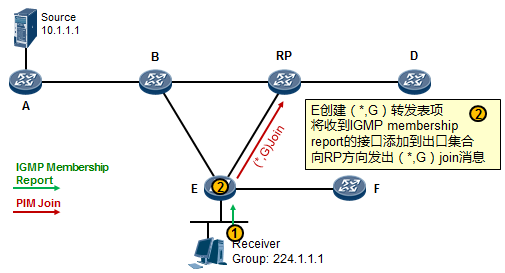
- 上图所示的网络拓扑中,所有的组播路由器均运行PIM-SM。初始化情况下,组播流量不会被转发给网络的任何分支。现在E直连的网络中出现了组播组224.1.1.1的接收者,主机通过发送IGMP成员关系报告宣称自己要加入组播组224.1.1.1。
-
最后一跳路由器E收到这个IGMP报文,它在自己的组播路由表中创建(*,224.1.1.1)表项、将收到IGMP 报文的接口添加到该组播表项的下行接口列表中,并朝着RP的方向发送(*,224.1.1.1)的 PIM Join 报文。注意E路由器知道RP的地址(可能是图中所示的RP路由器的Loopback接口IP地址),并且也能够通过单播路由协议(如OSPF)学习到该地址的路由,因此它借助单播路由协议来判断谁是比自己离
RP更近的上游PIM邻居。
-
RP收到了E路由器发送过来的PIM Join报文,它创建(*,224.1.1.1)组播路由表项,将收到该报文的接口添加到表项的下行接口列表中,由于它本身就是RP,因此如果此刻它已经从源接收到发往
224.1.1.1组播组的流量,则开始向下行接口转发组播流量:
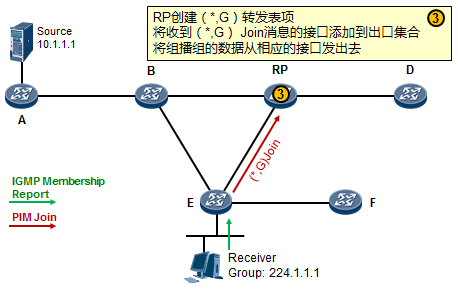
- 现在路由器F直连的网段也出现了组播组224.1.1.1的成员,该成员发送IGMP成员关系报告宣称自己加入组播组。
- F路由器创建组播路由表项(*,224.1.1.1)、将收到该IGMP报文的接口加入表项的下行接口列表中, 然后向上行接口发送(*,224.1.1.1)的PIM Join报文,请求加入共享树:
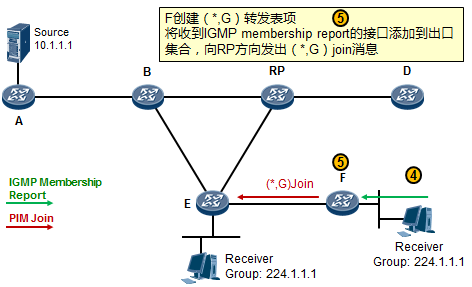
-
E将收到F发送过来的Join报文的接口加入(*,224.1.1.1)组播转发表项的下行接口列表中,由于此刻
E已经是共享树的一个分支了,因此它只是简单的将接口添加到下行接口列表,并向这个接口转发组播流量:
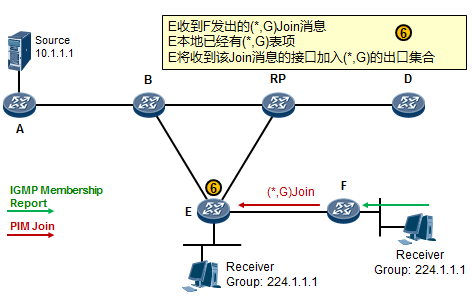
- 最终构建起来的RPT如下图所示:
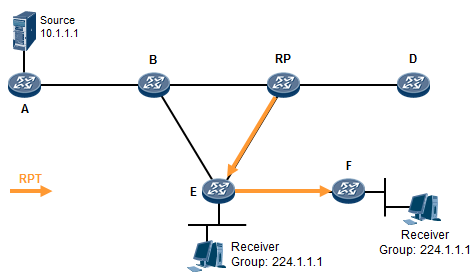
- 工作机制 2:共享树剪枝
继续上文的场景,现在F路由器直连的网段原有的组224.1.1.1的成员都离组了,它们发送IGMP leave报文宣称自己离组:
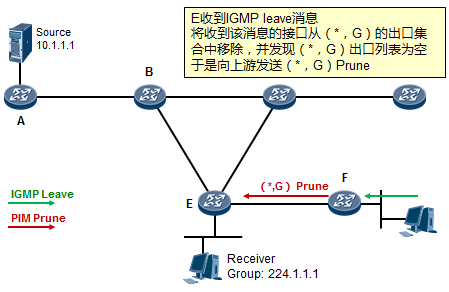
F收到这些IGMP报文,知道该子网中没有组播成员了,因此将接口从组播转发表项(*,224.1.1.1)的下行接口列表中移除,一移除它就发现下行接口列表为空了,它知道自己不再需要组224.1.1.1的流量,因此向上游接口发送一PIM Prune报文,请求将自己从(*,224.1.1.1)的共享树上剪除。
E路由器会收到这个PIM Prune报文,它将收到该报文的接口从(*,224.1.1.1)转发表项的下行接口列表中移除,由于移除之后,下行接口列表中仍然还有一个接口,因此E仍然保持自己在RPT上。这样组播流量仍然是从RP转发下来给E,而E只将组播流量转发给本地直连的、存在组播成员的网段,而不会转发给F。
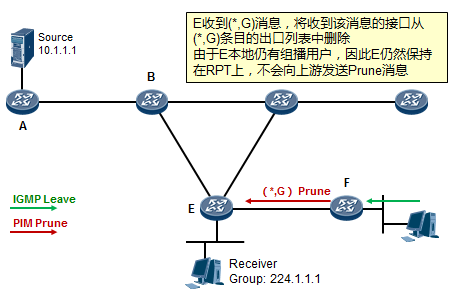
当E路由器上直连的组播组用户也离组时,E路由器就会发现下行接口列表为空,因此也朝着上行接口发送
Prune报文,将自己从共享树上剪除。
- 工作机制 3:源注册
上文讨论的是RP与接收者之间的问题,现在来讨论组播源和RP之间的问题。只有把这两个问题串起来,组播数据才能最终打通,从源流向接收者。
- 初始情况下,网络中是没有组播流量在流动的,当源开始向组播组224.1.1.1发送组播数据时,这些数据首先是被第一跳路由器A接收。
- A收到之后要将组播数据发向RP。A知道RP的地址,也通过单播路由协议发现了到达RP的路由。它将组播数据封装在PIM Register报文中,PIM Register报文是单播包,目的地址是RP的地址。A将数据包发给B,由B转发给RP。
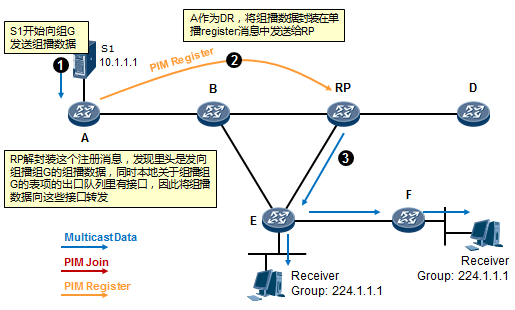
- 封装着组播数据的PIM Register报文被路由到了RP上,RP将数据解封装,得到组播数据,它将组播数据沿着已经建立好的RPT转发下去。
- A不断的将源发送出来的组播数据封装在单播的Register报文中发往RP,这显然是低效的,因为组播流量往往比较多,持续的封装和解封装无疑是增加A和RP的负担,这是没有意义的。于是RP朝着源的方向发送(10.1.1.1,224.1.1.1)的(S,G)PIM Join报文,试图在自己和源之间构建一棵最短路径树,也就是源树,从而能够从源直接收到组播数据包,而不是被封装的单播包:
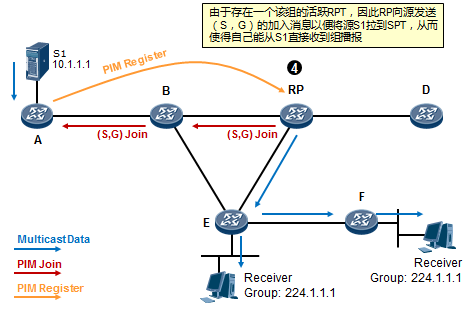
- 这个(S,G)的PIM Join报文朝着源一跳一跳的传输过去,这就在RP和第一跳路由器A之间建立起了一棵源树,组播流量就可以顺着这棵源树流向RP,再从RP上沿着构建好的共享树流向所有分支:

- 上一步完成之后,由于已经构建好了从A到RP的源树,因此A将组播流量直接发往B(再由B顺着SPT发往RP),另一方面,A仍然在单播的Register报文中封装组播数据然后发往RP,这将导致RP收到两份相同的组播数据,显然是没有意义的。实际上由于源树已经建立好了,RP没有必要再从A收到Register 报文了,因此它向A发送一个PIM的Register-STOP报文:
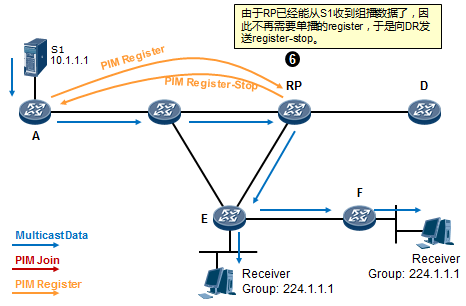
-
PIM Register报文被A收到之后,A就不再使用Register报文向RP发送组播数据了,组播数据也就只是顺着源树流向RP。
到此网络中存在的源树和共享树如下:
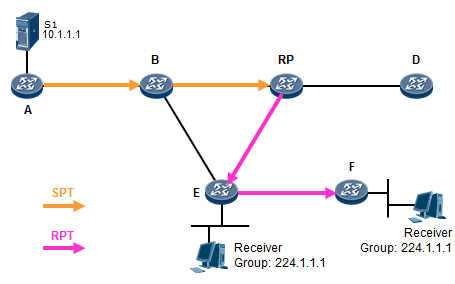
组播数据从第一跳路由器A顺着源树流到RP,再由RP顺着共享树下行到所有需要组播流量的分支。仔细一琢磨,我们会发现其实这里也存在不合理的现象,其实组播流量完全可以从B直接流到E的,没有必要再经由RP转到E。请继续往下看。
- 工作机制 4:RPT 到 SPT 的切换
上文提到的问题,PIM-SM有解决办法,那就是RPT到SPT的切换机制。PIM-SM中,默认情况下最后一跳路由器一旦从RPT收到一个组播数据包,则马上尝试在自己与组播源之间建立一棵源树SPT,这样可以让自己从最优的路径获得来自第一跳路由器的组播数据,而不用从RP拐过来。
F最为最后一跳路由器,当它从RP收到一个224.1.1.1的组播数据包的时候,它立即向源的方向发送一个
(10.1.1.1,224.1.1.1)的PIM Join报文,试图在自己与源之间建立一棵源树。它通过单播路由表来判断哪个接口是朝向源的RPF接口(源树使用组播源做RPF检查)。B路由器是E去往10.1.1.1的下一跳,因此E将Join 报文发向B:
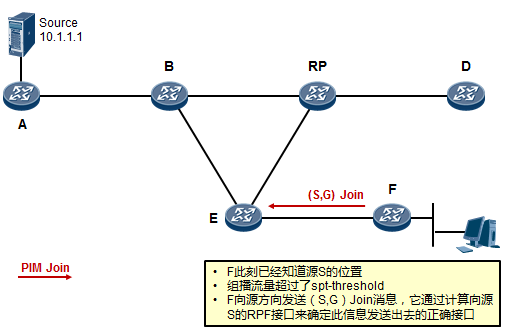
B路由器收到这个Join报文后,将收到该报文的接口添加到(10.1.1.1,224.1.1.1)的组播表项下行接口列表:
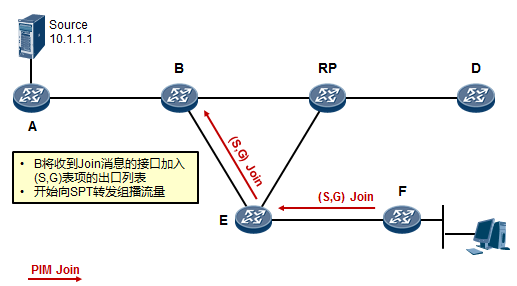
到目前为止,网路中的组播路径树如下:
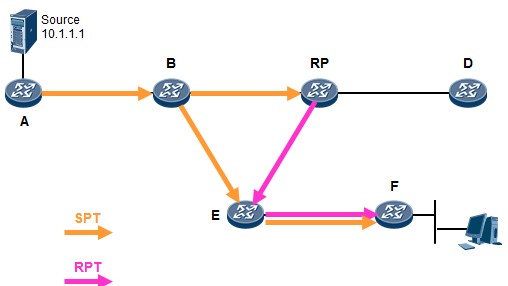
我们发现F将收到同一个组播数据的两份拷贝,这显然是无意义的。既然已经能够从SPT拿到组播数据,就没有必要再从RPT拿组播数据了,因此F朝着RP的方向发送一个(*,224.1.1.1)的Prune报文,请求将自己从RPT上剪除,E作为SPT和RPT的分叉口并且已经能够从SPT直接获取到来自Source的组播数据,E向
RP发送(S,G)RP位剪枝报文,将自己从共享树上剪枝:
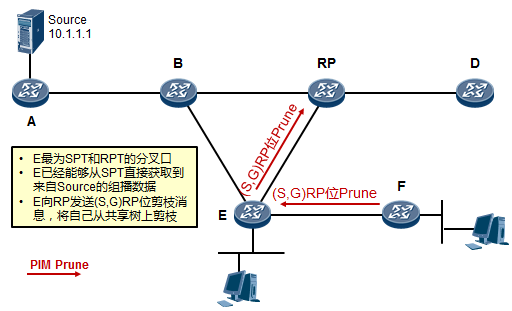
RP收到这个剪枝报文后,将接口从(S,G)表项的下行接口列表中去除,然后朝着源的方向发送Prune报文,
B收到这个报文后,将接收该报文的接口从(S,G)表项中移除。
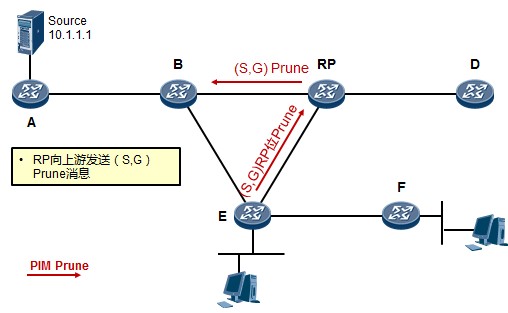
最终,组播路径树如下:
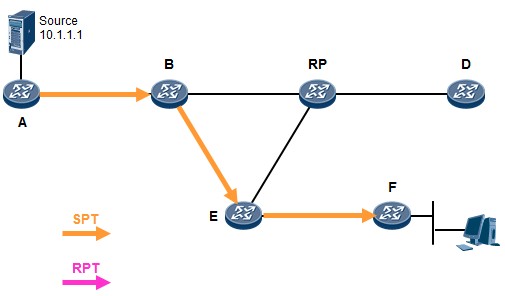
- PIM-SM DR 指定路由器

PIM在每一个多路访问网络,都会选举一个DR(DesignatedRouter,指定路由器),DR的身份是可以抢占的,利用Hello进行选举。
在PIM-DM中,只有当IGMPv1被用在多路访问网络的时候DR才会有意义,这是因为IGMPv1没有定义IGMP 查询器选择机制,在这种情况下,被选择的DR也有IGMP查询功能。PIM-SM中,指定路由器的作用更大:
靠近源的DR(如上图中的R2)负责向RP发送PIM Register报文及组播数据¶
上图中,R1与R2都和组播路由在同一个LAN中,他们都会收到组播源发出来的组播数据,如果两者都向RP发送Register报文或者组播流量,这显然是多余的,因此R1及R2连接到该LAN的接口就会通过PIM
Hello包进行PK,先比较DR-Priority(默认为1),如果相等则再比较接口IP,选择IP较大的。假设R2的
接口成为DR,那么就由R2来向RP注册,以及发送后续的组播报文。
靠近接收者的DR(如上图的R4)负责向RP发送Join报文从而形成共享树,也就是负责将接受者拉到共享树(同时负责将来自源的组播数据转发给接收者)。¶
并非所有的PIM路由器都支持DR优先级选项,不支持的路由器在发送PIM HELLO的时候不携带这个选项, 当PIMv2路由器收到一个不包含DR优先级选项的hello时(或此报文中的优先级=0),那么接收方就知道, 发送者不支持这个优先级选项,因此这个子网中的DR选举将使用IP地址大小进行PK。
使用如下命令在接口上修改DR优先级:
[Router-GigabitEthernet0/0/0] pim hello-option dr-priority ?
- 配置示例
实验拓扑¶
实验需求¶
- 网络拓扑、IP地址规划如上图所示;
- R1、R2、R3、R4运行OSPF协议,打通网络的单播路由;
- R1、R2、R3、R4同时也是组播路由器,运行PIM-SM;
- R3为RP,配置Loopback0,IP地址为3.3.3.3,该地址作为RP的地址;
- R1、R2、R3、R4同时也是组播路由器,运行PIM-SM;
- R1、R2、R3、R4运行OSPF协议,打通网络的单播路由;
- Receiver加入组播组224.1.1.1;观察RPT的构建;
-
在R4上将RPT-SPT的切换设置为永远不切换,同时从源开始发送组播数据,观察源的注册过程、
RP到源的SPT建立过程、组播流量沿着RPT下行的过程。
-
在R4上将RPT-SPT的切换恢复为默认值,同时将R4的GE0/0/1口的OSPF Cost值稍稍调大,观察
RPT到SPT的切换过程。
- 本实验可使用华为自研模拟器eNSP完成。
-
-
配置实现¶
R1的基础配置如下:
R2的基础配置如下:
R3的基础配置如下:
R4的基础配置如下:
完成配置后,先做一下初步的验证:
| \<R4>display pim neighbor VPN-Instance: public net Total Number of Neighbors = 2 | |||||
|---|---|---|---|---|---|
| Neighbor | Interface | Uptime | Expires | Dr-Priority | BFD-Session |
| 10.1.14.1 | GE0/0/0 | 00:53:40 | 00:01:24 | 1 | N |
| 10.1.34.3 | GE0/0/1 | 00:53:39 | 00:01:37 | 1 | N |
上述输出的是R4的PIM邻居表,可以看到R4发现了两个PIM邻居。在其他路由器上也做相应的查看,确保
PIM邻居都发现完整了。
上面的输出查看的是R4的PIM RP信息,我们为R4手工告知了RP的地址,3.3.3.3,其实也就是R3。
组播用户加入组224.1.1.1,查看RPT的建立过程:¶
现在PC加入组224.1.1.1,这将触发PC发送IGMP成员关系报告,R4最为最后一跳路由器会从GE0/0/2 口上收到这个报告,它便知道该接口下出现了组播组224.1.1.1的成员,它将建立(* , 224.1.1.1)的组播路由表项。
随后R4会向RPF上行接口发送(*,G)PIM Join报文,请求加入共享树RPT。R4如何判断哪个接口是RPF 上行接口呢?R4通过单播路由表来判断,对于RPT,PIM路由器在做RPF检查的时候是朝向RP的,因此R4在单播路由表中查找到达RP3.3.3.3的路由,选择路由的出接口作为RPF接口,但是这里由于全网接口COST都是默认值,因此R4上关于3.3.3.3的OSPF路由在R1及R3上出现等价负载均衡,这时R4会选择R1及R3中接口IP较大的作为RPF的主邻居,也就是R3,因此R4的GE0/0/1成为RPF接口。这与上面的输出吻合。
R3在收到R4发上来的PIM Join报文后,它会创建一个(*,224.1.1.1)表项,将收到该报文的接口GE0/0/1
添加到下行接口列表中,由于自己就是RP了,因此共享树的一个分支就此建立完成。
源注册、RP到源的SPT建立过程、组播报文的传输过程:¶
接下去我们来观察一下源注册、RP到源的SPT建立过程及组播报文的传输过程。首先在R4上将RPT-
SPT的切换设置为永远不切换,因为这个特性我们在下一步中再去关注,这里暂时忽略掉。
使用上述配置将R4的PIM SPT切换特性设置为永远不切换。
现在组播源开始向组播组224.1.1.1发送组播数据(这可以通过ping 224.1.1.1来模拟)。组播数据到达第一跳路由器R2后,R2会将组播数据封装在单播的PIM Register报文中发往RP也就是R3。
通过在R2的GE0/0/1口上抓包,可以看到Register报文,这是一个单播包,目的地址是3.3.3.3。R3在收到这个包后,解封装发现里头是个(10.10.10.10,224.1.1.1)的组播数据包,因此在本地创建一个
(10.10.10.10,224.1.1.1)表项,同时将组播数据包沿着RPT先传下去(从GE0/0/1口发出去)。另一方面,R3紧接着向源的方向(同样是借助单播路由表查找到10.10.10.10的路由来获得RPF接口)发送
(10.10.10.10,224.1.1.1)的PIM Join报文,试图在自己与源之间建立一条源树SPT。
\<R3>display pim routing-table
R2收到这个Join报文后,将GE0/0/1口添加到(10.10.10.10,224.1.1.1)组播表项的下行接口列表中,
然后将组播流量沿着建立好的SPT转发到RP,而不再将组播流量封装到Register报文中。
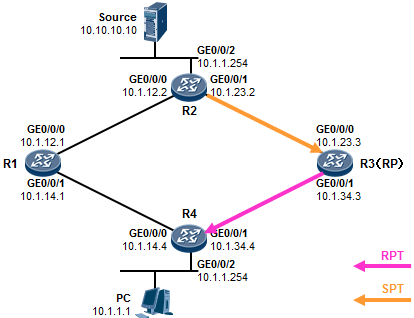
SPT的切换过程:¶
现在,将R4上之前配置的SPT切换的相关配置去除(undo spt-switch-threshold),恢复成默认。在默认情况下,R4作为最后一跳路由器,只要一收到224.1.1.1的组播数据包,则立即进行SPT的切换。接着将R4的GE0/0/1口OSPF Cost稍稍调大,调节为2(默认是1),我们通过这个动作,来模拟这样一个事实:“R4从R1到达源,比从R3到达源要更近”。
现在,当R4从GE0/0/1口收到第一个224.1.1.1的组播数据包时,将启动SPT切换机制,朝着源的方向
(更优的下一跳是R1)发送(10.10.10.10,224.1.1.1)的PIM Join报文,请求加入SPT。
R1收到这个Join报文后,创建(10.10.10.10,224.1.1.1)表项,将GE0/0/1口添加到下行接口列表,同时向R2发送Join报文。R2收到这个Join报文后,将自己的GE0/0/0口添加到(10.10.10.10,224.1.1.1) 表项的下行接口列表,并开始向GE0/0/0口下传组播数据。
这一步完成之后,网络中的组播路径树如下所示:
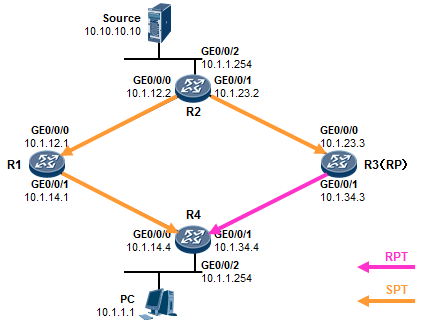
现在R4会从R1及R3收到组播数据的两份拷贝,这显然是没有意义的,因此它向R3发送一个Prune报文, 将自己从RPT上剪除。R3收到这个报文后,将接口GE0/0/1从(*,224.1.1.1)表项的下行接口列表中删除,也就不再向GE0/0/1口发送组播流量了,然后发现下行接口列表为空,因此向R2发送一个Prune 报文,请求将自己从SPT上修剪掉,因为它不再需要组播流量了。R2收到这个Prune报文后,将GE0/0/1 口从表项的下行接口列表中删除。
最终R2的组播表项如下:
组播路径树如下:
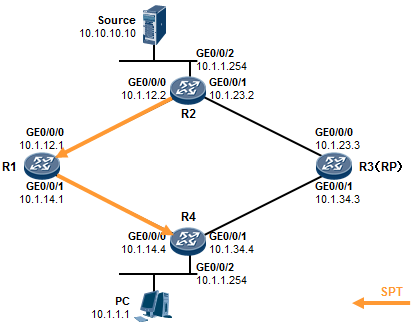
IPv6 基础¶
- IPv6 基础
概述¶
IPv4存在的问题¶
- IPv4公网地址耗尽。这应该是当前IPv6替代IPv4的最大原动力。随着最后一块IPv4公网地址分配光,加上接入公网的用户及设备越来越多,IPv4地址枯竭的问题日益加剧。
- Internet用户快速增长,随着科技行业的发展,有更多的用户、更多种类的设备接入公网。
- IPv4缺乏真正的端到端通信模型。为了缓解地址紧缺的问题,私有IPv4地址空间被大量的部署,应该说私有地址空间的定义极大程度上缓解了IPv4地址枯竭的问题,任何人在任何本地私有的网络中都能够随意使用IPv4私有地址,只是这些地址无法上公网,如果需要访问公网,或者被公网访问, 那就需要用到NAT。NAT确实能解决私有地址空间与公网互访的问题,但是却破坏了端到端通信的完整性。
- IPv4无法适应新技术的发展,如物联网等。所有行业都是IPv6的潜在用户。
- 广播机制的存在,对ARP的依赖等,使得IPv4局域网的相关运作问题频发。
- IPv4对移动性的支持不够理想。
IPv6的特点及优势¶
- IPv6地址采用128bit长度,地址空间非常庞大,为未来数十年提供了巨大的地址空间。
- 多等级层次有助于路由聚合,极大程度上优化了骨干网路由。公网地址分配更加合理有序。
- 独特的无状态自动配置功能使得IPv6终端能够即插即用,省去了地址配置的麻烦。
- 前缀重编址机制使得IPv6提供商之间的转换对最终用户透明、更平滑。
- 仅存在特定需求的场景中部署NAT,确保端到端通信的完整性。
- IPv6中取消了广播这一在IPv4中带来诸多问题的传输机制。在IPv4中所有需要借助广播来工作的协议,在IPv6中均采用组播替代。
- IPv6中取消了ARP,使用ND报文实现地址解析,地址解析请求通过组播的方式发送。
- IPv6的包头比IPv4更简洁、字段更少。定长IPv6基本报头提高了网络设备的处理效率。
- 新定义的扩展包头替代了IPv4的选项字段,并且提供了更多的灵活性、扩展性。
- 更有效地支持移动性和安全性。
- IPv4到IPv6网络的过渡技术丰富多彩。
报文格式¶
IPv6基本包头¶

以上是IPv4与IPv6包头结构的对比(可以从图中看到对于IPv4而言,IPv6的头部发生的变化,以及被保留、取消和新增的字段)。IPv4的包头最小为20byte,最大则为60byte,由于包含了可选项及填充字段, 因此包头长度不固定。IPv6的基本包头相比于IPv4虽然长度加长了,变成了40byte,但是包头长度是固定的,而且变得更加简洁,它将原来IPv4中的可选项、填充字段以及部分其他字段的功能通过“扩展包头”来实现。
在IPv6基本包头中,“Traffic Class”字段类似IPv4中的ToS。“Hop Limit”字段相当于TTL,另外“Next
Header”字段用来指示IPv6基本包头后面的报文类型,相当于IPv4中的Protocol字段。新增的“Flow
Label”字段用来标记同属一个流的报文。转发路径上的网络设备可以根据这个值来区分流并进行处理, 由于Flow Label在V6的包头中携带,因此相比IPv4那样还要通过源目的IP、源目的端口号和协议类型
(五元组信息)来确定一个流,效率就要高得多。
一个IPv6数据包拥有一个IPv6基本包头,以及0个或多个扩展包头,在扩展包头之后,便是数据载荷。
IPv6扩展包头¶
在IPv6中,原来IPv4包头中的选项字段等的相关功能通过IPv6扩展包头实现。一个IPv6数据包可能包括
0个或多个扩展包头,当使用多个扩展包头时,通过前面的包头的Next Head字段指明该包头后的扩展包头类型。有了扩展包头,中间路由器就不需要处理每一个可能出现的选项,提高了路由器处理数据包的效率,提高了其转发性能。在扩展报头链的最后就是有效负载。
扩展报头是可选的,只有需要该扩展报头对应的功能时,数据的发送者才会添加相应扩展报头。
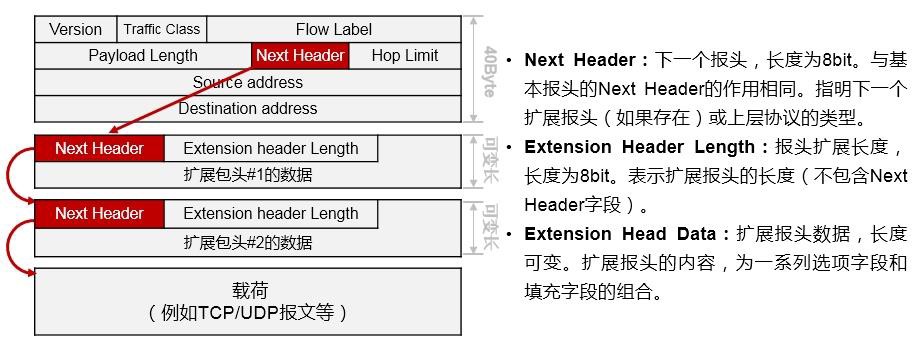
RFC 2460中定义了6个IPv6扩展头。当超过一种扩展报头被用在同一个IPv6报文里时,报头必须按照下列顺序出现:
- IPv6基本报头
- 逐跳选项扩展报头
- 目的选项扩展报头
- 路由扩展报头
- 分段扩展报头
- 认证扩展报头
- 封装安全有效载荷扩展报头
- 目的选项扩展报头
- 上层协议数据报文
- IPv6 编址
IPv6 地址¶
IPv6地址一共128bit,因此地址空间是相当庞大的,可提供给PC、无线IP电话、机顶盒、视频设备、安保监控设备等等。IPv6地址不再像V4那样使用“点分十进制”的格式来表现,而是使用“冒号分隔十六进制” 格式表示例如2001:0da8:0207:0000:0000:0000:0000:8207。乍一看这地址确实很长,书写起来有诸多不便,但是不用担心,IPv6定义了地址简写方式:
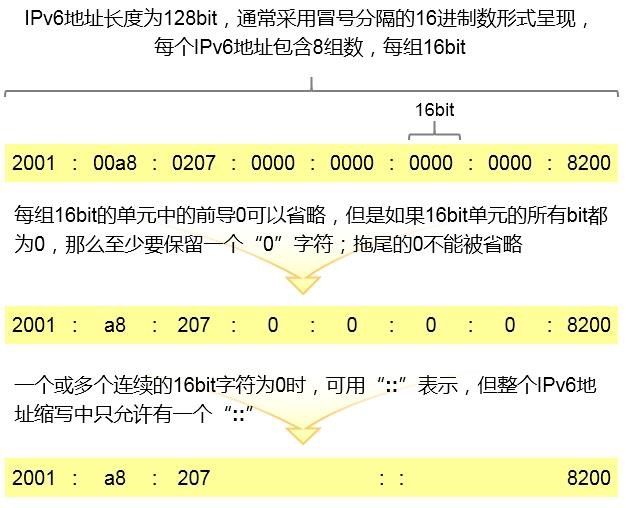
以下是几个简写的例子:
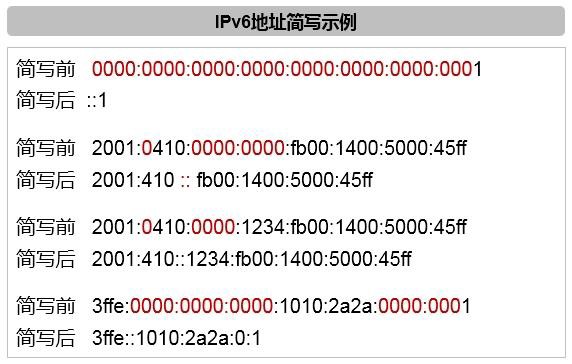
地址类型¶
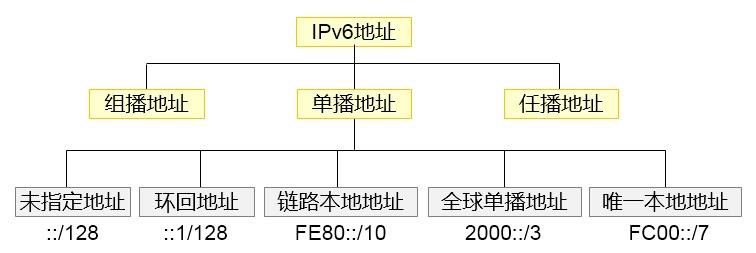
- 单播地址(Unicast Address):标识一个接口,目的地址为单播地址的报文会被送到被标识的接口。在IPv6中,一个接口拥有多个IPv6地址是非常常见的现象。
- 组播地址(Multicast Address):标识多个接口,目的地址为组播地址的报文会被送到被标识的所有接口。只有加入相应组播组的设备接口才会侦听发往该组播地址的报文。
- 任播地址(Anycast Address):任播地址标识一组网络接口(通常属于不同的节点)。目标地址是任播地址的数据包将发送给其中路由意义上最近的一个网络接口。
- IPv6没有使用广播地址(Broadcast Address)。
- 可以通过IANA网站了解目前的IPv6地址空间分配情况:Internet Protocol Version 6 Address Space
单播地址¶
可聚合全局单播地址(Aggregatable Global Unicast Address)¶
- 可聚合全局单播地址也被称为全局单播地址,该类地址全球唯一,相当于IPv4的公网地址。
- 目前IANA为这类地址分配了前缀2000::/3。常见的情况是,从运营商申请到的IPv6地址空间为/48, 再由自己根据需要进一步规划。
 如下图,分配给终端的IPv6地址可能是这样的结构:
如下图,分配给终端的IPv6地址可能是这样的结构:- 全局路由前缀:由提供商指定给一个组织机构,一般至少为48bit(加上前面固定的3bit)。目前已经分配的全局路由前缀的前3bit均为001。因此前缀为2000::/3。
- 子网ID:组织机构可以用子网ID来构建本地网络。
- 接口ID:用来标识一个设备(的接口)。与IPv4中的主机地址的概念类似。
站点本地地址(Site-Local Address)¶
类似IPv4中的私有地址。该地址以FEC0::/10为前缀。也就是说最高10bit固定为1111111011,紧跟在后面的是连续38bit的0。因此,对于站点本地地址来说,前48bit总是固定的。
在地址最后的接口ID和高位48bit特定前缀之间有16bit子网ID,供机构在内部构建子网。站点本地地址只能够在本地或者私有环境中使用,不能访问公网。
RFC1884定义了FEC0::/10地址块用于站点本地地址,这些地址只能够在私有的IPv6“站点”内使用,但是由于历史原因,站点本地地址的使用一度出现混乱,最终导致该类地址不再被使用。
唯一本地地址(Unique Local Address)¶
唯一本地地址,概念上相当于私有地址,仅能够在本地网络使用,在IPv6 Internet上不可被路由。上面提到的站点本地地址由于起初的标准定义模糊而被弃用,而后RFC又重新定义了唯一本地地址以满足本地环境中私有IPv6地址的使用。
在RFC4193中标准化了这种用来在本地通信中取代站点本地单播地址的类型。唯一本地地址拥有固定前缀FC00::/7,它被分为两块,其中FC00::/8暂未定义,另一块是FD00::/8,其格式如下:

唯一本地地址虽然只在有限范围内有效,但也具有全球唯一的前缀(严格来说,应该是几乎可能是全球唯一)。这是因为,地址前缀中的Global ID是通过伪随机的方式产生的,RFC4193给出了一些关于产生方式的建议,例如“Obtain the current time of day in 64-bit NTP format [NTP]”等 。
链路本地地址(Link-local Address)¶
链路本地地址是一类非常重要的地址,它的有效范围仅仅在所处链路上。它以FE80::/10为前缀,其中左边数起第11-64bit为0,外加一个64bit的接口ID。格式如下:

IPv6主机的网卡,或者网络设备的接口可以拥有多个可聚合全局单播地址,但是这些接口要能够正常工作的话,就必须有一个链路范围内唯一的链路本地地址,该地址由于其稳定性、链路唯一性,被用于
IGP邻居关系构建、自动地址配置、邻居发现、路由器发现等机制中。
源或目的IPv6地址为链路本地地址的数据包将不会被转发出始发的链路之外,换句话说,链路本地地址的有效范围仅仅是其所属的本地链路。
每一个IPv6接口都必须具备一个链路本地地址。华为设备支持自动生成及手工指定两种配置方式。在华为路由器上,当接口获得一个IPv6全球单播地址后,设备会自动为该接口配置链路本地地址。
如果设备接口上并未配置全局单播IPv6地址,则需使用**ipv6 address auto link-local**命令手工使设备自动产生一个链路本地地址,在防火墙、路由器、交换机等设备上,该自动生成的链路本地地址采用EUI-64规范的接口ID生成。如果设备接口上配置了全局单播IPv6地址,则无需使用上述命令让设备自动生成链路本地地址,一旦接口获得IPv6全局单播地址,会自动产生链路本地地址。关于EUI-64规范, 将在后文介绍。
特殊的地址¶
未指定地址,也就是全0地址“::/128”或者“0:0:0:0:0:0/128”¶
该地址作为某些报文的源地址,比如作为重复地址检测时发送的邻居请求报文(NS)的源地址, 或者DHCPv6初始化过程中客户端所发送的请求报文的源地址。
回环地址0:0:0:0:0:1/128,或者::1/128¶
用于本地回环,发往::/1的数据包实际上就是发给本地,可用于本地协议栈回环测试。
IPv4兼容地址¶
在过渡技术中会使用到一些包含IPv4地址的IPv6地址,为了让IPv4地址显得更加突出一些,定义了内嵌IPv4地址的IPv6地址格式。内嵌IPv4地址格式是过渡机制中使用的一种特殊表示方法。在这种
表示方法中,IPv6地址的部分使用十六进制表示,IPv4地址部分可用十进制格式。例如:
IPv4兼容地址用于过渡机制,如自动IPv4兼容隧道及NAT-PT等。该地址已经几乎不再使用。
接口 ID¶
接口ID的概念¶
接口ID(Interface Identification,接口标识)的长度为64bit,用于标识链路上的接口。在每条链路上, 接口ID必须唯一。接口ID有许多用途,最常见的用于就是黏贴在链路本地地址前缀后面,形成接口的链路本地地址。或者在无状态自动配置中,黏贴在获取到的IPv6全局单播地址前缀后面,构成接口的全局单播地址。
接口ID的设置¶
接口ID可通过3种方法生成:手工配置、系统自动生成,或基于IEEE EUI-64规范生成。其中,基于IEEE EUI-64规范自动生成的方式最为常用。EUI-64规范将接口的MAC地址转换为IPv6接口ID。
- 手工为接口配置接口ID。
- 可以根据IEEE的EUI-64规范将接口的48bit MAC地址转化为64bit的接口ID。
- 某些系统支持自动生成随机接口ID(例如Windows7)。
通过EUI-64规范根据MAC地址生成接口ID¶

假设一个接口的MAC地址如上图所示,那么采用EUI-64规范,接口可根据该MAC地址计算得到接口ID, 由于MAC地址全局唯一,因此该接口ID也相应的具备全局唯一性。计算过程如下。
将48bit的MAC地址对半劈开,然后插入“FFFE”,再对从左数起的第7位,也就是U/L位取反,即可得
到对应的接口ID。
在单播MAC地址中,第1个Byte的第7bit是U/L(Universal/Local,也称为G/L,其中G表示Global)位, 用于表示MAC地址的唯一性。如果U/L=0,则该MAC地址是全局管理地址,是由拥有OUI的厂商所分配的MAC地址;如果U/L=1,则是本地管理地址,是网络管理员基于业务目的自定义的MAC地址。
而在在EUI-64接口ID中,第7bit的含义与MAC地址正好相反,0表示本地管理,1表示全球管理,所以使用EUI-64格式的接口ID,U/L位为1,则地址是全球唯一的,如果为0,则为本地唯一。这就是为什么要反转该位。
组播地址¶
组播IPv6地址结构¶
一个IPv6组播地址由前缀(FF00::/8)、标志(Flag)字段、范围(Scope)字段以及组播组ID(Group
ID)4个部分组成。

知名的组播IPv6地址¶
一些常见的知名组播IPv6地址:
| FF02:0:0:0:0:0:0:1 | All Nodes Address |
|---|---|
| FF02:0:0:0:0:0:0:2 | All Routers Address |
| FF02:0:0:0:0:0:0:4 | DVMRP Routers |
| FF02:0:0:0:0:0:0:5 | OSPFIGP |
| FF02:0:0:0:0:0:0:6 | OSPFIGP Designated Routers |
|---|---|
| FF02:0:0:0:0:0:0:9 | RIP Routers |
| FF02:0:0:0:0:0:0:D | All PIM Routers |
| FF02:0:0:0:0:0:0:12 | VRRP |
| FF02:0:0:0:0:0:0:16 | All MLDv2-capable routers |
IPv6组播地址的MAC地址映射¶
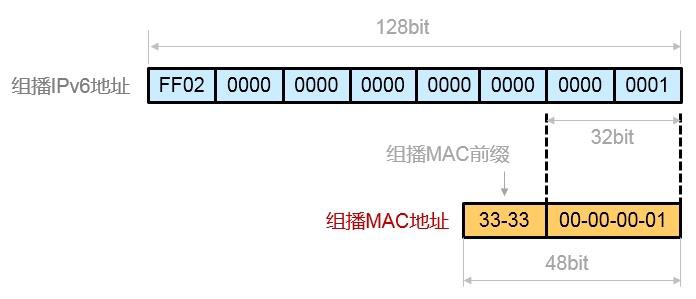
在以太网环境中,一个组播IPv6报文必须执行以太网封装。组播IPv6报文的目的IP地址是组播IPv6地址,而目的MAC地址则必须是组播MAC地址,并且该地址必须与组播IPv6地址对应。与组播IPv6地址对应的组播MAC地址,其映射关系如上图所示。33-33是专门为IPv6组播预留的MAC地址前缀,MAC 地址的后32bit从对应的组播IPv6地址的后32bit拷贝而来。
被请求节点组播地址¶
在IPv6组播地址中,有一种特别的组播地址,叫做被请求节点组播地址(Solicited-Node Multicast
Address)。被请求节点组播地址基于节点的单播或任播地址生成。
当一个节点具有了单播或任播地址,就会自动加入与之相对应的被请求节点组播组。一个单播地址或任播地址对应一个被请求节点组播组。被请求节点组播组采用被请求节点组播地址标识,该地址主要用于地址解析、邻居发现机制和地址重复检测等功能。
被请求节点组播地址由固定前缀FF02::1:FF00:0/104和对应IPv6地址的最后24bit组成。被请求节点组播地址的有效范围为本地链路范围。以下是一个示例:
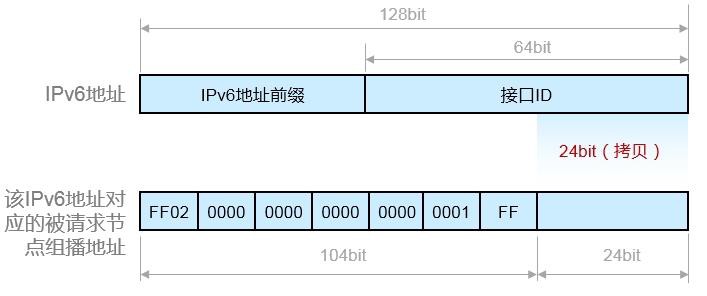
被请求节点组播地址的作用究竟是什么呢?举个非常简单的例子,回顾一下IPv4中的ARP,这个协议主要用于地址解析,当设备需要解析某个IP地址对应的MAC地址时,就会发送一个广播ARP Request帧,之所以要发送广播帧,是因为它要确保广播域内所有节点都能收到(它不知道目标节点的具体位置)。然而除了目标节点之外,该帧对于其他节点而言是个困扰,因为它们不得不去解析这个帧(从数据链路层封装一直解析到ARP载荷),这个动作将会浪费设备的资源。
在IPv6中,ARP及广播都被取消,当设备需要请求某个IPv6地址对应的MAC地址时,设备依然需要发送请 求报文,但是该报文是一个组播报文,其目的IPv6地址是目标IPv6单播地址对应的被请求节点组播地址,而 目的MAC地址则是该组播地址对应的组播MAC地址。由于只有目标节点才会侦听这个被请求节点组播地址, 因此当其他设备收到该帧时,这些设备可以通过目的MAC地址、在网卡层面就判断出不需要处理它并将帧 丢弃。
- 基础配置
基础配置命令¶
全局激活设备的IPv6功能:¶
[Quidway] ipv6
在网络设备上进行IPv6的各种配置之前,必须首先在系统视图下激活设备的IPv6功能。
激活设备接口的IPv6功能:¶
[Quidway-GigabitEthernet0/0/0] ipv6 enable
在接口上进行IPv6的各种配置之前,必须首先在接口上激活IPv6功能。
配置设备接口的IPv6全局单播地址:¶
[Quidway-GigabitEthernet0/0/0] ipv6 address 2001::1 64
上面的命令用于为接口指定具体的IPv6地址,其中包括前缀及接口ID。当然,也可为接口指定具体的
IPv6前缀,而接口ID则让设备通过EUI-64规范自动产生,使用如下命令:
[Quidway-GigabitEthernet0/0/0] ipv6 address 2001:: 64 eui-64
配置设备接口的IPv6链路本地地址:¶
当一个接口激活IPv6后,该接口没有任何IPv6地址,为了让接口能够正常工作,需要为接口配置IPv6地
址,当用户为接口配置全局IPv6单播地址后,接口将自动配置链路本地地址,无需人为干预。
但是如果接口没有获得任何IPv6单播地址,而我们又希望接口能正常工作,那么需选用上面两条命令中的一条进行链路本地地址的配置。
实验 1:IPv6 入门实验¶
拓扑及需求¶

网络拓扑如上图所示,PC的默认网关为Switch,完成所有设备的配置,使得PC能够ping通Router的
Loopback0接口。
配置及实现¶
Switch的配置如下:
Router的配置如下:
PC的网卡配置如下:
完成上述配置后,PC即可ping通2001:2222::1。此时看一下路由器的相关参数:
| [Router] display ipv6 interface brief | ||
|---|---|---|
| *down: administratively down | ||
| (l): loopback (s): spoofing | ||
| Interface | Physical | Protocol |
| GigabitEthernet0/0/0 [IPv6 Address] 2012::2 | up | up |
| LoopBack0 | up | up(s) |
| [IPv6 Address] 2001:2222::1 |
以上输出的是Router的IPv6接口摘要,可以看到我们配置的两个接口的IPv6地址。
可以进一步查看某个接口的详细参数:

再查看一下路由器的IPv6路由表中的静态路由:
实验 2:无状态地址自动配置¶
拓扑及需求¶

网络拓扑如上图所示,其中PC的默认网关为Switch。PC通过无状态地址自动配置的方式获得其全局单播IPv6地址及默认网关地址。完成所有设备的配置,使得PC能够ping通Router的Loopback0接口。
配置及实现¶
Router的配置如下:
Switch的配置如下:
PC网卡的配置如下:
完成上述配置后,由于Router开启了RA(Router Advertisement,路由器通告)报文的通告功能,因此会从vlanif10接口发送RA报文,而RA报文中包含了vlanif10的IPv6全局单播地址前缀信息(2001::/64), PC网卡在接收到这个信息后,就可以根据前缀信息再加上自己网卡的标识符构成IPv6全局单播地址。
PC网卡获取的地址:
TCPIP 上 的 NetBIOS . . . . . . . : 已 启 用
如此一来PC就能够ping通2001:2222::1了。
- ICMPv6
ICMPv6 概述¶
ICMPv6是IPv6的基础协议之一。在IPv6中,ICMPv6除了提供ICMPv4的对应功能之外,还是其它一些功能的基础,如邻居发现、无状态地址配置、重复地址检测、PMTU发现等。
ICMPv6报文有两种:差错报文及信息报文。
IANA在IPv6包头的NextHeader字段中,为ICMPv6分配的值是58。如果报文存在IPv6扩展包头,那么ICMPv6 载荷与TCP、UDP载荷一样,必须位于所有扩展包头之后。在IPv6包头中,NextHead=58则表示IPv6包头后封装着一个ICMPv6报文。
在ICMPv6的报文头部中,Type字段用于指示报文类型,Code字段用于进一步指示报文的作用。以下是一些常见的ICMPv6报文类型:
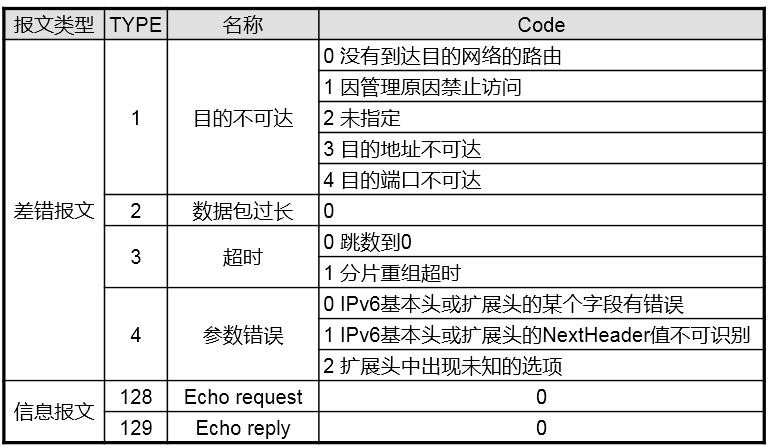
还有一些其他报文,为NDP而定义,后续介绍。
NDP¶
NDP概述¶
NDP(Neighbor Discovery Protocol,邻居发现协议)在RFC2462及RFC4861中定义。NDP实现了IPv6中诸多重要机制,如下图所示:
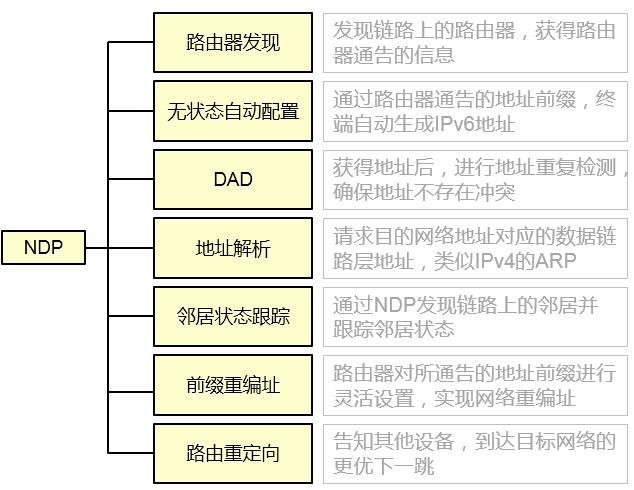
- **路由器发现:**该功能帮助设备发现链路上的路由器,并获得路由器通告的信息。
- **无状态自动配置:**无状态自动配置是IPv6的一个亮点功能,它使得IPv6主机能够非常便捷地连入到IPv6 网络中,即插即用,无需手工配置繁冗的IPv6地址,无需部署应用服务器(例如DHCP服务器)为主机分发地址。无状态自动配置机制使用到了ICMPv6中的路由器请求报文(RS)及路由器通告报文(RA)。
- **重复地址检测:**重复地址检测是一个非常重要的机制,一个IPv6地址必须经历重复地址检测并通过检测之后才能够启用。重复地址检测用于发现链路上是否存在IPv6地址冲突。
- **地址解析:**在IPv6中,取消了IPv4中的ARP协议,使用NDP所定义的邻居请求报文(NS)及邻居通告报文(NA)来实现地址解析功能。
- **邻居的状态跟踪:**IPv6定义了节点之间邻居的状态机,同时还维护邻居IPv6地址与二层地址如MAC的映射关系,相应的表项存储于设备的IPv6邻居表中。
- **前缀重编址:**IPv6路由器能够通过ICMPv6的路由器通告报文(RA)向链路上通告IPv6前缀信息。通过这种方式,主机能够从RA中所包含的前缀信息自动构建自己的IPv6单播地址。当然这些自动获取的地址是有生存时间的。通过在RA中通告IPv6地址前缀,并且灵活地设定地址的生存时间,能够实现网络中IPv6新、老前缀的平滑过渡,而无需在主机终端上消耗大量的手工劳动重新配置地址。
-
**路由器重定向:**路由器向一个IPv6节点发送ICMPv6的重定向报文,通知它在相同的本地链路上有一个更好的、到达目的地的下一跳。IPv6中的重定向功能与IPv4中的是一样的。
NDP使用ICMPv6的相关报文实现其功能:
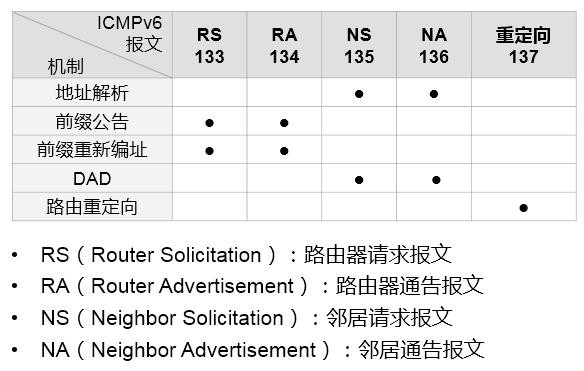
地址解析¶
两个节点之间要进行IP通信,除了需知晓双方的网络地址,还需要知道网络地址对应的数据链路层地址以便组装数据帧,在以太网环境中,这个数据链路层地址就是MAC地址。在IPv4中ARP用于帮助节点获取目标
IP地址对应的MAC地址。ARP使用广播的方式发送Request报文以便请求目标地址对应的MAC地址,这实际上造成了链路上其他节点的额外负担。
NDP使用Type 135(邻居请求报文NS)及Type 136(邻居通告报文NA)来替代ARP实现地址解析。具体的过程如下:
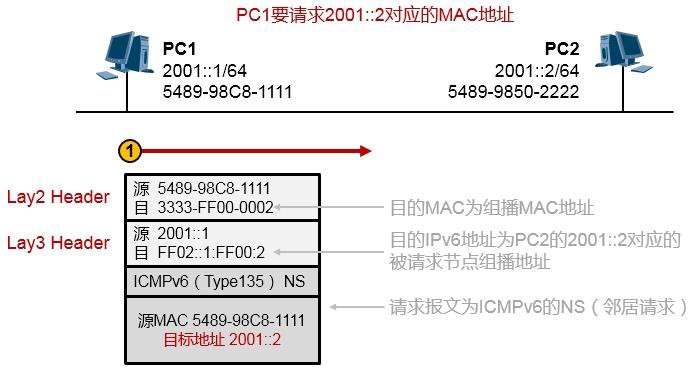
在上图所示的场景中,PC1要请求PC2的2001::2这个地址对应的MAC地址,PC1将发送一个NS报文达到这个目的。这个NS报文的源地址是2001::1,目的地址则是2001::2对应的被请求节点组播地址。
然后IPv6数据包又被封装上数据帧的头部,其中源MAC地址是PC1的MAC地址,目的MAC地址则是2001::2
这个目标地址对应的被请求节点组播地址映射得到的MAC地址,这是一个组播MAC地址。
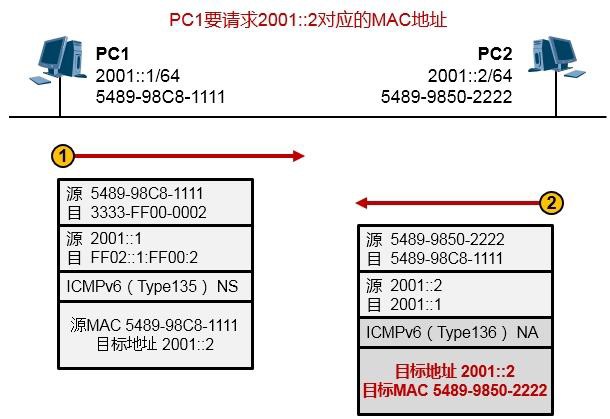
除PC2外的其他节点也会收到这个数据帧,在读取数据帧头的时候发现目的MAC地址是一个组播MAC地址, 而该组播MAC地址在本地并不侦听,因此在网卡层面就将数据帧丢弃而不再往报文里看了。
PC2收到这个数据帧后,由于本地网卡接收目的MAC地址为3333-FF00-0002的数据帧,因此在对数据帧做校验之后从帧头的类型字段得知里头是个IPv6报文,于是将帧头拆掉,把IPv6报文上送IPv6协议栈处理。
IPv6 协议栈从报文的IPv6 头部中的目的IPv6 地址得知这个数据包是发往一个被请求节点组播地址
FF02::1:FF00:2,而本地网卡加入了这个组播组。接着,从IPv6包头的NextHeader字段得知IPv6包头后面封装着一个ICMPv6的报文,因此将IPv6包头拆除,将ICMPv6报文交给ICMPv6协议去处理。最后ICMPv6 发现这是个NS报文,要请求自己2001::2对应的MAC地址,于是回送一个NA报文给PC1,在该报文中就包含着PC2的MAC地址。
在windows7里,可以使用**netsh interface ipv6 show neighbors**命令查看邻居缓存的内容。IPv6不像IPv4 那样使用ARP表来缓存IP与MAC地址的映射,而是维护一个IPv6邻居表。在华为数通设备上则使用**display ipv6 neighbors**命令来查看IPv6邻居表。
以下是某台设备的IPv6邻居表:
重复地址检测¶
DAD(Duplicate Address Detection,重复地址检测),用于确保IPv6单播地址在链路上不存在冲突(重复) 所有IPv6单播地址都需要通过DAD检测(包括链路本地地址),确保无冲突后才能够正式启用。一个IPv6地址在通过DAD检测之前是“tentative”地址,也就是试验性地址。接口暂时还不能使用这个地址进行正常的
IPv6通讯,但是会加入该地址所对应的Solicited-Node组播组。
DAD使用NS(邻居请求)和NA(邻居通告)来实现其功能。
DAD的基本机制:节点向IPv6地址对应的被请求节点组播组地址发送一个NS报文,如果收到NA报文,就证明该地址已被链路上的其他设备使用了,它将不能使用该地址,否则,一段时间后,如果没有设备回应,则正式启用该地址。
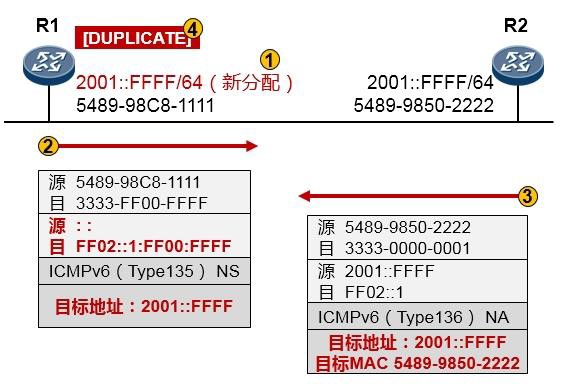
在上图中,R2已是在线的设备,该设备已经使用了如图所示的地址,现在我们为R1新配置IPv6的地址
2001::FFFF/64,观察一下会发生什么事情。R1的接口配置2001::FFFF/64地址后,该地址立即进入tentative
状态,此时仍然是不可用的,除非该地址通过DAD检测。
-
R1向链路上以组播的方式发送一个NS报文,该NS的源IPv6地址为“::”,目的IPv6地址为要进行DAD 检测的2001::FFFF对应的被请求节点组播地址,也就是FF02::1:FF00:FFFF。这个NS里包含着要做
DAD检测的目标地址2001::FFFF。
-
链路上的节点都会收到这个组播的NS报文,没有配置2001::FFFF的节点接口由于没有加入该地址对应的被请求节点组播组,因此在收到这个NS的时候默默丢弃。而R2在收到这个NS后,由于它的接口配置了2001::FFFF地址,因此接口会加入组播组FF02::1:FF00:FFFF,而此刻所收到的报文又是以该地址为目的地址,因此它会解析该报文,它发现对方进行DAD的目标地址与自己本地接口地址相同,于是立即回送一个NA报文,该报文的目的地址是FF02::1,也就是所有节点组播地址,同时在报文内写入目标地址2001::FFFF,以及自己接口的MAC地址。
-
当R1收到这个NA后,它就知道2001::FFFF在链路上已经有人在用了,因此将该地址标记为Duplicate
(重复的),该地址将不能用于通信。此时在R1上可以观察到如下现象:
无状态自动配置¶
在IPv6中,设备可以通过手工或者动态的方式获取地址。在动态获取地址的方式中,存在DHCPv6及无状态地址自动配置两种方式。
IPv6地址无状态自动配置(StateLess Address AutoConfiguration,SLAAC)是IPv6的标准功能,在RFC2462中定义。使用IPv6地址无状态自动配置后,设备的IPv6地址无需进行手工配置,而是即插即用,这减轻网络管理的负担。相比于DHCPv6这种动态地址分配技术而言,SLAAC无需部署应用服务器,更加轻量。当然,
它也有缺点,例如SLAAC无法对终端所使用的地址进行管理,也并不记录地址分配结果。
大致的工作过程如下:¶
- 主机根据本地接口ID自动产生网卡的链路本地地址。
- 主机对链路本地地址进行DAD检测, 如果该地址不存在冲突则可以启用。
- 主机发送RS报文尝试在链路上发现IPv6路由器,该报文的源地址为主机的链路本地地址。
- 路由器回复RA报文(携带IPv6前缀信息,路由器在未收到RS时也能够通过配置主动发出RA报文)。
- 主机根据路由器回应的RA报文,获得IPv6地址前缀信息,使用该地址前缀,加上本地产生的接口ID, 形成单播IPv6地址。
-
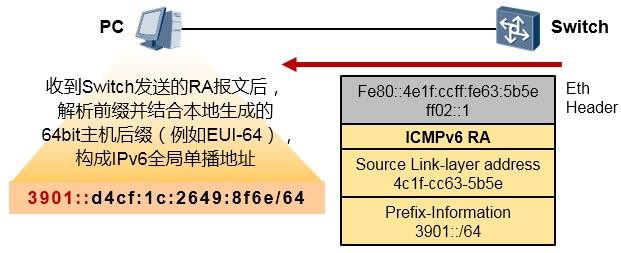 主机对生成的IPv6地址进行DAD检测,如果没有检测到冲突,那么该地址才能够启用。
主机对生成的IPv6地址进行DAD检测,如果没有检测到冲突,那么该地址才能够启用。华为路由器和交换机都可以配置RA通告功能,在RA报文中通告IPv6地址前缀。
路由器发现¶
路由器发现功能用来发现与本地链路相连的路由器(也可以是交换机等),并获取与地址自动配置相关的前缀和其他配置参数。经过前面的介绍,我们已经知道IPv6地址支持无状态自动配置,即主机通过路由器发送的RA报文获取网络前缀信息,然后主机自己生成地址的接口标识部分,并自动配置IPv6地址。
路由器发现功能是IPv6地址自动配置功能的基础,主要通过以下两种报文实现:
- RA(Router Advertisement,路由器通告)报文:每台设备为了让二层网络上的主机和设备知道自己的存在,可以定时以组播方式发送RA报文,RA报文中会带有网络前缀信息,及其他一些标志位信息。RA 报文的Type字段值为134。
- RS(Router Solicitation,路由器请求)报文:很多情况下主机接入网络后希望尽快获取网络前缀进行通信,此时主机可以立刻发送RS报文,网络上的设备将回应RA报文。RS报文的Tpye字段值为133。
RA报文解析¶
RA报文格式如下:


RA报文中的可选字段:前缀信息¶
在一个RA报文中,可以包含多个ICMPv6 Option(可选项),路由器向链路通告的IPv6地址前缀信息就是以ICMPv6 Option的形式被RA报文携带的。一个RA报文可以包含0个、1个或者多个IPv6前缀,每个前缀都以一个Option来携带。
下面我们看看用于携带IPv6前缀的Option有什么进一步的内容:


从报文中可以看到,用于携带IPv6前缀的Option内,除了有前缀信息,以及前缀长度,还有几个标志位,和两个lifetime。关于标志位上面已经有所介绍了,而这两个lifetime请看下文。
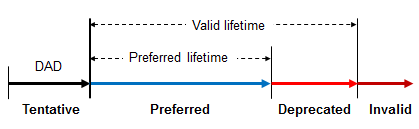
前面已经说了,路由器发送的RA中可以包含IPv6前缀信息,主机在收到RA后,就能够使用RA中所携带的IPv6前缀来构造自己的IPv6单播地址。在RA所携带的每个IPv6前缀信息中都各自捆绑了两个
lifetime,其中一个是valid lifetime,另一个是preferred lifetime。
在主机使用RA中的前缀构造IPv6单播地址后,该地址需要先经过DAD,在DAD过程中的地址状态为
tantative,还不能够启用。DAD通过后地址即可正式启用,地址启用后进入Preferred状态,同时启动计时器,当地址生存时间超过preferred lifetime时,地址进入deprecated状态,处于该状态的地址只能用于被动接收连接,而不能够用于主动发起的连接。当地址的生存时间超出valid lifetime后,地址就变成了invalid,不再可用。
修改RA报文的相关参数¶
RA报文的相关参数的修改在接口上完成:
ipv6 nd ra halt¶
抑制接口的RA报文周期性发送,该命令默认开启,也就是说默认情况下,接口不会周期性发送RA 报文,使用**undo**关键字可将该命令取消。
ipv6 nd ra hop-limit¶
修改RA报文中hop-limit字段的值,该值作为主机发送出来的IPv6报文的hop-limit。
ipv6 nd ra max-interval 及 ipv6 nd ra min-interval¶
周期性发送RA报文的最大及最小时间间隔。
ipv6 nd ra prefix¶
修改RA报文所携带的IPv6前缀及前缀所关联的参数,这条命令的详细内容请见下文。
ipv6 nd ra router-lifetime¶
修改RA报文中router-lifetime的值,默认1800s。
使用**ipv6 nd ra prefix**命令,可以修改RA报文所携带的IPv6前缀及其所关联的参数:
1. ipv6 nd ra prefix 2001:: 64 360000 180000
修改特定前缀的**valid lifetime**及**preferred lifetime** ,注意前者一定要比后者大。
2. ipv6 nd ra prefix 2001:: 64 360000 180000 no-autoconfig
将该前缀的A比特设置为0,该前缀将不能被用于无状态自动配置。
3. ipv6 nd ra prefix 2001:: 64 360000 180000 off-link
将该前缀的L比特设置为0。
- IPv6 过渡技术
概述¶
现今IP网络仍然是以IPv4为主体,IPv6网络只是得到小范围的部署和商用,因此必然会在很长的一个时期内,IPv4及IPv6网络会有共存的场景,那就需要考虑V4V6并存的策略和技术。
同时从IPv4过渡到IPv6不可能一气呵成,这是一个综合政治、经济、商业、技术、方法、策略等各种因素的问题,因此IPv4到IPv6的过渡需要一个漫长的过程。在这个过程中,就不得不考虑过渡的策略和方法。以下是三种常见的共存策略和过渡技术:
双栈DualStack¶
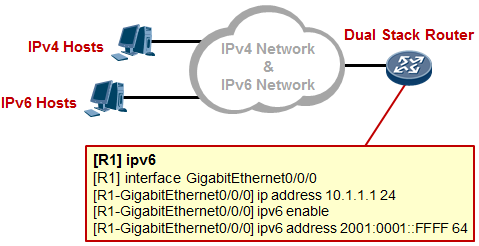
所谓的双栈就是主机或者网络设备同时支持IPv4及IPv6双协议栈,如果节点支持双栈,那么它能够同时使用V4和V6的协议栈、同时处理IPv4及IPv6的数据。
在双栈设备上,上层应用会优先选择IPv6协议栈,而不是IPv4。比如,一个同时支持v4和v6的应用请求通过DNS请求地址,会先请求AAAA记录,如果没有,则再请求A记录。
就拿上图来说,路由器就是一个双栈设备,默认情况下路由器本身就已经支持IPv4,接口上也配置了
IPv4的地址,已经能够正常转发IPv4的报文,此刻在激活路由器的IPv6数据转发能力,再为接口分配
IPv6的单播地址,那么这个接口又有了IPv6数据转发能力。当然,此时对于路由器而言,IPv4及IPv6协议栈互不干扰,独立工作。
双栈是V4、V6并存及IPv6过渡技术的基础。
隧道技术¶
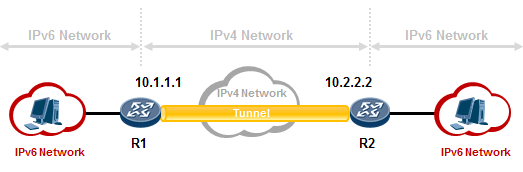
隧道技术是一种非常经典的解决方案,被应用在各种场景中解决数据通信问题。简单地说就是在两个通信孤岛之间搭建一条虚拟通道,使得此二者能够通过这条隧道、穿越中间的网络进行通信。隧道技术的核心思想其实就是将一种协议的数据报文封装在另一种协议中,例如将IPv6报文封装在IPv4头部后,使得IPv6流量能够穿越IPv4网络,反之亦然。
上图所示的场景中,R1及R2都连接到同一个IPv4网络中,同时还各自连接一个IPv6网络。此刻R1及R2 均是双栈路由器,而两者各自下挂的这两个IPv6网络其实是信息孤岛,彼此之间无法互相通信,因为要通信就需要经过中间的网络,而中间的网络是IPv4的,根本无法识别IPv6数据。
这个场景相信在如今的网络中是常见的,毕竟如今IP网络的主体还是IPv4,IPv6的站点只是零星建立, 那么如何实现IPv6站点之间的相互通信呢。
利用隧道技术可以在R1及R2之间建立起一条点到点的通道,这条虚拟通道穿越了中间的IPv4网络,使得两个信息孤岛之间能够互通。实际上孤岛之间的IPv6互访流量还是经过中间的IPv4网络进行转发,只不过在被转发的IPv6报文基础之上增加了一个新的IPv4头部,这个头部我们称之为隧道头,正是这个隧道IPv4头部,使得IPv6报文能够被包裹在其中从而穿越中间的IPv4网络。
NAT64¶
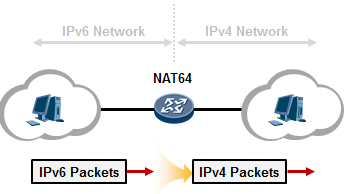
NAT64技术实际上是一种协议转换技术,能够将分组在V4及V6格式之间灵活转换。当IPv4网络的节点需要直接与IPv6网络的节点进行通信时,默认情况下当然是行不通的,因为两个协议栈无法兼容。但是借助一台设备,由该设备来实现IPv6与IPv4的互转,那么上述通信需求就可以实现了。
IPv6 Over IPv4 手工隧道¶
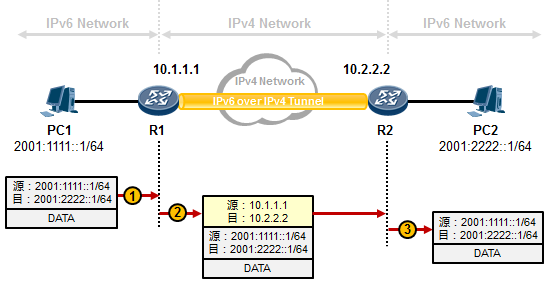
上图所示的场景中,R1及R2都连接到同一个IPv4网络中,R1使用地址10.1.1.1接入IPv4网络,R2使用
10.2.2.2接入IPv4网络,两者的IPv4地址能够互通。
此外R1、R2还连接到一个IPv6网络,而两者各自下挂的这两个IPv6网络其实是信息孤岛,彼此之间无法互相通信,因为IPv6报文不可能直接被送到IPv4网络,这种报文在中间的网络是不可被路由的。
在R1及R2之间利用隧道技术可以建立起一条点到点的通道,我们这里使用的是IPv6 Over IPv4的手工隧道, 也就是在R1及R2之间建立一条虚拟的手工隧道,在R1上隧道的源是10.1.1.1,目的是10.2.2.2,只要是PC1 访问PC2的流量就往隧道里扔。R2同理,隧道的源是10.2.2.2,目的是10.1.1.1。
现在当PC1要访问PC2时,PC1发送出来的是IPv6数据,这些数据被丢给默认网关R1,R1经过IPv6路由表查询后发现这些数据要送往隧道接口,于是这些IPv6报文被封装上一个隧道的IPv4头部,在IPv4头部中源IP 地址为隧道的源地址10.1.1.1,目的IP地址为隧道的目的地址10.2.2.2。然后这个被封装的报文就送入了IPv4 网络,由于报文外头封装了一个IPv4的头部,因此IPv4网络中的设备将只会解析这个IPv4头部,而不会关心里头装的是什么,这个报文被一路转发最终到达10.2.2.2,也就是R2。R2再将报文的IPv4头部拆除,然后将里头的IPv6原始数据转发给PC2。
实验拓扑及需求¶

设备配置及实现¶
R3的配置如下
R1的配置如下:
R2的配置如下:
几个注意事项:
- 隧道两端的地址:10.1.1.1及10.2.2.2必须路由可达,否则隧道建立不成功。
- IPv6 Over IPv4手工隧道需要在隧道接口的配置中手工指定隧道的源和目的。
- Ipv6 route-static 2001:1111:: 64 tunnel0/0/0这条路由,将去往该IPv6网络的数据包送到隧道接口,这些数据就会被封装上隧道IPv4的头部然后送到IPv4网络。
完成配置后,做一些基本的验证及查看:
以上输出的是R1上接口IPv6摘要信息,可以看到为GE0/0/1口配置的IPv6地址,以及Tunnel0/0/0口的链路
本地地址。
GRE 隧道¶
GRE(Generic Routing Encapsulation,通用路由封装)是一种隧道协议,可以在虚拟点对点链路中封装多种上层协议,它在RFC 2784中定义,它的通用性特别高,能够支持各种各样的上层协议。
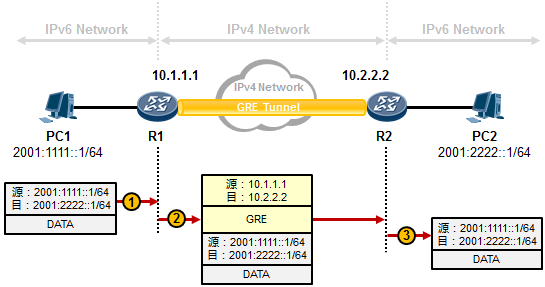
从上图可以看出,其实采用GRE隧道,与上文介绍的IPv6 Over IPv4手工隧道在机制上并没有太大的区别,
都是为原始的IPv6数据包封装上新的头部,只不过GRE这种机制除了会为IPv6数据封装上新的隧道IPv4头部外,还会加上一个GRE的头部。
实验拓扑及需求¶
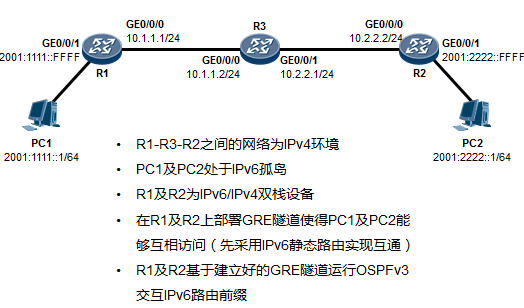
设备配置及实现¶
R3的配置如下
R1的配置如下:
R2的配置如下:
为了完成这个实验,我们在R1及R2上配置了IPv6静态路由,然而静态路由是需要手工配置的,而且欠缺灵
活性,采用动态路由协议可以解决这些问题,但是R1-R3并非直连路由器,如何能够运行IPv6动态路由协议?
得益于R1-R2之间已经建立起来的GRE隧道,R1、R2相当于打通了一条承载在IPv4网络上的IPv6点到点“直连链路”——虽然这条链路是虚拟的。基于这条直连链路,R1、R2即可运行IPv6动态路由协议从而动态地交互路由信息。

现在,去掉R1、R2上配置的IPv6静态路由(命令不再赘述)。然后在R1及R2上增补配置:
R1的增补配置如下:
R2的增补配置如下:
完成上述配置后,R1、R2即会通过GRE Tunnel发送OSPFv3 Hello从而发现邻居,随后建立OSPFv3邻居关系。此时在R1上查看OSPFv3邻居表如下:
在R1上查看IPv6路由表中通过OSPF学习到的路由:
R1已经学习到2001:2::/64路由,R2也学到了2001:1::/64路由,因此PC1及PC2能够互相ping通,通过抓包可以观察到OSPFv3在GRE隧道上的工作过程。实际上我们并未给Tunnel接口配置全局单播IPv6地址,但是
OSPFv3依然能够正常工作,这是因为R1及R2使用的是Tunnel接口的链路本地地址建立OSPFv3邻居关系, 以及作为路由的下一跳地址。
使用IPv6 Over IPv4手工隧道时,也可以像本例这样,在隧道端点设备之间建立OSPFv3邻接关系从而交互
OSPF路由,但是相对的,GRE的通用性较好,可用于承载各种上层协议,因此在面对IS-IS这样的路由协议时间,IPv6 Over IPv4手工隧道场景就可能出现问题,而GRE则不会有问题。
6to4 自动隧道¶

上文介绍的两种隧道机制有个共同的特点,就是隧道的对端需明确指定,例如在R1上建隧道,需要指定隧道的目的端为10.2.2.2,这种手工建隧道的方式在站点少、而且地址固定的情况下可行,但是可展性太差。
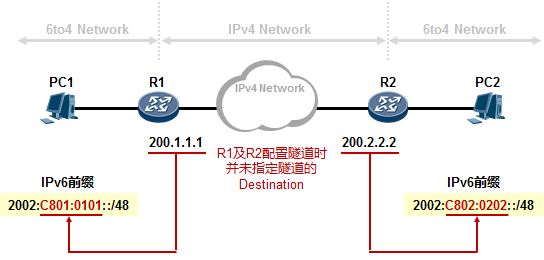
相比之下,6to4自动隧道则要灵活许多。6to4自动隧道利用IPv6单播地址中的6to4地址。6to4地址是一类特殊的IPv6单播地址,它通过IPv4地址映射而来。例如R1已经有IPv4地址200.1.1.1,那么该IPv4地址对应的6to4 IPv6地址就是2002:C801:0101:: /48,其中**C801:0101**就是200.1.1.1的16进制形式。如此一来就得到了/48的IPv6地址前缀,这个前缀可进一步进行子网划分,最终形成/64的IPv6前缀用于终端。R2这一侧的
IPv6网络同理。
现在当PC1要访问PC2这一侧的IPv6网络时,其发出的报文的目的IPv6地址就是2002:C802:0202::/48这一前缀下的某个IPv6地址,而这个IPv6数据包到达R1后,R1从目的IPv6地址中取出IPv4地址的映射部分,也就是C802:0202,进而得到200.2.2.2,这就是隧道的目的地址。IPv6报文被封装上隧道的IPv4头部,源地址为200.1.1.1,目的地址为200.2.2.2。
实验拓扑及需求¶

设备配置及实现¶
Internet Router的配置如下
R1的配置如下:
R2的配置如下:
在6to4 自动隧道的解决方案中,我们利用了2002::/16的6to4知名地址空间。
首先R1及R2都已经有了200.1.1.1及200.2.2.2的IPv4地址。拿R1来说,我们可以通过R1的地址200.1.1.1映射得到该IP对应的2002::/16前缀的6to4 IPv6地址,如上图所示,对于R1所在的站点,得到的6to4 IPv6地址空间就是2002:C801:0101::/48,前缀中的前16bit也就是2002是固定的,后面的32bit就是200.1.1.1这个地址对应的16进制数,组装后就得到/48bit的IPv6地址前缀,这样一来PC1所在网络就可以使用这个IPv6地址来组建网络:
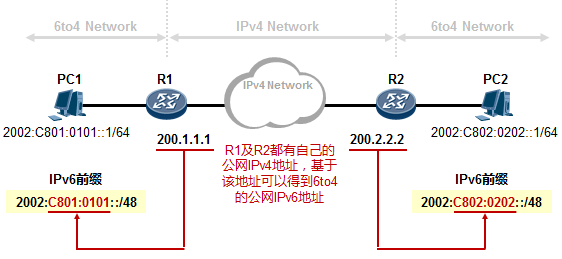
当PC1要访问2002:C802:0202::/48网络时:
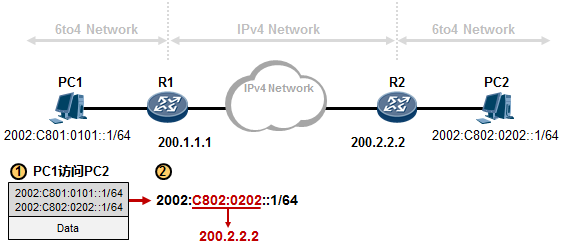
数据包到达R1后,R1发现目的地址是IPv6地址,而且是2002开头的地址,这是个6to4的IPv6地址,于是从该地址中抽离出C802:0202,得到200.2.2.2这个IPv4地址。然后:
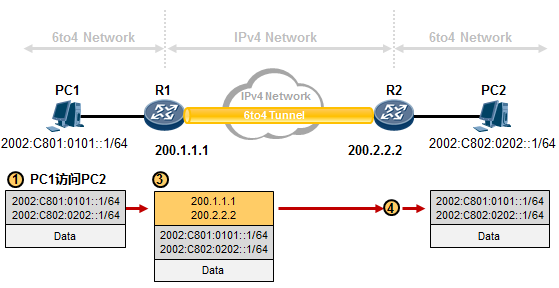
R1在原始IPv6报文的基础上加装IPv4头部,IPv4头部的源地址为6to4tunnel的源地址,而目的地址为
200.2.2.2。数据包被路由到R2后,R2将外层的IPv4头部剥除,将里头的IPv6报文转发给PC2。
NAT64 概述¶
场景1:NAT64(动态映射)¶
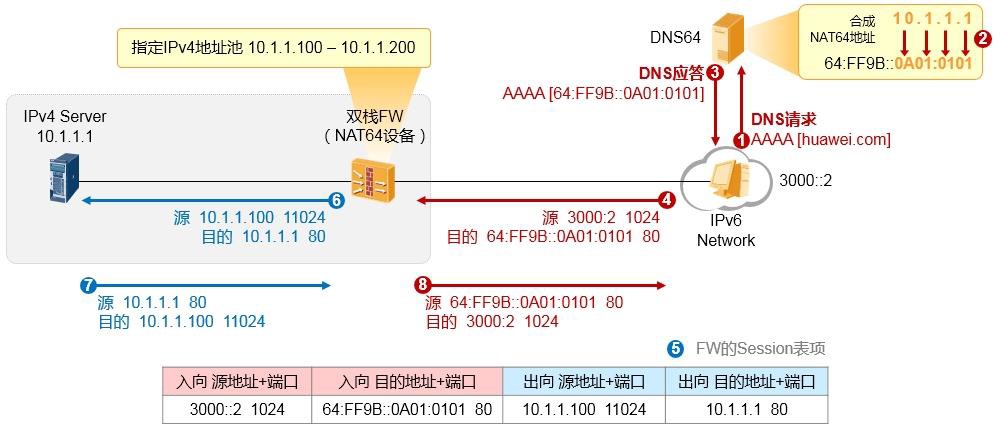
NAT64动态映射只适用于IPv6用户主动发起访问IPv4 Server的场景。
- IPv6用户发起AAAA DNS请求(huawei.com)。
- DNS64收到请求报文后,先解析AAAA请求,如果解析不到IPv6地址,再发起A请求,通过解析发现此
服 务 地 址 为 IPv4 地 址 , 根 据 配 置 的 Prefix64::/n ( 在 本 例 中 是 9b::/96 ) , 合 成 NAT64 地址
(64:FF9B::0A01:0101)。
- DNS64将应答发给用户。
- 用户收到DNS64的回复后,发送IPv6报文给该目标服务器。
- FW收到用户发出的IPv6报文后,使用地址转换算法提取出IPv6报文中的IPv4地址(10.1.1.1),以此IPv4 地址作为IPv4报文的目的地址。然后根据NAT64策略配置的映射关系,以NAT地址池中的地址为IPv4 报文的源地址(例如10.1.1.100),将IPv6报文转换为IPv4报文,发送给IPv4网络中的服务器。并生成有地址对应关系的会话表。
- 服务器收到报文后,回复响应报文。
-
NAT64收到IPv4网络中服务器的响应报文后,根据会话表将IPv4报文转换为IPv6报文,然后发送至IPv6
用户。
需要DNS64配合;可用知名NAT64前缀64:FF9B::/96或自定义前缀;配置DNS64时,需确保NAT64前缀和前缀长度与FW上的配置相同
场景2:NAT64(静态映射)¶
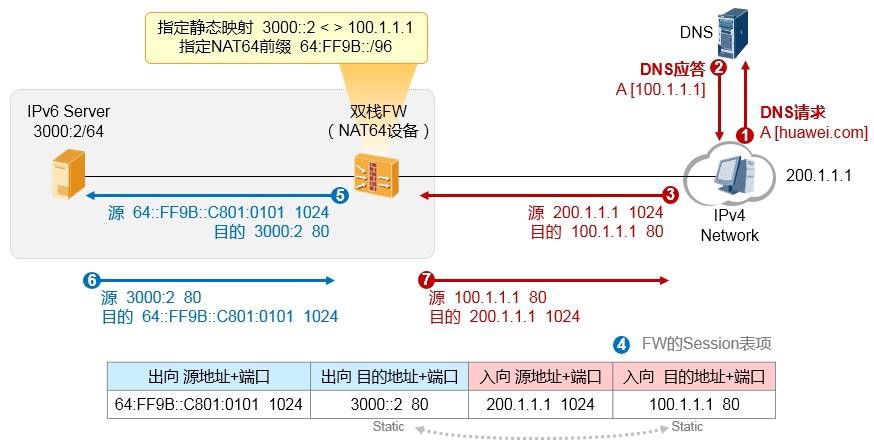
静态NAT64不仅可以实现IPv6用户访问IPv4服务器,也为IPv4用户访问IPv6服务器提供了一种方案。
- IPv4用户向DNS发起A请求(Huawei.com)。
- DNS收到请求报文后,解析域名对应的IPv4地址100.1.1.1(A请求如果无法解析IPv4地址,报文将丢弃。此场景中,域名与地址关系一般已经提前在DNS设定好),然后发送回复报文给用户。
- 用户收到DNS的回复报文后,把解析的地址作为目的地址发往远端服务器。
-
NAT64设备收到用户发出的IPv4报文后,根据事先设置好的静态映射关系(会产成Server-Map表),把报文的目的IPv4地址转换成对应的IPv6地址3000::2,以此IPv6地址作为IPv6报文的目的地址,把
IPv4报文与设置好的NAT64前缀合成IPv6报文的源地址(64:ff9b::c801:0101),完成IPv4报文到IPv6
报文的转换,发送给IPv6网络中的服务器。并生成会话表。
- 服务器收到报文后,回复响应报文。
-
NAT64收到IPv6网络中服务器的响应报文后,根据会话表将IPv6报文转换为IPv4报文,然后发送至
IPv4用户。
需在NAT64设备上配置IPv4地址与IPv6地址的静态映射,该映射不会老化。
-
NAT64(IPv6 节点主动访问 IPv4 服务器)¶
拓扑及需求¶
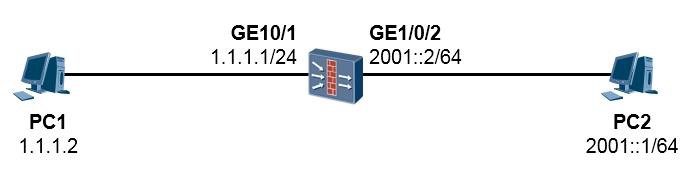
- PC1是IPv4网络的一个节点,处于Trust安全域。
- PC2是IPv6网络的一个节点(可能是一台服务器),处于Untrust安全域。
- 在防火墙上完成NAT64的配置,使得PC2能够主动发起流量访问PC1。
- 在本实验中,防火墙以华为USG6000 V5R1C60的配置为例进行介绍。
配置及实现¶
FW的配置如下:
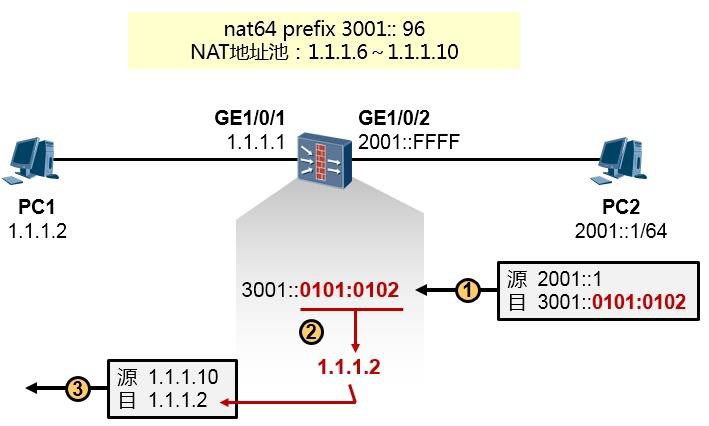
在本例中,我们没有设置DNS64,因此PC2直接使用3001::0101:0102这个地址来访问PC1,但是为什么是这个地址?3001::/96这个前缀是我们在配置的时候指定的,而这个目的地址的最后32bit也就是
0101:0102,换算成10进制就是1.1.1.2,因此当防火墙收到目的地址为3001::0101:0102的IPv6数据包时,根据该地址的最后32bit计算得到IPv4地址, 这就是协议转换后的IPv4目的地址,而IPv4源地址则从NAT64地址池中挑一个。
此时在防火墙上能看到如下IPv6会话表项:
NAT64(IPv4 节点主动访问 IPv6 服务器)¶
拓扑及需求¶
PC1是IPv4网络的一个节点,处于Trust安全域;PC2是IPv6网络的一个节点,处于Untrust安全域。在防火墙上完成NAT64的配置,使得PC1能够主动发起流量访问PC2。
在本实验中,防火墙以华为USG6000 V5R1C60的配置为例进行介绍。
配置及实现¶
FW的配置如下:
[FW] interface GigabitEthernet 1/0/1
[FW-GigabitEthernet1/0/1] ip address 1.1.1.1 24 [FW] firewall zone trust
[FW-zone-trust] add interface GigabitEthernet1/0/1
[FW] ipv6
[FW] interface GigabitEthernet 1/0/2 [FW-GigabitEthernet1/0/2] ipv6 enable
[FW-GigabitEthernet1/0/2] ipv6 address 2001::2 64 #激活接口的NAT64功能
[FW-GigabitEthernet1/0/2] nat64 enable [FW] firewall zone untrust
[FW-zone-untrust] add interface GigabitEthernet1/0/2
#配置NAT64前缀,PC1访问PC2的报文在IPv6网络中传输时使用的源地址由NAT64前缀和PC1的IPv4地址组合而成: [FW] nat64 prefix 3001:: 96
#配置NAT64静态映射关系,将PC2的IPv6地址2001::1映射为IPv4地址1.1.1.10,PC1将以1.1.1.10为目的地址访问PC2: [FW] nat64 static 2001::1 1.1.1.10 unr-route
#配置安全策略: [FW] security-policy
[FW-policy-security] rule name policy_sec_1
[FW-policy-security-rule-policy_sec_1] source-zone trust
[FW-policy-security-rule-policy_sec_1] destination-zone untrust
[FW-policy-security-rule-policy_sec_1] destination-address 2001::1 64 [FW-policy-security-rule-policy_sec_1] action permit
完成配置后,PC1即可ping通1.1.1.10,也即PC2。在FW任意视图下执行**display firewall ipv6 session**
table,查看NAT64的会话表信息。
MPLS 与 MPLS VPN¶
- MPLS 基础
MPLS 概述¶
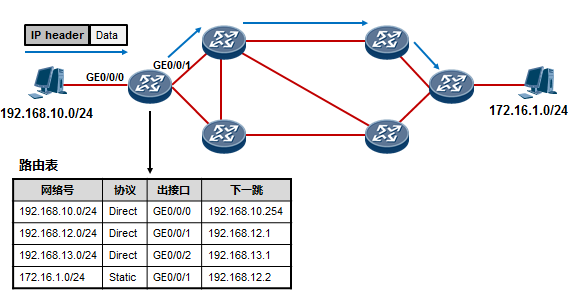
IP路由其实已经有不短的历史了,在IP发展的过程中,曾经出现过许多的争论,例如路由和交换速度之争, 路由和标签交换的地位之争等等。早先的通过软件实现的路由是“很慢的”,是“耗时、耗设备资源的”, 加之查表的机制、相关数据字段的重写使得其速度更加缓慢,而对于交换技术,由于对数据帧的读取“较浅”,加上本身的机制、通过专用的硬件实现使得其速度有很大程度的提升。
为了加快网络的对数据的转发速度,以及提高网络的可服务性和对多样化业务的支持,行业中一度涌现了许多新的技术,例如ATM、帧中继等等。其中有一个技术不得不提,那就是MPLS。虽然随着数据通信技术的飞速发展,IP路由的速度已经得到巨大的提升,控制和数据层面的机制都有了革命性的突破,使得速度上的劣势几乎消除,但是MPLS带来的革命性突破,和丰富的业务支持能力依然使得它在运营商网络中得到广泛的部署。
首先回顾一下IP路由的概念,什么是IP路由?可以简单的将路由理解为当三层设备(Layer3 Device)收到
一个IP数据包时,它拿着数据包的目的IP地址在自己的路由表中进行查找,如果找到相匹配的表项,则将数据包依照表项所指示的出接口和下一跳IP地址转发出去。
简单的一句话,包含的东西却是非常多的,实际上路由的动作从微观层面来探讨,可以拆解成复杂的过程, 例如当目的地址在路由表中查询时,默认采用“最长匹配原则”,逐位(Bit by Bit)地将目的IP地址与路由表中的各个路由前缀进行匹配,这显然是非常耗时的,再加上如果找到匹配项,而所匹配项的下一跳如果并非直连,则还要进一步递归;再如路由查找过程完成后,还需对数据包的IP头部进行修改(TTL值减一等), 并重写数据帧头部,而如果数据帧头部重写过程中缺少二层信息(如MAC),那么就还需要启动相关的协议或机制去查找(如ARP)。因此在某种程度上,IP路由一度被认为是速度缓慢的。
MPLS技术的发展,给行业带来了许多革新,也带来了许多应用和商机。初期最显著的亮点自然是在速度上快于IP路由,因为转发标签数据时仅需对标签进行查询。然而MPLS的亮点远不只是速度上的优势,随着IP 路由技术的发展,其速度上的短板已经得到极大的改进,但是这完全无法阻挡MPLS的广泛部署和应用。
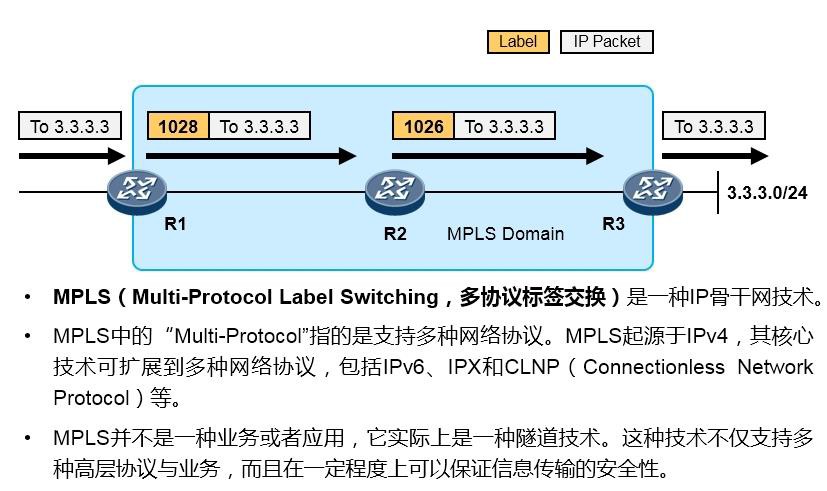
简单的说,MPLS的思想就是在IP报文的基础上,增加“标签头部”,这个标签头部可以视为是2.5层的概念, 也就是说标签头部是压在IP头之前、二层帧头之后的。压了MPLS标签头的数据称为标签报文(Labeled
Packet),标签报文在MPLS网络中被转发时,转发设备只需查看标签头中的标签值,即可快速的做出决策并将报文转发出去,因此速度很快。再者由于加了一层标签,这使得IP报文能够被“隐藏”在标签头后面, 这就可以解决诸多问题,例如BGP路由黑洞的问题等,当然更加带来了诸多新的业务,例如VPN业务,流量工程应用等等。
MPLS 术语¶
LSR¶
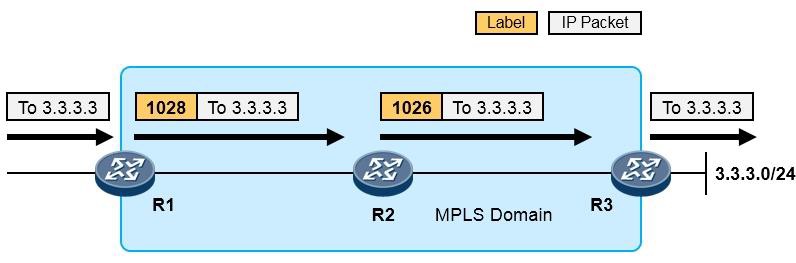
LSR(Label Switch Router,标签交换路由器)是支持并激活MPLS的路由器。LSR能够理解MPLS标签并且能够对MPLS标签包进行交换。有三种类型的LSR:
- Ingress LSR:或者叫入站LSR。如上图所示,R1、R2、R3构建了MPLS域,其中R1及R3身处MPLS 域边界,它们一侧连接着MPLS网络,另一侧连接着IP网络。当我们考虑IP数据包从R1左侧的IP网络到达R1,然后被R1转发到MPLS网络时,我们称R1为“入站LSR”,它此刻负责将收到的IP报文压上MPLS标签,然后转发到MPLS网络。
- Intermediate LSR:R2就是一台Intermediate LSR(也叫transit LSR),它没有连接任何的IP网络, 而是完全身处MPLS网络,只负责标签数据交换。
- Egress LSR:出站LSR,例如上图所示的R3,对于从左向右的数据流来说,它们被R1压上MPLS 标签后,被R2转发给了R3,现在这些数据要从MPLS网络转发到IP网络,R3负责将这些数据的标签栈移除,再将得到的IP报文转发到目的地3.3.3.0.24。
FEC¶
FEC(Forwarding Equivalence Class,转发等价类),是在转发过程中,具有相同处理方式和处理待遇的数据流,可通过地址、隧道、CoS等方式来标识,通常在一台设备上,对于一个FEC分配相同的标签。属于一个FEC的流量具有相同的转发方式、转发路径和转发待遇。但是并不是所有拥有相同标签的报文都属于一个FEC,因为这些报文的EXP值可能不相同,执行方式可能不同,因此它们可能属于不同的FEC。决定报文属于哪一个FEC的路由器是入站LSR,因为是它对报文进行分类和压入标签。
下面是一些FEC的范例:
- 目的IP地址匹配同一个特定前缀的报文;
- 属于某个特定组播组的组播报文;
-
根据进程或者IP DSCP字段有相同处理方式的报文。
注:一条FEC可以包含多个流,但不是一个流一个FEC,比如一台主机在看新浪的网页,这是一个流,又在看新浪的视
LSP¶
LSP(Label Switched Path,标签交换路径),标签报文穿越MPLS网络到达目的地所走的路径。MPLS 网络通过标签分配协议自行进行标签的分配和学习,为流量建立一条标签转发的通道。LSP是单向的。实际上,LSP是报文在穿越MPLS网络或者部分MPLS网络时的路径。为了满足通信节点之间的双向通信,我们往往需要建立双向的LSP。
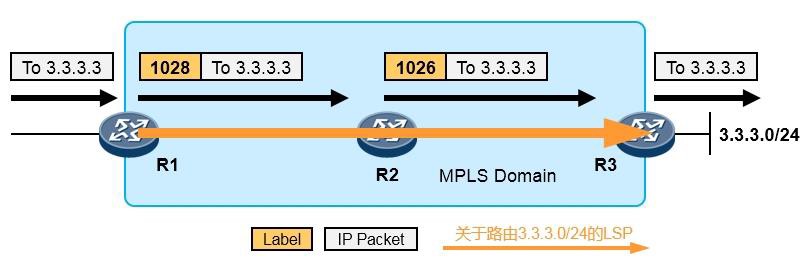
LSP分为静态LSP和动态LSP两种。静态LSP由管理员手工配置,动态LSP则利用路由协议和标签发布协议动态建立。
静态LSP是用户通过手工为各个转发等价类分配标签而建立的。手工分配标签需要遵循的原则是:上游LSR 出标签的值就是下游LSR入标签的值。
由于静态LSP沿途的各LSR不能相互感知到整个LSP的情况,因此静态LSP是一个本地的概念。
静态LSP不使用标签发布协议,不需要交互控制报文,因此消耗资源比较小,适用于拓扑结构简单并且稳定的小型网络。但通过静态方式分配标签建立的LSP不能根据网络拓扑变化动态调整,需要管理员干预。
MPLS 标签¶
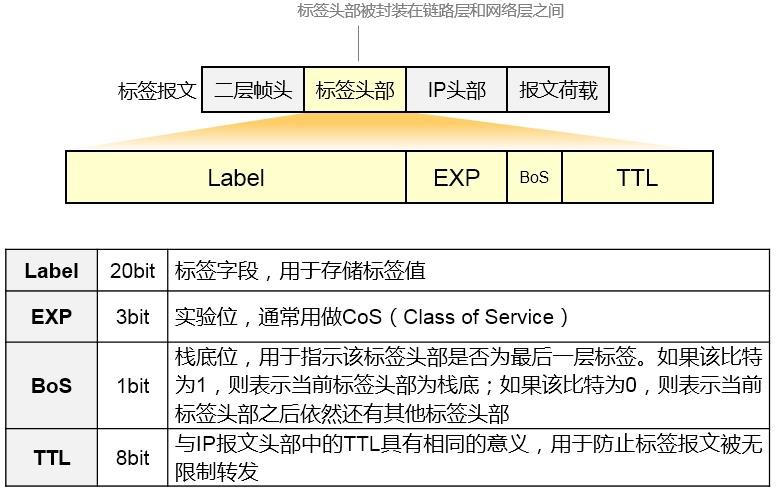
一个IP数据包如果要进入MPLS网络,会被LSR压入标签栈,一个标签栈中可能包含一层标签,也可能包含多层标签。标签头部的字段格式如上图所示。以下展示的是一个携带多个标签头部的标签报文:
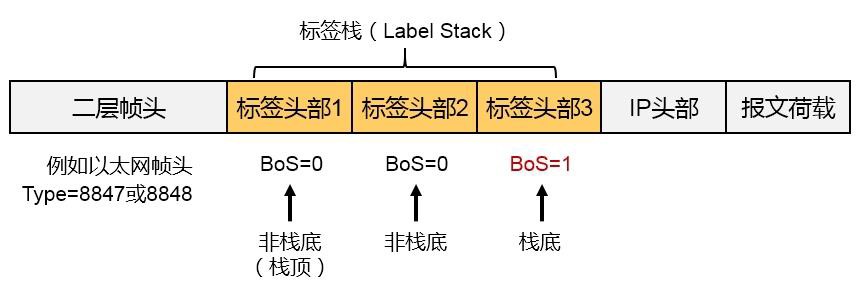
一个IP数据包可以被压入一层MPLS标签,也可以是多层标签。例如上图所示的IP数据包,就被压入了三层标签。在每层标签头部中都有一个BoS位来标识本标签头部是否是标签栈的栈低(每个标签头部都拥有完整的四个字段),如果本标签头已经是栈底,也就是最后一层标签,或者说后面就是IP头部了,那么该层标签头部的BoS比特值被设置为1,否则设置为0。
MPLS 标签操作¶
标签的操作类型包括标签压入(Push,或Insert)、标签交换(Swap)和标签弹出(Pop),它们是标签转发的基本动作,是标签转发信息表的组成部分。
- Push:指当IP报文进入MPLS域时,MPLS边界设备在报文二层头部和IP头部之间插入一个新标签;或者MPLS中间设备根据需要,在标签栈顶增加一个新的标签(即标签嵌套封装)。
- Swap:当报文在MPLS域内转发时,根据标签转发表,用下一跳分配的标签,替换MPLS报文的栈顶标签。
-
Pop:当报文离开MPLS域时,将MPLS报文的标签去掉。
在最后一跳LSR,标签已经没有使用价值。这种情况下,可以利用倒数第二跳弹出特性PHP(Penultimate Hop Popping),在倒数第二跳LSR处将标签弹出,减少最后一跳的负担。最后一跳LSR直接进行IP转发或者下一层标签转发。
PHP在Egress LSR上配置。支持PHP的Egress LSR分配给倒数第二跳LSR的标签值为3。
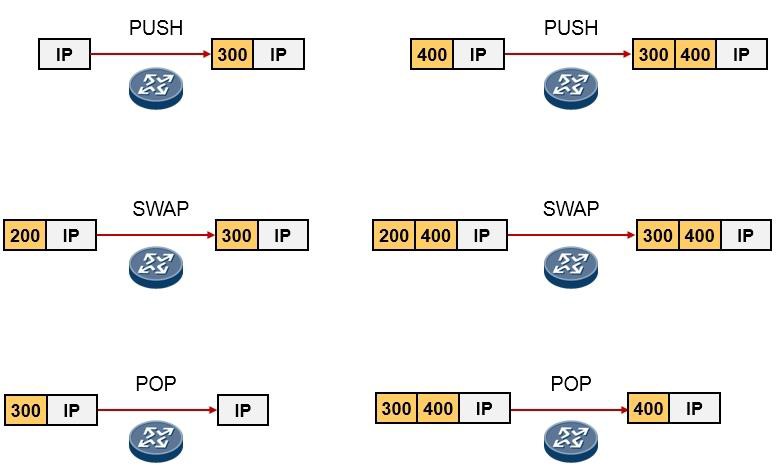
下面是一个小例子:
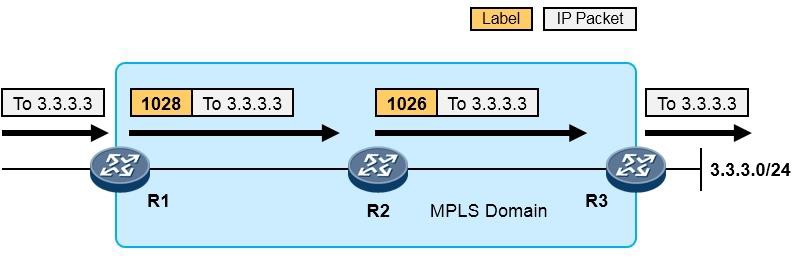
例如上图所示,R1在收到一个IP数据包之后,经过FIB表(转发信息表)查询,它发现去往3.3.3.0/24的下一跳是R2,并且报文需要压入一层标签,标签值为1028。因此R1将IP数据包压入一层标签然后转发给R2。
R2收到这个携带了标签的标签包,它取出标签值并在自己的标签转发表里进行查询,发现入站标签1028对应出站标签1026,且下一跳为R3,因此它将报文的标签置换(SWAP)成1026并转发给R3。同样的,R3收到这个标签报文后,在其标签转发表里查询入站标签1026,结果发现入站标签1026对应的出站动作是3(标签值3是一个特殊的、被保留的标签值,当出站标签为3时,意味着要弹出标签头),因此将标签头弹出,这就得到了原始的IP报文,最后R3将这个IP数据包转发出去。
LSP的入口LSR被称为Ingress LSR(入站LSR)。位于LSP中间的LSR被称为中间LSR(Transit LSR)。
LSP的出口LSR被称为Egress LSR(出站LSR)。Ingress LSR及Egress LSR都是LER。在上图中,对于去往3.3.3.0/24的数据流量而言,R1是Ingress LSR,R2是Transit LSR,R3是Egress LSR。一条LSP可以有
0个、1个或多个Transit LSR ,但有且只有一个Ingress LSR和一个Egress LSR 。
值得一提的是在本例中,R1是Ingress LER,也及是入站的边界标签交换路由器,它左侧连接着IP网络,而右侧连接着MPLS网络。当R1收到一个IP数据包时,它会怎么处理?它会在FIB表中查找该IP报文的目的IP 地址,如果有匹配的表项并且该表项所指示的下一跳是一个IP设备而不是LSR,那么这个报文会被直接路由。但是如果FIB中的表项指示下一跳是一台LSR并且需要压入标签,情况就不同了,R1会给IP报文压入标签, 然后再把这个标签包转发出去,这个时候,IP数据包就通过R1进入了MPLS网络。一旦以标签包的形态进入
MPLS网络,在转发的过程中所有LSR(除了出站LSR)就只看数据包的标签头,对其进行查找及交换,而不会去理会标签头里头的IP头部。而至于给这个报文压入的标签值是多少,标签值是怎么确定的,请继续看下文。
MPLS 转发过程详解¶
首先,我们要掌握一些基本概念:
NHLFE(Next Hop Label Forwarding Entry,下一跳标签转发表项)用于指导MPLS报文的转发。¶
NHLFE包括:Tunnel ID、出接口、下一跳、出标签、标签操作类型等信息。
FTN (FEC-to-NHLFE, FEC到一组NHLFE的映射)¶
通过查看FIB表中Tunnel ID值不为0x0的表项,能够获得FTN的详细信息。FTN只在Ingress存在。
ILM (Incoming Label Map,入标签到一组下一跳标签转发表项的映射)¶
ILM包括:Tunnel ID、入标签、入接口、标签操作类型等信息。
ILM在Transit LSR的作用是将标签和NHLFE绑定。通过标签索引ILM表,就相当于使用目的IP地址查询
FIB,能够得到所有的标签转发信息。
Tunnel ID¶
为了给使用隧道的上层应用(如VPN、路由管理)提供统一的接口,系统自动为隧道分配了一个ID,也称为Tunnel ID。该Tunnel ID的长度为32比特,只是本地有效。
在报文的转发过程中:
- 在Ingress LSR,通过查询FIB表和NHLFE表指导报文的转发。
-
当IP报文进入MPLS域时,首先查看FIB表,检查目的IP地址对应的Tunnel ID值是否为0x0。如果Tunnel
ID值为0x0,则进入正常的IP转发流程。如果Tunnel ID值不为0x0,则进入MPLS转发流程。
-
在Transit LSR,通过查询ILM表和NHLFE表指导MPLS报文的转发。
- 在Egress LSR,通过查询ILM表指导MPLS报文的转发或查询路由表指导IP报文转发。
Ingress LSR的处理:¶
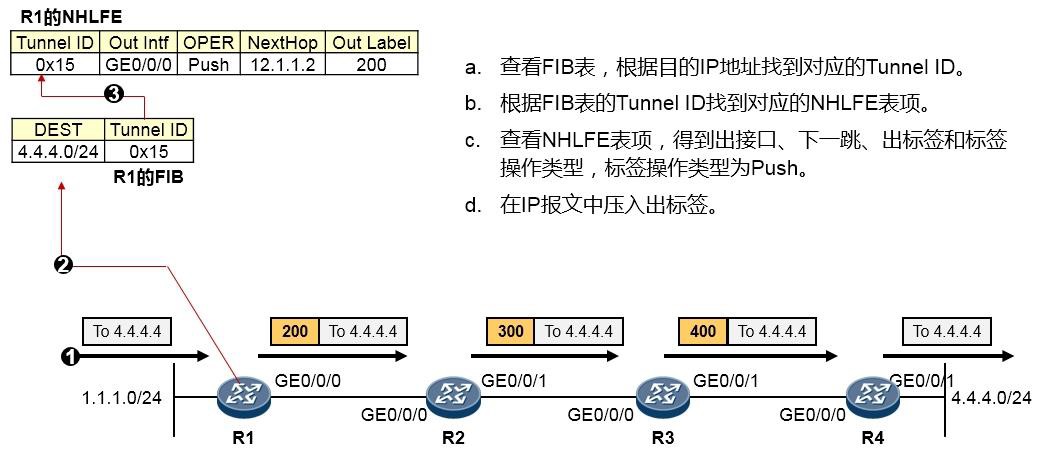
Transit LSR的处理:¶
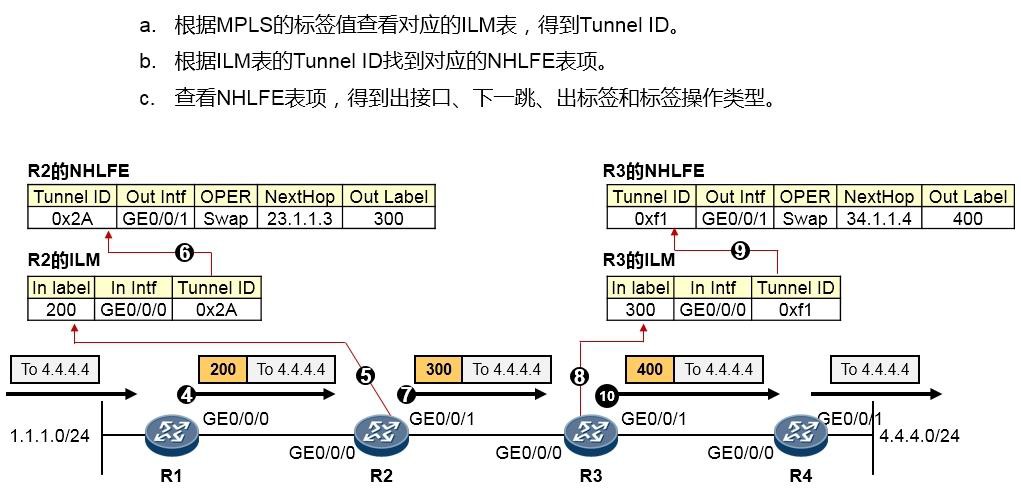
Egress LSR的处理:¶
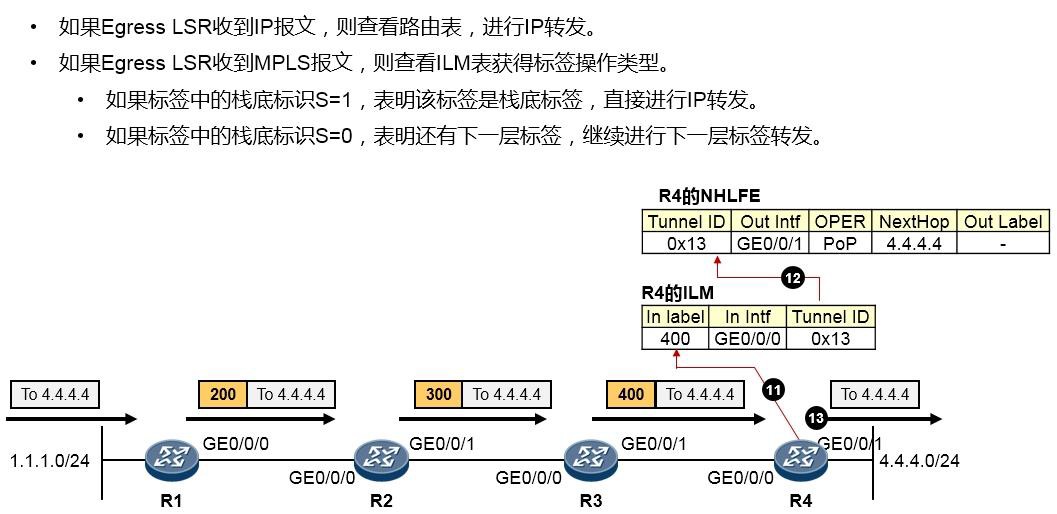
小结:¶
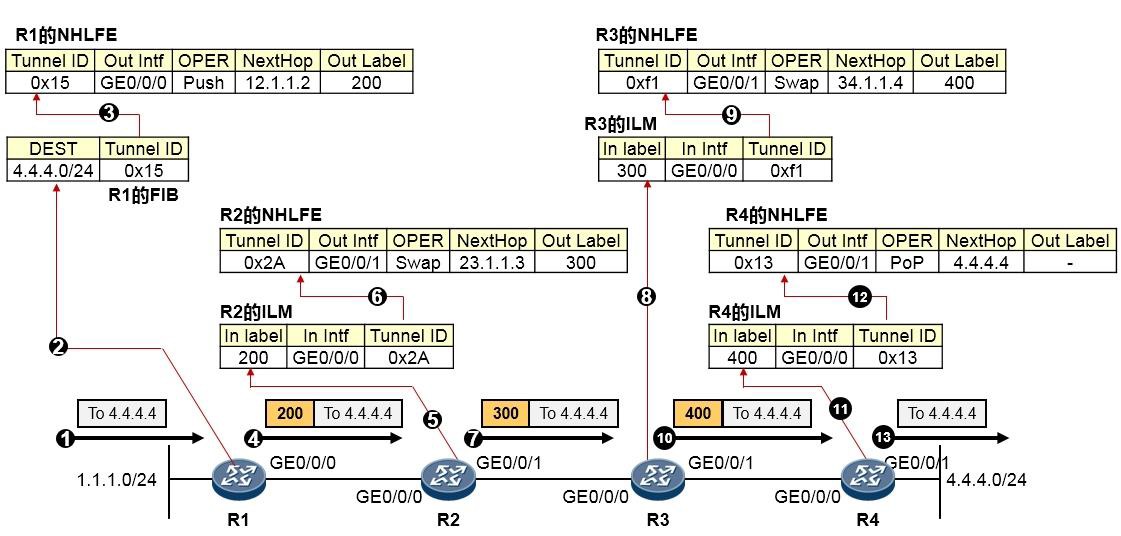
- LDP
LDP 概述¶
标签报文在MPLS网络沿着标签交换路径转发的过程中,中间LSR都只是查看数据的标签值,并且针对该标签进行查询、置换等操作。那么入站LSR究竟该为IP数据包压什么标签呢?标签交换路径是怎样的?如何确保这个IP数据包能够顺利的穿越MPLS网络?这些都是控制层面的问题,肯定是需要协议来解决的,而且应该在IP数据包到达之前就把所有的事情准备好。
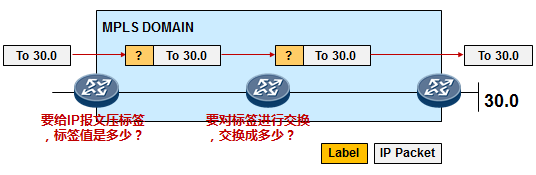
所有我们需要一个协议,这个协议能够帮助我们为特定的流量建立LSP,能够为FEC(例如特定的路由前缀)分配标签,并且将标签映射传递(或者说分发)给其他的标签交换路由器。
如果让OSPF、ISIS这样的协议来分发标签是不可能的了(至少在未对协议做扩展之前是不可能的)。那么就需要一个新的协议,独立于所有的路由协议并且能够结合路由协议一起使用,这个协议能够为特定的FEC 捆绑标签,并且将标签分发给其他的LSR。LDP(Label Distribution Protocol标签分发协议)就是一个这样的协议。
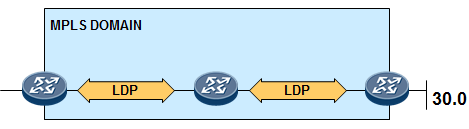
每一台运行LDP的LSR都会为自己路由表中的路由前缀捆绑标签,然后再将所分配的标签分发给所有的LSR 邻居。LDP邻居将这些接收到的标签视为出站标签Outgoing label(或者远端标签),之后邻居将该出站标签和其自己本地的标签存储于一张特殊的表中。通常一台LDP路由器会有多个LDP邻居,那么这些邻居都会给路由分配标签然后将这些标签传给自己。
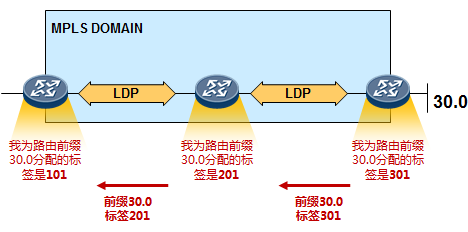
一台LSR有可能会收到多个LDP邻居分发的标签,可能对于同一个FEC,会同时收到多个邻居分发的标签, 通常路由器只使用其中一个标签作为该前缀的出站标签。它通过RIB也就是IP路由表得到该IPv4前缀的下一跳,它将使用这个下一跳LSR所分发的标签作为最终的出站标签。

在LDP完成工作后,一条LSP就建立起来了。
LDP ID¶
LDP-ID是长度为6Byte的LDP标识符,包含4Byte的LSR-ID及2Byte的标签空间值,例如192.168.255.1:0。
其中4Byte的LSR-ID为系统视图命令mpls lsr-id所指定的标识符,也就是LSR的标识符 (在对设备做MPLS 配置之前,需要首先在系统视图下指定LSR-ID,LSR-ID与IPv4地址的格式相同,例如192.168.255.1)。
标签空间值一般为0,表示标签是基于设备或者说是基于平台的(Per-Platform);如果是非0,就说明用的是基于接口的标签空间。
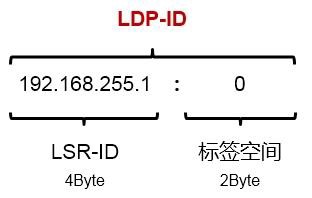
标签空间¶
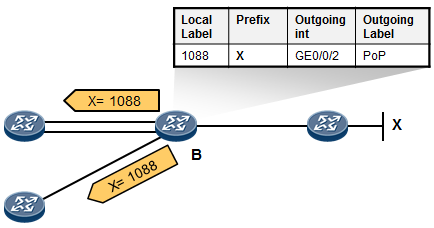
默认的LDP标签空间是基于设备或者说基于平台的(per-platform)。什么意思呢,看上图中的B路由器,它为前缀X捆绑了标签1088,并且将这个标签捆绑信息发布给所有的LDP邻居,给大家的都一样而且人人有份,都是标签1088。这就是基于平台的意思。除此之外还有基于接口的标签空间。
- Label Space ID一般为0,表示我们的标签是基于平台(Per-platform)的标签空间。
- 为前缀分配的标签在本地任意MPLS接口可用并且会分发给所有LSR邻居。
- 本地分配的标签会分发给邻居,如果与单个邻居有多条连接,则该标签在所有连接上均有效。那么不管
本地从哪个接口上收到一个标签包,只要有这个标签,都会对其进行交换。
传输地址¶
- 两台LSR之间在建立LDP会话之前,需要先建立TCP连接,以便进行LDP协议报文的交换。
- 互为邻居的LSR需基于双方的传输地址(Transport Address)建立TCP连接。
- 在LDP Hello报文中,包含设备的传输地址,LSR通过Hello报文知晓邻居的传输地址。
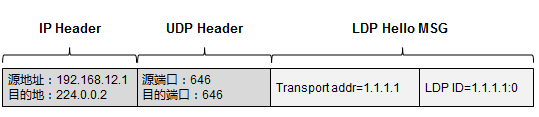
- 在使用Hello报文发现邻居并且知道了对方的传输地址后,邻居之间就会开始尝试TCP三次握手(基于传输地址),并且交互LDP的初始化报文、标签映射报文等,这些报文都使用双方的传输地址作为源、目的IP地址。
- 传输地址会被用来与邻居建立TCP连接,因此LSR必须拥有到达邻居的传输地址的路由。
- 缺省情况下,公网的LDP传输地址等于设备的LSR-ID,私网的传输地址等于接口的主IP地址。
- 在接口视图下,使用mpls ldp transport-address命令,可以修改传输地址。
LDP 的基本工作过程¶
Step1:¶
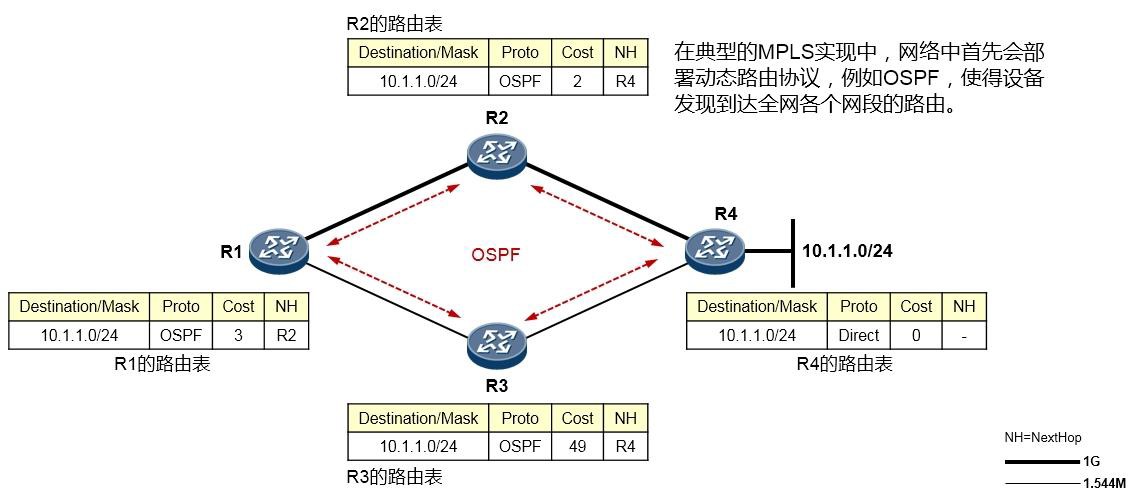
Step2:¶
Step3:¶
Step4:¶
Step5:¶
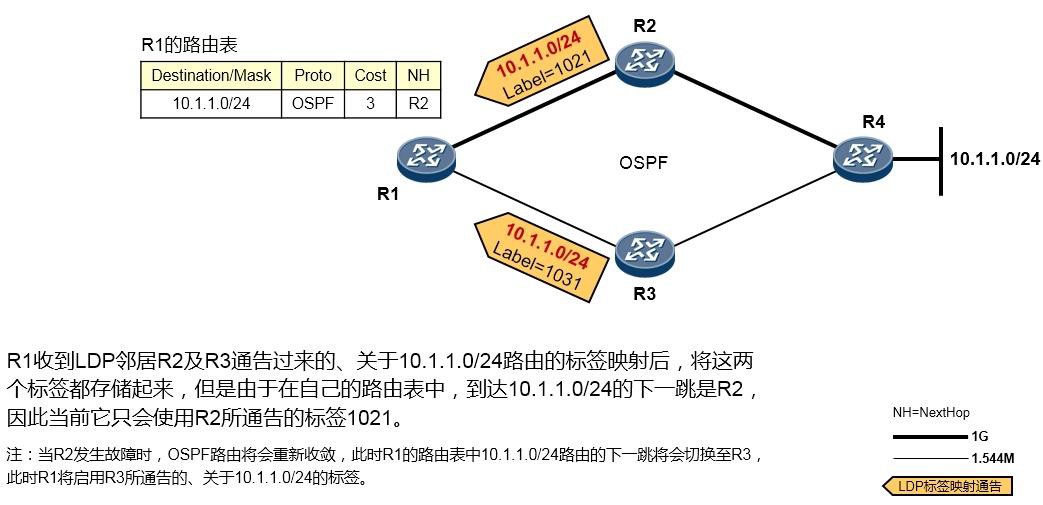
Step6:¶
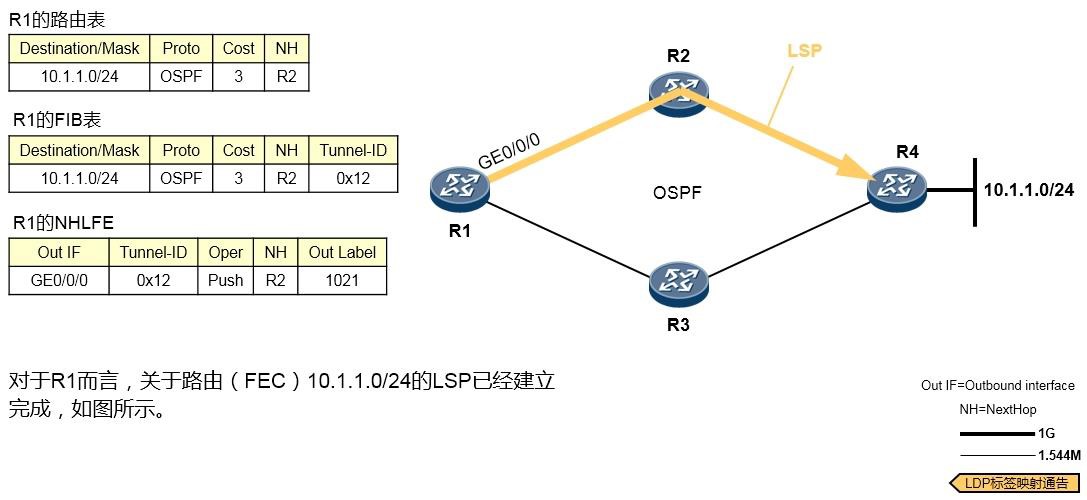
Step7:¶
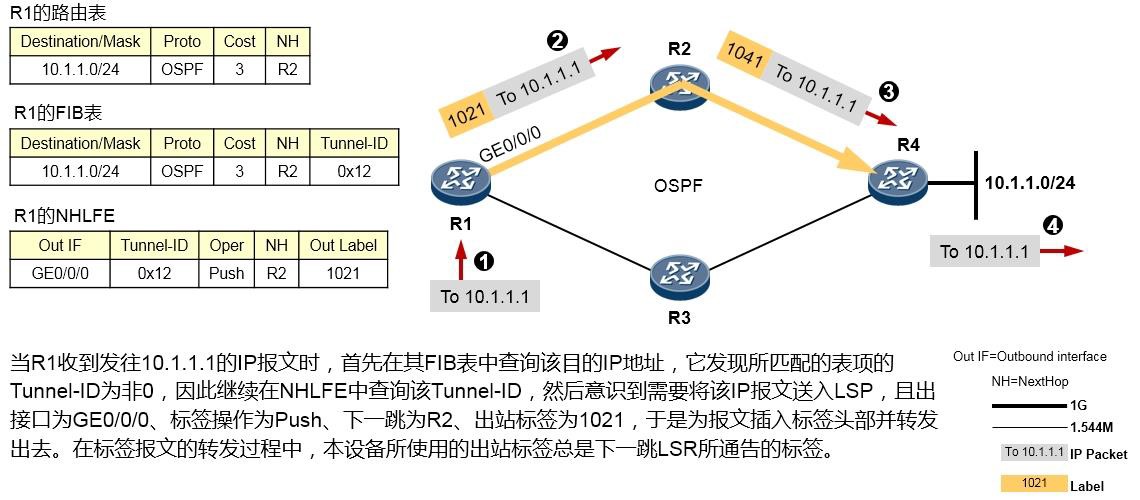
在MPLS中,运行LDP协议的LSR的操作小结:¶
- LSR首先通过运行IGP协议(例如OSPF、IS-IS等)来构建路由表、FIB表;
- LDP根据相应的模式,为路由表中的路由前缀(FEC)分配标签;
- LDP根据相应的模式,将自己为路由前缀分配的标签,通过LDP标签映射报文通告给LDP邻居;
- LSR将自己为路由前缀分配的标签,以及LDP邻居为该路由前缀通告的标签存储起来,并形成关联;
- 当LSR转发到达目的网络的标签报文时,所使用的出站标签总是下游LDP邻居所通告的标签,此处所指的下游邻居,是设备的路由表中到达该目的网络的下一跳设备。
PHP¶
PHP(Penultimate Hop Poppoing,次末跳弹出或者倒数第二跳弹出),这是MPLS的一个基础性机制。下面,来看一个简单的例子:
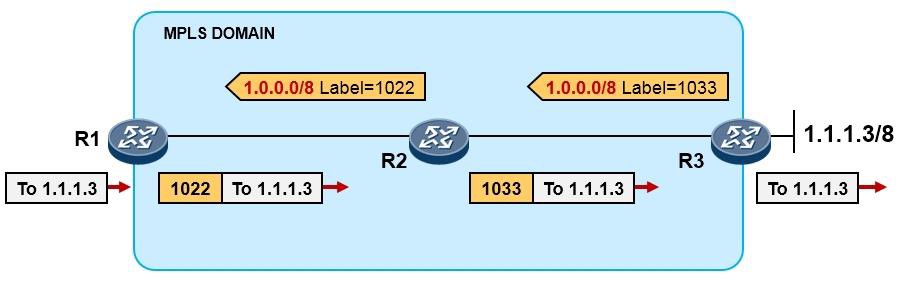
在上图中,R3收到发往1.0.0.0/8的标签报文后,需首先在ILM中查询标签值,然后根据指示将标签头部弹出,再到FIB表中查询IP报文的目的IP地址,最后将IP报文转发出去。也就是说,R3需要执行两次查询操作。实际上,对于这个过程来说,是存在优化空间的。
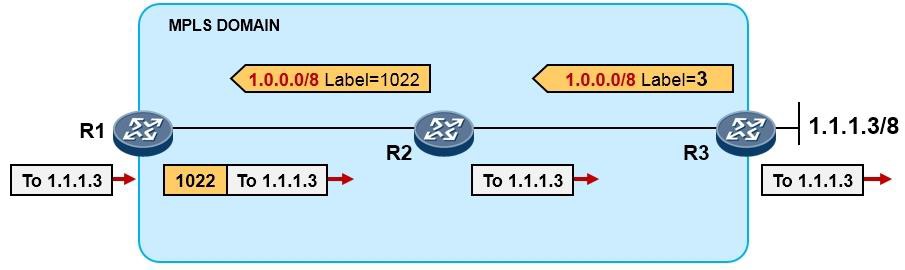
R3如果激活了PHP特性,那么当它为本地直连路由1.0.0.0/8分配标签时,会分配一个特殊的标签,该标签被称为隐式空标签(Implicit NULL Label),其值为3。R3将该标签值通告给R2。当LSR转发一个标签报文时,如果发现相应的入站标签对应的出站标签值为3,那么该LSR将把报文的标签头部弹出,然后将里面所封装的数据转发给下游LSR,也就是执行PHP( Penultimate hop popping,次末跳弹出)操作。
R2作为到达1.0.0.0/8的次末跳(倒数第二跳),收到发往1.1.1.3的标签报文后,发现出站标签值为3,于是将标签头部弹出,将IP报文转发给R3,而R3则仅需执行一次查询操作(查询FIB表)即可获得相应的转发信息,转发效率得到了提升。
LDP在帧模式Frame Mode下(现在基本都用帧模式了),LSR会为本地路由捆绑标签值3,3是一个LDP保留的标签,叫做“impilict null隐式空”标签。
倒数第二跳弹出机制(PHP)有两种标签,一是implicit nul(l 隐式空),在LDP中标签值为3;另一个是explicit
null(显式空),在LDP中标签值为0。如果收到LDP邻居发送来的关于某条路由分配的标签值为3,则我发送前往该目标网段的数据给该邻居时,我会将该标签弹出,再将内层数据转给邻居。而如果邻居关于某条路由分配的标签值为0,那么本地在转数据给邻居时,会带上标签头(标签值为0的),一并发给邻居。
在MPLS视图下,使用“label advertise explicit-null”命令,可以让设备向倒数第二跳分配显式空标签; “label advertise implicit-null”命令(默认即开启)则会使得设备向倒数第二跳分配隐式空标签。“label advertise non-null”命令则相当于关闭PHP机制,使得设备正常分配标签而不使用空标签。
- MPLS 的基础配置
基础命令¶
配置设备的LSR ID¶
[Huawei] mpls lsr-id x.x.x.x
配置LSR ID是进行所有MPLS配置的前提,LSR没有缺省的LSR ID,必须手工配置。
全局激活MPLS¶
[Huawei] mpls
全局激活LDP¶
[Huawei] mpls ldp
在接口上激活MPLS¶
[Huawei-GigabitEthernet2/0/0] mpls
在接口上激活LDP¶
[Huawei-GigabitEthernet2/0/0] mpls ldp
(可选)配置设备的LDP传输地址Transport Address¶
[Huawei-GigabitEthernet2/0/0] mpls ldp transport-address intf.
缺省情况下,公网的LDP传输地址等于节点的LSR ID,私网的传输地址等于接口的主IP地址。
(可选)配置LSP建立的触发策略¶
[Huawei-mpls] lsp-trigger { all | host | ip-prefix ip-prefix-name | none } 缺省情况下,触发策略为host,即32位地址的主机IP路由(不包括接口的32位地址的主机IP路由)触发 建立LSP。如果触发策略为all,则所有静态路由和IGP路由触发建立LSP。BGP公网路由不能触发建立
LSP。如果触发策略为ip-prefix,则只有通过IP地址前缀列表过滤的FEC项能够触发建立LSP。如果触发策略为none,则不触发建立LSP
基础实验¶
-
设备互联地址如图所示;所有设备开设Loopback0口,该接口IP地址为x.x.x.x/32,其中x为设备编号。
Loopback0的IP地址作为OSPF RouterID以及LSR ID、LDP传输地址。
-
R1、R2、R3、R4运行OSPF,通告直连接口及Loopback0。
- 所有设备激活MPLS,基于直连建立LDP邻居,观察标签的分发情况。
-
观察1.1.1.1访问4.4.4.4数据包,分析数据包穿越MPLS网络的过程。
R1的配置如下:
R2的配置如下:
R3的配置如下:
R4的配置如下:
完成上述配置后,我们来做一些查看和验证:
以上输出的是R1的LDP邻居表,从表中可以看出R1已经发现了一个LDP邻居,那就是R2。
以上输出的是LDP会话的详细信息,邻居的状态必须为Operational才是最终的稳态,另外从TCP连接1.1.1.1
\< 2.2.2.2可以验证一点,LDP的会话建立是由传输地址大的一方发起的。
以上输出的是R1的标签转发库,可以看到已经建立好的LSP。
实际上,当我们再R1、R2、R3、R4上运行OSPF后,全网的路由已经被打通,也就是每台路由器都拥有全网的路由,其中包括互联网段的路由,以及各设备的Loopback路由。随后我们激活各设备的MPLS和LDP, 每台设备会基于自己的路由表中的路由前缀进行标签捆绑,并且将为路由前缀(FEC)所捆绑的标签分发给自己的LDP邻居。默认情况下在我司的设备上,仅为/32的主机路由分发标签。
现在,来测试一下,从R1去tracert 4.4.4.4:
从tracert的结果我们可以看到数据包行走的路径,以及被压入的标签。
报文的转发过程实际上类似下面这样(读者在实验过程中,可能会发现实际的标签值与本文档的不相同,这是正常的):

- MPLS VPN
本文档描述的MPLS VPN是三层的BGP/MPLS IP VPN。
BGP/MPLS IP VPN是一种L3VPN(Layer 3 Virtual Private Network)。它使用BGP在服务提供商骨干网上发布VPN路由,使用MPLS在服务提供商骨干网上转发VPN报文。这里的IP是指VPN承载的是IP报文。
BGP/MPLS IP VPN基于对等体模型,这种模型使得服务提供商和用户可以交换路由,服务提供商转发用户站点间的数据而不需要用户的参与。相比较传统的VPN,BGP/MPLS IP VPN更容易扩展和管理。新增一个站点时,只需要修改提供该站点业务的边缘节点的配置。
BGP/MPLS IP VPN支持地址空间重叠、支持重叠VPN、组网方式灵活、可扩展性好,并能够方便地支持MPLS QoS和MPLS TE,成为在IP网络运营商提供增值业务的重要手段,因此得到越来越多的应用。
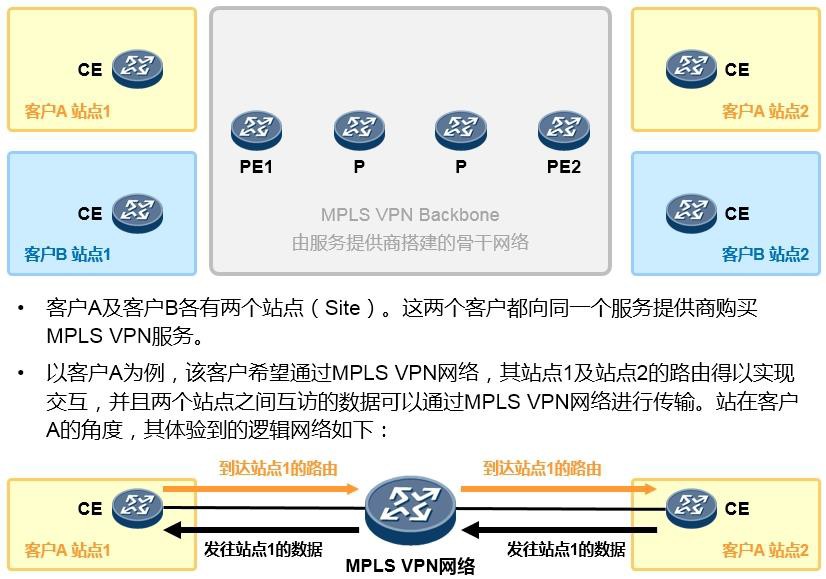
MPLS VPN 的架构¶
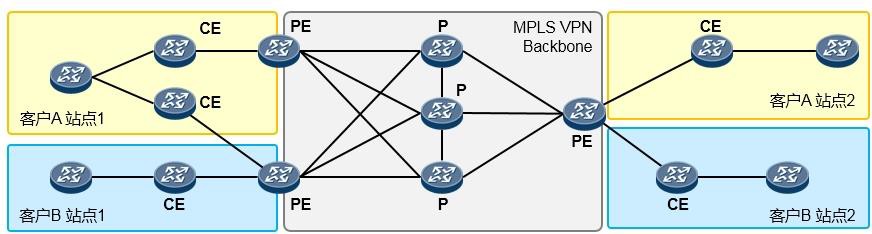
- **CE(Customer Edge):**客户网络边缘设备,该设备属于客户,它除了连接着客户网络,还有接口直接与MPLS VPN网络相连。CE设备可以是路由器或交换机,也可以是一台主机。通常情况下,CE“感知”不到VPN的存在,也不需要支持MPLS。
- **PE(Provider Edge):**是服务提供商网络的边缘设备,与CE直接相连。在MPLS网络中,对VPN的所有处理都发生在PE上,对PE性能要求较高。
- **P(Provider):**服务提供商网络中的骨干设备,不与CE直接相连。P设备只需要具备基本MPLS转发能力,不维护VPN信息,也不维护客户VPN路由。
MPLS VPN 初体验¶

在上图所示的网络中,中间是运营商搭建的“MPLS VPN Backbone”也就是MPLS VPN骨干网络,这个网络面向客户提供VPN业务,使得不同的客户的路由、数据都能够通过这个公共的网络进行传输,而且互相不干扰。客户之间的路由及数据是完全隔离的,即使他们通过同一张运营商的网络进行承载。现在我们来看看MPLS VPN究竟是怎么一回事。
上图中,我们拿了两个客户做示例:客户A及客户B,他们各自有两个站点。现在要求客户A的两个站点之间能够互通,客户B的两个站点之间能够互通,而客户A、B之间是完全隔离的。再者,同一个客户的两站点之间,要能够动态的交互路由信息,也就是说客户A的站点1的CE路由器要能够动态的学习到站点2内的路由。

首先客户A站点1的CE路由器及客户B站点1的CE路由器与PE路由器均运行路由协议(也就是PE-CE之间的路由协议),例如BGP或者OSPF,或者干脆静态路由都行,这么做的目的是把本地站点的路由交给PE1, 然后让PE1帮忙传递给PE2,再由PE2交给客户A站点2的CE路由器,从而将路由打通。
现在第一个问题来了。PE路由器如何区分不同客户的路由呢?而且从图中我们可以看出,客户A的站点1及客户B的站点1地址空间是重叠的,都是10.1.1.0/24,PE是如何区分的?
这就要提到MPLS VPN的一个组件:VRF(VPN Routing & Forwarding Instance),虚拟路由及转发实例, 在我司的平台上是VPN-Instance。所谓的VPN实例,我们可以简单的理解为是“一台虚拟路由器”,通过在PE1上创建两个VPN实例,用于分别面向客户1及客户2提供服务。在PE1创建的这两个VPN实例相当于两
台虚拟路由器,它们各自有完全独立的路由表、转发表、路由协议进程、接口、等等,由于是完全独立的两台“虚拟路由器”,因此即使从两个不同的客户学习到同一个网段的路由也不用担心冲突的问题。
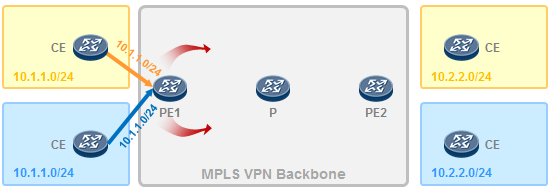
现在PE1上创建了两个VPN实例,用于分别和客户1及客户2交互VPN路由(客户的路由),那么为了将路由传递到PE2我们要考虑几个问题:
1、 用什么路由协议来“搬运”这些客户的VPN路由(将它们从PE1搬运到PE2)?PE肯定是面向大量客户的,因此路由前缀的数量肯定非常庞大。
2、 MPLS VPN Backbone的P路由器主要的功能是高速地转发数据,如果要它们也一起维护客户的路由肯定会增加负担,如何规避这个问题?
你可能已经想到,有一个协议能够胜任这个工作,那就是BGP,BGP能够承载大量的路由前缀,是一个在骨干网络中被广泛使用的路由协议,而且它具有丰富的路径属性和路由策略工具,使得网络的部署变得非常灵活和弹性。另外,BGP还有一个非常突出的优势,那就是它是基于TCP工作的,它不用像OSPF那样要求邻居必须直连,因此我们可以在PE1及PE2之间来建立iBGP的邻居关系,这样客户的路由就可以直接通过BGP传递,而P路由器则无需运行BGP,也无需维护客户的路由。
当然为了让PE1及PE2能够建立起iBGP邻居关系,我们要打通MPLS Backbone内的路由(注意,只是骨干网内部,不包含任何客户的路由),因此我们需要在Backbone内的PE及P路由器上运行一个IGP,例如OSPF 或者ISIS,使得骨干网络内部的路由能够打通,为后面的工作做铺垫。
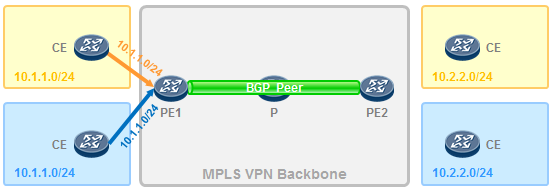
现在PE1及PE2之间有了BGP连接,PE1通过PE-CE间的路由协议所学习到的客户A及客户B的路由就能够
通过BGP传递给PE2(反之亦然),但是问题又来了,客户A的站点1及客户B的站点1使用重叠的地址空间, 都是10.1.1.0/24,PE1上虽然有VPN实例用于区分,但是现在要把这些路由通通传递给PE2,那么如何保证这些路由在MPLS VPN Backbone中传递时的唯一性呢?如何规避他们的重叠问题?很简单,我们为路由
10.1.1.0/24增加一个“前缀”,这个前缀称为RD(Route Distinguisher),RD值的长度为64bit,表现形式通常为类似123:11这样,也就是AS:NN的形式。
我们给PE上的每一个VPN实例均设置一个唯一的RD值,例如为客户1设置一个6812:1,为客户2设置一个
6812:2,然后当要把客户1的路由放进BGP搬运给PE2时,将IPv4的路由前缀10.1.1.0/24前面增加该VPN 的RD值,得到6812:1:10.1.1.0/24,这样就构成了一个64+32bit也就是96bit的新前缀,这个前缀我们称之为VPNv4前缀,客户B的站点1路由在BGP中传递时就变成了6812:2:10.1.1.0/24,如此则可解决地址重叠的问题,保证所有客户路由的唯一性。
传统的BGP只能够运载10.1.1.0/24这样的IPv4路由前缀,现在我们要让BGP运载6812:1:10.1.1.0/24这样的VPNv4前缀,就需要对BGP进行扩展了,扩展以后的BGP我们称之为MP-BGP,也就是Multi-Protocol BGP,翻译为多协议BGP,如下图所示:
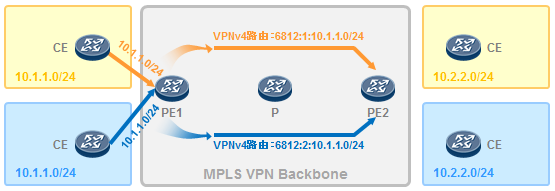
现在客户A及客户B的路由终于传递到了PE2上,接下去PE2就要把客户A站点1的路由传递给客户A站点2的
CE路由器、把客户B站点1的路由传递给客户B站点2的CE路由器。问题又来了,PE2如何知道该把哪条VPN 路由交给哪个客户的CE呢?显然在PE2上为了区分它自己所直连的不同客户,也需要创建VPN实例,但是从PE1收到的这么一大坨的路由前缀,哪些是要放进哪一个VPN实例的现在还是无从得知,因此我们需要一个新的标记来帮助PE,这就是RT(Route Target)值,如下图所示:
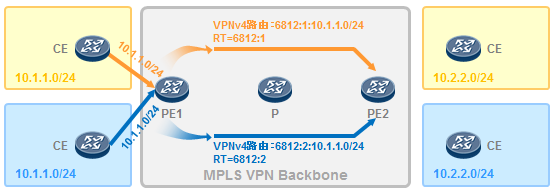
如上图所示,PE1在将客户A站点1的路由通过MP-BGP传递给PE2之前为路由打上“标记”,也就是RT值
6812:1,而为客户B站点1的路由打上标记6812:2,这些RT的标记实际上是“粘贴”着VPNv4前缀一块儿传给PE2的,其实它们是以BGP的扩展Community的形式来存储的。如此一来路由到了PE2后,PE2就能够根据RT值来将不同的路由导入到对应的本地VPN实例中。
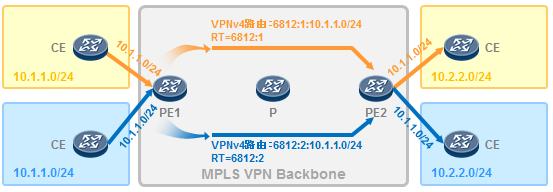
终于,路由千辛万苦被传递到了远端站点的CE路由器上。但是,事情还没有结束。设想一下,虽然客户A的站点2的CE路由器已经学习到站点1的10.1.1.0/24路由,现在它发送数据到站点1,这个IP数据包先是送到
PE2,PE2通过VPN路由表的查找找到匹配的条目来自BGP那么接下去呢?直接把IP数据包送出去么?肯定是有问题的,因为IP数据包如果直接送出去,P路由器接收了铁定就丢包了,因为它并没有运行BGP也没有VPN客户的路由,它只有MPLS Backbone内的路由,这就出现了路由黑洞。怎么办,得为这个IP数据包穿上一件马甲,这个马甲整个MPLS Backbone都能认识,而且能帮助我们把这穿了马甲的数据包从PE2送到PE1去,这就是MPLS标签。当PE2把来自VPN客户的IP数据包送到MPLS VPN Backbone之前,要为数据包压入一层标签:
这层标签显然是P路由器给分发的,为谁分发的? 为PE1路由器的Loopback路由分发的标签,而这个
Loopback地址,就是PE2上去往目标网段路由(客户A的站点1)的下一跳地址。PE2为数据包压入标签后, 送到P路由器,P路由器沿着建立好的LSP将标签包送到PE1路由器。当然,为了保证整个MPLS VPN
Backbone能够建立LSP,要在设备上都激活MPLS和LDP,这就是为什么我们称之为MPLS VPN。
但是,标签包是到了PE1,PE1该如何处理里头的数据呢?这个包是去往10.1.1.0/24网络的,而自己有两个
10.1.1.0/24网络直连啊,为了解决这个问题,我们就需要为数据包再压入一层标签:
PE2将IP数据包送上MPLS VPN Backbone之前,为数据包压入两层标签,其中外层标签,也就是标签1011 我们称之为IGP标签,它是由P路由器通过LDP协议分发的。而1233标签是内层标签,我们称之为VPN标签, 它是由PE1路由器通过MP-BGP分发给PE2的。
外层标签是为了将数据沿着LSP送到PE1,而内层标签是为了在数据到达PE1后,让PE1判断该数据包究竟是应该送到哪一个VPN,因为VPN标签是PE1分配的所以它肯定不会搞错。完美的解决方案。
数据包终于穿越了整个MPLS VPN网络,到达了站点1。这就是MPLS VPN。
VPN 实例¶
MPLS VPN一个非常吸引人的地方,就是可以让不同客户的路由及数据穿越运营商的MPLS VPN Backbone, 而且这些路由和数据又是相互隔离和独立的,即使不同的客户拥有相同的IPv4地址空间也不要紧。与客户的
CE路由器交互“VPN客户路由”的PE路由器,就显得非常重要了。
在PE上有个非常重要的概念—VRF(严格的说,VRF的作用现在已经扩展了,我们这里重点讨论在MPLS
VPN中的运用)。
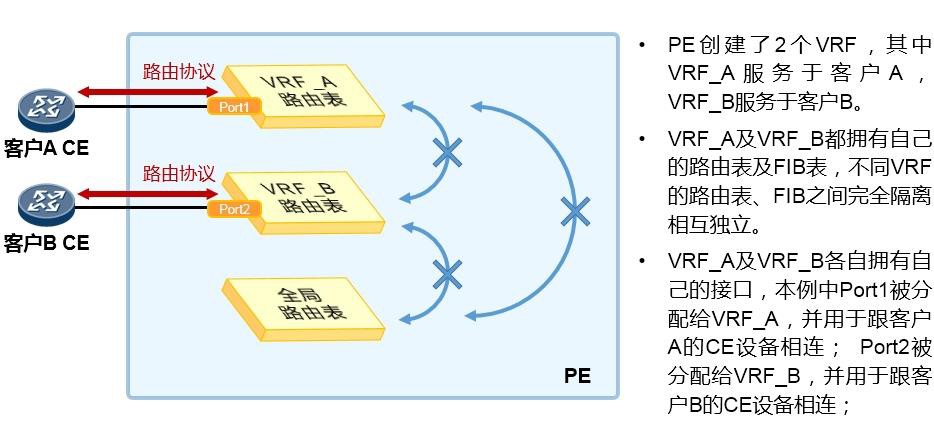
VRF:Virtual Routing and Forwarding,翻译成虚拟路由及转发(在我司的设备上也被称为VPN-Instance), 它是一种VPN路由和转发实例。一台PE路由器,由于可能同时连接了多个VPN用户,这些用户(的路由和数据)彼此之间需要相互隔离,这时候就用到了VRF。PE路由器上每一个VPN都有一个VRF。PE路由器除了维护全局IP路由表之外,还为每个VRF维护一张独立的IP路由表,这张路由表称为VRF路由表。要注意的是全局IP路由表以及每个VRF的路由表都是相互独立或者说相互隔离的。因为每一个VPN都有一张独立的
VRF路由表,所以PE路由器上每一个VPN也会有一张独立的FIB表来转发这些报文,这就是VRF FIB表。
一旦在PE路由器上创建了一个VPN的实例,我们就可以将特定的接口(物理或逻辑的)绑定到这个VPN实例,那么这个接口将不再属于全局IP路由表或其他任何VPN实例,只为该VPN服务。
RD¶
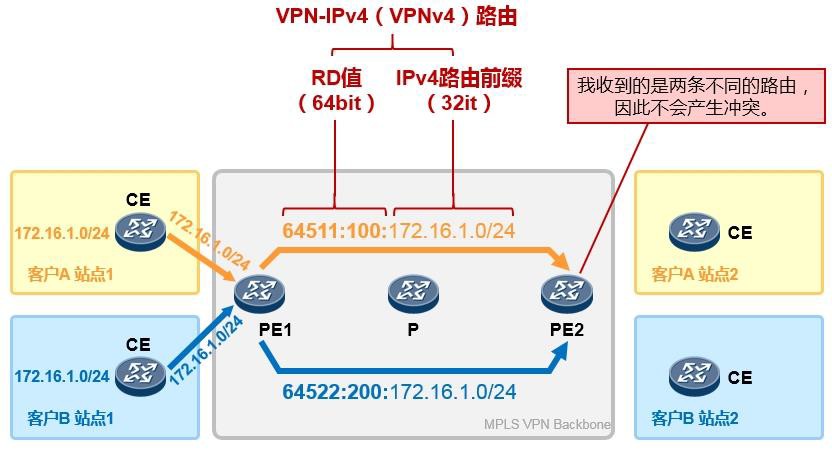
传统BGP无法正确处理地址空间重叠的VPN的路由。假设客户A和客户B都使用了1.1.1.0/24网段的地址,并各自发布了一条去往此网段的路由。虽然本端PE通过不同的VRF可以区分地址空间重叠的VPN的路由,但是这些路由发往对端PE后,对端PE将根据BGP选路规则只选择其中一条VPN路由,从而导致去往另一个
VPN的路由丢失。
PE之间使用MP-BGP(Multiprotocol Extensions for BGP-4,BGP-4的多协议扩展)来发布VPN路由,并使用VPN-IPv4地址来解决上述问题。VPN-IPv4地址共有96bit,包括64bit的RD(Route Distinguisher,路由标识符)和32bit的IPv4地址前缀。RD用于区分使用相同地址空间的IPv4前缀,增加了RD的IPv4地址称为VPN-IPv4地址(即VPNv4地址)。PE从CE接收到IPv4路由后,转换为全局唯一的VPNv4路由,然后将其通告给远端PE。RD值在VPN实例中进行配置。
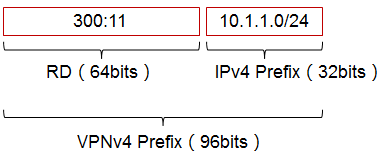
RD用于在MP-BGP运载VPN前缀时,确保这些前缀的唯一性。但是RD并不会说明该前缀属于哪一个VRF
(需要搭配RT),RD的功能并不是VPN标示符,因为在一些复杂的VPN环境中,可能一个VPN存在多个RD。
RD的最重要的两个功能:
- 与32bit的IPv4前缀一起构成96bit的VPNv4前缀;
-
如果不同的VPN客户存在相同的IPv4地址空间,那么可以通过设置不同的RD值从而保证前缀的唯一性。
RD可以有两种表现形式:AS:nn或者IP-address:nn。其中nn代表编号。最常用的格式是AS:nn,其中AS代表AS号。通常AS是IANA分配给服务提供商的AS号,nn是服务提供商分配给VRF的唯一号码。产生的VPNv4 前缀通过MP-BGP在PE路由器之间被传递。
RT¶
Route Targets(在我司的设备上也叫VPN-Target),RT值用于区分VPN实例、控制VPN路由的收发,它定义了一条VPNv4路由可以为哪些站点所接收,以及PE可以接收哪些站点发送来的路由。RT值其实是一种类似“路由标记”的东西,相当于我们给VPNv4路由打上标记了,然后再基于这些标记来决定哪些路由是要放入哪一个VPN实例的。
每个VRF关联一个或多个RT。有两类RT:
-
**Export RT:**PE从本地直连的站点学到IPv4客户路由后,将其转换为VPNv4路由,并为这些路由设置
RT值,该RT值等于VRF中指定的Export RT。RT值作为BGP的扩展Community属性随路由发布给远端
PE。
-
**Import RT:**PE收到其它PE通告过来的VPNv4路由时,将检查路由的RT,当路由的RT与该PE上某个
VRF的Import RT匹配时,PE就把路由注入到该VRF中。
Export RT和Import RT的设置相互独立,并且都可以设置多个值,能够实现灵活的VPN访问控制,从而实现多种VPN组网方案。例如:某VRF的Import RT包含100:1,200:1和300:1,当收到的路由的RT为100:1、200:1、
300:1中的任意值时,都可以被注入到该VRF中。
前面已经说了,VPN客户的路由在MPLS VPN Backbone内传输时,是通过MP-BGP来运载的,并且在运载的过程中是以VPNv4路由前缀的形式被运载,RD值用于和32bit的IPv4前缀构成96bit的VPNv4前缀。而与路由前缀共同被运载的还有其他的BGP路径属性,例如AS_PATH、LP、OriginCode等,除此之外还有非常重要的RT值,RT被存储在扩展Community属性中,与VPNv4路由一同被运载到对端PE路由器。对端PE也部署了VPN实例,RT值(包括Import RT和Export RT两个值)是关联在VPN实例中的。当PE接收到一大坨
VPNv4路由时,它只将那些匹配VPN实例中的Import RT的路由放入该VPN实例。
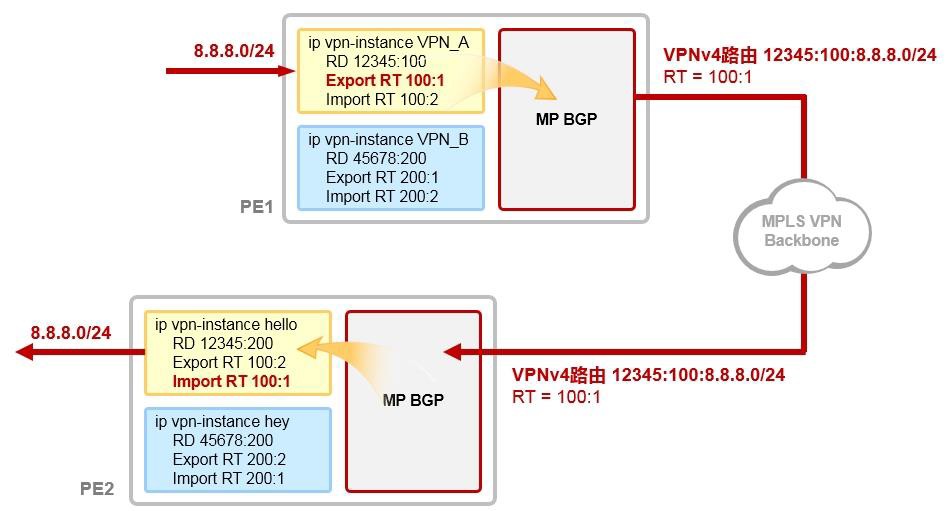
基础实验¶
拓扑说明¶
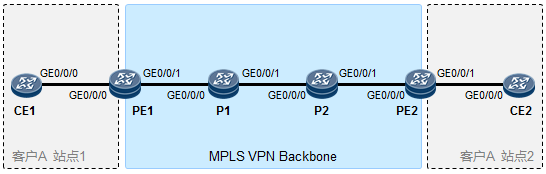
| Device | Port | IP Address | Description | ||
|---|---|---|---|---|---|
| CE1(R1) | GE0/0/0 | 10.1.12.1/24 | |||
| Loopback0 | 1.1.1.1/32 | 模拟站点1的内网路由 | |||
| PE1(R2) | GE0/0/0 | 10.1.12.2/24 | 接口添加到VPN实例ABC | ||
| GE0/0/1 | 10.1.23.2/24 | ||||
| Loopback0 | 2.2.2.2/32 | ||||
| P1(R3) | GE0/0/0 | 10.1.23.3/24 | |||
| GE0/0/1 | 10.1.34.3/24 | ||||
| Loopback0 | 3.3.3.3/32 | ||||
| P2(R4) | GE0/0/0 | 10.1.34.4/24 | |
|---|---|---|---|
| GE0/0/1 | 10.1.45.4/24 | ||
| Loopback0 | 4.4.4.4/32 | ||
| PE2(R5) | GE0/0/0 | 10.1.45.5/24 | 接口添加到VPN实例ABC |
| GE0/0/1 | 10.1.56.5/24 | ||
| Loopback0 | 5.5.5.5/32 | ||
| CE2(R6) | GE0/0/0 | 10.1.56.6/24 | |
| Loopback0 | 6.6.6.6/32 | 模拟站点2的内网路由 |
-
CE1模拟客户A的站点1设备,CE2模拟客户A的站点2设备,CE1及CE2上各有一个Loopback接口
用来模拟站点内的客户路由。CE1与PE1之间,CE2与PE2之间运行的PE-CE路由协议是OSPF, 使用进程号1。
- Backbone内使用OSPF打通骨干内的路由,OSPF使用进程号100。
- PE1及PE2建立基于Loopback的MP-iBGP邻居关系。
- 完成相关配置,使得客户A的两个站点能够互通。
- PE1及PE2建立基于Loopback的MP-iBGP邻居关系。
- Backbone内使用OSPF打通骨干内的路由,OSPF使用进程号100。
配置步骤¶
Backbone内运行OSPF,统一使用进程号100¶
在PE1、P1、P2、PE2上运行OSPF。运行该OSPF进程的目的是为了打通Backbone内的路由,四台路由器都要通告自己的Loopback0网段路由。这个IGP打通的路由一方面是为了LDP能够建立起邻接关系,并且能够正常的分发标签,另一方面也是为了PE1及PE2之间能够建立起基于Loopback 的MP-iBGP邻居关系。
Backbone内运行LDP¶
在PE1、P1、P2、PE2上运行MPLS及LDP。LDP开始工作后,缺省情况下即会为/32的主机路由捆绑并分发标签。骨干网内四台路由器的Loopback路由都会建立LSP。这为后续的客户数据转发做了铺垫。
PE1及PE2创建VPN实例,并运行PE-CE路由协议¶
在PE1及PE2上创建一个VPN实例,命令为ABC,将连接到CE的接口添加到这个VPN实例中。同时PE1、PE2均与自己直连的CE路由器运行一个基于VPN实例的OSPF进程,统一使用进程号1。务必要注意的是这个OSPF进程是基于VPN实例ABC(也就是基于虚拟路由器)的,而不是基于全局路由器的。
PE1及PE2创建MP-BGP进程,并且建立MP-iBGP邻居关系¶
PE1及PE2基于Loopback建立MP-iBGP邻居关系,激活二者的VPNv4连接。
PE1及PE2上配置VPN路由与BGP路由的互重发布¶
由于PE-CE之间选用的路由协议是OSPF,因此为了将路由拉通,需要在两台PE上配置OSPF进程
1,以及MP-BGP的路由双向重发布。
查看及验证¶
设备配置¶
各设备接口IP地址的配置这里不再赘述了。
Backbone内运行OSPF¶
Backbone内的设备:PE1、PE2、P1、P2运行OSPF,统一使用进程号100。运行该OSPF进程的目的是为了打通骨干网内的路由,四台设备在互联接口上激活OSPF,并且通告自己的Loopback0 接口路由。
PE1的配置如下:
P1的配置如下:
P2的配置如下:
PE2的配置如下:
完成配置后,在各设备上查看路由,确保路由表是正确的。
Backbone内运行MPLS及LDP¶
PE1的配置如下:
P1的配置如下:
P2的配置如下:
PE2的配置如下:
完成配置后,确保所有的LDP邻居关系都正确的建立:
其他设备的查看不再赘述。
| \<PE1>display mpls lsp ------------------------------------------------------------------------------- LSP Information: LDP LSP ------------------------------------------------------------------------------- | ||
|---|---|---|
| FEC | In/Out Label | In/Out IF Vrf Name |
| 2.2.2.2/32 | 3/NULL | -/- |
| 3.3.3.3/32 | NULL/3 | -/GE0/0/1 |
| 3.3.3.3/32 | 1024/3 | -/GE0/0/1 |
| 4.4.4.4/32 | NULL/1025 | -/GE0/0/1 |
| 4.4.4.4/32 | 1025/1025 | -/GE0/0/1 |
| 5.5.5.5/32 | NULL/1026 | -/GE0/0/1 |
| 5.5.5.5/32 | 1026/1026 | -/GE0/0/1 |
上面输出的是PE1的标签转发表。我们看到关于网络中的/32主机路由都已经收到了标签。
PE1及PE2创建VPN实例,并运行PE-CE路由协议¶
PE1的配置如下:
CE1的配置如下:
PE2的配置如下:
CE2的配置如下:
完成配置后,确保PE能够学习到直连CE的客户路由:
| Destinations : 5 Routes : 5 | ||||||
|---|---|---|---|---|---|---|
| Destination/Mask | Proto | Pre | Cost | Flags | NextHop | Interface |
| 1.1.1.1/32 | OSPF | 10 | 1 | D | 10.1.12.1 | GigabitEthernet0/0/0 |
| 10.1.12.0/24 | Direct | 0 | 0 | D | 10.1.12.2 | GigabitEthernet0/0/0 |
| 10.1.12.2/32 | Direct | 0 | 0 | D | 127.0.0.1 | GigabitEthernet0/0/0 |
| 10.1.12.255/32 | Direct | 0 | 0 | D | 127.0.0.1 | GigabitEthernet0/0/0 |
| 255.255.255.255/32 | Direct | 0 | 0 | D | 127.0.0.1 | InLoopBack0 |
PE1上VPN实例ABC的路由表中已经通过OSPF学习到CE1的客户路由1.1.1.1/32。
PE1及PE2创建MP-BGP进程,并且建立MP-iBGP邻居关系¶
PE1的配置如下:
PE2的配置如下:
PE1及PE2上配置PE-CE协议与BGP的互重发布¶
PE1的配置如下:
PE2的配置如下:
确认下CE1是否已经收到去往CE2的路由:
CE1已经学习到了CE2所在站点的路由。反之同理,不再赘述。
查看及验证¶
在PE1上查看路由6.6.6.6/32的详细信息。该条路由是通过MP-iBGP从PE2传递过来的。从详细信息的
输出我们可以看到路由的下一跳是5.5.5.5。并且该路由捆绑的VPN标签是1027。因此当PE1收到IP数据包要去往6.6.6.6时,会为数据包压入VPN标签1027,同时为了让这个标签包能够正常的穿越骨干网并到达PE2上,还需为该标签包再增加一层标签。由于去往6.6.6.6的下一跳是5.5.5.5,因此在外层压入
5.5.5.5路由对应的标签:
| 3.3.3.3/32 | NULL/3 | -/GE0/0/1 |
|---|---|---|
| 3.3.3.3/32 | 1024/3 | -/GE0/0/1 |
| 4.4.4.4/32 | NULL/1025 | -/GE0/0/1 |
| 4.4.4.4/32 | 1025/1025 | -/GE0/0/1 |
| 5.5.5.5/32 | NULL/1026 | -/GE0/0/1 |
| 5.5.5.5/32 | 1026/1026 | -/GE0/0/1 |
从上面的输出我们可以看到PE1的标签转发表中,5.5.5.5的出站标签是1026。所以最终去往6.6.6.6的
IP包被压入两层标签。内层VPN标签值是1027,外层LDP标签是1026。报文被处理后转发给了P1。P1
在收到这个标签包后查看自己的标签转发表,注意,它只会查看外层标签。
从P1的转发表我们可以看出,1026的入站标签,对应的出站标签是1026,并且出站接口是GE0/0/1。因此它将收到的标签包的外层标签从1026置换成1026(碰巧置换前后标签值是一样的),然后从
GE0/0/1口发出去。P2将收到这个标签包,也是查标签转发表:
P2发现,1026的入站标签,对应的出站标签是3,而3是一个保留标签,意味着要将该顶层标签弹出。于是它将收到的标签数据的顶层标签弹出,然后剩余的数据从GE0/0/1口送出去。PE2将最终收到仍然
携带者VPN标签的数据。由于这个VPN标签是它自己发给PE1的,因此它知道这个标签值意味着什么、与哪一个VPN实例对应。因此最终它将VPN标签剥去,然后将IP数据包转发给CE2。
在PE1上Tracert 6.6.6.6,可以查看到整个数据层面的过程:
实际上是这样的:
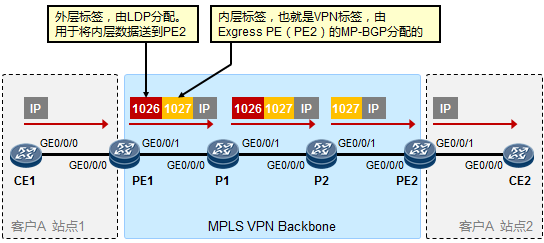
服务质量¶
12.1 流量分类与标记
12.1.1 修改流量的 DSCP¶
在上图所示的场景中,缺省情况下,SW1并未对R1发往SW2的IP流量做DSCP值的设置。一个简单的验证方法是在SW2上使用:“capture-packet acl xxx interface GigabitEthernet 6/0/15 destination terminal”(其中XXX为事先定义好的ACL)来捕获R1发过来的报文,例如当R1 ping 1.1.1.3时,可以捕获如下ICMP报文:

从上图可以看出,此时报文的ToS字段(红色子图部分)值为0x00,因此DSCP值也为缺省的0。现在,我们在SW1上完成如下配置,使得SW1将所有从GE0/0/15接口出站的ICMP报文的DSCP值设置为EF,从而让上游交换机SW2能够有针对性地处理这些流量:
完成上述配置后,让R1 ping 1.1.1.3 时,将看到在SW3上捕获到如下报文:
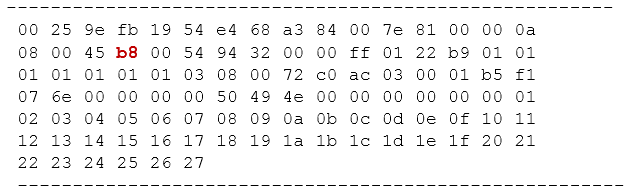
可以看到ToS字段的值变成了0xB8,换算成二进制也就是10111000,这就是EF对应的值。而对于其他非
ICMP报文(没有被ACL3000匹配的流量),SW1将直接放行(上述场景在S5300交换机上验证)。
故障处理¶
- 网络故障处理概述
网络问题处理的一般流程:¶
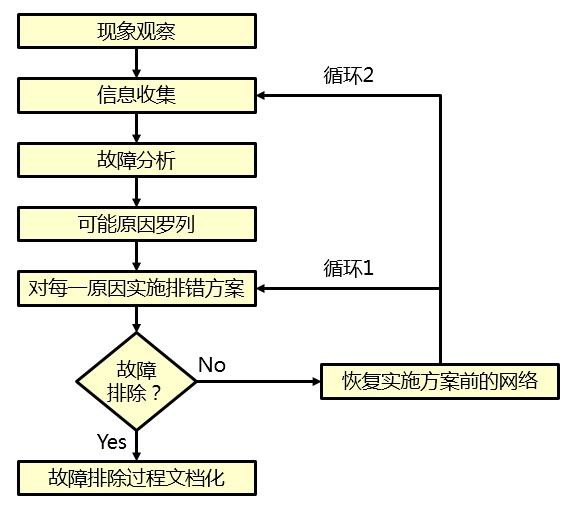
综合网络问题定位及处理方法(宏观):¶

什么是分层处理法:¶
分层法思想很简单:所有通信都遵循相同的基本前提——当参考模型的所有低层结构工作正常时,它的高层结构才能正常工作。

分层法处理案例:¶
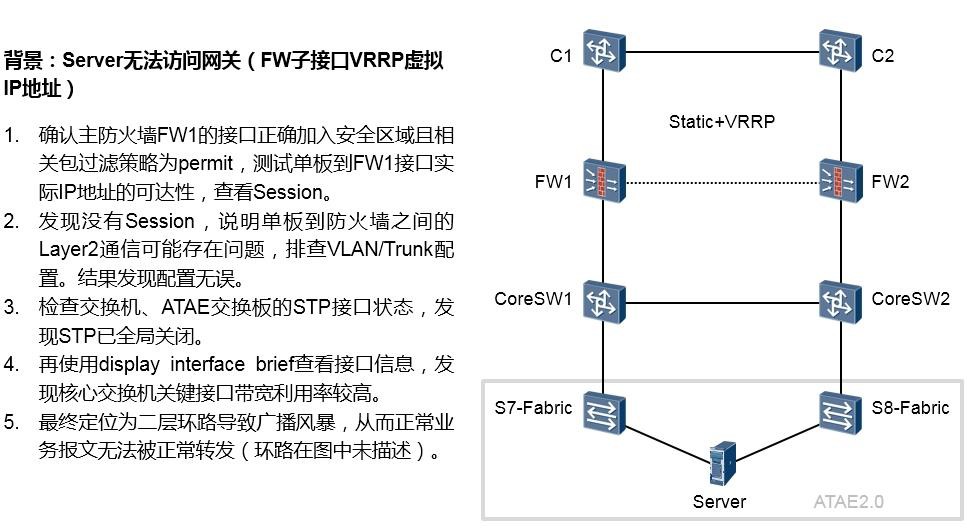
分段故障处理案例:¶
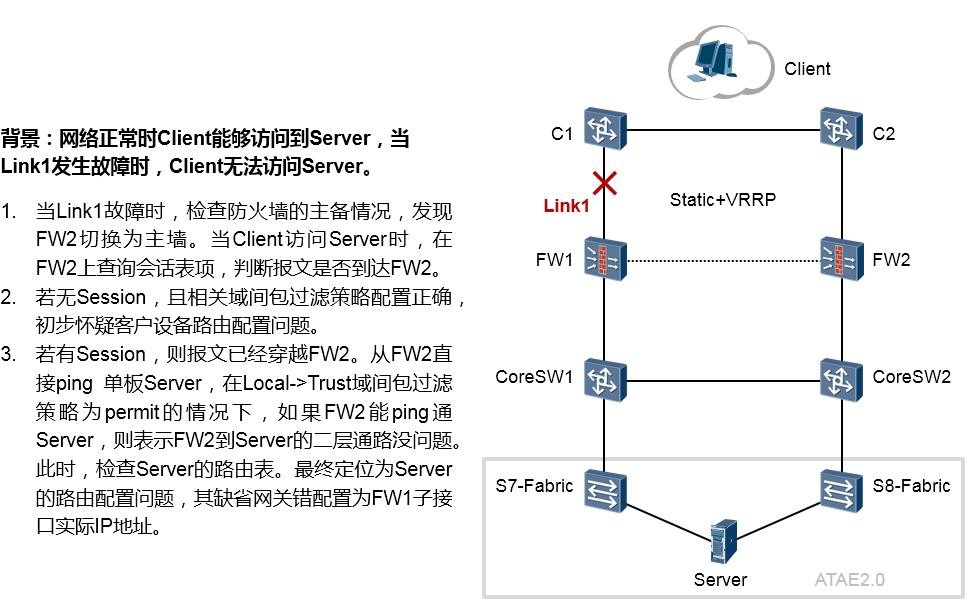
替换法:替换法是检查硬件问题最常用的方法之一:¶
- 当怀疑是网线问题时,更换一根确定是好的网线试一试;
- 当怀疑是接口模块有问题时,更换一个其它接口模块试一试 ;
- 在实际网络故障排错时,可以先采用分段法确定故障点,再通过分层或其它方法排除故障 。
- 网络故障处理案例
案例 1:某局点单板无法访问客户网络设备¶
故障背景¶
网络拓扑如上图所示。核心交换机CO-SW是两台S6300交换机(堆叠组),CO-SW作为ATAE3.0业务单板的网关设备。CO-SW与FW1/FW2采用独立的VLAN进行三层对接,采用静态路由的对接方案。CO-SW配置默认路由,下一跳为防火墙。FW1/FW2以主备方式工作,FW1被配置为初始时的主墙。FW1/FW2配置了
HRP非抢占,开启了HRP会话快速镜像,此前由于进行过切换测试,因此FW2是当前的主墙。一线反馈ATAE3.0中的服务器单板存在如下问题:
- 单板能ping通网关(CO-SW),单板的缺省网关是CO-SW的Vlanif;
- 单板能ping通192.168.1.1(该地址是防火墙内部接口,或者说下行接口的VRRP浮动IP地址);
- 单板能ping通10.1.1.1(该地址是防火墙对外接口,或者说上行接口的VRRP浮动IP地址);
- 单板无法ping通10.1.1.5;(C1/C2为客户交换机);
- 单板无法ping通客户网络中的某个设备10.3.97.6。
故障分析¶
-
检查当前主墙FW2的配置,发现上行接口、下行接口均被放置在trust区域,而NGFW(现场是E1000E-
N防火墙)对于相同区域内、不同接口间的流量缺省禁止,因此单板访问客户网络(流量是从trust到trust) 自然是不通的。
-
一线按照要求将FW1/FW2上行接口改为放置在untrust区域,且配置了trust到untrust区域的安全策略, 发现单板可以ping通10.1.1.5,但是依然无法ping通客户网络中的服务器10.3.97.6。在执行ping的过程中,在当前主墙FW2上无法观察到Session,说明可能报文没有到达FW2,或者到达了却没被安全策略放通,又或者FW2没有外出的路由(使得其无法判断报文的出接口及出站区域),检查FW2的策略及路由配置发现均无问题。
- 在一线反馈的数据中观察到,单板访问10.1.1.5时,在当前主墙FW2看到的Session如下:
Session带有remote字样,说明该会话是从FW1同步过来的(防火墙配置了hrp mirror session enable),
那么流量应该是从FW1外出的。由此可猜测,交换机到达客户网络的默认路由下一跳可能设置在FW1 的接口实际IP地址上,而不是VRRP虚拟IP192.168.1.1。也就是说,单板访问外部网络的流量不是从
FW2外出,而是从FW1。
- 检查FW1的配置,发现其配置的静态路由中,并没有到达10.3.97.6的路由,因此单板访问该IP地址的流量到达FW1后,无法被正常转发。
解决方案¶
- 修改核心交换机的配置,将到达客户网络的路由指向192.168.1.1;
- 在FW1上增加到达客户网络的路由。
案例 2¶
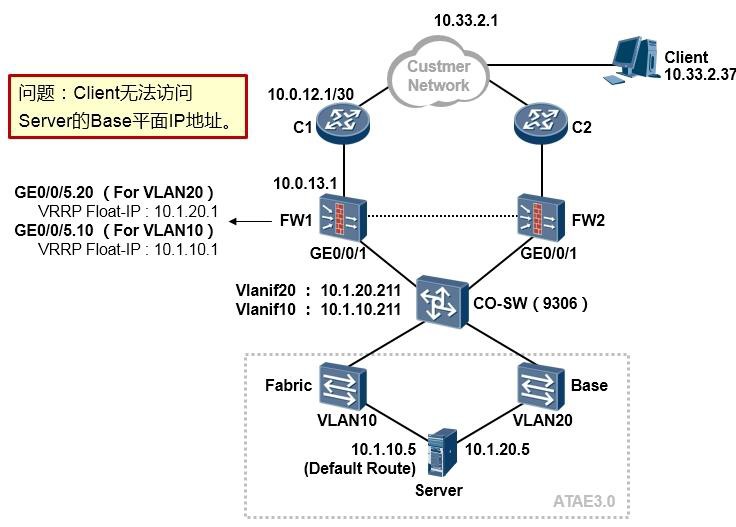
- 从Client ping 10.1.20.5,发现无法ping通,问题存在。
- 从Client tracert 目标节点的输出来看,数据包应该是到达了防火墙,检查防火墙策略,发现已经域间策略已经放通了相应的流量。
- 从Client ping 10.1.20.5时,在防火墙查看会话表,发现出现了相应表项,证明数据包已经穿越防火墙进入了内网。
- 从防火墙ping 10.1.20.5,发现能够ping通,说明如果报文到达防火墙,因此防火墙是有能力报文转发到目的地的。
- 初步怀疑Client访问Server的Base网卡的流量已经到达了单板,但是回程流量存在问题,在防火墙上查看相应会话表的明细信息(verbose),发现在Client ping 10.1.20.5时,去程的报文个数始终在增加, 而回程报文个数为0,进一步验证了我们的猜测。
-
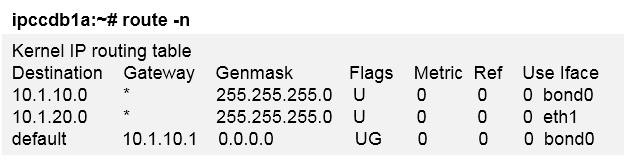 检查Server的路由配置:
检查Server的路由配置:因此,故障根因如下:
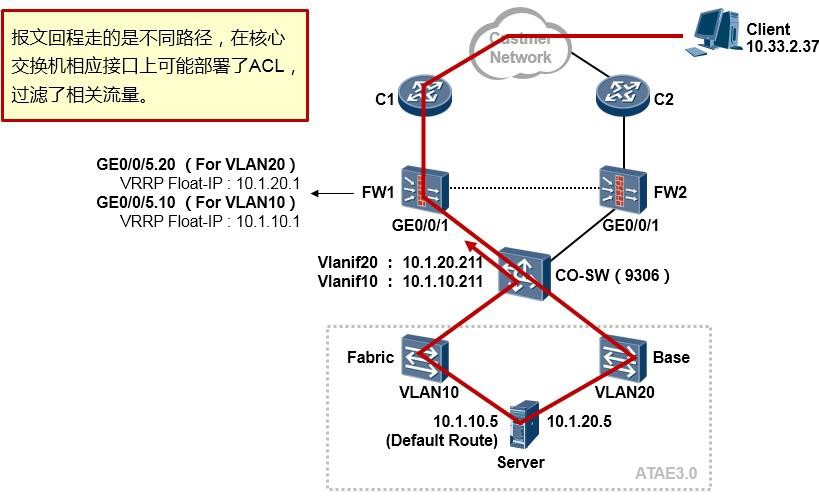
案例 3¶
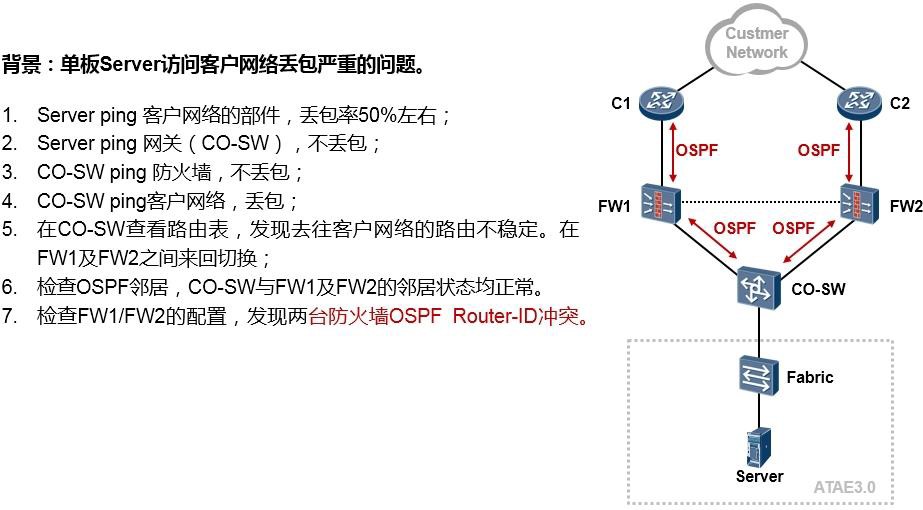
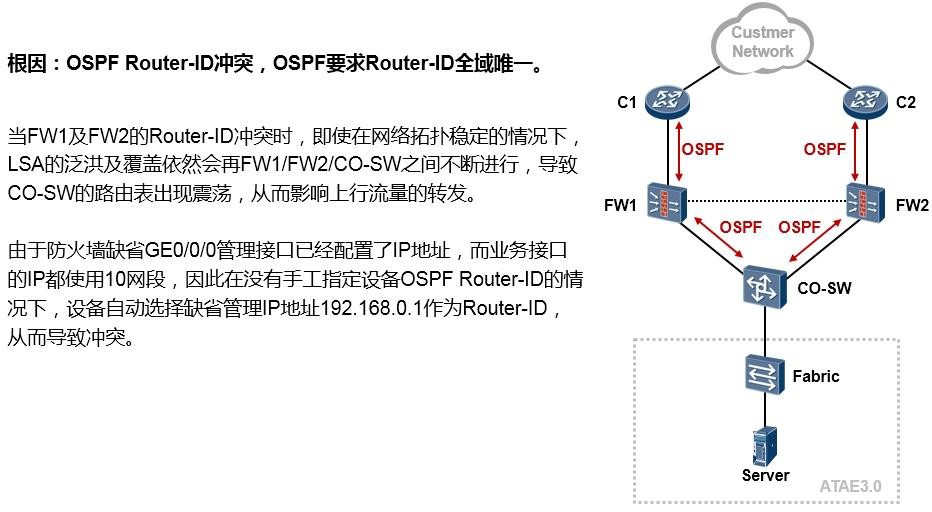
案例 4¶
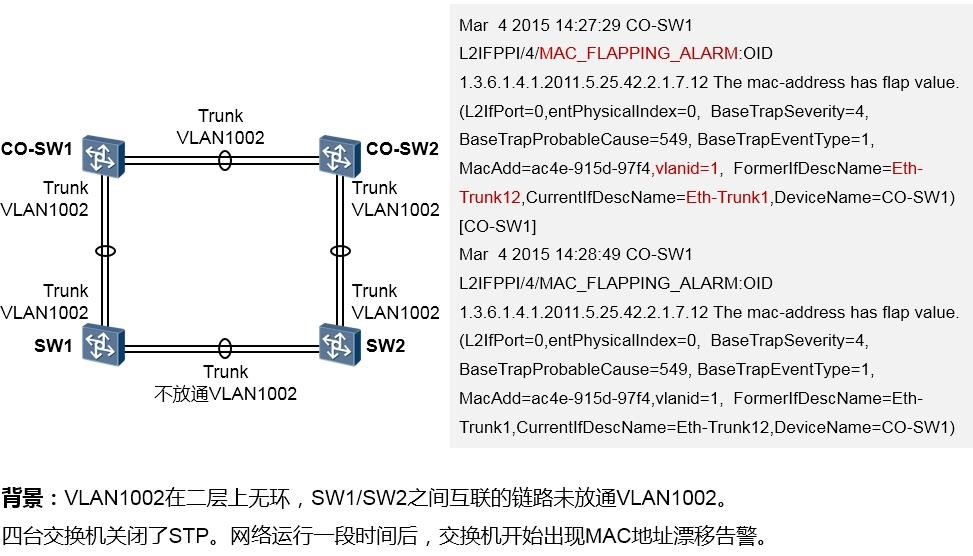
经检查后,发现根因如下:
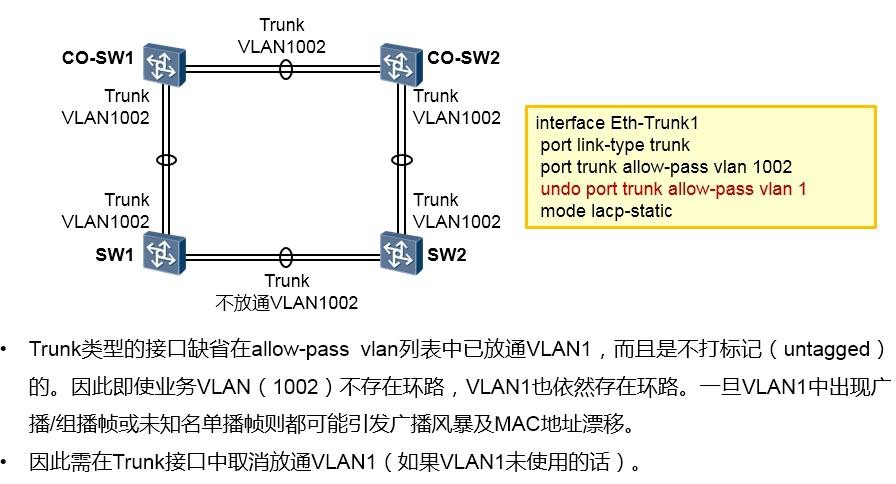
案例 5¶
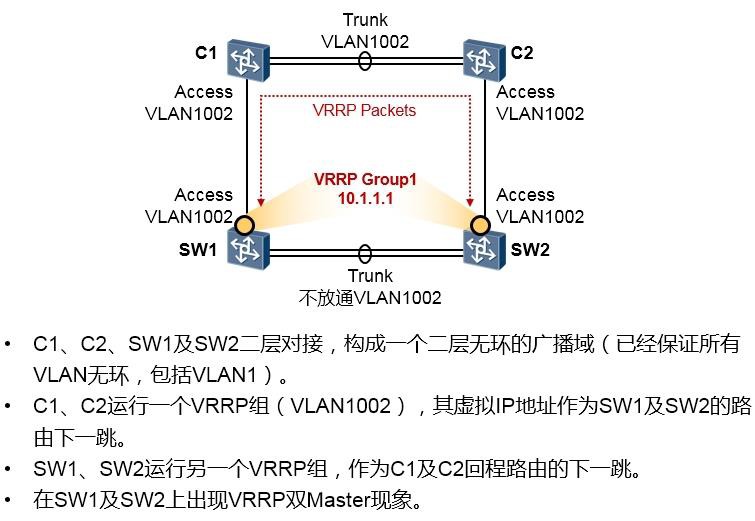
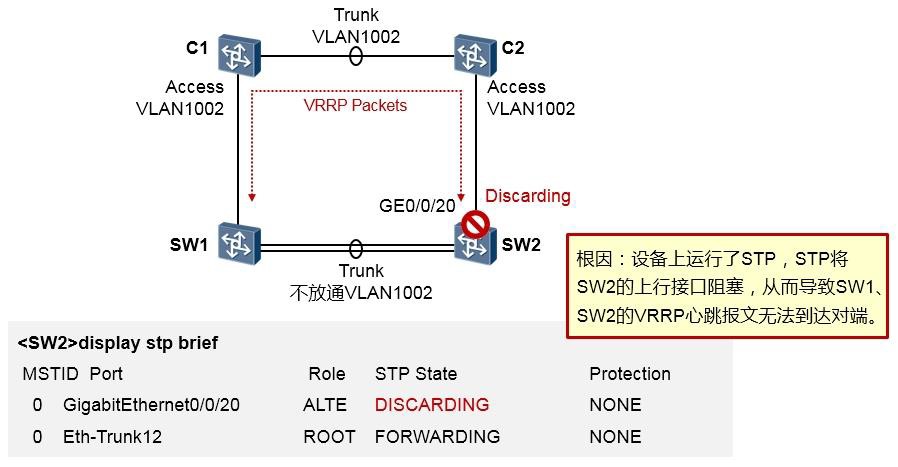
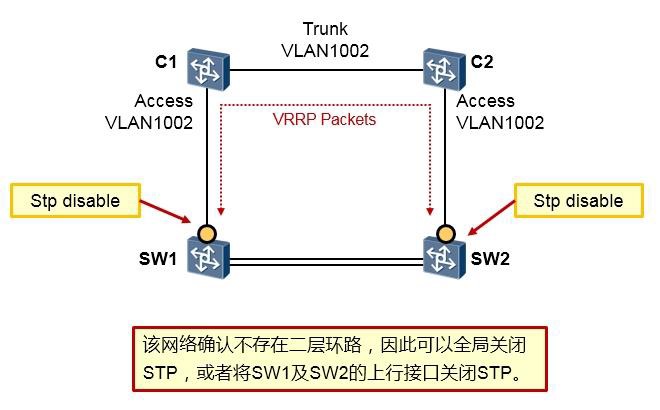
案例 6¶
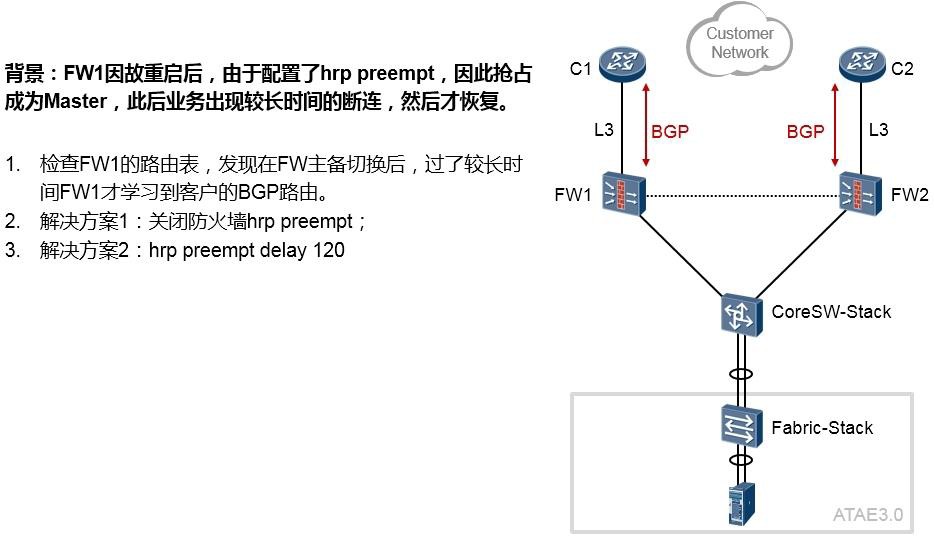
案例 7¶
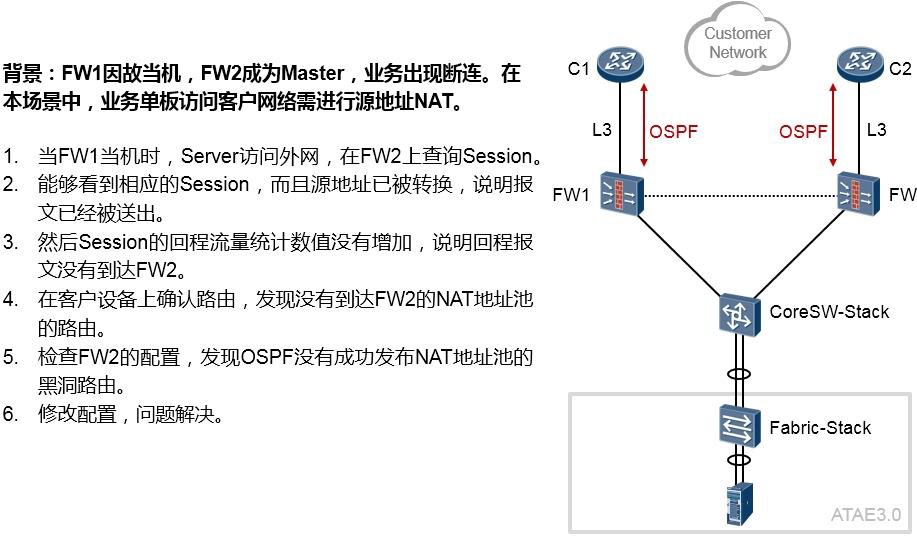
案例 8¶
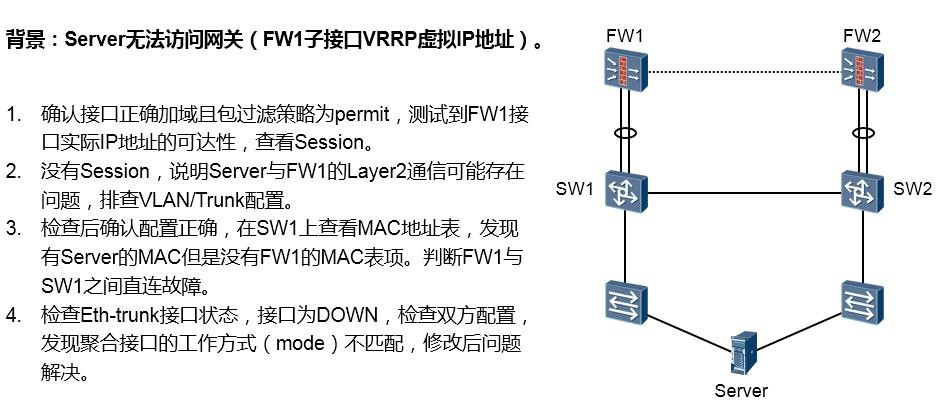
案例 9¶